이전 포스팅에서 DML(UPDATE, INSERT, DELETE)의 성능에 영향을 미치는 요소 중, 다루지 않았던 요소들을 이해하고, 왜 DML의 성능에 영향을 미치는지 알아보았다. 크게 정리했을 때 DML의 성능에 영향을 미치는 요소는 크게 다음과 같다.
- 인덱스
- 무결성 제약 조건
- Redo 로그
- Undo 로그
- 커밋
- Lock
이번 포스팅에서는 커밋과 Lock을 제외한 각 요소에 따른 DML 병목 상황을 가정하고, 이를 적절하게 튜닝해보는 과정을 거치면서 대량 INSERT 상황에 대한 적절한 튜닝 기법을 이해해보려고 한다. Lock은 격리 수준과 함께 추후에 튜닝하는 방법을 자세히 다루기 위해서 제외하였다.
인덱스 + 무결성 제약 조건으로 인한 INSERT 병목
문제 상황을 발생 시키기 위해, 테스트 테이블을 생성하고, 데이터를 생성해주겠다. 아래와 같이 t1 테이블을 생성하고 row 100만개를 생성해주겠다.
DELIMITER $$
CREATE PROCEDURE insertDummyData()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE randNum INT;
WHILE i <= 1000000 DO
-- 랜덤 숫자 생성
SET randNum = FLOOR(1 + (RAND() * 1000000));
INSERT INTO t1 (c1, c2, c3) VALUES
(CONCAT('content', randNum), CONCAT('content', randNum), CONCAT('content', randNum));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL insertDummyData();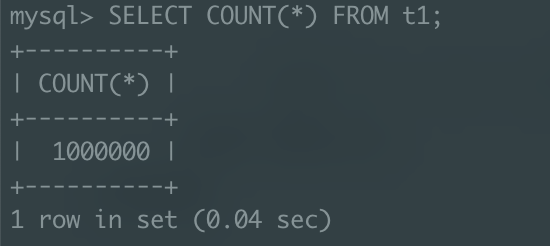
t1 테이블에 100만 건의 row를 성공적으로 INSERT한 것을 확인하였으니,



이제 같은 컬럼을 가진 t2, t3 테이블을 생성해주고 t3 테이블의 c1 컬럼에는 인덱스를 생성해서 각각의 100만개 row에 대한 대량 INSERT 실행 속도 차이를 비교해보자.

t2 테이블의 경우, 2.49초의 실행 속도로 작업을 완료하였다.

