.png)
Table of Contents
1 - Introduction to ML Strategy
2 - Setting up your goal
3 - Comparing to human level performance
4 - Error Analysis
5 - Mismatched Training and Dev/Test Set
6 - Learning from Multiple Tasks
7 - End-to-end Deep Learning
Objective
- Apply satisfying and optimizing metrics to set up your goal for ML projects
- Choose a correct train/dev/test split of your dataset
- Understand how to define human-level performance
- Use human-level perform to define your key priorities in ML projects
- Take the correct ML Strategic decision based on observations of performances and dataset
- Understand what multi-task learning and transfer learning are
- Recognize bias, variance and data-mismatch by looking at the performances of your algorithm on train/dev/test sets
1 - Introduction to ML Strategy
Why ML Strategy
딥러닝 모델 성능을 향상시키기 위해 다양한 전략이 있다.
- 데이터 수집
- 더 많은 학습 데이터 수집
- 다양한 학습 데이터 수집
- 최적화 알고리즘
- 경사하강법
- Adam
- 신경망 크기 bigger/smaller network
- 정규화
- Dropout
- L2
- 네트워크 구조
- 활성화 함수
- 은닉층 수
...
다양한 아이디어들이 존재하지만, 좋은 아이디어를 빠르고 효율적으로 선택할 수 있으면 좋지 않을까? 머신러닝 문제 분석 전략 ways of analyzing a machine learning problem that will point you in the direction of the most promising things to try 과 머신러닝 제품을 만들면서 얻은 러닝을 살펴본다.
Orthogonalization
-
머신러닝 전략에서 직교화 : 원하는 효과를 위해 변수를 조정하는 과정
(직교는 서로 90도를 이룬다는 뜻이다. 이 개념을 시스템에 적용해서 이해해보자. 하나의 버튼이 회전각에 영향을 주고 다른 하나의 버튼이 속도에 영향을 준다. 이 경우(직교)에는 쉽게 버튼을 조작해서 원하는 속도나 회전각대로 시스템이 작동하도록 만들 수 있다. 만약 두 가지가 동시에 조절될 경우(직교가 아닌 경우)에는 원하는 대로 조작하기 어려울 수도 있다.)
Chain of assumptions in ML
지도학습이 잘 이루어지기 위해서는 다음 4가지 가정을 만족해야한다. 4가지 가정에 기반해서 문제가 생긴 원인을 파악하고 해당 부분을 조정(관련된 하나의 버튼을 조작)하는 것이다.
- Fit
training setwell on cost function
최소한 학습 데이터에서는 잘 작동해야한다. (어플리케이션에 따라서 human-level performance만큼 나와야할 수도 있다.)
- 신경망 네트워크 조정, 학습 알고리즘 변경
- Fit
dev setwell on cost function
개발 세트에 대해서 좋은 성능을 보여야한다.
- 정규화, 더 큰 training set
- Fit
test setwell on cost function
테스트 세트에 대해서 좋은 성능을 보여야한다.
- 더 큰 dev set
- Performs well in real world
실제 세상에서도 좋은 성과로 이어져야한다.
- dev set 변경(개발 세트의 분포 설정 문제), 비용함수 변경
2 - Setting up your goal
Single number evaluation metric
분류기의 성능을 평가하는 합리적인 방법 중 하나는 정밀도, 재현율 보는 것이다.
- 정밀도 : 모델이 분류한 정답중에 진짜 정답이 얼만큼 있는지 측정
- 분류기가 고양이로 인식한 예시( = 1) 중 실제 고양이( = 1)인 비율
- 재현율 : 실제 정답중에 모델이 정답을 얼만큼 분류했는지를 측정
- 실제 고양이 ( = 1) 중에서 분류기가 고양이로 인식한 ( = 1) 비율
정밀도와 재현율사이에는 트레이드 오프 관계가 있다.
| Classifier | 정밀도(Precision) | 재현률(Recall) | F-1 score |
|---|---|---|---|
| A | 95% | 90% | 92.4% |
| B | 98% | 85% | 91.0% |
단일 숫자 평가 지표가 아닌 두 개의 숫자 평가 기준 정밀도와 재현률로는 A와 B 둘 중 어느 분류기가 좋은 모델인지 선택하기 어렵다. 어느 모델이 좋은 성능인지 빠르게 고르기 어려우므로, 둘을 결합한 새로운 단일 평가 기준을 정의하고 그 기준을로 어느 분류기가 더 잘 작동하는 지 결정할 수 있다.
- 정밀도와 재현율의 조화 평균 F-1 Score
dev set개발세트와Single (real) number evaluation metric하나의 정량적 평가기준을 사용하면 빠르고, 효율적으로 모델 선택, 알고리즘 개선을 할 수 있다.
Satisficing and optimistic metric
위에서 살펴본 것처럼 하나의 정량적 평가기준을 설정하는 것은 어려움이 있다.
-
모델 평가 기준에 정확도와 실행시간을 결합한다고 가정해보자.
분류기 정확도(Accuracy) 실행 시간(Running Time) A 90% 80ms B 92% 95ms C 95% 1500ms 두가지 기준을 결합해서 비용을
Cost = Accuracy - 0.5*RunningTime정의하는 것은 부자연스럽다. -
대신, 정확도 Accuracy가 최대인 분류기를 선택하되, 이미지를 분류하는 데 소요되는 실행 시간 Running Time이 100ms보다 작은 것 중에 고른다.
- Optimizing Metric 최적화 지표 : 정확성 Accuracy
- Satisficing Metric 조건 지표 : 실행 시간 Running Time
- Threshold 허용 가능 임계값 : 100ms
(이 기준 이하면 어떤 값이든 허용)
- Threshold 허용 가능 임계값 : 100ms
-
Trigger Word Detection System 의 예를 살펴보자.
