쿼리 개선은 서버 개발에 있어서 중요한 부분 중에 하나다. RDBMS는 디스크로 구성이 되어있기 때문에 SQL을 실행하면 프로세스가 디스크 I/O에 관련된 시스템 콜을 호출한다. I/O가 완료될 때까지 프로세스는 대기 큐에서 아무런 작업도 수행하지 않고 대기하게 되는데, 이는 DB서버 내 I/O 작업이 많아질수록 더 많은 병목이 발생하게 되고 DB와 연결된 WAS의 성능에도 영향을 미친다. 그렇기 때문에 쿼리 개선을 통해 I/O작업에 걸리는 시간을 개선하는 것은 전체 서버 성능에 유의미한 영향을 미칠 수 있다.
물론 인-메모리 데이터베이스를 활용한 캐싱이나, 비동기 통신(메시지 큐 등)을 활용해서 서버 성능이나 사용자 경험을 개선하는 방법도 있지만, 이 방법들은 새로운 기술들을 도입해야할 가능성이 있다. 반면에 일반적인 웹 애플리케이션은 클라이언트 - WAS - RDBMS의 구조가 대부분 적용되어있을 것이고, 쿼리 개선같은 경우에는, 프로젝트에서 사용중인 기술을 변경할 수 없는 경우는 물론이고 단순히 쿼리만 개선했을 때 서버 성능을 올릴 수 있는 중요한 부분이 된다.
서버 개발자를 지망하는 입장에서 이토록 장황하게 쿼리 개선의 중요성을 늘어놓지는 않아도, 내가 개발하는 서버 성능을 끌어올리기 위해서 우선적으로 고려할만한 선택지는 쿼리 개선이라고 생각하기 때문에, 이에 대해 알아보고자 한다.
들어가기
RDBMS는 클라이언트가 SQL을 선언하면 데이터라는 결과 집합을 내놓게 된다. 이 때 DBMS 엔진은 SQL 옵티마이저가 선택한 최적의 쿼리 실행계획에 의해서 로우 데이터를 생성하는 과정을 거치게 되는데, 쿼리 개선은 이 실행 계획을 살펴보고 쿼리의 어떤 부분에 문제가 있는지부터 살펴보는 것이 첫번째 단계가 된다. 그러기 위해서 먼저 실행계획이 무엇이고, 사용자가 SQL을 실행하면 실행계획이 어떻게 생성되고, 어떻게 활용되는지 알아야 한다.
SQL 최적화
DBMS 내부에서 프로시저를 작성하고 컴파일해서 실행 가능한 상태로 만드는 전 과정
사용자가 SQL을 실행하면 DBMS 내부에서 SQL 최적화 과정을 거치게 된다.
최적화 과정
일반적인 최적화 과정은 다음과 같다.
- SQL 파싱
- 파싱 트리 생성 : SQL 문을 이루는 개별 구성요소를 분석해서 파싱 트리 생성
- 문법 체크 : 선언한 SQL에 문법적 오류가 없는지 확인
- Semantic 체크 : 의미상 오류가 없는지 확인 ex) 존재하지 않는 테이블, 컬럼 사용 여부
- SQL 최적화
- SQL 옵티마이저가 수행. 미리 수집한 시스템 및 오브젝트 통계정보를 바탕으로 다양한 실행경로 생성
- 생성된 실행 경로를 비교후 가장 효율적인 실행계획 하나를 선택
- 로우 소스 생성
- SQL 옵티마이저가 선택한 경로를 실제 실행 가능한 코드 또는 프로시저 형태로 포맷팅. 로우 소스 생성기가 수행.
위 과정을 거치면 프로시저가 생성되어 시스템 콜을 호출해서 디스크로부터 사용자가 선언한 결과 집합을 가져오게 된다.
I/O 위주의 여타 DBMS 작업들과 달리 SQL 최적화와 로우 소스 생성 과정은 CPU를 많이 사용하는 작업이다(실행 경로를 생성하는데 무수히 많은 경우의 수가 있기 때문에 많은 연산 작업이 필요하게 된다).
