CB&CF(2), Social Information : Sorec, Soreg, SBPR, TBPR
추천시스템의 종류
1. Collaborative Filtering
□ 메모리 기반 접근 (Neighborhood-based)
□ 모델 기반 접근 Explicit
□ 모델 기반 접근 Implicit, MF-based
□ 모델 기반 접근 Implicit, Metric / Deep learning-based
2. Side Information-based Recommendation
□ 컨텐츠 기반 추천
☑ 컨텐츠 기반 Collaborative Filtering
Side Information : User Social Network
지난 글에 이어 CB와 CF를 결합한 모델에 대해 알아보자. 우선 CB와 CF를 결합한 모델은 사용하는 기존의 유저-아이템, 아이템속성 데이터 이외의 Side Information을 사용한다고 했었다. 이번 글에는 Side-Information 가운데 Social Network를 알아보고자 한다.
Recall : PMF, Probabilistic MF
[Mnih, A., & Salakhutdinov, R. R. (2007). Probabilistic matrix factorization. Advances in neural information processing systems, 20.]
지난 Model-based CF에서 데이터의 확률적 분포를 고려해 개발한 Matrix Factorization인 PMF를 기억하는가. 의 구성요소인 와 또한 평균이 0, 분산이 인 정규분포로 구성되어 있다는 가정들에 따라 각각의 확률 변수를 정의한다.
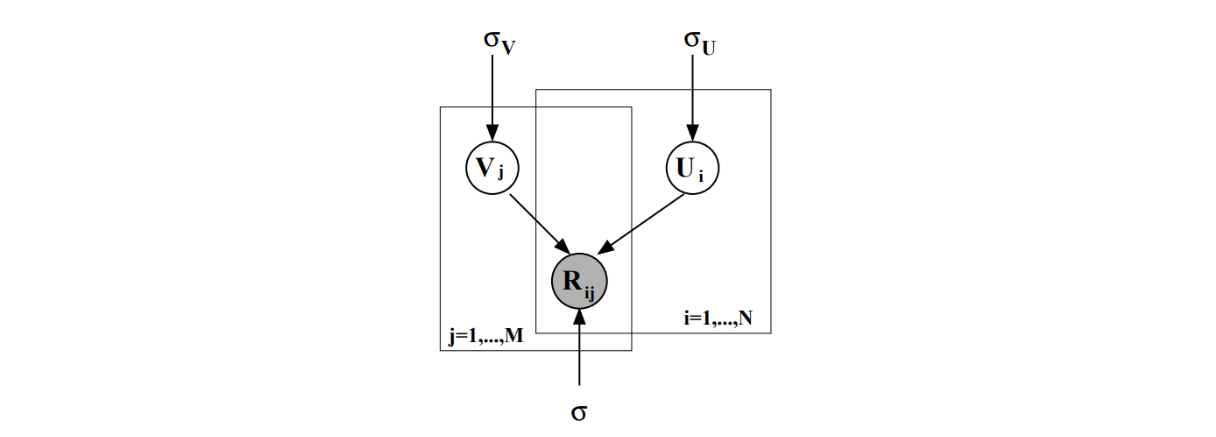
Joint PDF for rating vector R
Joint PDF for user vector U, item vector V
(i)
(ii)
Target Optimization Fuction
Sorec
[Ma, H., Yang, H., Lyu, M. R., & King, I. (2008, October). Sorec: social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM conference on Information and knowledge management (pp. 931-940).]
Sorec(Social Recommenation using Probabilistic Matrix Factorization)은 PMF의 확장 버전과 같은 추천 알고리즘으로, 평점 매트릭스 뿐 아니라, 사회관계 매트릭스도 함께 Factorize 하는 알고리즘이다. 다음 그림을 보면, PMF 다이어그램이 확장된 모습이란 것을 알 수 있다.