두 개의 평가 척도 평가 척도 결합 Trigger word를 말한 경우에 장치가 반응하는 빈도 (True Positive rate) Optimizing Metric Trigger word를 말하지 않은 경우에 반응하는 빈도 (False positive rate) Satisficing Metric 시스템 성능에 대한 두 개의 평가 척도를 결합하는 합리적인 방법은
- Satisficing Metric : 24시간 이내에 1번(Threshold) 이상 거짓 양성이 발생하지 않는다는 조건 하에
- Optimizing Metric : True Positive 최대화하는 것이다.
N 개의 Metric 기준이 있을 때, 1개의 Optimizing Metric 최적화 지표를 설정하고, N-1개의 Satisficing Metric 조건 지표로 설정해 모델을 평가할 수 있다.
Train/dev/test distributions
학습 개발 테스트 세트를 설정하는 방법에 대해서 살펴보자.
Dev set 개발 세트
- development set, hold cross validation set 교차 검증 세트라고도 불린다.
- 다양한 아이디어를 개발 세트를 통해 검증, 평가하고 선택한다. 이 과정을 개발 세트 성능이 만족스러울 때까지 반복한 뒤, Test set 를 이용해 평가한다.
- 향후 현실에서 얻을 수 있고, 좋은 성과를 내는 중요한 데이터에 대해 개발, 시험 세트를 설정한다.
분류기를 개발해 다양한 지역에서 작동시킨다고 가정해보자.
| Regions | Set |
|---|---|
| US, UK, Other Europe, South America | dev |
| India, China, Other Asia, Austrailia | Test |
위의 분류는 개발 세트와 시험 세트가 다른 분포에서 만들어지므로 나쁜 예에 해당한다.
향후 현실에서 얻을 수 있고, 좋은 성과를 낼 것이라고 예상하는 데이터를 무작위로 섞은 뒤 (동일한 분포에서) 개발 세트와 시험 세트를 설정한다.
Size of the dev and test sets
Rule of Thumb
데이터가 부족했을 때(100-10000)는 훈련:시험 = 7:3 or 훈련:개발:시험 = 6:2:2 로 나누는 경향이 있었다.
Size of the dev and test sets를 결정함에 있어 다음 가이드라인을 따른다.
Set your test set to be big enough to give high confidence in the overall performance of your system.전체 시스템 성능을 대변할 수 있도록 시험세트를 충분히 크게 설정해야한다
최근 머신러닝에서는 훨씬 큰 데이터 세트를 다루기 때문에 훈련:개발:시험=98:1:1 로 나누는 것이 합리적이다. 예를 들어, 1000000 개의 샘플이 있는 경우, 1% 만 해도 10,000 개의 예시로 충분하기 때문이다.
또한 test set의 목적은 최종 모델을 평가하는 것이고, 실제 머신러닝 프로젝트에서는 train/dev set만으로 모델 학습/검증 하기도 한다. (사람들이 dev set을 test로 칭함)
When to change dev/test sets and metrics?
앞서 살펴본바, dev set개발세트와 Single (real) number evaluation metric 하나의 정량적 평가기준 을 정하는 것이 중요하지만, 프로젝트 진행 중 잘못 설정된 것을 알게된 경우에는 어떻게 해야할까?
-
고양이 분류기 예를 통해 살펴보자. 평가 Metric 기준에 의하면 A가 나아보이지만, 모종의 이유로 알고리즘 A가 야한 사진을 분류했다고 가정해보자.
-
평가 Metric : Classification Error
- Algorithm A : 3 % Error
- Algorithm B : 5 % Error
-
평가 척도가 올바른 방향을 제시하지 않는다
Dev + Metric ⇒ A vs Users ⇒ B
- 알고리즘 A를 사용하면 유저들은 더 많은 고양이 사진을 볼 수 있을 것이지만, 유저들에게 야한 사진도 보여주게 된다. 이런 경우 useless한 알고리즘이 된다.
- 반면, 알고리즘 B를 사용하면 더 많은 사진을 잘못 분류하게 되지만, 야한 사진을 분류하지는 않는다. 유저에게도 회사에게도 B가 더 나은 선택이 된다.
-
평가 척도 수정
원하지 않는 결과에 가중치를 크게 부여해 손실값을 나쁘게 만든다.구분 Metric 평가 척도 수정 기존 야한 사진, 야하지 않은 사진도 동등하게 본다는 문제점이 있다. 야한 사진의 경우 label이 제대로 붙여지도록 가중항 = {0 or 야한 사진:1} 을 추가해, 야한 사진을 분류했을 때 오차가 훨씬 커지게 만든다. 오차가 0과 1사이 값을 가지도록 정규화항을 로 수정한다. 실제 이 가중치 항을 구현하기 위해서는 dev/test set안의 야한사진(1)을 확인해야한다. 수정 후 * 는 indicator로 {}안의 식이 참이 되는 예시의 계수를 센다.
-
-
고양이 분류기 예를 통해 살펴보자. 평가 Metric 기준에 의하면 A가 나아보이지만, 모종의 이유로 알고리즘 B가 상품에 적용시켰을 때 더 좋은 성능을 보일 수 있다.
- 평가 Metric : Classification Error
- Algorithm A : 3 % Error
- Algorithm B : 5 % Error
-
평가 척도와 dev/test set가 올바른 방향을 제시하지 않는다
Dev + Metric ⇒ A vs Users ⇒ B- 고화질의 이미지를 사용해 모델을 학습시키지만 어플리케이션에서는 불투명한 저화질의 이미지를 사용한 경우에 B가 더 좋은 성능을 낸 것일 수도 있다.
