
최근에 토스 과제 전형이나 다른 과제 전형에서 동시성 문제에 대한 요구사항을 제대로 구현하지 못한 적이 있습니다. 해당 경험을 통해 스스로 부족함을 느꼈습니다. 이에 Java + Spring Boot 3 + JPA로 동시에 들어오는 요청을 처리할 수 있는 상품 주문 서버를 구현하면서, 동시성 문제 해결 방법에 대해 학습하고 알게 된 내용을 정리해두고자 합니다.
먼저 이번 토픽에서 JPA와 Spring의 특성 중 이해해야 될 몇 가지를 살펴보겠습니다.
영속성 컨텍스트
영속성 컨텍스트는 JPA를 이용할 때 반드시 이해해야 하는 부분입니다. 동시성 문제 해결을 위해서는 더더욱 그렇습니다.
영속성 컨텍스트와 멀티 스레드
기본적으로 영속성 컨텍스트는 스레드 별로 할당이 되기 때문에 스레드 안전(Thread Safe)하다고 할 수 있겠습니다.
따라서 여러 스레드가 동시에 DB 상 같은 레코드에서 데이터를 로드하고, 비즈니스 로직을 처리할 때, 각 스레드가 서로 같은 '버전'의 엔티티를 보고 있을 가능성이 존재하고, Lost Update와 같은 동시성 문제가 발생할 수 있음을 시사합니다.
영속성 컨텍스트의 특성 및 스프링 트랜잭션의 범위
이번엔 동시성 문제 해결을 위해 영속성 컨텍스트와 스프링 트랜잭션에 대해서 이해하고 있어야할 특성들을 알아보겠습니다.
1차 캐시
영속성 컨텍스트는 1차 캐시 기능을 제공하여, 한 트랜잭션 내에서 엔티티의 반복적인 조회를 최적화합니다. 엔티티를 처음 조회할 때 영속성 컨텍스트에 캐싱되고, 이후 같은 트랜잭션 내에서 데이터베이스를 다시 조회할 필요 없이 캐시된 엔티티를 반환합니다.
변경 감지(Dirty Checking)
영속성 컨텍스트는 영속 상태의 엔티티에 대한 변경 사항을 자동으로 감지하고 데이터베이스에 반영합니다. 이 기능은 개발자가 데이터베이스의 변경 사항을 수동으로 추적할 필요 없이, 트랜잭션이 커밋되는 시점에서 자동으로 업데이트 쿼리를 실행하게 해 줍니다.
스프링 트랜잭션과 영속성 컨텍스트
스프링에서 트랜잭션의 시작과 종료는 영속성 컨텍스트의 시작과 종료를 의미합니다. 따라서
@Transactional어노테이션은 트랜잭션과 함께 영속성 컨텍스트의 시작과 종료 시점을 제어하게 되는 것이죠.
영속성 컨텍스트에서 변경된 내용의 DB 반영 순서
- 트랜잭션 시작 : 스프링 트랜잭션 AOP가 트랜잭션을 시작합니다. 이때 @Transactional 어노테이션이 붙은 메소드가 호출되면 스프링 AOP는 트랜잭션을 시작하는 프록시 로직을 수행합니다.
- 메소드 실행 : 비즈니스 로직이 수행되며, 이 과정에서 엔티티의 상태가 변경될 수 있습니다. 변경된 엔티티는 영속성 컨텍스트 내에서 관리됩니다.
- 메소드 종료 : 비즈니스 로직이 종료되고 메소드가 리턴됩니다. 이 시점에서 트랜잭션이 아직 커밋되지 않았기 때문에 변경 내용은 데이터베이스에 반영되지 않습니다.
- 트랜잭션 커밋 : 스프링 AOP 트랜잭션 인터셉터가 트랜잭션을 커밋합니다. 이 때 JPA는 영속성 컨텍스트를 플러시합니다.
- JPA 플러시 : JPA가 영속성 컨텍스트를 플러시하며, 변경된 엔티티에 대한 SQL 문이 데이터베이스에 전송됩니다. 이 과정에서 실제 데이터베이스에 쓰기 작업이 발생합니다.
- DB 트랜잭션 커밋 : JPA 플러시 이후, 데이터베이스 트랜잭션이 커밋되며 변경 내용이 영구적으로 저장됩니다.
엔티티의 생명주기
비영속(new/transient) : 영속성 컨텍스트와 전혀 관계가 없는 상태
영속(managed) : 영속성 컨텍스트에 저장된 상태
준영속(detached) : 영속성 컨텍스트에 저장되었다가 분리된 상태
삭제(removed) : 삭제된 상태
플러시 : 영속성 컨텍스트의 변경 내용을 DB에 반영
상품 주문 서비스 코드
다음은 동시성 문제를 테스트하기 위해 작성한 상품 주문 서비스의 엔티티 객체와 비즈니스 로직 코드입니다.
