Collaborative Filtering_메모리 기반
Recommender System
추천시스템의 종류
1. Collaborative Filtering
☑ 메모리 기반 접근 (Neighborhood-based)
□ 모델 기반 접근 Explicit
□ 모델 기반 접근 Implicit, MF-based
□ 모델 기반 접근 Implicit, Metric / Deep learning-based
2. Side Information-based Recommendation
□ 컨텐츠 기반 추천
□ 컨텐츠 기반 Collaborative Filtering
I. Collaborative Filtering
가장 널리 쓰이는 추천 알고리즘의 형태로, 추천을 위해 집단지성을 사용하는 방법이다. 가장 기본이 되는 방법이기에 책, 영화, 상품 등등 다양한 도메인의 e-commerce 기업에서 활발하게 사용되고 있다. 이 알고리즘의 기본 전제는; 유저의 평가(Implicit이든 Explicit이든)를 기반으로 보았을 때, '과거에 유사한 취향을 가지고 있던 유저들은, 앞으로도 유사한 취향을 공유할 것이다.'라는 것. 편의상 Collaborative Filtering을 CF라 하겠다.
II. Neighborhood-based 추천 (메모리 기반 접근)
가장 초기에 등장하고 기본이 되는 CF모델은 Neighborhood 기반 추천이다. Neighborhood를 계산한 데이터를 메모리에 저장하고 진행하기 때문에 메모리 기반 접근이라고도 불린다. 앞서도 언급했듯 아이템을 추천하기 위해서는 유사한 항목을 정의해야한다. 유사함을 측정할 대상은 유저/아이템으로 분류할 수 있다.
- User-based CF : 유사한 유저들은 평점 패턴이 유사하다 → 유저별 구매한 아이템을 기준으로
- Item-based CF : 유사한 아이템들은 유사한 평점 분포를 갖는다 → 아이템별 구매한 유저들을 기준으로
내용의 간결함을 위해 User-based CF위주로 다음 설명을 이어가 본다.
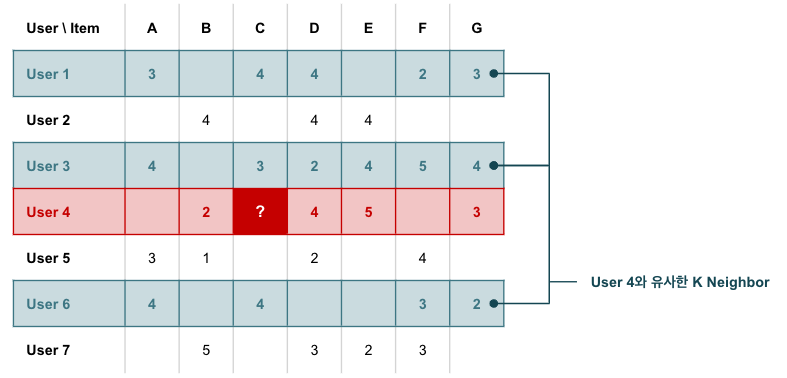
0. User-based CF
User-based CF는 다음과 같은 방식으로 계산한다.유저와, 가 아직 경험하지 못한 임의의 아이템 에 대해 :
- 를 경험했고 & 와 동일한 아이템을 좋아한 유저들의 집합, 이웃들을 구한다.
- 이웃들이 에 대해 매긴 평점의 평균값을 유저의 에 대한 평점에 대한 예측.
- 위 과정을 가 보지 않은 모든 아이템에 대해 수행하고, 최고 평점인 것을 추천한다.
이런 계산을 함에 있어 다음과 같은 점이 전제되어 있다:
- 과거에 유사한 취향을 가지고 있던 유저들은 앞으로도 유사한 취향을 갖게 될 것이다.
- 아이템에 대한 유저의 선호도는 시간이 지나도 일정할 것이다.
유저 개개인의 취향이 변할 수도 있고, 유사한 유저군이 달라질 수 있다는 점을 간과하고 있다는 점은 Neighborhood-based 추천에 내재된 단점이기도 하다. 그렇다면 여기서부터 드는 질문들이 있을 것이다. 유사도는 어떻게 측정하며, 이웃은 몇명까지 고려해야하며, 이웃의 평점으로부터 예측값을 어떻게 도출하는 것일까? 다음 항목에서 알아보자.