-
알고리즘이 좋은 성능을 내야하는 데이터를 포함하도록 dev/test set을 변경한다.
- 평가 Metric : Classification Error
If doing well on your metric + dev/test set does not correspond to doing well on your application, change your metric and/or dev/test set.
dev set개발세트와Single (real) number evaluation metric하나의 정량적 평가기준을 정의하고, Metric을 기준으로 좋은 성능의 모델을 구현한다.그러나, 실제 어플리케이션에서 좋은 결과를 얻지 못하는 경우 신속하게 변경해야한다.
- Metric이 모델에 있어 가장 중요한 것을 측정하지 못하는 경우, Metric 변경
- 실제 대상 데이터 분포가 dev/test set 분포와 다른 경우, dev/test set을 실제에서 사용되는 데이터로 변경
3 - Comparing to human level performance
Why human-level performance?
최근 몇 년 동안 머신러닝 연구자들이 머신러닝의 성능을 Human-level Performance와 비교해왔다. 이는 더 좋은 성능의 알고리즘이 개발되어 다양한 분야에 적용될 수 있고, 특히 사람이 할 수 있는 것에 대해서 머신러닝 시스템을 구축하는 것이 더 효율적이기 때문이다. 따라서 사람 수준의 성능과 비교하고 그에 도전하는 것이 자연스러워졌다. 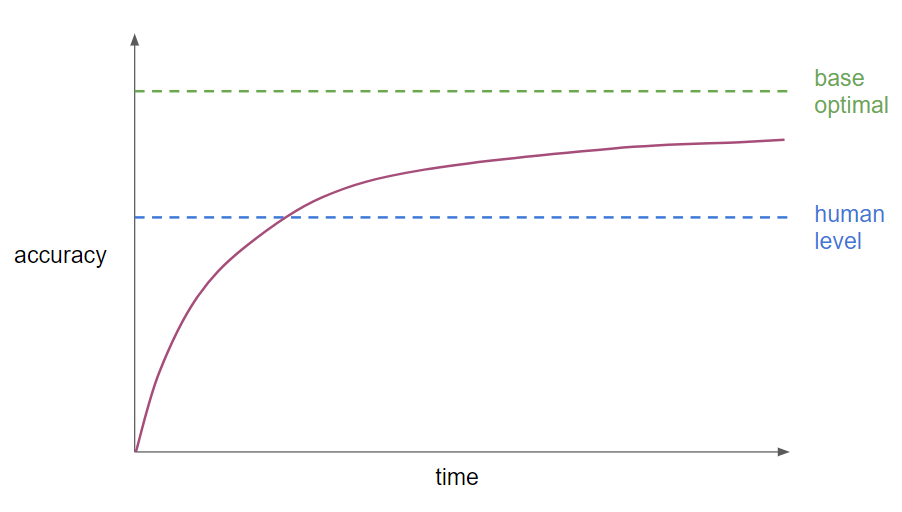
- Base Optimal 베이지안 최적 오차
- 모델의 이론상 가능한 최저의 오차 값
- x 에서 y로의 이론적으로 최적의 함수
- 과대적합이 되지 않는 이상 이 값을 뛰어 넘을 수 없다.
- 머신러닝 모델들이 사람 성능 Human level Performance 성능을 넘기 전까지는 아주 빠른 속도로 정확도가 상승해 빠르게 뛰어 넘지만, 사람 성능을 넘어서 베이지안 최적 오차까지 줄이는 데는 많은 시간이 소요된다.
- 대부분의 경우 Human level performance 사람 수준의 오차와 베이지안 최적오차간 차이가 크지 않다.
- 사람 수준의 성능이 나오지 않을 때 사용하는 특정 성능 향상 기법을 쓸 수 없기 때문이다.
When your model is worse than humans, you can
- Get labeled data from human
사람이 라벨링한 데이터를 더 수집- Gain insight from manual error analysis
수동 오차 분석 - 알고리즘이 틀린 예시를 사람들이 보는 것- Better analysis of Bias/Variance
Avoidable bias
고양이 분류기 예시를 통해 살펴보자.
| 구분 | (1) | (2) |
|---|---|---|
| Human Error | 1% | 7.5% |
| Training Error | 8% | 8% |
| Dev Error | 10% | 10% |
-
(1) 사람은 거의 정확하게 판별한다고 가정
-
train set performance 8% 와 human-level performance 1%의 큰 차이는 알고리즘이 train set에 충분히 들어맞지 않았음을 의미한다.
-
분산과 편향 문제에서 편향을 줄이는 데 집중할 것이다.
Focus on Reducing Bias더 큰 신경망을 학습시키거나, 경사하강법을 더 오래 실행해서 train set에서 더 좋은 성능을 만들고자할 것.
-
-
(2) 사진이 흐려 사람조차도 정확히 구분할 수 없다 가정
-
train set performance 8% 는 human-level performance 7.5%에 약간 못 미치니까 train set에서 좋은 성능을 보인다.
-
분산과 편향 문제에서 분산을 줄이는 데 집중할 것이다.
Focus on Reducing Variance정규화를 통해 train error 와 dev error 차이를 줄이고자 할 것.
-
Human-level error as a proxy for Bayes Optimal error
사람 수준의 오차와 베이지안 최적오차는 차이가 많이 나지 않는 것으로 가정하고, 사람 수준의 오차를 베이지안 최적오차로 추정한다.Avoidable bias 회피가능편향
- 베이지안 최적오차(Human level error)와 훈련오차의 차이
- 더 이상 낮아 질 수 없는 편향 또는 최소 오차가 있다는 뜻이다.