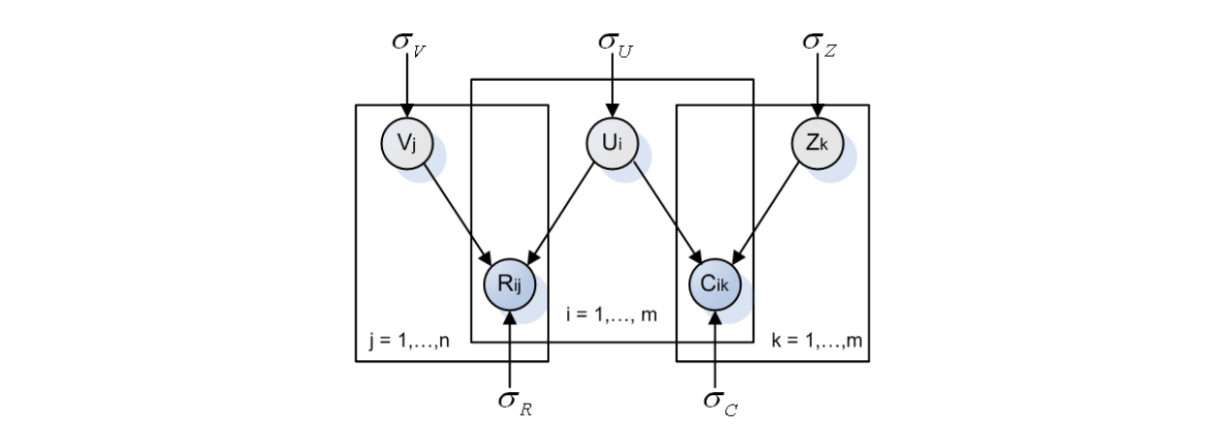
Joint PDF & Posterior Probability for Rating Vector R
-
PDF :
-
Joint PDF & Posterior Probability Network Vector C
-
PDF :
-
Target Optimization Fuction
(PMF)
(Social Info)

MAE를 활용해 다른 알고리즘들과 비교한 최종 결과다. 특히 기반이 되는 모델인 PMF와 비교했을 때, MAE값이 PMF보다 작아진 것을 확인할 수 있다. 결론적으로 Social Information을 데이터에 추가하는 것이 의미가 있다는 것을 확인할 수 있다.
Soreg
[Ma, H., Zhou, D., Liu, C., Lyu, M. R., & King, I. (2011, February). Recommender systems with social regularization. In Proceedings of the fourth ACM international conference on Web search and data mining (pp. 287-296).]
Soreg (Recommender Systems with Social Regularization) 또한 PMF의 확장 버전으로, Sorec에서는 사회관계 데이터를 평점데이터와 동일하게 Factorize 하는 방식으로 다뤘다면, Soreg에서는 사회관계데이터를 Regularize Term으로 활용한다.
Target Optimization Fuction
(PMF)
(Social Info)
유저 와 사이의 관계인 를 통해 유사도가 다른, 즉 취향이 다른 유저들을 다른 가중치로 다루었다는 점이 특징이다. 유사도 계산식은 다음과 같이 Pearson Correlation Coefficient를 통해 계산한다.
Similarity Function
SBPR
[Zhao, T., McAuley, J., & King, I. (2014, November). Leveraging social connections to improve personalized ranking for collaborative filtering. In Proceedings of the 23rd ACM international conference on conference on information and knowledge management (pp. 261-270).]
SBPR은 BPR(Bayesian Personalized Ranking)의 확장된 연구로, BPR에 사회관계 개념을 더해 top-k 순위를 매기는 알고리즘이다. 기본 가정은 '유저는 친구들이 좋아하는 물건에 대해 대체로 높은 랭킹을 부여한다' 이다. 내가 소비한 물건 , 친구가 소비한 물건 , 나도 친구도 소비한적 없는 물건 순으로 높은 랭킹을 차지한다는 가정이다.
