
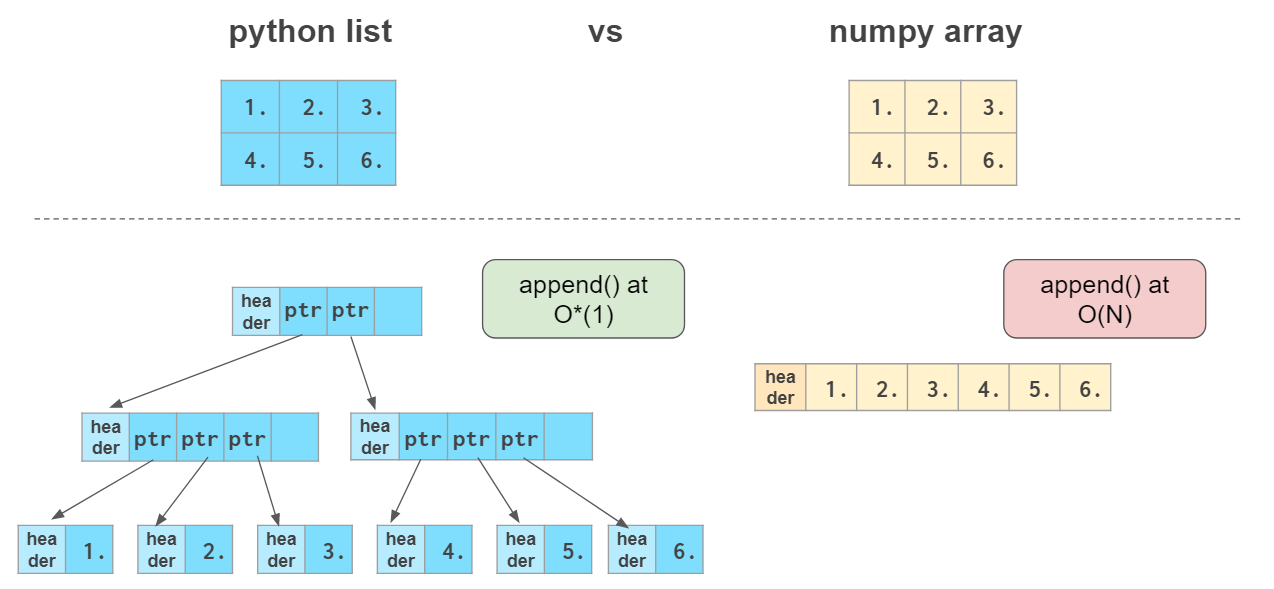
Numpy 배열 VS 파이썬 List
처음 봤을 때 둘을 비슷해보인다. insert, delete가 간편하다는 점에서.
하지만 그 배열 자체에 연산자를 적용할 수 있는 것은 numpy 배열이다
numpy는 1차원을 벡터로 다루기에 list보다 빠르다

다만 마자막 원소를 추가할 때는 list(append)보다 느리다
list는 O(1)인 반면에 numpy 배열은 O(N)
벡터 초기화
list를 numpy 배열로
데이터 타입은 자동으로 정해진다.

모두 동일한 값으로
python list와 다르게 처음 정해진 길이 그대로 가기 때문에
np.zeros()나 np.empty()로 미리 초기화해야한다