실행되는 매 쿼리마다 저 과정이 실행된다면, DB에 엄청난 부하가 걸리게 된다. 하지만 DB는 그리 멍청하지가 않기 때문에 SQL이 실행될 때마다 위 과정을 모두 수행하지는 않는다.
위 과정을 모두 수행하고 SQL을 실행하는 것이 하드 파싱이고, 소프트 파싱은 2, 3번 과정을 라이브러리 캐시(MySQL의 경우에는 Buffer pool 영역에 실행계획을 캐싱해둔다)에서 가져와 SQL을 곧바로 실행하게 된다.
SQL 옵티마이저
사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해 주는 DBMS의 핵심 엔진
SQL 옵티마이저의 최적화 단계
- 사용자들로부터 전달받은 쿼리를 수행하는 데 후보군이 될만한 실행계획들을 찾아낸다.
- 데이터 딕셔너리에 미리 수집해 둔 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
- 아래 그림과 같이 최저 비용을 나타내는 실행계획을 선택한다.
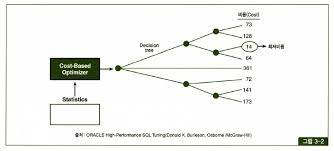
비용
쿼리를 실행하는 데 필요한 자원의 양을 추정한 값이다. 테이블의 크기, 인덱스의 사용 여부, 조인의 복잡성, 데이터 분포, I/O 비용 등을 종합적으로 고려하여 계산한 단위가 없는추상적인 값이다.
단위가 없고, 상대적인 값이기 때문에 비용의 값이 높은 부분일수록 말그대로 작업에 대한 처리에 대한 비용이 비싸다는 뜻으로 이해하면 될 것 같다.
MySQl의 SQL 최적화
MySQL은 다른 DBMS 서버와 다르게, 실행계획 수립 과정에서 통계 정보 뿐만 아니라 실제 테이블에 있는 데이터를 샘플링해서 실행 계획을 수립하는 특이한 과정이 있다. 이를 Index dive라고 한다.
인덱스 다이브란?
For as long as there have been a range access method in MySQL, the number of rows in a range has been estimated by diving down the index to find the start and end of the range and use these to count the number of rows between them. This technique is accurate, and is therefore a good basis to make the best possible execution plan. -MySQl 개발자 블로그-
요약하면, 인덱스를 사용하는 쿼리 비용 산정에 사용되는 기법이다. 개발자 블로그와 공식 문서에 따라 Index dive의 핵심 개념을 정리해보면 다음과 같다.
- 범위 산정 : Index dive는 주로 범위 쿼리에서 사용된다. ex)
WHERE price BETWEEN 100 AND 200 - 인덱스 탐색 : Index dive는 인덱스의 자료 구조를 따라 범위의 시작점과 끝점을 찾고, 이를 통해 범위 내의 row 수를 추정한다.
DBMS는 1, 2번에서 얻은 정보를 토대로 비용을 산정하게 된다. 이 때 Index dive를 통해 얻은 정보로 수립된 실행 계획이 가장 낮은 비용을 가질 경우, SQL 옵티마이저가 해당 인덱스를 사용하는 실행 계획을 선택한다. 인덱스를 사용하는 쿼리에 대한 실행 계획 수립을 도와주는 역할을 한다고 이해하면 될 것 같다.
이를 통해서 MySQL은 다른 DBMS에 비해 더 최적화된 실행계획을 수립할 수 있다.
Index Dive가 발생하는 경우
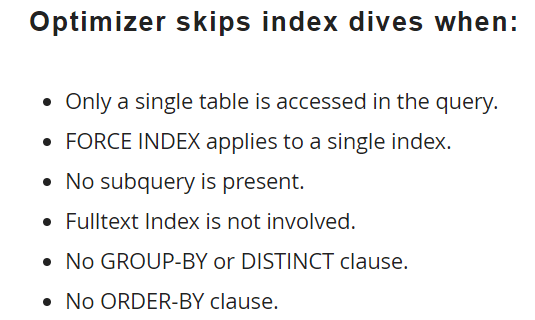
MySQL은 다음과 같은 경우를 제외하고, 실행계획 수립 시에 Index dive가 일어난다.