Product.java
@Entity
@Table(name = "product")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
public class Product {
@Id
private Long id;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "price", nullable = false)
private int price;
@Column(name = "stock", nullable = false)
private int stock;
@Builder
public Product(Long id, String name, int price, int stock){
this.id = id;
this.name = name;
this.price = price;
this.stock = stock;
}
public void decreaseStock(int quantity) {
if (this.stock < quantity) {
throw new SoldOutException("SoldOutException 발생. 주문한 상품량이 재고량보다 큽니다.");
}
this.stock -= quantity;
}
}
product 객체는 decreaseStock() 메소드를 통해서 자신의 재고 상태를 변경합니다.
ProductService.java
@Transactional
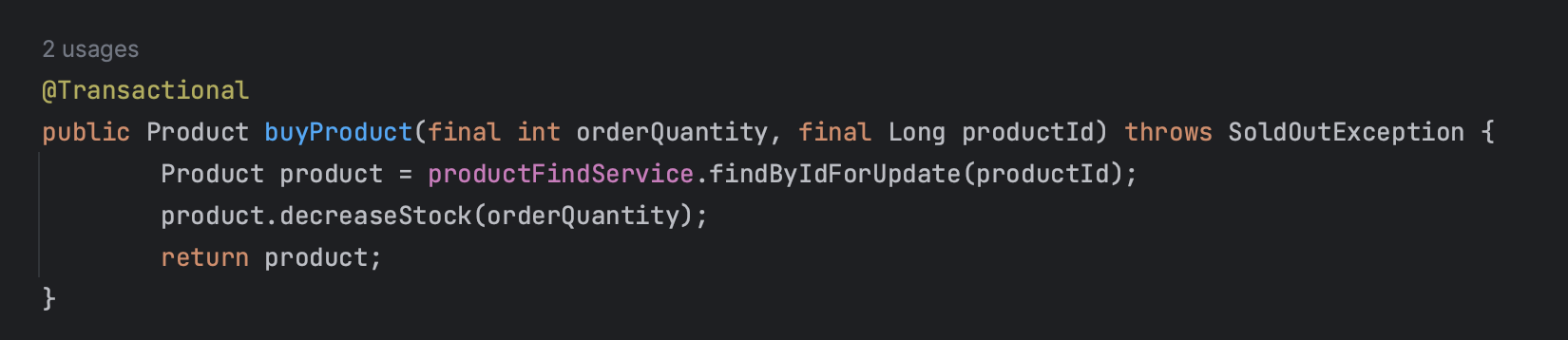
public synchronized Product buyProduct(final int orderQuantity, final Long productId) throws SoldOutException {
Product product = productFindService.findById(productId);
product.decreaseStock(orderQuantity);
return product;
}ProductService의 buyProduct() 메소드를 통해 상품 주문을 처리하게 됩니다. synchronized 키워드를 통해서 트랜잭션을 직렬화하고, 앞서 이해했던 더티 체킹에 의해 변경 사항을 DB에 반영합니다.
ProductFindService.java
@Transactional(readOnly = true)
public Product findById(final Long productId){
return this.productRepository.findById(productId)
.orElseThrow(ProductNotFoundException::new);
}
ProductPurchaseTest.java
@Test
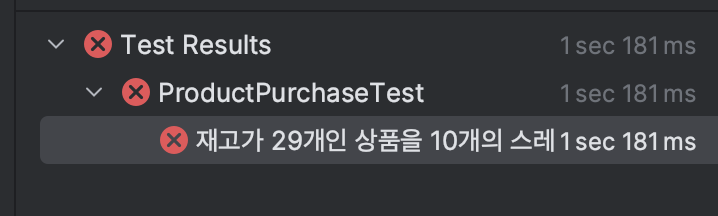
@DisplayName("재고가 29개인 상품을 10개의 스레드가 3개씩 동시에 구매했을 때 하나의 구매가 실패한다.")
void testConcurrentBuyProduct() throws Exception {
// Given
Long productId = 1L;
Product product = Product.builder()
.id(productId)
.price(1000)
.stock(29)
.name("Test")
.build();
productRepository.save(product);
AtomicInteger failCount = new AtomicInteger(0);
ExecutorService executorService = Executors.newFixedThreadPool(10);
var startLatch = new CountDownLatch(1);
var endLatch = new CountDownLatch(10);
Runnable task = () -> {
try {
startLatch.await();
productService.buyProduct(3, productId);
} catch (Exception e) {
failCount.incrementAndGet();
} finally {
endLatch.countDown();
}
};
// 10개 스레드 실행
for (int i = 0; i < 10; i++) {
executorService.submit(task);
}
startLatch.countDown();
endLatch.await();
// Then
var productForSale = productFindService.findById(productId);
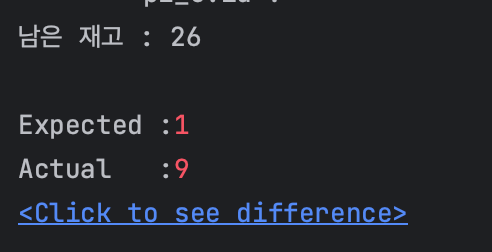
assertEquals(1, failCount.get());
assertThat(productForSale.getStock()).isNotEqualTo(0);
}이를 기반으로 작성한 테스트입니다. 29개의 재고를 가진 상품에 대해서, 10개의 스레드가 동시에 3개씩 구매하여 하나의 스레드만 실패, 나머지 9개의 스레드는 모두 구매에 성공하는 시나리오입니다.