_like 를 붙이면 원본 shape를 유지하면서 초기화할 수 있다

순차적으로 증감하도록
순차성을 가진 배열을 만들 때는
np.arange() 와 np.linspace()를 쓰면 된다
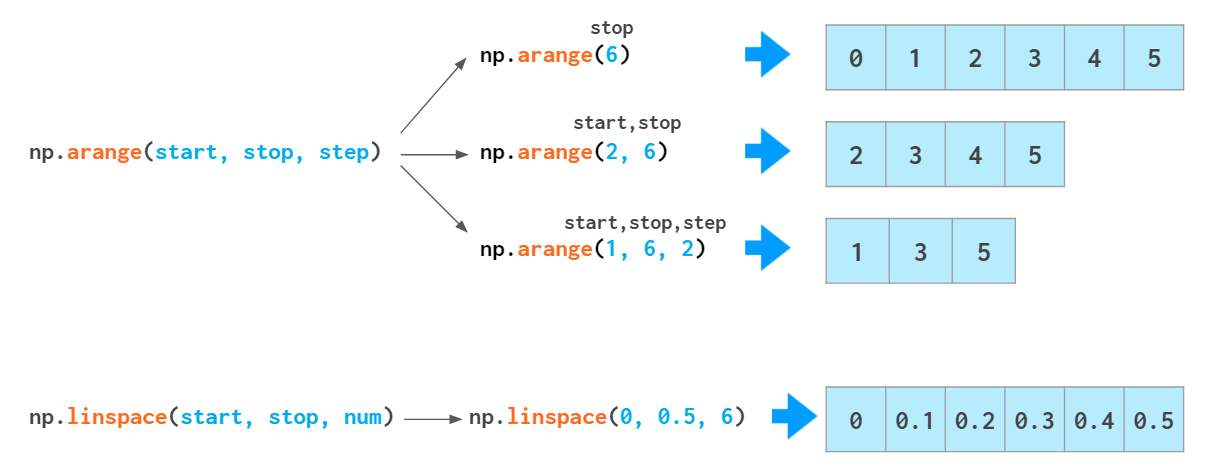
np.arange()는 python range와 비슷하다 (start, stop, step)
다만 float를 다룰 때는 arange가 훨씬 좋다
사람 눈에는 0.1이 유한소수점 수로 보이겠지만 컴퓨터에겐 아니다
이진수에서 무한소수는 어느 지점에서 올림이 되어 에러를 일으킨다
그래서 arange()의 step을 float로 하는 것은 나쁜 생각.
대신 stop이 정수가 아닌 수에 떨어질 수 있게 정하는 것이 중요하다 (solution 1)
그렇지만 이는 가독성을 떨어뜨리고 유지보수하기 어려워진다
이럴 때는 linspace 추천 (solution 2)
이 함수는 올림 에러를 일으키지 않는다.
점의 개수를 세지, 간격의 개수를 세지 않기 때문에 마지막 argument는 항상 +1이 되어
사람이 생각한 방식대로 된다
그래서 gotcha의 ?는 10이 아닌 11이다