- 하나의 테이블에만 접근하는 쿼리의 경우
FORCE INDEX가 단일 인덱스에 적용 될 경우- 서브쿼리가 없는 경우
- Fulltext 인덱스가 관련되지 않을 경우
* Fulltext 인덱스는, 긴 텍스트 데이터를 위한 MySQL에서 제공하는 인덱스이다. GROUP BY나DISTINCT절이 없을 경우ORDER BY절이 없을 경우
MySQL의 최적화 과정을 이해했으니, 예제를 통해서 실제 실행 계획을 살펴보자.
실행계획 예제
다음은 43111번 지역(region)에 대한 토양 산성 데이터(acid 컬럼, 8.0 이상)를 SELECT하는 SQL과 실행결과물이다.
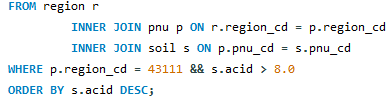

EXPLAIN
EXPLAIN은 MySQL 실행계획을 보기위해 사용하는 명령어이다. 위 예시 SQL에 붙여서 실행하면 아래와 같은 실행 계획을 볼 수 있다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | p | null | index | PRIMARY,FK7cq1jb1l0r305tx9e761yjbup | FK7cq1jb1l0r305tx9e761yjbup | 1022 | null | 1495 | 10 | Using where; Using index; Using temporary; Using filesort |
| 1 | SIMPLE | r | null | eq_ref | PRIMARY | PRIMARY | 1022 | guasuNuri.p.region_cd | 1 | 100 | null |
| 1 | SIMPLE | s | null | ref | FKp1andn1jj1a4quyc9ifylhmec | FKp1andn1jj1a4quyc9ifylhmec | 1022 | guasuNuri.p.pnu_cd | 75 | 33.33 | Using index condition; Using where |
MySQL 실행계획의 각 컬럼 설명
- id :
SELECT문의 식별자 - select_type:
SELECT문의 유형 - table : 접근하고 있는 테이블에 대한 표시
- partitions: 테이블에 파티셔닝이 되어 있는 경우 사용되는 필드
- type: 각 테이블의 레코드를 어떻게 읽었는지에 대한 접근 방식(index, full table scan 등등)
- possible_keys: 옵티마이저가 최적의 실행계획을 만들기 위해 후보로 선정했던 접근 방법에서 사용되는 인덱스 목록
- key: 최종 선택된 실행계획에서 사용되는 인덱스
- key_len: 선택된 인덱스의 길이
- ref: 접근 방법이 ref면 참조 조건으로 어떤 값이 제공됐는지 표시
- rows: 실행계획 효율성 판단을 위해 예측했던 레코드 건수
- filtered: 테이블 조건에 의해 필터링된 레코드의 비율
- Extra: 성능에 관련된 중요한 내용
주요 정보 해석
- table : p(pnu), s(soil), r(region) 세 테이블이
JOIN되어 쿼리가 실행되고 있다. - SQL에서 선언한대로, p와 s 테이블은 FK를 사용하고 있다.
- Extra : p 테이블의 경우
Using temporary라고 명시되어있다. 또한Using filesort라고 되어있는데, 이는 정렬하기 위한 임시 테이블이 사용되었음을 의미한다.
EXPLAIN ANALYZE
EXPLAIN ANALYZE 문을 실행하면 실행계획에 대한 통계 정보를 확인할 수 있다.