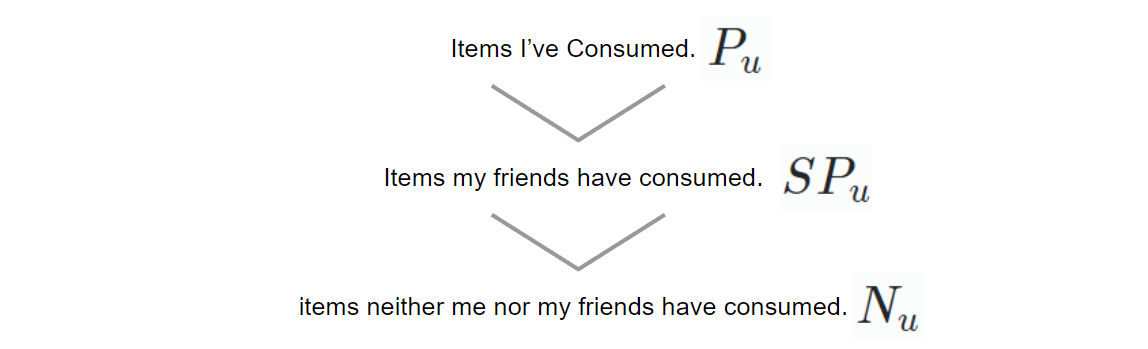
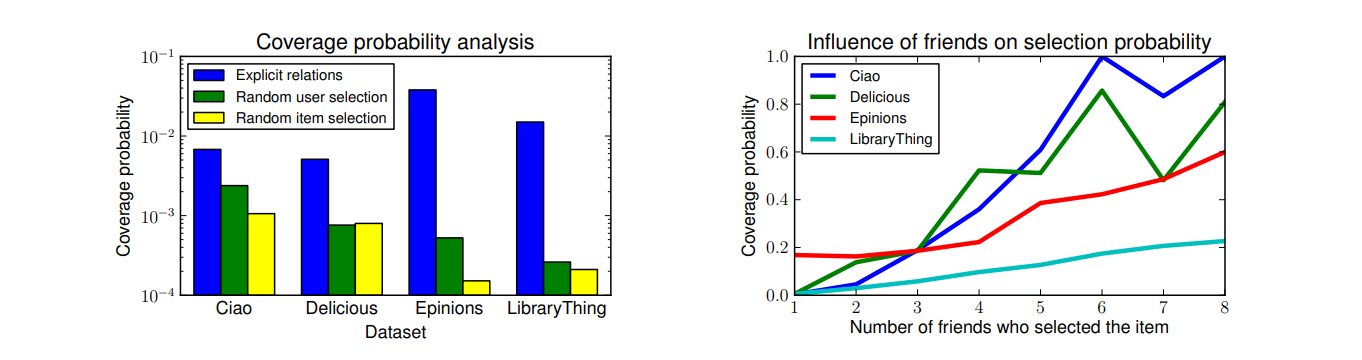
이 가정은 다음과 같은 분석을 통해 어느정도 검증을 한 것이다. 왼쪽 다이어그램의 파란색은 '유저가 선택한 아이템을 친구도 선택했을 경우'의 coverage probability다. 이 파란색이 '유저가 선택한 아이템을 랜덤하게 샘플한 유저도 선택했을 경우' (초록)과 '랜덤하게 샘플한 아이템이 유저가 선택한 것일 경우'(노랑) 보다 압도적으로 높은 것을 확인할 수 있다.
오른쪽 다이어그램의 경우에도, 동시에 같은 아이템을 선택했을 경우에 나도 소비할 확률이 높다는 것을 확인할 수 있다.
Target Optimization Fuction
한편으로 인문학적인 관점으로 보았을 때, 이(1)와 반대의 가정을 할 수도 있다. 친구들이 이미 소비한 물건을 굳이 나도 소비하지 않으려고 하는 관점이다(2).