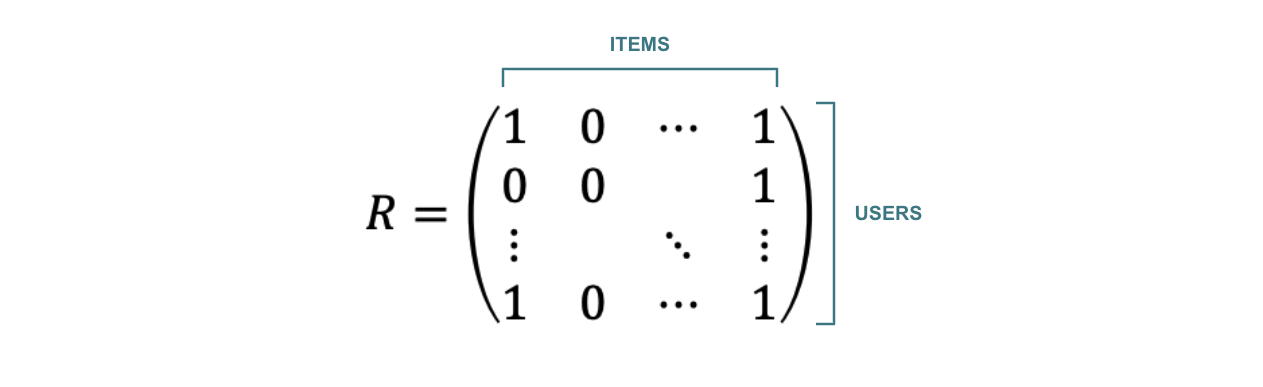
Notation
- = 유저 가 구매한 아이템 세트
- = 아이템 를 구매한 유저 세트
- = 유저 가 구매한 아이템에 대한 이진 표현
- = 아이템 를 구매한 유저에 대한 이진 표현
1-1. 유저 유사도 측정하기, Implicit Feedback
Implicit Feedback은 어쩌고 저쩌고
(1) Euclidean Distance
유저 와 사이의 거리로, 각각의 차집합에 속한 요소의 합이다. 값이 클수록 유사도가 낮다.
단점 : 집합의 크기가 작을수록 값이 작게, 즉 유사도가 높게 나오는 경향이 있어, 절대적인 지표가 되기 어렵다.
(2) Jaccard Similarity
유저 와 사이의 거리로, 유저들이 경험한 아이템의 교집합을 합집합으로 나눈 값이다. 값이 클수록 유사도가 높다. 이 때, 값은 0에서 1사이다.
값이 1일 경우 : 두 유저가 동일한 아이템셋 경험
값이 0일 경우 : 두 유저가 완전히 다른 아이템셋 경험
단점: Jaccard Similarity는 이 이진으로 표현되어있을 때, 즉 Implicit Feedback일때만 사용 가능하다. Explicit Feedback의 경우엔 사용이 불가능하다. 왜냐면 이것은 단순히 교집합의 수를 세는 것이기 때문에 평점 데이터와 같은 가중치가 들어가면 사용할 수 없게 된다.
(3) Cosine Similarity
유저 와 사이의 거리로, 각 유저 벡터간의 각도를 계산한 것이다. 이전 Jaccard Similarity와 다르게 가중치가 반영된 Feedback도 사용할 수 있다.
값이 +1일 경우 : 벡터간 각도 0, 유저 와 모두 같은 아이템을 평가했고, 의견이 일치
값이 -1일 경우 : 벡터간 각도 180, 유저 와 모두 같은 아이템을 평가했고, 의견이 불일치
값이 0일 경우 : 벡터간 각도 90, 유저 와 는 완전히 다른 아이템 경험.
1-2. 유저 유사도 측정하기, Explicit Feedback
Explicit Feedback은 유저가 사진의 선호도를 직접적으로 표현한 데이터셋이다.
(1) Pearnson Correlation
유저 와 사이의 상관관계를 거리로 채택한 것. 가능한 값의 범위는 -1에서 1이다.
비슷한 아이템을 경험했다고 하더라도, 어떤 유저는 점수를 후하게 주는 경향일 수 있고, 어떤 유저는 점수를 짜게 주는 경향일 수 있다. 피어슨 유사도는 이러한 스케일 차이도 감안(각 유저의 평균값을 빼주는 방식으로 보완)한 값이다.
2. 예측하기
Implicit Feedback이든 Explicit Feedback이든, 각각 계산한 유사도(Euclid, Jaccard, Cosine, Pearson ..etc)를 바탕으로 유저의 아이템 에 대한 최종 평점을 예측한다. 이때 를 평가한 유저 의 평점에 유저와의 유사도를 가중하여 총 평균을 계산한다.