- 회피가능편향 값이 클 수록 아직 모델이 충분히 훈련이 안된 것이다. 더 큰 신경망이나 경사하강법을 더 오래 실행해서 회피 가능 편향을 줄이도록 한다.
Variance
- 훈련오차와 개발오차의 차이
- 개발 세트로 모델을 얼만큼 일반화 할 수 있는 지를 의미하고, 차이가 적을 수록 새로운 데이터를 잘 예측한다.
Understanding human-level performance
앞서 현재, 미래에 어떤 함수가 달성할 수 있는 최적의 오차값을 의미하는 베이지안 오차의 추정치로 사람 수준의 오차를 사용했다. Human level performance 라는 용어는 논문에서 큰 뜻 없이 사용되기도 하는데, 사람 수준의 성능의 정의를 이용해 머신러닝 프로젝트를 발전시켜보자.
Medical image classification 예시를 살펴보자.
| 구분 | Error |
|---|---|
| Typical Human | 3% |
| Typical doctor | 1% |
| Experience doctor | 0.7% |
| Team of experience doctors | 0.5% |
Human-level error 사람 수준의 오차는 어떻게 정의할까?
- Bayes Optimal Error ≤ 0.5%
얼마나 더 나은 결과가 가능할지는 알 수 없지만, 숙련도 높은 전문의 다수의 오차를 베이지안 최적의 오차로 추정할 수 있다. Bayes Optimal Error의 최댓값이 0.5%, 최적의 오차 Bayes Optimal Error가 0.5%보다 크지 않을 것이라는 것은 알 수 있다.
0.5%를 베이지안 최적오차로 추정하게 된다면, 일반적인 진료 시스템에 사용하기 위해, 일반 의사의 오차 1%를 사람 수준의 오차(Estimate of Bayes Optimal Error, 베이지안 오차의 추정치)로 볼 수 있다. 또한 사람 수준의 오차가 훈련 오차보다 더 높지 않도록 설정하는 것을 주의해야한다.
이처럼 사람 수준의 오차의 추정치를 토대로 베이지안 최적오차를 추정할 수 있고, 사람 수준의 오차를 정의함으로써 머신러닝이 학습하게될 목적을 명확히 할 수 있게 된다.
| 구분 | (1) | (2) | (3) |
|---|---|---|---|
| Human (proxy for Bayes Error) | 1% / 0.7% / 0.5% | 1% / 0.7% / 0.5% | 0.5% |
| Training Error | 5% | 1% | 0.7% |
| Dev Error | 6% | 5% | 0.8% |
(1) Focus on Avoidable bias
(2) Focus on Variance
(3) Avoidable bias = 0.2%, Variance= 0.1% : 사람수준의 오차에 가까워질수록 편향과 분산 중 무엇에 중점을 둘 지 결정하기 어렵다.
베이지안 오차를 갖고 있는 문제(베이지안 오차가 0이 아닌 경우), Avoidable Bias(Diff on Human vs Train) 회피가능 편향 이나, Variance (Diff on Train vs Dev) 분산의 추정치를 통해 알고리즘의 편향을 줄일지, 분산을 줄일지 결정할 수 있다.
Surpassing human-level performance
머신러닝이 사람 수준의 성능을 뛰어넘는 문제들
- Online Advertising
- Product Recommendations
- Logistics (predicting transit time)
- Loan approvals 대출 승인
이러한 문제들의 특징
- Structured data 구조화된 데이터이다. Not natural percetption task 컴퓨터비전, 음성인식, 자연어 처리 문제가 아니다. (딥러닝의 발전으로 일부 Natural Perception task에서도 컴퓨터가 사람의 성능을 뛰어넘은 사례가 있기도 하다.)
- Huge amount of data 방대한 양의 데이터를 사용한다.
즉, 컴퓨터가 사람보다 더 많은 구조화된 정보를 가지고 통계적 패턴을 쉽게 찾는다는 것이다.
Improving your model performance
앞서 학습한 내용을 바탕으로 가이드라인을 정리해보면 다음과 같다.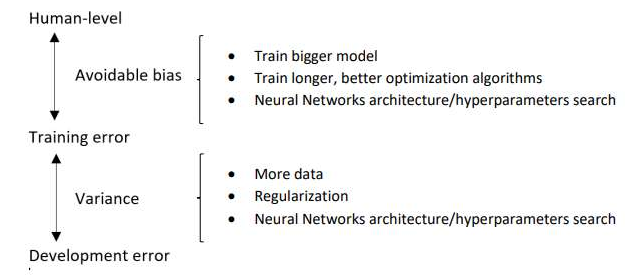
2 fundamental assumptions of supervised learning
지도학습 알고리즘이 잘 작동할 수 있도록
- Fit the training set pretty well ⇒ Low Avoidable Bias
- Train bigger model
더 큰 모델로 훈련- Train longer/better optimization algorithms
더 오랫동안 모멘텀, RMSprop, Adam과 같은 더 나은 최적화 알고리즘을 사용- NN architecture/hyperparameters search
더 나은 신경망 구조나 하이퍼파라미터 값을 찾는다. 활성함수를 변경, 은닉층 수 변경, RNN/CNN
- Traing set performance generalize pretty well to the dev/test set ⇒ Low Variance
- More data
더 많은 데이터 사용- Regularization
L2정규화, 드롭아웃, Data Augumentation,- NN architecture/hyperparameters search
4 - Error Analysis
Carrying Out Error Analysis
- Error Analysis 오차 분석
- 오차를 줄이는 것에 대한 비용을 알아보고 기존보다 얼마나 성능을 높일 수 있는 지 그 상한
ceiling을 파악할 수 있다.- dev 세트에서 잘못된 결과가 나온 것들 중 가장 비중을 많이 차지하는 부분(원인)을 찾아, 해당 오류를 고치는 것이 가장 효율적인 방법이다.