random 배열로
테스트 시 필요한 random 배열은 다음과 같이 초기화 할 수 있다
아래 방식은 구버전 코드

새롭게 random 배열 초기화 방식이 나왔다
멀티 쓰레딩에 적합하고, 빠르고,
구버전에서 실패하던 까다로운 합치기 과정도 된다

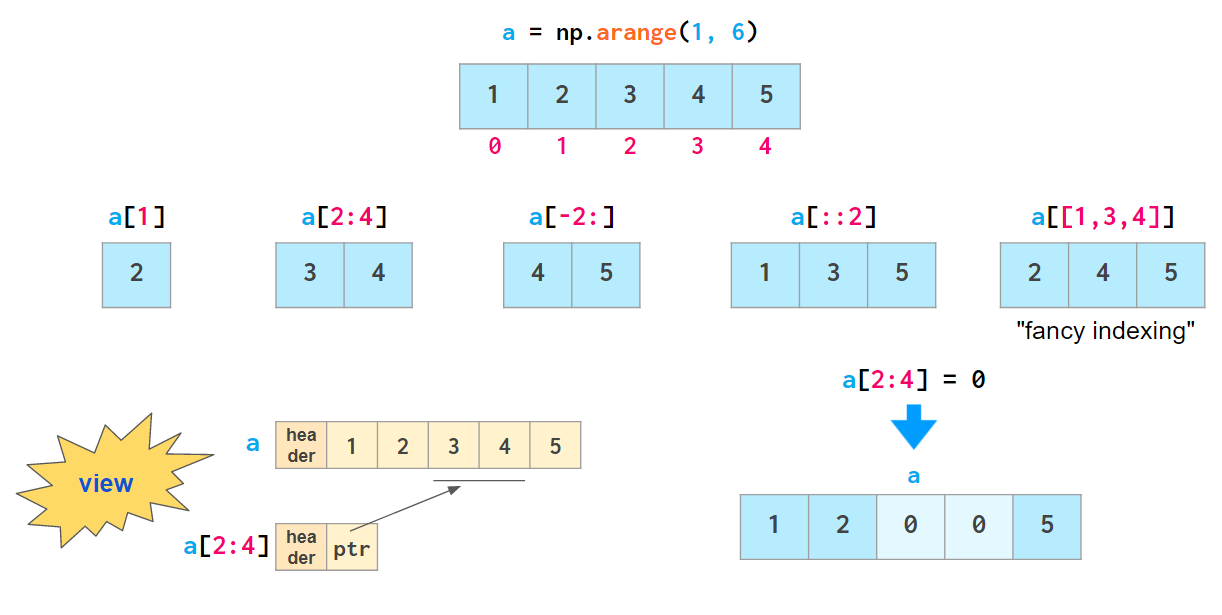
벡터 접근
slicing으로 가져온 것은 소위 "views"라고 부르며
실제 값을 가져오는 것이 아닌 해당하는 부분의 pointer(주소)만 가져온다
그래서 원본 배열에서 일어난 변형이 slicing에도 적용된다