테스트 결과

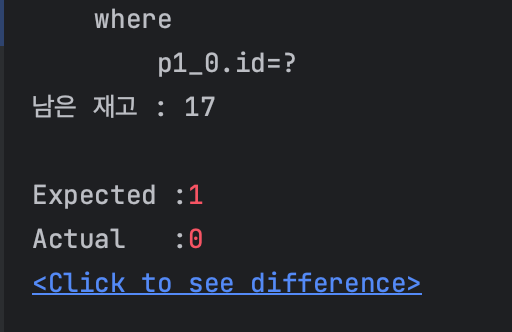
의도한 테스트 결과는 product 엔티티의 stock 값이 2가 남고, 1 번의 구매 실패가 발생하는 것인데, product의 stock 값은 17, 구매 실패는 0번 발생했습니다.
문제 원인
buyProduct() 설계 의도
다시 buyProduct()를 살펴보겠습니다. buyProduct() 메소드는 synchronized 키워드를 통해서 한 번에 하나의 스레드만 실행할 수 있도록 설계 했습니다. 이를 통해 동시에 여러 스레드가 같은 버전의 데이터를 읽고 값을 갱신하여 발생하는 Lost Update 문제를 방지하고자 했습니다.
synchronized
synchronized키워드는 여러 스레드가 동시에 같은 객체의 특정 부분을 접근하는 것을 제한하여, 동시성 문제를 방지하는 역할을 합니다. 이 키워드를 사용하면 지정된 객체에 대한 락을 획득하고, 해당 블록의 코드가 실행되는 동안 다른 스레드는 그 객체의 잠긴 부분에 접근할 수 없습니다.
원인 분석
synchronized 키워드로 트랜잭션을 직렬화 했다고 생각했는데, 왜 이런 문제가 발생했을까요?
이유는 영속성 컨텍스트에서 관리하는 영속 상태 엔티티의 생명주기에 있었습니다. DB에서 로드한 값을 지닌 Product 객체는 @Transactional 어노테이션에 의해서 영속성 컨텍스트에 영속 상태로 있게 됩니다. 메소드 내 변경된 내용은 트랜잭션이 커밋된 다음 JPA가 영속성 컨텍스트를 플러시 하는 시점에 DB에 반영이 되는 생명주기를 갖습니다. (위 설명 참고)
문제는 여기서 발생합니다. Java의 synchronized 키워드가 달린 메소드의 시작 - 종료와 영속성 컨텍스트의 생명주기는 서로 독립적입니다. 그렇기 때문에 Product 엔티티의 이전 변경사항이 DB에 반영되기 전, 다음 스레드가 buyProduct() 메소드를 실행하여 이전 스레드가 로드했던 동일한 버전의 값을 갖게 되는 것입니다.
정리해보면 JVM 상에서 메소드의 실행은 제대로 직렬화가 이루어졌지만, 메소드의 실행 - 종료와 변경 사항의 반영 시점이 달라, 다른 스레드에서 같은 값을 불러오는 경우가 발생했고, 결과적으로 데이터 무결성이 깨지게 된 것입니다.
추가
다음과 같이 hibernate 로깅 설정을 한다면, 훨씬 더 쉽게 트랜잭션과 영속성 컨텍스트, 그리고 스레드 동작 순서에 대해서 파악할 수 있습니다.
logging:
level:
org:
hibernate:
SQL: DEBUG
type: TRACE
engine:
transaction:
internal:
TransactionImpl: DEBUG
spi: TRACE
event: TRACE
해결 방안
앞서 분석한 원인에 따라서, 영속성 컨텍스트의 플러시 시점을 메소드 종료 이전에 명시적으로 실행하면 해결될 것이라고 생각했습니다.
1. 트랜잭션 내에서 엔티티를 명시적으로 flush
따라서 기존 ProductService에서 EntityManger를 주입 받아, buyProduct 메소드 내에서 flush()를 명시적으로 호출하면서 메소드 종료 이전에 변경 내용을 DB에 반영하고자 하였습니다.