"-> Sort: s.acid DESC (actual time=33.7..33.7 rows=81 loops=1)
-> Stream results (cost=4170 rows=3777) (actual time=0.658..30.6 rows=81 loops=1)
-> Nested loop inner join (cost=4170 rows=3777) (actual time=0.652..30.5 rows=81 loops=1)
-> Nested loop inner join (cost=204 rows=150) (actual time=0.0832..3.3 rows=106 loops=1)
-> Filter: (p.region_cd = 43111) (cost=152 rows=150) (actual time=0.0601..2.64 rows=106 loops=1)
-> Covering index scan on p using FK7cq1jb1l0r305tx9e761yjbup (cost=152 rows=1495) (actual time=0.0539..1.45 rows=1495 loops=1)
-> Single-row index lookup on r using PRIMARY (region_cd=p.region_cd) (cost=0.251 rows=1) (actual time=0.00221..0.00287 rows=1 loops=106)
-> Filter: (s.acid > 8) (cost=19 rows=25.3) (actual time=0.176..0.253 rows=0.764 loops=106)
-> Index lookup on s using FKp1andn1jj1a4quyc9ifylhmec (pnu_cd=p.pnu_cd), with index condition: (p.pnu_cd = s.pnu_cd) (cost=19 rows=75.8) (actual time=0.0819..0.202 rows=68.1 loops=106)
"용어 설명
Sort: s.acid DESC: 결과가 s.acid 열에 따라 내림차순으로 정렬되었다는 것을 의미한다.
Nested Loop Inner Join: Inner Join 방식으로 Join문 처리. 이는 각 행을 다른 테이블의 모든 행과 비교하는 방식으로 조인을 수행한다.
Filter: 특정 조건을 충족하는 행만 선택한다. 예를 들어, p.region_cd = 43111는 p.region_cd가 43111인 행만 필터링한다.
Single-row Index Lookup: 단일 row를 찾기 위한 인데스를 사용. 여기서 PRIMARY (region_cd=p.region_cd)는 region_cd Column에 대한 PK를 사용해서 단일 row를 조회한다.
Index Lookup: 인덱스를 사용하여 특정 row를 탐색한다. 여기서 FKp1andn1jj1a4quyc9ifylhmec (pnu_cd=p.pnu_cd)는 pnu_cd 열에 대한 FK 인덱스를 사용하여 row를 조회한다.
actual time: 실제 쿼리 실행 시간을 나타낸다. actual time=0.652...30.5 라고 되어있으면, 0.652가 시작 시간, 30.5가 종료 시간이다.
rows: 처리되거나 조회된 행의 수.
loops: 해당 작업이 몇 번 반복되었는지를 나타냄.
힌트
SQL 옵티마이저가 최선의 선택을 항상 하는 것은 아니다. 사용자는 옵티마이저 힌트를 통해서 SQL 옵티마이저가 특정 실행계획을 선택하도록 유도할 수 있다.
MySQL 옵티마이저 힌트
위에서 사용했던 SQL의 실행계획 중, s.acid를 내림차순으로 정렬하는 부분이 비용이 가장 많이 들었기 때문에 acid에 index를 걸고 실행계획을 다시 실행해보겠다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s | null | range | FKp1andn1jj1a4quyc9ifylhmec,idx__soil | idx__soil | 9 | null | 1558 | 100 | Using index condition; Backward index scan |
| 1 | SIMPLE | p | null | eq_ref | PRIMARY,idx__region | PRIMARY | 42 | guasuNuri.s.pnu_cd | 1 | 10 | Using where |
| 1 | SIMPLE | r | null | eq_ref | PRIMARY | PRIMARY | 1022 | guasuNuri.p.region_cd | 1 | 100 | null |
possible_keys에 idxsoil과 idxregion이 추가되었고, idx__soil이 사용된 것을 확인할 수 있다.