-
오차분석에서 하나의 아이디어 평가
<고양이 분류기 예시 A - misclassified images>
dev set accuracy 가 90%로, dev set error가 10%였다고 가정해보자. 알고리즘이 범하고 있는 실수를 직접 파악해보니, 몇 종류의 개를 고양이로 잘못 분류한 것을 확인했다. 이 경우 개 사진에 더 좋은 성능을 내도록, 더 많은 개 사진을 모아 개 사진에만 특정된 특징을 필터링 되도록 만들 수 있다. 하지만 개 그림에 대한 실수를 줄이기 위한 문제에 초점을 두고 추가 프로젝트를 진행하는 것이 가치있는 일일까?- 오차 분석을 위해 잘못 라벨링된 개발 세트의 예시들 중 실제 개 사진을 세본다. Get ~100 mislabeled dev set examples & count up how many are dogs
- (1) 100개중 5개인 경우
개 문제를 해결하더라도 5개만 정답으로 바뀐다. 즉, 기존 오차 10%에 대해서 0.5%만큼 감소해서 9.5%로 바뀌는 것이다.
- (2) 100개중 50개인 경우
개 문제를 해결하면 50개가 정답으로 바뀐다. 즉, 기존 오차 10%에 대해서 5%만큼 감소해서 5%로 바뀌는 것이다.
- 오차 분석을 위해 잘못 라벨링된 개발 세트의 예시들 중 실제 개 사진을 세본다. Get ~100 mislabeled dev set examples & count up how many are dogs
-
오차 분석에서 동시에 여러 아이디어 평가
<고양이 분류기 예시 B - misclassified images>
개를 고양이로 잘못 분류, great cats(사자,표범 등 고양이와 비슷하게 생긴 동물) 고양이로 잘못 분류, Blurry image에 대해 잘못 분류Image Dog Great Cat Blurry Comments 1 v Unusual pitbull color 2 v 3 v v Lion; picture taken at zoo on rainy day 4 v Panther behind tree …. … … … … % of total 8% 43% 61% 각각의 원인들이 전체 오분류에서 해당하는 비율을 통해서 알고리즘 개선을 위해 시도할만한 선택지를 파악할 수 있다.
Cleaning Up Incorrectly Labeled Data
지도학습 데이터는 입력값 와 출력 label 로 이루어진다.
일부 데이터에서 잘못 라벨링된 사례를 발견했다고 가정해보자. 이들을 옳게 고치는 것이 가치있는 일일까? 잘못 라벨링 된 데이터의 처리를 훈련, 개발, 시험 세트의 경우로 나눠 알아보자.
- Training set 훈련 세트
DL Algorithms are quite robust torandom errorsin the training set.
- 훈련세트는 무작위 오차에 대해 다소 둔감하다. 잘못 라벨링 된 데이터의 학습 결과 오차가 무작위 오차와 크게 차이 나지 않을 경우 수정하지 않아도 된다.
- 그러나 무작위 오차가 아닌
Systemmetic Error시스템적인 오류(같은 라벨에 대해서 계속 오분류 하는 것)는 덜 둔감하기 때문에 문제가 될 수 있다.
- Dev/Test set 개발 및 시험 세트
- 개발 및 시험 세트는 Error Analysis 오차 분석시 잘못 라벨링으로 인한 오차의 비율을 구하고, 전체 오차에서 얼만큼 차지하는지 살펴본 뒤 결정한다.
- 개발 과 시험 세트의 분포는 같아야하기 때문에 동시에 살펴본다.
-
Error Analysis on Dev/Test set
이전에 살펴본 misclassified images 예에 Incorrectly labeled를 추가해 살펴보자.
Error A B Overall Dev set error 10% 2% Errors due to incorrect labels 6% 0.6% Errors due to other causes 9.4% 1.4% dev set에서 잘못된 결과가 나온 것들을 살펴보고, B와 같이 알고리즘을 평가하는데 큰 영향을 미치는 경우 잘못 라벨링된 데이터를 수정한다.
Build your First System Quickly, then Iterate
새로운 머신러닝 어플리케이션을 만들때는 우선 시스템을 빨리 만든 뒤에 다시 검토한다
- 훈련, 개발 및 시험 세트를 만들고 학습 목표를 정한다.
- 빠르게 모델링한다. (시스템을 구성한다)
- 훈련 세트를 통해 모델을 학습 시키고, 개발 및 시험 세트로 평가한다.
- 편향-분산 분석 및 오차 분석을 통해 모델의 성능을 향상시킨다.
5 - Mismatched Training and Dev/Test Set
Train과 Dev/Test Set의 불일치 문제를 핸들링할 수 있는 방법에 대해 살펴본다.
Training and Testing on Different Distributions
딥러닝은 학습 데이터가 많이 필요하기 때문에 데이터 수집과 동시에 훈련세트에 집어넣다보니, 학습 세트와 개발 및 시험 세트의 분포가 달라지는 경우가 생길 수 있다. 이렇게 분포가 서로 다른 데이터가 추가 되었을 때, 적용할 수 있는 2가지 방법을 살펴본다.
분포가 서로 다른 데이터가 추가 되었을 때, 적용할 수 있는 2가지 방법
- 새로 얻은 데이터를 기존의 데이터와 합쳐서 무작위로 섞어서 다시 train, dev, test set 을 만드는 방법
- 같은 분포에서 얻어졌기 때문에 다루기가 쉽다.
- 새로 얻어진 데이터에서 좋은 결과를 원한다면, 새로운 데이터의 비중이 월등히 적기 때문에, 원하는 성능을 얻기가 어렵다.