변경된 로직
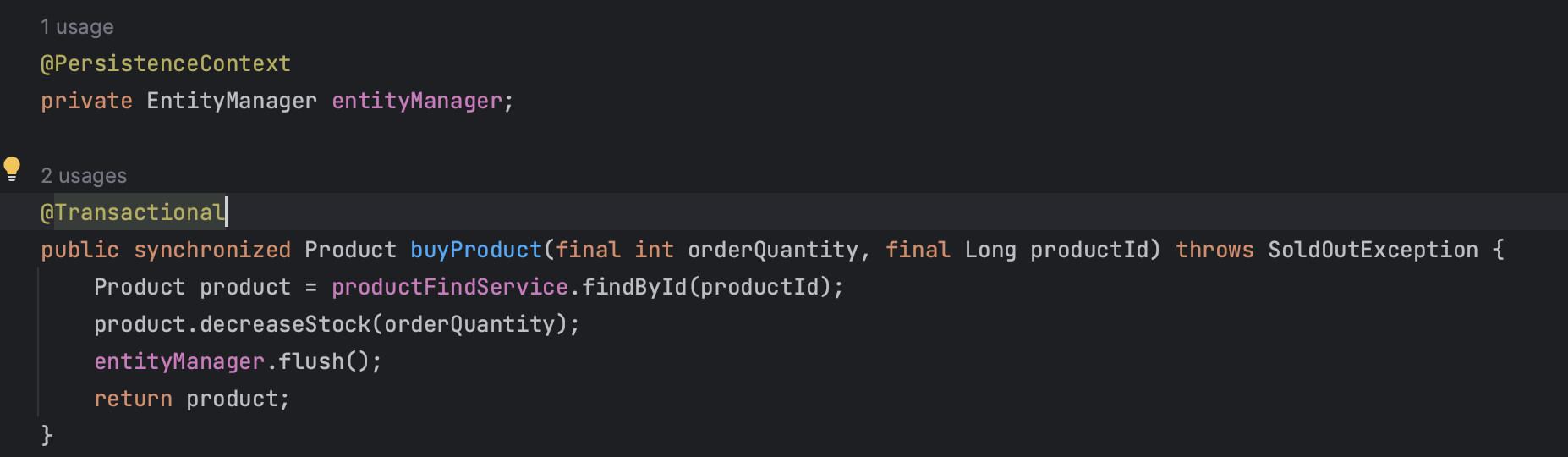
ProductService 클래스에 EntityManger를 주입하고, 직접 메소드 내에서 flush() 메소드를 호출해 영속성 컨텍스트의 생명주기를 앞당겼습니다.
테스트 결과
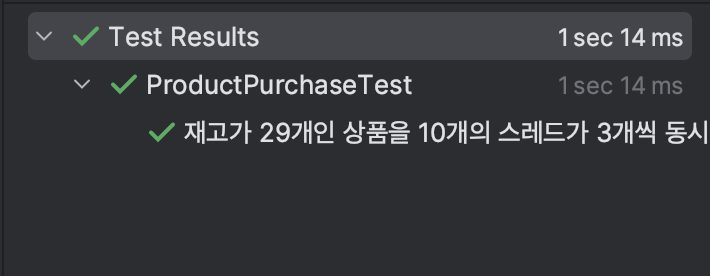
의도한대로 동작하는 것을 확인할 수 있습니다.
2. @Transactional 주석 처리 + save 호출
그런데 DB 반영 시점만 제어할 수 있다면, 굳이 @Transactional 어노테이션을 사용해서 영속성 컨텍스트과 synchronized를 함께 사용했을때의 불확실성을 안고 가야하나? 라는 생각이 들었습니다.
그래서 @Transactional 어노테이션을 주석처리하고, JPA Repository의 save() 메소드를 통해 Product 엔티티의 변경 사항을 명시적으로 동기화 시켜주었습니다.
변경된 로직

테스트 결과
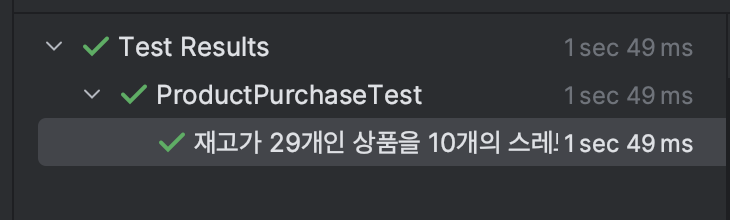
2번 로직에서 save() 메소드의 동작 방식
1번 해결안에서는 flush()를 호출해 영속성 컨텍스트에서 감지한 변경 내용을 DB에 반영했습니다. 그런데, 2번의 경우 트랜잭션 어노테이션을 주석처리 했기 때문에 영속성 컨텍스트의 변경 내용 자체를 buyProduct() 메소드 안에서 감지할 수가 없습니다.
따라서 JPARepository의 save() 메소드를 호출해서 변경 사항을 DB에 반영했는데요, Spring Data JPA에서 제공하는 모든 메소드는 기본적으로 트랜잭션을 생성하게 됩니다. 그렇기 때문에 save() 메소드의 호출과 실행 종료 시점에 따라 트랜잭션이 종료되어 곧바로 데이터베이스에 변경 내용이 반영되는 것이죠.

여기서 주의할 점이 하나 있는데요, 위 자료를 요약하면 save() 메소드는 트랜잭션 범위 내에서 명시적으로 호출할 경우, 곧바로 변경사항을 DB에 반영하지 않는다는 것입니다. 대신 saveAndFlush() 메소드가 존재합니다. @Transactional 어노테이션이 없는 조금 더 데이터베이스 동기화 시점을 확실하게 하고 싶다면 saveAndFlush() 메소드 또한 선택지가 될 수 있겠습니다.