(1) SBPR-2 :
(2) SBPR-1 :
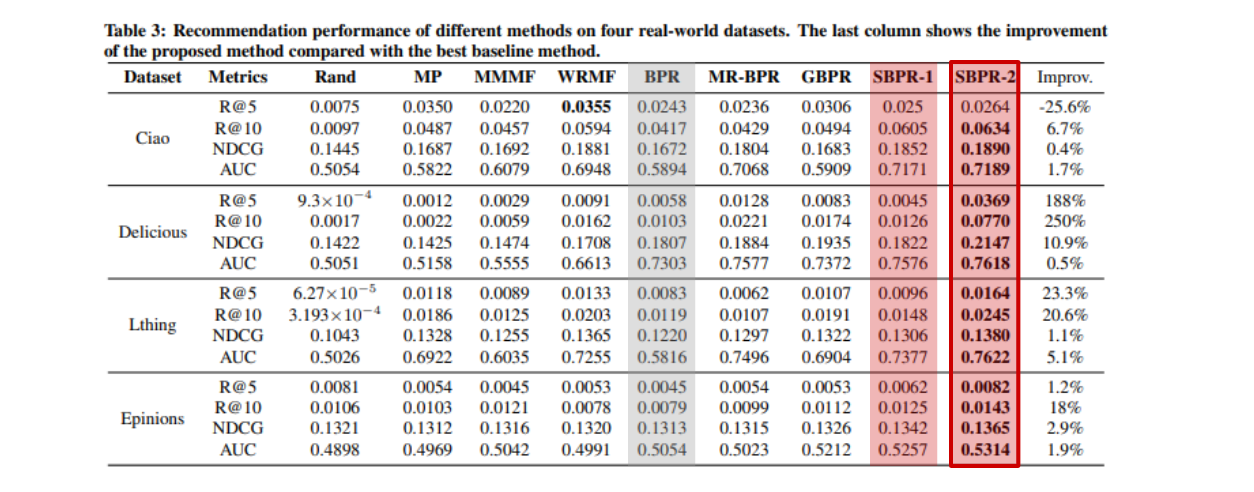
결론적으로 보았을 때, 이 두가지 가정은 모두 BPR보다 성능이 좋았다. 즉 사회관계 데이터를 활용한 것이 유의미한 것이다. 또한 가정(1)과 가정(2)를 비교했을 때에 가정(1), 즉 '친구들이 좋아한 아이템은 나 또한 구매할 확률이 높다'라는 가정이 조금 더 효과적이라는 점도 확인할 수 있다.
TBPR
[Wang, X., Lu, W., Ester, M., Wang, C., & Chen, C. (2016, October). Social recommendation with strong and weak ties. In Proceedings of the 25th ACM international on conference on information and knowledge management (pp. 5-14).]
TBPR역시 BPR을 기반으로 만들어진 알고리즘으로, 독특한 전제를 가지고 있다. 새로운 아이템을 추천할 확률을 높이기 위해서는 사회관계망을 자세히 볼 필요가 있다. 임의의 두 커뮤니티가 있다고 할때, 같은 커뮤니티 안에서는 서로 유사한 내용들이 공유될 것이다.
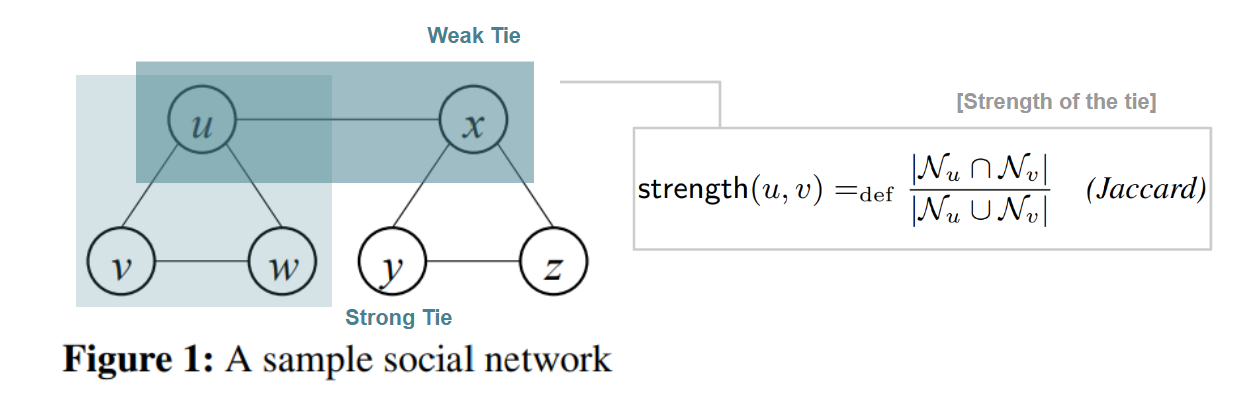
반면 서로다른 커뮤니티를 이어주는 약한 고리, weak tie를 거쳐야만 다른 커뮤니티에서 공유되는 내용이 전달될 것이라는 전제다.