- 새로 얻어진 데이터의 일부를 train set에 섞은 다음, dev/test set은 모두 새로운 데이터로 만드는 방법
- 새로운 데이터에서 원하는 성능을 얻을 수 있다. train과 dev/test의 분포가 달라진다는 단점이 있지만, 장기적으로 더 나은 성능을 얻을 수 있다.
- 새로 얻은 데이터를 전부 dev/test set에 포함할 때보다 Train set의 크기가 훨씬 커진다.
-
Speech Recognition Example
Speech Activated rearview mirror 말로 백미러를 활성화시키는 시스템을 구축하는 예를 살펴보자.구 분 Data size Resize Training 다른 음성인식 문제에서 사용했던 데이터
Purchased Data (X,y), Smart Speaker Control, Voice Keyboard500,000 510,000 Test/Dev 실제 상품이 좋은 성능을 보여야하는 데이터
Speech Activated rearview mirror20,000 10,000 Train vs Dev/Test set 데이터의 분포가 다른 경우, 위와 같이 새로운 데이터 일부(10,000)를 Train set에 포함시키고 나머지 데이터 (10,000)를 1:1로 나눠 Dev/Test set을 구성하는 것이다.
Bias and Variance with Mismatched Data Distributions
Bias and Variance 편향-분산 문제를 분석하는 방법에서 둘을 구별하는 데 어려움이 있다.
(1) 일반화의 부족으로 인한 오차인지
(2) Train set의 분포와 Dev set의 분포 차이로 인한 오차인지
-
Human level error가 0%에 가깝다고 가정하,
알고리즘 테스트 결과가Train error 1%, Dev error 10%-
Dev set이 Train set과 동일한 분포인 경우, 분산에 문제(Diff on Train and Dev error)가 있다고 할 수 있다.
-
Dev set이 Train set과 다른 분포인 경우, 위와 같은 결론을 내릴 수 없다. Dev set에는 문제가 없을 것이다. (예를 들어, Train은 고해상도의 이미지와 같이 쉬운 케이스이고, Dev가 더 어려운 케이스에 해당한다. )
-
9%의 오차 증가가 어느 원인에 기인한 것인지 구별이 어렵다.
-
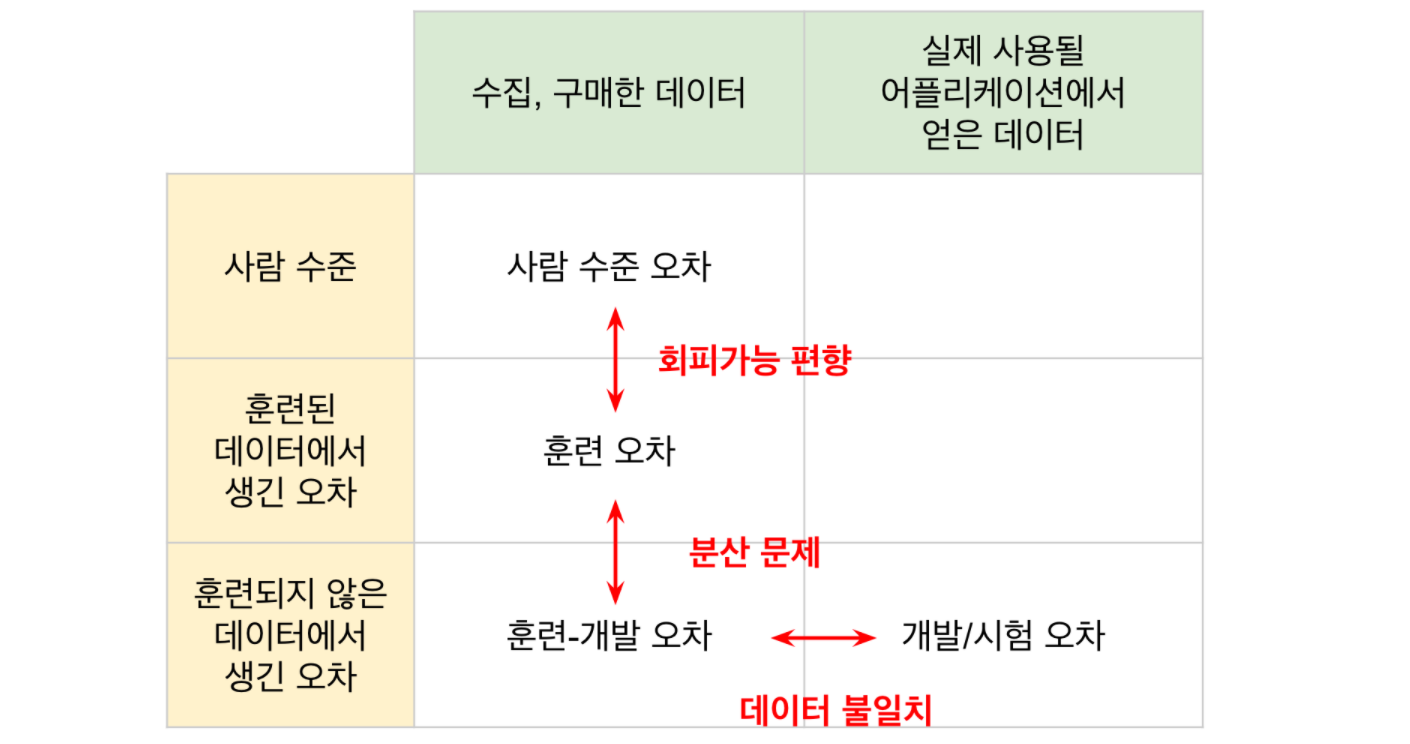
위와 같이 구별이 어려운 상황때문에 새로운 데이터를 정의한다.