결론
synchronized 키워드를 통한 스레드 직렬화 방식은 단일 서버 - DB 구조의 아키텍처에서 직관적이고 좋은 제어 방법이 될 것 같습니다. DB 자체적으로 어떠한 오버헤드 없이 동시성을 제어할 수 있기 때문에 성능상 이점도 존재할 것으로 보입니다.
만약 서버가 여러 개라면?
하지만 분산 서버 환경이나 JVM 인스턴스가 여러 개일 경우에는 단일 JVM 내에서 동기화하는 synchronized 키워드 만으로 문제를 해결할 수 없게 됩니다.
분산 환경에서 해결할 수 있는 방법
분산된 서버 환경에서 고려해볼 수 있는 기술과 전략은 매우 다양하지만, 대표적인 것들을 나열해보겠습니다.
-
분산 락(Distributed Locks) : 여러 서버 간 공유 자원에 대한 접근을 관리할 수 있는 분산 락 메커니즘을 구현합니다. Apache ZooKeeper, Redisson, 또는 Hazelcast와 같은 기술들이 분산 락 기능을 제공합니다.
-
낙관적 락(Optimistic Locking) : 데이터를 읽을 때 버전 번호나 타임스탬프를 확인하고 업데이트를 커밋하기 전에 변경되지 않았는지를 검증하는 기법입니다. 데이터가 변경된 경우 트랜잭션을 롤백합니다.
-
비관적 락(Pessimistic Locking) : 낙관적 락과는 반대로, 비관적 락은 트랜잭션 동안 데이터를 잠그는 것입니다. 이는 데이터베이스 수준에서
SELECT FOR UPDATE문을 사용하여 트랜잭션이 완료될 때까지 레코드를 잠그는 방식입니다. -
메시지 큐(Message Queues) : RabbitMQ, Apache Kafka, AWS SQS와 같은 메시지 큐를 사용하면 특정 작업에 대한 접근을 직렬화하여 한 번에 하나의 작업만 데이터를 조작하도록 할 수 있습니다.
기술 선택
이번에 고려해야될 일차적인 목표는 분산 환경에서 동시성 문제에 대한 해결입니다. 분산 환경에서 발생하는 동시성 문제는 DB 레벨에서 제어가 필요한 문제이며, 동시에 들어오는 요청에 대해서 모두 정상적인 작업이 이루어져야 합니다.(주문량보다 재고가 많을 경우 정상 주문, 재고보다 주문량이 많은 경우 예외 처리) 위에서 나열한 방법 모두 이에 해당된다고 생각합니다.
또한 JPA를 활용해 해결 가능한지에 초점을 맞추고자 했습니다. 이번 포스팅은 어디까지나 Java + JPA + Spring Boot 3 환경에서 동시성 문제 해결을 위한 학습에 목적을 두고 있기 때문에, 새로운 기술을 도입하는 것은 의미가 없을 것 같다 판단했습니다.
따라서 낙관적 락과 비관적 락을 선택하겠습니다. 두 방법 모두 JPA에서 지원하기 때문입니다.
명시적 락
명시적 : 내용이나 뜻을 분명하게 드러내 보이는 것.
명시적 락은 말 그대로 락을 명시해주는 것입니다. 자동으로 관리하는 락(암시적 락)과 대비되는 개념으로, 개발자가 특정 오퍼레이션 수행 시 데이터의 동시성을 제어하기 위해 직접 락을 지정하는 개념입니다.
명시적 락을 사용하는 목적은 다음과 같습니다.
-
데이터 일관성 유지 : 여러 트랜잭션이 동일한 데이터를 동시에 수정하지 못하도록 하여 데이터의 일관성을 보장합니다.
-
데드락 방지 : 특정 순서로 락을 획득함으로써 데드락 발생 가능성을 줄일 수 있습니다.
-
경쟁 상황 제어 : 경쟁 상황(race condition)을 명시적으로 제어하여 데이터의 무결성을 보장합니다.
앞서 언급한 낙관적 락과 비관적 락 모두 명시적 락의 일종이라고 할 수 있겠습니다.
JPA의 @Lock 옵션
JPA에서는 @Lock 어노테이션을 통해서 명시적 락을 구현할 수 있습니다. 어노테이션 파라미터에 현재 상황에 맞는 락 옵션을 선택할 수 있으며, 기본값은 None 입니다.