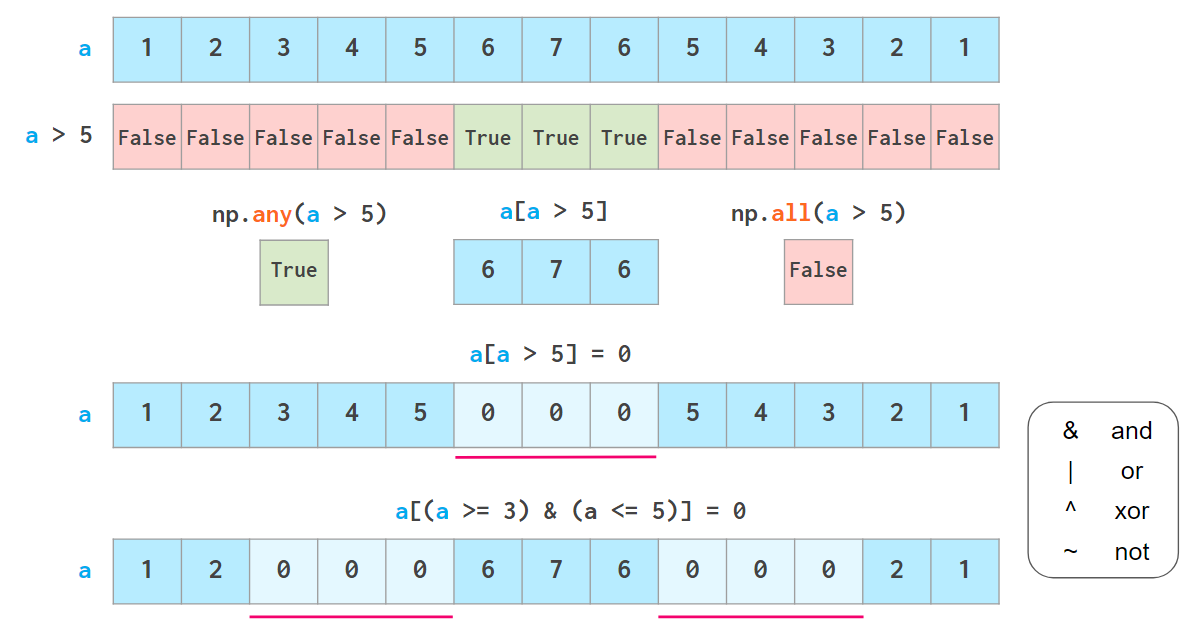
numpy 배열은 값 접근을 boolean으로 할 수 있다
아래처럼 논리 연산자를 이용해서.
이 때 3<=a<=5같은 파이썬 특유의 문법은 적용되지 않으니 주의
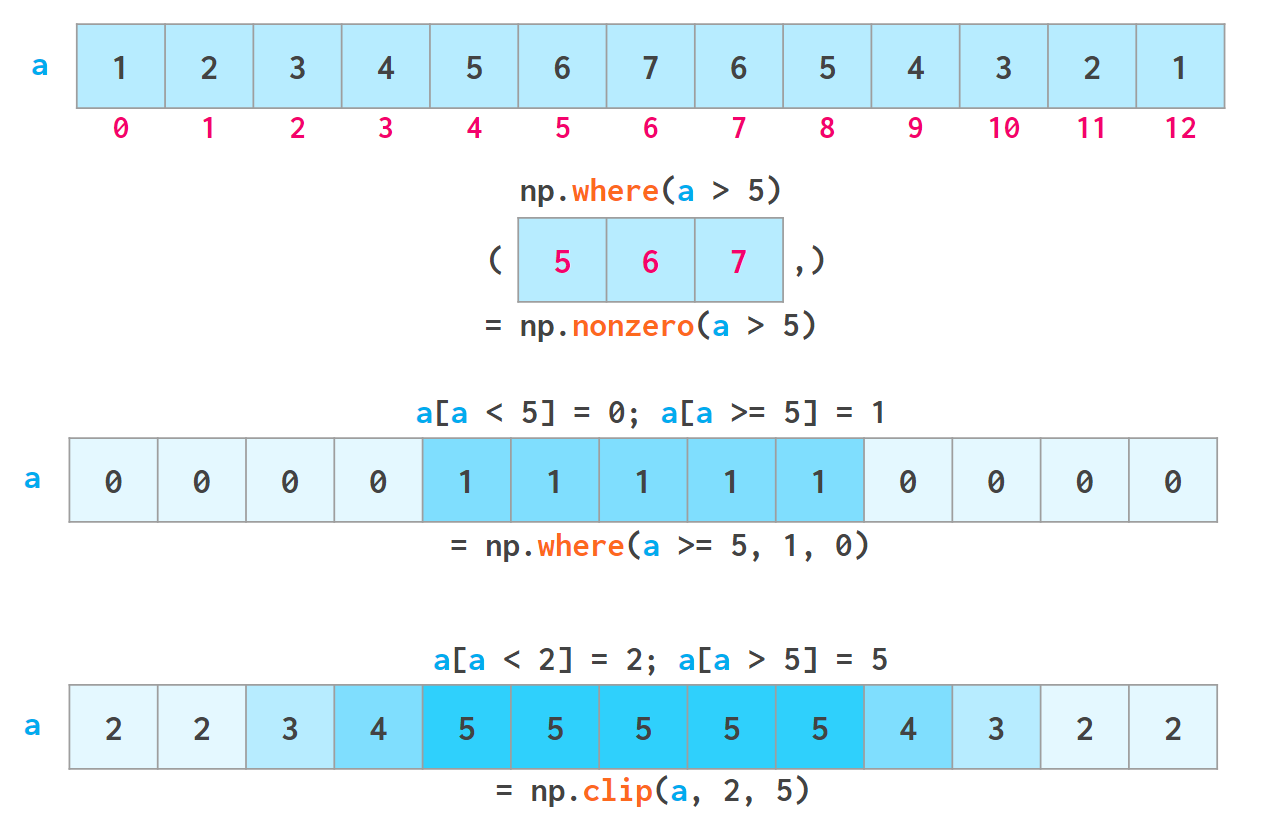
np.where
() 안에 조건(논리연산자) 하나만 있다면 해당 부분을 slice 해온다
대신 np.where(a>5)의 결과는 ([5,6,7], )인 튜플이기에
그 slice에 접근하고 싶다면 np.where(a>5)[0]