-
User-based :
-
Item-based :
이때 몇명의 유저를 감안해야 할까?
- 양의 상관관계가 있는 이웃들만을 포함한다. 음인 이웃들은 무시.
- 데이터셋으로부터 교차검증을 해 최적화할 수도 있다.
- 대부분의 경우 50~200사이 이웃들을 순서대로 계산한다.
3. 유저기반 CF vs 아이템기반 CF
지금까지의 설명은 유저기반 CF였다. 유저기반 CF가 유사한 유저를 기반으로 추천하는 방식이었다면 반대로 아이템기반 CF는 아이템별 구매한 유저들의 평점 분포가 유사한 또 다른 아이템을 추천해주는 방식이다.
- User-based CF : 유저 와 비슷한 고객이 ~를 소비했다.
- Item-based CF : 아이템 를 소비한 고객은 ~와 같은 아이템도 소비했다.
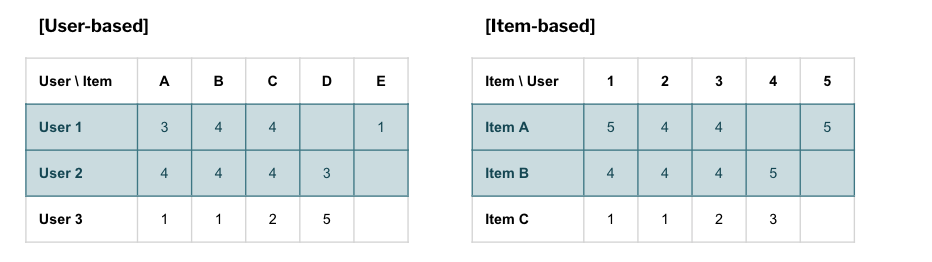
아이템기반 방법은 대부분의 경우 유저기반 방법보다 더 적절한 추천하는 경향이 높은데, 이것은 추천을 받을 유저의 평점들이 직접적으로 동원되기 때문이다. 또한 추천에 대한 이유도 제공할 수 있기 때문에 설명력이 높은 모델이다. 오히려 유저기반 추천이 효과적인 분야는 SNS다.
III. Regression으로 보는 Neighborhood-based 추천
위에서 다뤘던 를 생각해보면, 이 값은 가중치가 부여된 선형식(weighted linear combination)이라는 것을 알 수 있다. 즉 Regression과 같은 형태를 취하고 있다는 것이다. 각 항의 계수들이 Heuristic으로 계산된 인 것. 그렇다면 Regression이 계수들을 최적화하는 알고리즘인만큼, neighborhood method도 최적화 기반으로 풀 수 있게 된다.
Prediction 일반식
Prediction Regression 표현식
Sparse Linear Models, SLIM
위의 수식은 유저 의 아이템 에 대한 단일한 값이다. 모든 유저와 아이템에 대해 회귀 표현식으로 한번에 정리하기 위해 행렬을 사용하며, 이것을 SLIM이라 부른다. 지금까지 예측평점을 구하기 위해 이웃들만을 썼지만, SLIM에서는 이웃뿐만 아닌 모든 유저를 포함해 최적화한다.
Prediction Matrix 표현식
여기서 오버피팅을 방지하기 위해 행렬 곱별로 타겟 아이템은 제외하도록 한다.
$
이를 전부 종합하면, 다음과 같은 선형회귀식을 최적화함으로써 예측 평점 데이터셋을 구할 수 있게된다.
Optimization Function
지금까지 Implicit / Explicit Feedback 데이터를 활용해 평점을 예측하는 모델들을 살펴보았다. Neighborhood-based 추천은 Top K이웃을 통해 유저 의 아이템 에 대한 예측을 계산했다. 나아가 SLIM모델을 통해 예측을 Linear Regression으로 최적화 한 알고리즘도 살펴보았다. 본 텍스트에서의 알고리즘들은 메모리 기반 모형들로 그 단점을 꼽자면;
- 모든 유저의 아이템 예측값을 전부 에 저장하는 방식이기에 무겁다.
- 또한 벡터간의 유사도라는 개념은 실제 데이터가 아닌, 추정치, Heuristic이라는 문제가 있으며,
- 충분한 유저와 그들이 만든 평점을 필요로 한다(Sparsity Problem)는 단점이 있다.
다음 글에서는 이와 달리 데이터로부터 실제로 학습하는 Model-based CF를 알아본다.
Reference
Aggarwal, Charu C. Recommender systems. Vol. 1. Cham: Springer International Publishing, 2016.
https://pearlluck.tistory.com/667