| 구분 | 락 모드 | 설명 |
|---|---|---|
| 락 없음 | LockModeType.NONE | 아무런 락도 사용하지 않습니다. |
| 낙관적 락 | LockModeType.OPTIMISTIC | 데이터를 읽은 시점의 버전 정보를 통해 트랜잭션이 커밋되는 시점에 충돌을 감지합니다. |
| 낙관적 락(버전 증가) | LockModeType.OPTIMISTIC_FORCE_INCREMENT | 낙관적 락을 사용하며, 엔티티를 수정할 때마다 버전 번호를 강제로 증가시켜 변경 사항을 명확히 합니다. |
| 비관적 락(읽기) | LockModeType.PESSIMISTIC_READ | 트랜잭션이 해당 데이터를 읽는 동안 다른 트랜잭션이 데이터를 쓸 수 없도록 잠급니다. |
| 비관적 락(쓰기) | LockModeType.PESSIMISTIC_WRITE | 데이터에 대한 읽기 및 쓰기를 다른 트랜잭션이 수행할 수 없도록 잠급니다. |
| 비관적 락(버전 증가) | LockModeType.PESSIMISTIC_FORCE_INCREMENT | 비관적 락을 사용하며, 트랜잭션이 성공할 때마다 버전 번호를 강제로 증가시키며 읽기와 쓰기를 다른 트랜잭션이 할 수 없습니다. |
낙관적 락(Optimistic Lock)
낙관적 락은 트랜잭션 간 충돌이 발생하지 않는다는 가정 하에 공유 자원에 대한 버전 관리를 통해서 충돌을 감지하는 방식입니다.
@Version 어노테이션
JPA는 @Version 어노테이션만으로 낙관적 락을 사용할 수 있습니다. 다음과 같이 엔티티 클래스에 @Version 어노테이션과 필드를 추가해줍니다.
Product.java
@Entity
@Table(name = "product")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
public class Product {
@Id
private Long id;
@Column(name = "name", nullable = false)
private String name;
@Column(name = "price", nullable = false)
private int price;
@Column(name = "stock", nullable = false)
private int stock;
@Version
private int version;
@Builder
public Product(Long id, String name, int price, int stock){
this.id = id;
this.name = name;
this.price = price;
this.stock = stock;
}
public void decreaseStock(int quantity) {
if (this.stock < quantity) {
throw new SoldOutException("SoldOutException 발생. 주문한 상품량이 재고량보다 큽니다.");
}
this.stock -= quantity;
}
}
@Version 어노테이션을 추가하면, 엔티티에 수정이 가해질때마다 버전 필드 값에 1이 더해집니다. 그리고 조회 시점의 버전과 수정 시점의 버전이 다를 경우 예외가 발생하게 됩니다. 즉, 한 트랜잭션에서 엔티티를 조회 및 수정하여 버전이 1 증가했는데, 또 다른 트랜잭션이 같은 엔티티를 수정 및 커밋해버릴 경우 버전 충돌이 발생하게 되는 구조입니다.
ProductService
테스트 결과
테스트가 실패하게 됩니다. 이는 어찌보면 당연한 결과인데요, 10개의 스레드가 하나의 레코드에 동시 접근하고 하나의 스레드가 트랜잭션 커밋에 성공하면, 다른 스레드의 트랜잭션에서는 버전 충돌이 발생하기 때문에 위와 같은 결과가 나오게 됩니다.
OptimisticLockException
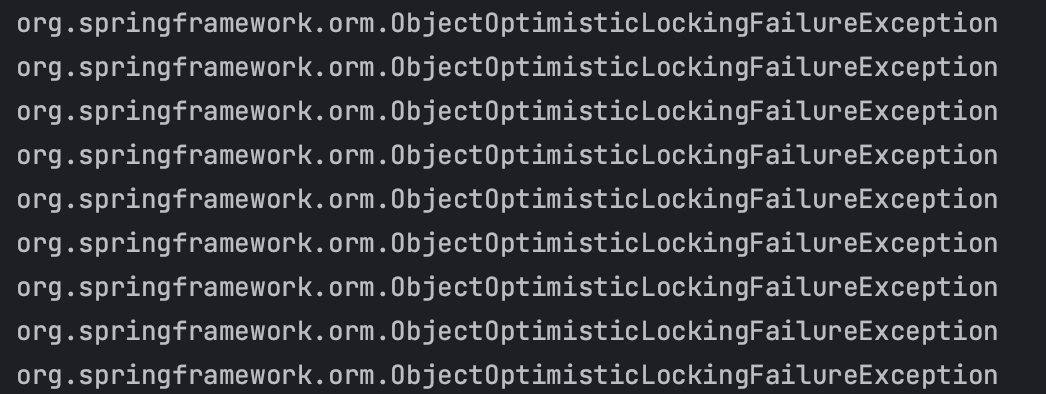
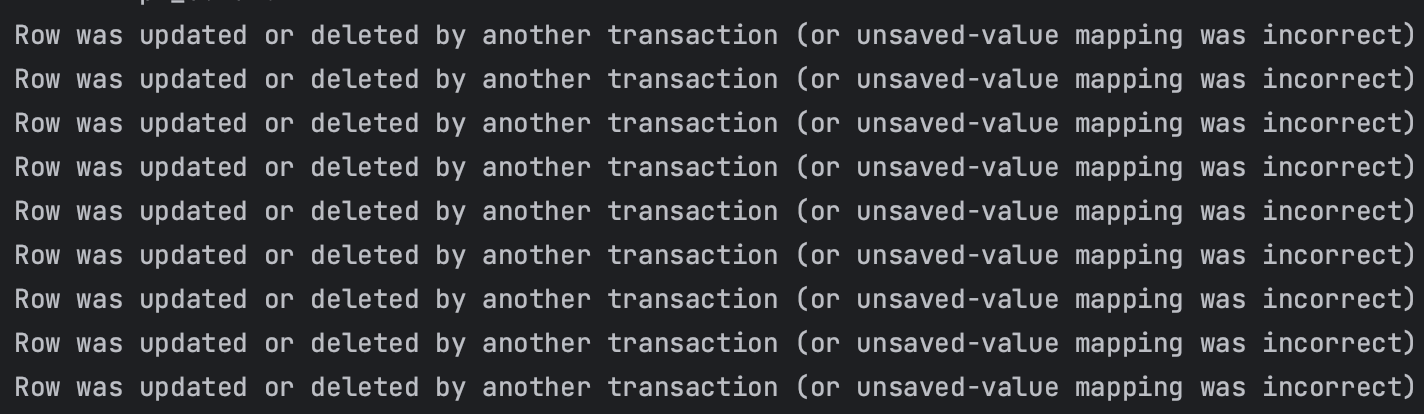
위 에러는 하이버네이트에서 발생시킨 OptimisticLockException 에러를 스프링에서 래핑한 에러 메시지입니다. 다른 트랜잭션에서 Row를 수정하여 충돌이 발생했다는 것인데 이를 의도대로 동작시키기 위해 적절한 재시도 로직이 필요합니다.