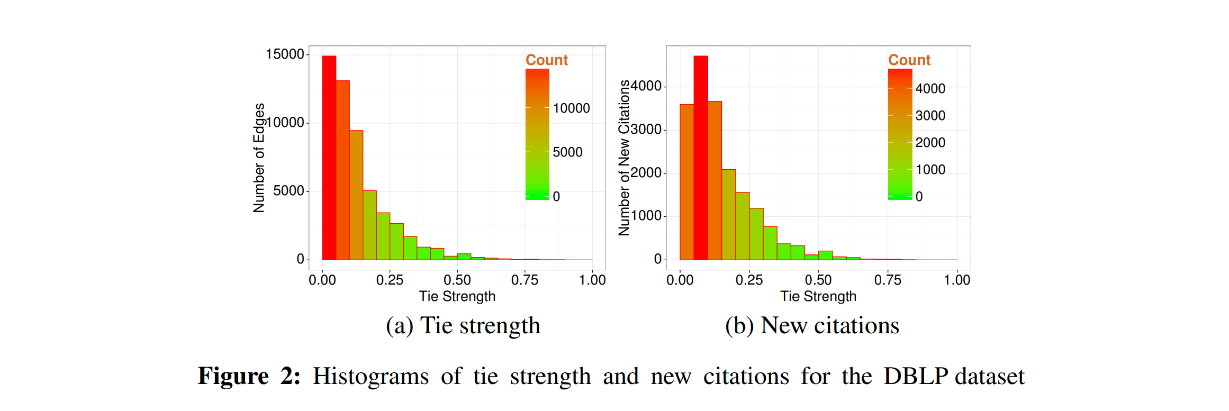
결국 새로운 아이템을 추천하기 위해서는 이 weak tie에 주목해야한다는 취지다. 그렇다면 어떻게 strong, weak tie 를 결정할 수 있을까? Jaccard Similarity를 통해 결정한다.
Target Optimization Fuction
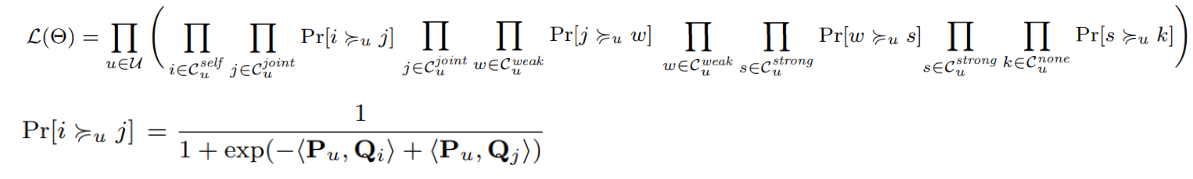
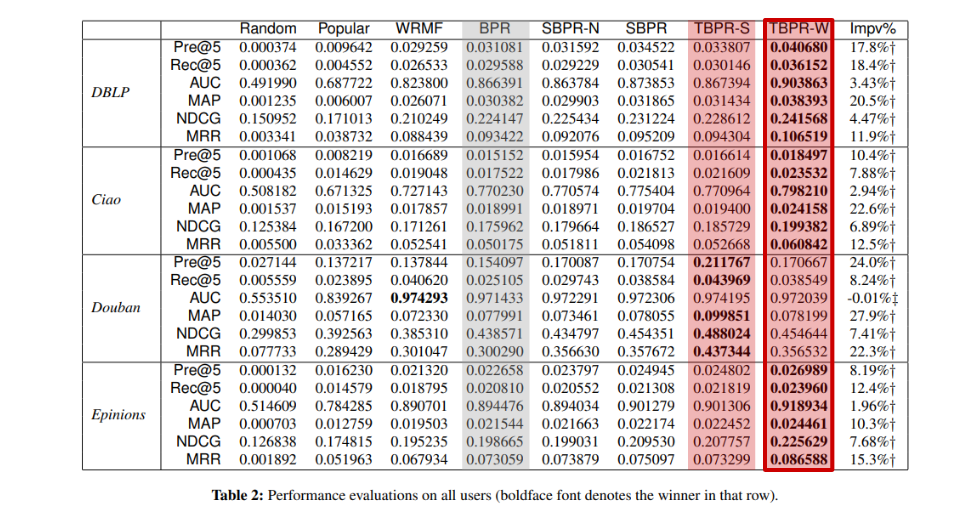
최종 결과다. 혹시 weak tie가 아니라 strong tie를 기반으로 한 추천을 더 선호할 수도 있으니, 반대 가정을 한 모델도 포함시켜 계산을 한 모양이다. 각각 TBPR-S(Strong), TBPR-W(Weak)이다. 결과는 Weak tie의 우승이다.