() 안에 조건, 값1, 값2 이렇게 3개가 있다면
조건 결과가 참인 곳은 값1이, 거짓인 곳은 값2가 저장된다
outlier(이상치)나 결측지를 처리하기 편하다
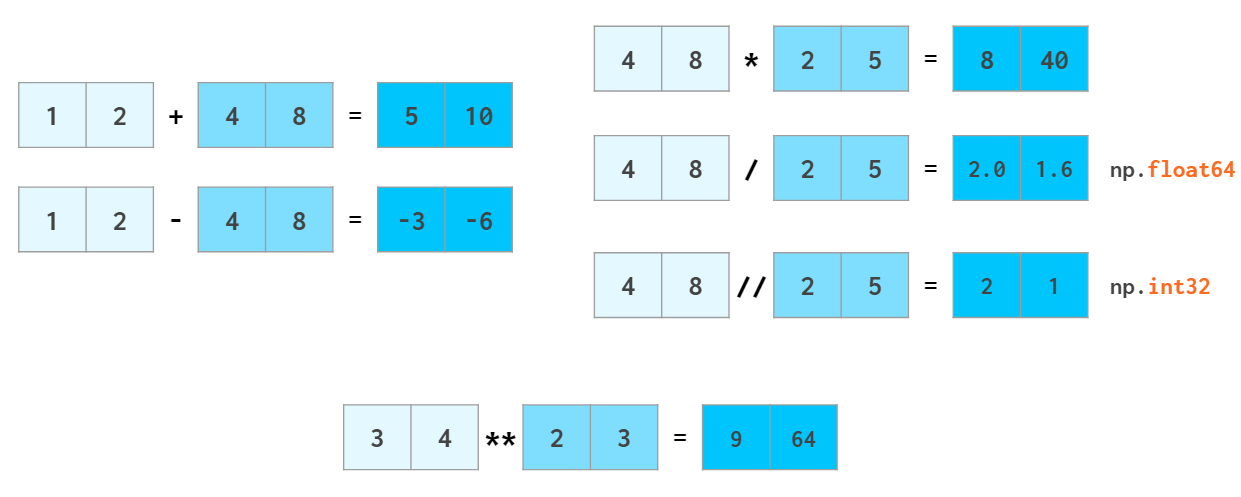
벡터 연산
벡터 연산은 c++ 수준에서 진행되기에 느린 파이썬의 단점을 피할 수 있다
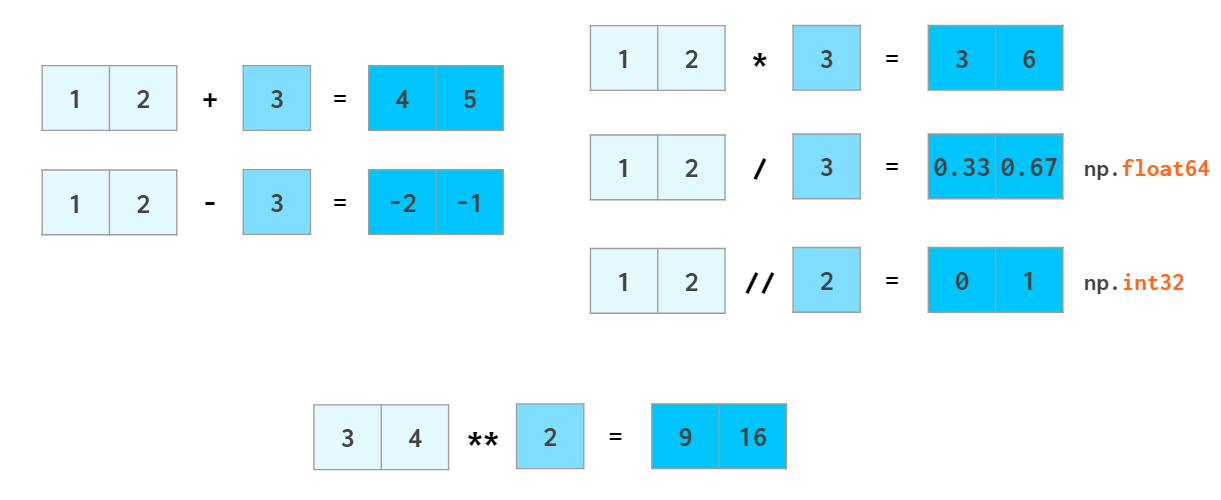
shape이 일치하지 않은 경우에는
자동적으로 broadcast되어 스칼라(scalar)처럼 계산한다
이외에도 Math 관련 함수도 있다