수정된 로직 + 결과
재시도 로직을 위해서 스프링의 @Retryable 어노테이션을 활용해보겠습니다.
- 의존성 추가
implementation 'org.springframework.retry:spring-retry'
-
리트라이 활성화

-
코드 수정

buyProduct() 메소드에 @Retryable 어노테이션을 사용해서 최대 시도횟수를 10으로 설정하고 다시 테스트를 실행해보겠습니다.
- 테스트 결과
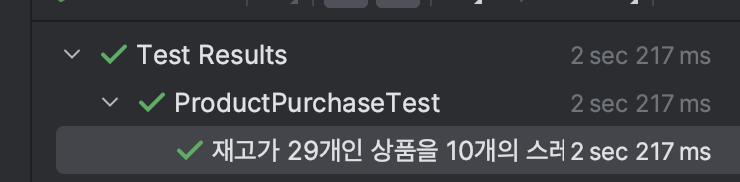
재시도 로직을 추가하여 테스트를 통과했습니다. 이를 통해 알 수 있는 것은, 쓰기 작업이 과하게 발생하는 환경에서 낙관적 락은 좋지 못한 선택이라는 것입니다. 단순히 테스트에 소요된 시간만 봐도, 밑에서 사용할 비관적 락에 비해 2배 정도가 소요됩니다. 하지만 DB 레벨에서 락을 걸지 않기 때문에 읽기 작업이 빈번한 환경에서는 성능상 이점이 있을 것으로 생각됩니다.
비관적 락(pessimistic lock)
비관적 락은 동시에 같은 데이터에 접근하는 여러 트랜잭션이 서로 간섭할 수 있다고 가정하고, 데이터를 읽거나 변경하기 전에 명시적으로 락을 걸어서 다른 트랜잭션이 동시에 해당 데이터를 수정하지 못하도록 합니다. 이 락은 데이터를 읽은 시점에서 바로 설정되며, 트랜잭션이 완료될 때까지 유지됩니다.
JPA에서 비관적 락은 일반적으로 PESSIMISTIC_WRITE 옵션을 사용합니다. 이 옵션을 걸게 되면 DB에서 SELECT FOR ...UPDATE 쿼리를 사용해 DB 레벨에서 X 락을 걸게 됩니다.
적용
ProductRepository
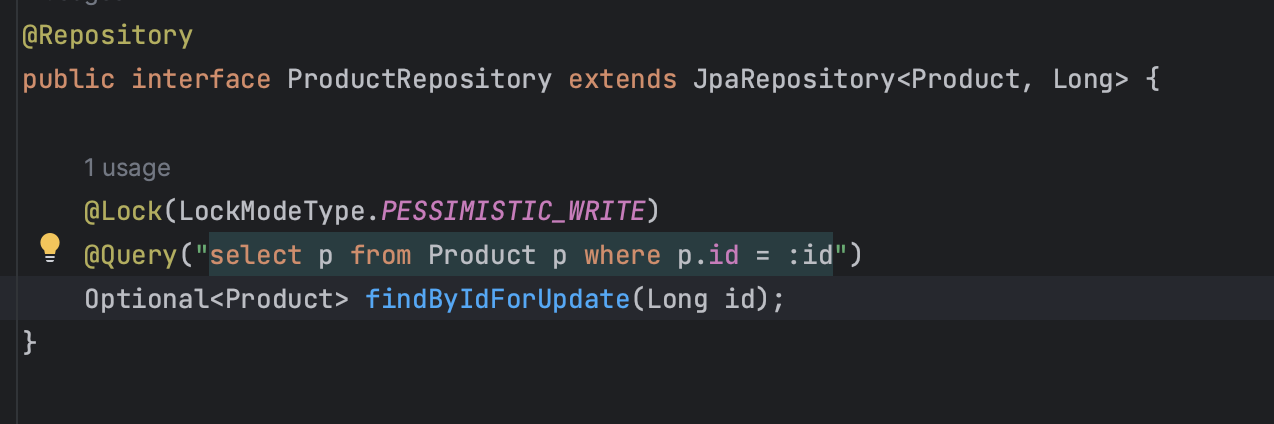
JpaRepository를 상속받은 인터페이스에서 Lock 옵션을 지정한 메소드를 정의해주면, 비관적 락을 사용할 수 있습니다.