Training-development set 훈련-개발 세트
Train과 동일한 분포를 가지지만 Training 학습에는 사용하지 않는 데이터
Train의 일부를 떼어내Bias and Variance 편향-분산 문제를 알아보기 위해 사용한다.
Train-dev set error VS Train error
- Training-development set훈련-개발 세트의 오차가 Train set의 오차와 크게 차이가 없다면,
(1) 일반화의 부족으로 인한 오차 Variance 분산문제로 볼 수 있다.- Training-development set훈련-개발 세트의 오차가 Train set의 오차와 차이가 크다면,
(2) Train set의 분포와 Dev set의 분포 차이문제입니다.
Addressing Data Mismatch
Train set과 Dev/Test set간의 데이터 분포가 다른 경우, 체계적인 해결법은 없지만 아래의 방법들을 시도해볼 수 있다.
- (1) Carry out manual Error Analysis to understand difference between training and dev/test sets
오차분석을 통해 train sets와 dev/test sets 간의 차이를 파악한다. test sets의 과대적합을 피하기 위해 dev sets를 봐야한다.
- (2) Making training data more similar; or collect more data similar to dev/test sets
dev set과 비슷한 데이터를 수집하여 train set을 구성한다.
Artificial data synthesis
Artificial data synthesis 인공적 데이터 합성 방법으로 (2) Making training data more similar to dev/test sets dev set과 비슷한 train data를 더 빠르게 만들 수 있다. 두 가지 예시를 통해 살펴보자.
-
Trigger word Recognition System
bunch of low noise voice recordings car noise
(or other audio effects)Synthesized in-car audio 10,000hrs 1hr Overfit to 1hr noise
Original의 1만 시간에 추가하기 위해 Noise를 1만번 반복하게 된다. 이런 경우, 학습 알고리즘이 일부의 합성된 Noise에 과대적합 될 수 있는 위험이 있다.10,000hrs 10,000hrs 학습 알고리즘이 더 나은 성능을 가지도록 할 것이다. -
Car Recognition System
graphic car images Synthesized car images 20 kinds of cars Overfit to synthesized graphic images
실제 가능한 경우보다 굉장히 적은 경우 train에 포함된 small subset 의 합성 자동차 이미지에만 과적합될 위험이 있다.
인공적 데이터 합성으로 dev set과 유사한 train data를 더 빠르게 만들 수 있지만, 모델이 작은 부분에 대해서만 과적합될 위험이 있으므로 주의해야한다.
6 - Learning from Multiple Tasks
Transfer Learning
딥러닝에서 가장 강력한 아이디어 중 하나는 전이학습 : 신경망이 하나의 작업에 대해 학습을 이미 한 경우, 그 지식을 다른 종류의 작업에 이용할 수 있다는 것이다.
TRANSFER TASK A ⇒ B
전이학습은 작업 A로부터 학습하고, 작업 B로 전이하여 순차적인 과정을 거친다. 기존에 학습된 지식A을 데이터가 적은 문제B에 적용시킬수 있다는 장점이 있다. 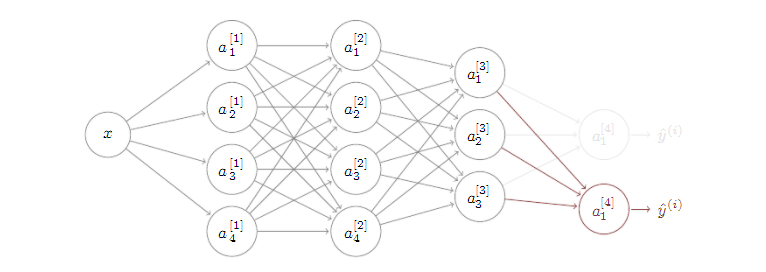 지도학습의 경우, 전이학습의 방법은 기존 학습된 모델에서 마지막 층을 제거한 후, 분류 하고자 하는 새로운 문제에 적합한 층을 연결시켜주고 학습한다.
지도학습의 경우, 전이학습의 방법은 기존 학습된 모델에서 마지막 층을 제거한 후, 분류 하고자 하는 새로운 문제에 적합한 층을 연결시켜주고 학습한다.
- 풀고자 하는 문제B의 데이터가 많을 경우, 모든 층을 재훈련한다.
- 풀고자 하는 문제B의 데이터가 거의 없을 경우, 새로 추가한 마지막 층만 학습한다.
그렇다면 어떤 경우에 Transfer Learning전이학습을 자주 활용할까?
- 전이 가능한 문제 A의 데이터는 많은데 전이 하려고 하는 문제B의 데이터가 정말 적을 때
- A,B의 입력 데이터가 같고, A의 저레벨 특성이 문제 B를 해결하는데 도움이 될 때
- 이미지 : 저레벨의 특성인 윤곽이나 물체의 일부분을 탐지하는 지식이 방사선의학에 적용될 수 있다.
- 음성 :
### Multi-task Learning
전이학습과는 반대로 Multi-task learning 다중 작업 학습은 한 신경망이 여러 작업을 동시에 할 수 있도록 학습한다.
-
Multi-Class Classification - Simplified autonomous driving example
자율주행자동차를 만드는 상황, 보행자, 자동차, 정지표시판, 신호등을 판별해야한다.
이 경우,One image can have multiple labels하나의 이미지가 여러 개의 레이블을 가진다.train set 레이블을 horizontally 가로로 쌓아 올리면 다음과 같이 표현할 수 있다.