반올림 관련

최대/최소 및 평균/표준편차/분산 등
-
argmax, argmin은 최대값, 최소값이 담긴 곳의 index를 반환

-
Bessel의 보정에 따라
var와std는 표본 크기 n을 대신하여 n-1을 사용. 모분산 추정에 있어 편향(bias)를 보정하는 역할을 하지만 평균제곱오차를 증가시키는 단점이 있다.
https://ko.wikipedia.org/wiki/%EB%B2%A0%EC%85%80_%EB%B3%B4%EC%A0%95 -
ddof : delta degrees of freedom
이를 코드로 표현하기 위해ddof=1을 설정한다-
np.sqrt((((x-x.mean())**2)/len(x)).sum()) -
np.sqrt((((x-x.mean())**2)/(len(x)-1)).sum())
-
삼각함수

내적과 외적

정렬
python과 비슷한 문법으로 해도 된다
다만 reverse 기능은 없다

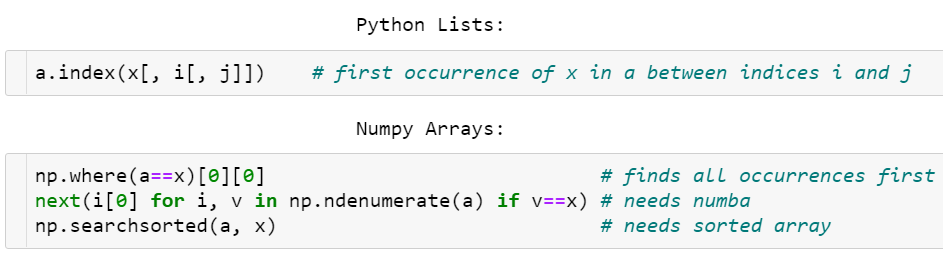
탐색
float 비교로 인해 획기적으로 빠를 순 없지만...
np.where(a==x)[0][0]- 더 빠르게 하는 방법은 ```next( (i[0] for i,v in np.ndenumerate(a) if v==x), -1)
- 다만 worst case에서는 where보다 느림 - 정렬한 경우에는
v = np.searchsorted(a, x)
-return v if a[v]==x else -1
Broadcasting
np.full
- 차원 수가 적은 배열의 왼쪽부터 채워진다
- 단 하나의 차원도 일치하지 않는다면, 1칸씩 늘려가며 매치하여 늘린다


비교
-
numpy.array_equal(a1, a2, equal_nan=False)
- NaN에는 보통 쓰레기값이 들어있기에 이들이 동일하려면 equal_nan=Trueimport numpy as np a1 = np.array([1,2,4,6,7]) a2 = np.array([1,3,4,5,7]) print(np.array_equal(a1,a1)) # True print(np.array_equal(a1,a2)) # False -
numpy.array_equiv(a1, a2)
- shape와 각 요소들이 동일하면 True```import numpy as np
a1 = np.array([1,2,4,6,7])
a2 = np.array([1,3,4,5,7])
a3 = np.array([1,3,4.00001,5,7])
print(np.array_equiv(a1,a2)) # False
print(np.array_equiv(a3,a2)) # False``` -
==과numpy.all()
- 두 배열의 shape이 다르면 에러 발생- 해당 Index의 값이 서로 일치하는지 확인
import numpy as np```
a1 = np.array([1,2,4,6,7])
a2 = np.array([1,3,4,5,7])
a3 = np.array([1,3,4.00001,5,7])
print((a1==a2).all()) # False
print((a3==a2).all()) # False
- 해당 Index의 값이 서로 일치하는지 확인
출처