-> Nested loop inner join (cost=1301 rows=156) (actual time=0.417..19.2 rows=81 loops=1)
-> Nested loop inner join (cost=1247 rows=156) (actual time=0.404..18.7 rows=81 loops=1)
-> Index range scan on s using idx__soil over (8 < acid) (reverse), with index condition: (s.acid > 8) (cost=701 rows=1558) (actual time=0.296..5.2 rows=1558 loops=1)
-> Filter: ((p.region_cd = 43111) and (p.pnu_cd = s.pnu_cd)) (cost=0.25 rows=0.1) (actual time=0.00649..0.0066 rows=0.052 loops=1558)
-> Single-row index lookup on p using PRIMARY (pnu_cd=s.pnu_cd) (cost=0.25 rows=1) (actual time=0.00243..0.00311 rows=1 loops=1558)
-> Single-row index lookup on r using PRIMARY (region_cd=p.region_cd) (cost=0.251 rows=1) (actual time=0.00211..0.00279 rows=1 loops=81)비용과 actual tiem이 확연히 줄었다. 이제 힌트를 활용해서 옵티마이저가 다른 실행계획을 선택하도록 유도해보자.
MySQL에서 힌트를 적용하는 방법은 세가지가 있다.
FORCE INDEX (ix_userid_categoryid)USE INDEX (ix_userid_categoryid)SELECT /*+ INDEX (articles ix_userid_categoryid) */
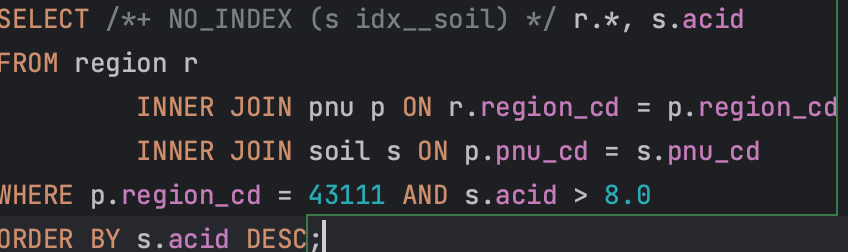
이같은 방식으로 적용할 수 있다(인덱스 사용하지 않는 문법은 NO_INDEX, IGNORE INDEX 등이 있다). 이제 힌트를 적용하는 법을 배웠으니, acid에 적용한 인덱스를 사용하지 않도록 힌트를 줘보겠다.
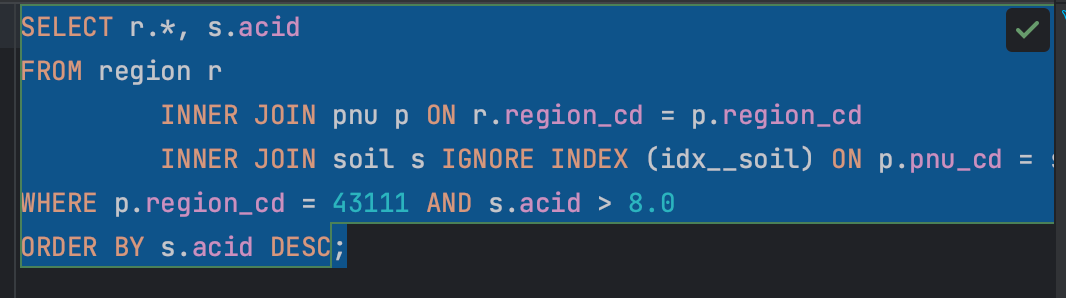
이 쿼리문에 대해 EXPLAIN과 EXPLAIN ANALYZE로 실행계획을 살펴보면
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | p | null | index | PRIMARY,idx__region | idx__region | 1022 | null | 1495 | 10 | Using where; Using index; Using temporary; Using filesort |
| 1 | SIMPLE | r | null | eq_ref | PRIMARY | PRIMARY | 1022 | guasuNuri.p.region_cd | 1 | 100 | null |
| 1 | SIMPLE | s | null | ref | FKp1andn1jj1a4quyc9ifylhmec | FKp1andn1jj1a4quyc9ifylhmec | 1022 | guasuNuri.p.pnu_cd | 70 | 33.33 | Using index condition; Using where |
-> Sort: s.acid DESC (actual time=32.1..32.2 rows=81 loops=1)
-> Stream results (cost=3900 rows=3520) (actual time=0.642..32 rows=81 loops=1)
-> Nested loop inner join (cost=3900 rows=3520) (actual time=0.637..31.9 rows=81 loops=1)
-> Nested loop inner join (cost=204 rows=150) (actual time=0.0811..3.23 rows=106 loops=1)
-> Filter: (p.region_cd = 43111) (cost=152 rows=150) (actual time=0.0578..2.57 rows=106 loops=1)
-> Covering index scan on p using idx__region (cost=152 rows=1495) (actual time=0.0521..1.39 rows=1495 loops=1)
-> Single-row index lookup on r using PRIMARY (region_cd=p.region_cd) (cost=0.251 rows=1) (actual time=0.00224..0.00291 rows=1 loops=106)
-> Filter: (s.acid > 8) (cost=17.7 rows=23.5) (actual time=0.188..0.267 rows=0.764 loops=106)
-> Index lookup on s using FKp1andn1jj1a4quyc9ifylhmec (pnu_cd=p.pnu_cd), with index condition: (p.pnu_cd = s.pnu_cd) (cost=17.7 rows=70.6) (actual time=0.0907..0.215 rows=68.1 loops=106)인덱스를 적용하기 이전 실행 비용과 거의 유사하게 나오는 것을 확인할 수 있다! NO_INDEX를 사용해도 이와 같은 결과를 얻을 수 있다.