의 = 4개의 물체를 포함한 이미지를 인식하는 하나의 신경망을 나타내면 다음과 같다. (출력층의 4개의 node 다중 분류 문제)
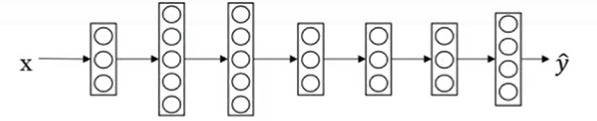
4가지 작업에 대해 하나의 신경망을 학습 vs 독립적인 4개의 신경망을 개별 학습
- 두 가지를 시도할 수 있지만, 신경망 초기 특성들은 여러 물체에 대해서 공유 가능하기 때문에, 전자가 후자보다 더 좋은 성능을 보이고, 효율적이다.
(신호등, 자동차, 보행자를 인식하는 것이 정지 표지판을 인식하는 데 도움이 되는 비슷한 도로에 관련된 특성을 가지고 있기 때문이다.)
- 두 가지를 시도할 수 있지만, 신경망 초기 특성들은 여러 물체에 대해서 공유 가능하기 때문에, 전자가 후자보다 더 좋은 성능을 보이고, 효율적이다.
그렇다면 어떤 경우에 Multi-task learning 다중 작업 학습을 자주 사용할까?
- Training on a set of tasks that could benefit from having shared lower-level features
여러 문제들의 하나의 저레벨 특성을 공유할 때
- Usually : Amound of data you have for each task is quite similar 데이터 양이 비슷할 때 (항상 만족하는 것은 아님)
- 전이학습의 경우 A: 1000000 ⇒ B:1000
- 다중학습의 경우 각각 1000
- 은 1000개의 샘플로 학습할 수 있고, 나머지 99개의 작업 학습에서 99000개의 샘플이 제공하는 지식으로 학습할 수 있다.
- 하지만 특정 하나의 작업에만 초점을 두고 보면, 다중 작업에서 큰 효과를 얻기 위해서는 그 외의 다른 작업들이 특정 작업에 비해 훨씬 많은 데이터를 가져야한다. (항상 만족하는 것이 아닌 이유)
- Can train a big enough nn to do well on all the tasks
거대한 작업 세트들을 하나의 큰 신경망으로 한번에 학습 시키려고 할 때
Transfer Learning VS Multi-task Learning
평균적으로 다중 작업 학습보다는 전이학습이 더 많이 쓰인다.
- 전이학습 : 적은 데이터를 가지는 문제가 있을 때, 많은 데이터를 가지고 있는 문제와 연관시켜 이미 학습한 것들을 새로운 문제에 전이시켜 학습한다.
- 다중작업학습 : 사용하고자 하는 거대한 작업 세트가 있을 때, 이 모든 작업들을 동시에 훈련하고자 할 때 사용한다.(ex Computer Vision)
7 - End-to-end Deep Learning
What is End-to-end Deep Learning?
최근 딥러닝 분야에 있었던 가장 큰 발전
End-to-End Deep Learning
자료처리 시스템, 학습시스템에서 여러 단계의 필요한 처리과정을 재배치하고 단 하나의 신경망을 이용해 한번에 처리한다. 즉, 데이터만 입력하고 원하는 목적을 학습시키는 것이다. 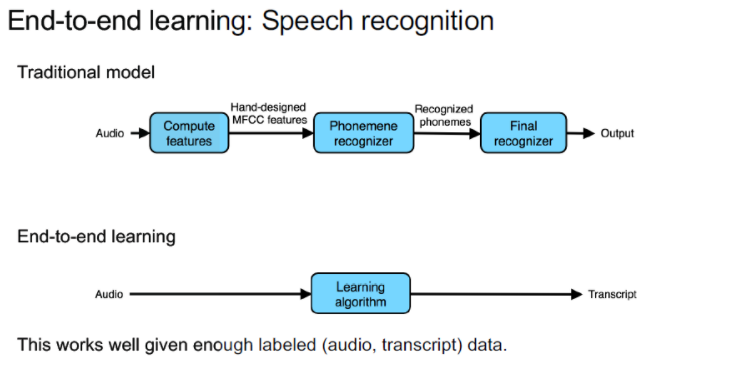
Whether to use End-to-end Deep Learning
- Pros
- Let the data speak
사람의 선입견에 영향을 덜 받아, 데이터 그 자체의 특성이 잘 나타난다.- 음성 인식 문제에서 Phonemene 음소의 개념을 적용할 필요 없이, 알고리즘이 원하는 표현법을 알아서 학습하게 한다.
- Less hand-designing of components needed
기존의 처리 파이프라인 중 일부를 대체해 시스템을 굉장히 단순화 할 수 있다.
- Let the data speak
- Cons end-to-end 딥러닝이 만능은 아니다
- May need large amount of data
엄청나게 많은 양의 데이터가 필요하다. - Excludes potentially useful hand-designed components
잠재적으로 유용하게 쓰여질 수 있는 사람이 만드는 중간 요소, 지식을 완전히 배제한다. (특히 데이터가 적을 때 hand-designed 특정 지식을 유용하게 사용할 수 있다.) - 단계를 나눠 학습시키는 것이 효율적인 경우가 있다. 복잡한 문제를 분리하여 각각의 간단한 문제로 바꾸고, 데이터의 정보가 각각의 작업에 더 적합되게 사용될 수 있다면, 문제를 쪼개서 해결하는 것이 더 좋다.
- May need large amount of data
End-to-end 딥러닝을 사용하기 전에
Do you have sufficient data to learn a function of the complexity need to map x to y?
- 항상 어떤 작업을 하려고 하는지, 특히 지도학습에서 x, y 를 어떻게 연관지을 것인지를 생각해야한다.
- 학습하기 위한 데이터가 충분한지도 고려해야한다.