ProductService

결과
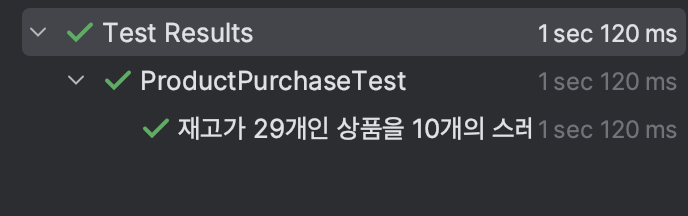
동시성 문제가 발생하지 않으면서, 테스트가 통과한 것을 확인할 수 있습니다.
여러모로 낙관적 락에 비해 생산성 있게 코드를 작성할 수 있는 것 같습니다.
결론
정리하자면, 낙관적 락은 읽기 작업이 많을 경우 성능상 이점이 있습니다. 데이터를 읽을 때 DB 레벨에서 락을 걸지 않기 때문입니다. 이로 인해 데드락 또한 발생할 여지가 없습니다. 하지만 가정 자체가 트랜잭션 간 충돌이 발생하지 않는 것이기 때문에, 쓰기 작업에 대한 동시성 처리가 빈번한 경우에는 적합하지 않겠습니다.
반면에 비관적 락은 쓰기 작업이 빈번할 경우에 적합한 락 전략입니다. 데이터를 읽기 위해 DB 레벨에서 락을 걸기 때문에 동시에 들어오는 요청에 대해서 안전하게 처리할 수 있습니다. 하지만 단순한 읽기 작업에도 레코드에 대한 락을 걸어야하기 때문에 읽기 작업이 빈번한 상황에는 적합하지 않을 수 있습니다.
마무리
간단한 상품 주문 서비스를 구축하면서 발생한 동시성 문제를 synchronized 키워드, 스프링 트랜잭션과 JPA + 영속성 컨텍스트의 특성을 이용해 해결해보았습니다.
또 분산된 서버 환경에서 발생할 수 있는 동시성 문제를 고려해 JPA를 활용해서 비관적 락과 낙관적 락을 적용해보았습니다. 이 경우 실제 분산된 환경에서 실행하지 않았기 때문에 더 세밀한 검증이 필요하지만, 이론적으로는 동시성 제어가 가능할 것으로 보입니다. 또한 읽기 비율과 쓰기 비율에 따라 적합한 기술을 선택할 수 있도록 내가 선택할 기술에 대한 이해도가 있어야겠다는 생각이 들었습니다.
기본적인 동시성 문제를 해결하기 위해 꽤 많은 양의 학습을 했다는 생각이 드는데, 실제 업무에서는 더 복잡한 문제를 다룰 것이기 때문에 더 깊이있는 학습이 필요하다고 생각합니다. 동시성 문제에 대한 다른 토픽이 생긴다면 다시 관련 문제에 대해서 학습하고 포스팅하겠습니다.
참고
- 자바 ORM 표준 JPA 프로그래밍 - 김영한 저
- https://www.baeldung.com/sql-logging-spring-boot
- https://sabarada.tistory.com/175
https://medium.com/@bindubc/distributed-system-concurrency-problem-in-relational-database-59866069ca7c - https://hyos-dev-log.tistory.com/34
- https://ksh-coding.tistory.com/125#3.%20%EB%8F%99%EC%8B%9C%EC%84%B1%20%EB%AC%B8%EC%A0%9C%EB%A5%BC%20%ED%95%B4%EA%B2%B0%ED%95%98%EB%8A%94%20%EB%B0%A9%EB%B2%95%20(feat.%203%EA%B0%80%EC%A7%80%20Lock)-1
- https://www.baeldung.com/spring-data-jpa-save-saveandflush
- https://www.baeldung.com/jpa-optimistic-locking
- https://xxeol.tistory.com/57

잘 읽고 갑니다.
내용 중 한가지 트집아닌 트집을 잡자면 '@Transactional 주석 처리 + save 호출' 내용에서 제가 생각했을 땐, 영속성 컨텍스트가 두번 열렸다가 닫히게 되고, START ~ COMMIT 흐름도 두번 발생하게 됩니다. 또한 save 시 명시적인 SELECT 쿼리가 나가기도 할 것입니다. 즉, 해당 작업에서 불필요한 쿼리가 네트워크를 타고 DB에 도달하게 되어 @Transactional 어노테이션 내에서 명시적으로 Flush를 해주는 것보다 성능 상 불이익이 있을 것이라고 생각되는데 이에 대해서는 어떻게 생각하시는지 궁금합니다.