-> Sort: s.acid DESC (actual time=32.8..32.8 rows=81 loops=1)
-> Stream results (cost=3900 rows=3520) (actual time=0.758..32.7 rows=81 loops=1)
-> Nested loop inner join (cost=3900 rows=3520) (actual time=0.753..32.5 rows=81 loops=1)
-> Nested loop inner join (cost=204 rows=150) (actual time=0.079..3.25 rows=106 loops=1)
-> Filter: (p.region_cd = 43111) (cost=152 rows=150) (actual time=0.0555..2.58 rows=106 loops=1)
-> Covering index scan on p using idx__region (cost=152 rows=1495) (actual time=0.0498..1.38 rows=1495 loops=1)
-> Single-row index lookup on r using PRIMARY (region_cd=p.region_cd) (cost=0.251 rows=1) (actual time=0.00232..0.00297 rows=1 loops=106)
-> Filter: (s.acid > 8) (cost=17.7 rows=23.5) (actual time=0.192..0.272 rows=0.764 loops=106)
-> Index lookup on s using FKp1andn1jj1a4quyc9ifylhmec (pnu_cd=p.pnu_cd), with index condition: (p.pnu_cd = s.pnu_cd) (cost=17.7 rows=70.6) (actual time=0.0933..0.221 rows=68.1 loops=106)| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | p | null | index | PRIMARY,idx__region | idx__region | 1022 | null | 1495 | 10 | Using where; Using index; Using temporary; Using filesort |
| 1 | SIMPLE | r | null | eq_ref | PRIMARY | PRIMARY | 1022 | guasuNuri.p.region_cd | 1 | 100 | null |
| 1 | SIMPLE | s | null | ref | FKp1andn1jj1a4quyc9ifylhmec | FKp1andn1jj1a4quyc9ifylhmec | 1022 | guasuNuri.p.pnu_cd | 70 | 33.33 | Using index condition; Using where |
실행 계획을 보면, IGNORE과 같은 결과를 얻을 수 있다.
마무리
앞서 예시로 사용했던 SQL은, idx__soil 인덱스에 대한 사용 여부만 힌트로 주고, 나머지는 옵티마이저가 선택하도록 했다. 이보다 더 세밀하게 힌트를 줄 수도 있고, 아예 힌트를 사용하지 않을 수 있다. 어떤 방식이 옳은지는 애플리케이션 환경에 따라서 유연하게 사용하면 된다.
참고
친절한 SQL 튜닝 - 조시형 저
https://dev.mysql.com/blog-archive/optimization-to-skip-index-dives-with-force-index/
https://medium.com/daangn/index-dive-%EB%B9%84%EC%9A%A9-%EC%B5%9C%EC%A0%81%ED%99%94-1a50478f7df8
https://dev.mysql.com/doc/refman/8.0/en/
https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html#optimizer-hints-join-order