t3 테이블의 경우, 5.88초의 실행 속도를 보였는데, 인덱스로 인해 3.4초 가량의 병목이 발생했음을 알 수 있다.
튜닝 1. 인덱스 삭제 및 재생성
인덱스로 인해 병목이 발생하기 때문에, 이를 INSERT 시점에는 삭제하고, 레코드가 생성된 후에 다시 재생성해주는 방법이다.
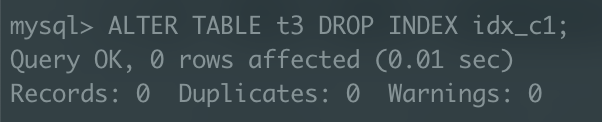
앞서 인덱스를 생성해주었던 t3 테이블의 c1 컬럼 인덱스를 삭제해준 후, 100만 건을 입력한 다음 다시 인덱스를 재생성 해주자.
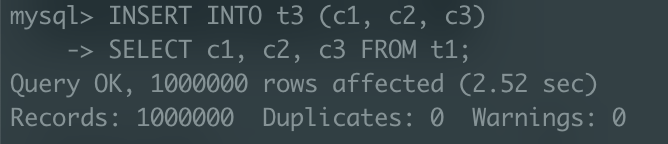
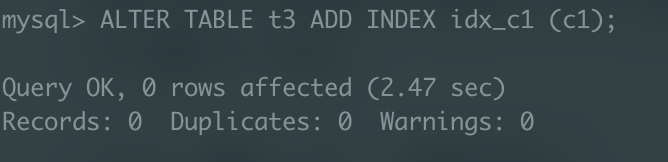
인덱스 삭제(0.01초) -> 100만건 레코드 삽입(2.52초) -> 인덱스 재생성(2.47초) 도합 약 5초
개선 전 5.88초 -> 개선 후 5.00초
결과적으로 약 0.88초의 성능 개선을 이루어낼 수 있었다.
다만, 이 방법은 기존에 존재하는 모든 인덱스를 삭제한 후, 새로 생성된 대용량 레코드에 대한 인덱스까지 합쳐서 다시 생성해야하는 작업을 거치기 때문에 해당 부분에 있어서는 효율적이지 못할 수 있다.
튜닝 2. 파티셔닝
앞서 소개한 문제를 더 효율적으로 해결할 수 있는 방법이 있다. 파티셔닝을 활용하는 것이다.
파티셔닝이란?
파티셔닝은 DBMS에서 큰 테이블이나 인덱스를 관리 가능한 작은 조각으로 나누는 기술이다. 이해하기 쉽게 코드로 설명을 하면,
CREATE TABLE sales (
sales_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT NOT NULL,
sales_date DATE NOT NULL,
amount DECIMAL(10,2) NOT NULL
)
PARTITION BY RANGE (YEAR(sales_date)) (
PARTITION p0 VALUES LESS THAN (2020),
PARTITION p1 VALUES LESS THAN (2021),
PARTITION p2 VALUES LESS THAN (2022),
PARTITION p3 VALUES LESS THAN (2023),
PARTITION p4 VALUES LESS THAN MAXVALUE
);sales 테이블은 sales_date의 연도에 따라 데이터를 파티셔닝한다. 예를 들어, 2020년 이전의 모든 데이터는 p0 파티션에, 2020년부터 2020년 말까지의 데이터는 p1 파티션에 저장된다. 이와 같은 방식으로, p2, p3 파티션에도 각각 해당하는 데이터가 저장되며, MAXVALUE는 그 이상의 모든 값을 포함하는 파티션에 대한 지정자로 사용된다.
인덱스 또한 파티셔닝 될 경우, 레코드의 삽입으로 인한 인덱스 재정렬 과정이 간결해질 수 있다. 경우에 따라라서 삽입, 검색, 삭제 등의 작업을 수행 시 경우에 따라서 인덱스의 탐색 범위를 줄일 수 있다.
파티셔닝은 LIST, HASH, RANGE, KEY 등 여러가지 전략이 있으며, 위 sales 테이블은 RANGE 기반 파티셔닝을 한 상태이다.
파티셔닝에 따른 테이블, 인덱스의 구분
앞서 테이블과 인덱스를 파티셔닝할 수 있다고 했는데, 테이블의 경우 파티셔닝 테이블과 비파티션 테이블로 구분할 수 있다.
반면 인덱스의 파티션 별 구분은 조금 더 복잡한데,
- 로컬 파티션 인덱스(Local Partitioned Index)
- 글로벌 파티션 인덱스(Global Partitioned Index)
- 비파티션 인덱스(Non-Partitioned Index)
로 구분할 수 있다. 로컬 파티션 인덱스는 파티션된 테이블과 1:1 대응이 되는 파티션 인덱스를 말한다. 글로벌 파티션 인덱스는 로컬 파티션 인덱스 이외의 파티션 인덱스를 뜻한다.
여기까지 이해했을 때, 대량 INSERT에 대한 아이디어를 떠올릴 수 있다. 파티션 단위로 인덱스를 삭제하고 재생성 해준다면, 전체 인덱스를 삭제하고 재생성하는 과정에 비해서 훨씬 더 효율적일 것이다.
MySQL의 파티셔닝
테이블 파티셔닝과 인덱스 파티셔닝은 위와 같이 구분할 수 있지만, DBMS마다 이에 대한 구현은 제각기 다를 것이다. MySQL의 경우 파티션 테이블 단위로 인덱스를 관리하는 로컬 파티션 인덱스를 지원한다.
다만, MySQL에서 파티셔닝을 할 경우, 몇 가지 제약사항이 존재한다.
- 파티셔닝 키에 PK 컬럼을 반드시 포함
예시
다음과 같은 테이블이 있을 때, 파티션 테이블 + 로컬 파티션 인덱스 와 비파티션 테이블 + 비파티션 인덱스 간 데이터 삽입 실행 속도 차이를 비교해보겠다.
먼저 동일한 데이터 셋을 100만건 씩 비파티션 테이블과 파티션 테이블에 적재하고, 또 다른 데이터셋 100만건 중, 일정 범위 내 c1 컬럼 값을 SELECT하여 각 테이블에 적재하는 작업의 실행 속도를 비교할 것이다.
- 더미데이터 테이블 생성
CREATE TABLE partition_t1 (
id INT NOT NULL,
c1 INT NOT NULL,
c2 VARCHAR(100)
)- 더미데이터 삽입
DELIMITER $$
CREATE PROCEDURE InsertRandomData1000000()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000000 DO
INSERT INTO partition_t1 (id, c1, c2) VALUES (i, FLOOR(RAND() * 1001), CONCAT('Content ', i));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL InsertRandomData1000000();-
비파티션 테이블 생성
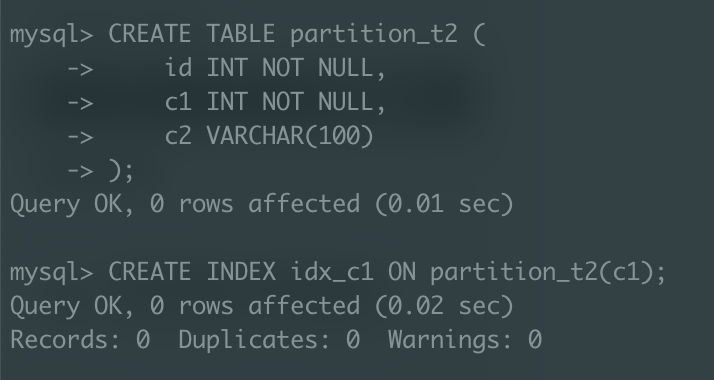
이 때 -
파티션할 테이블 생성
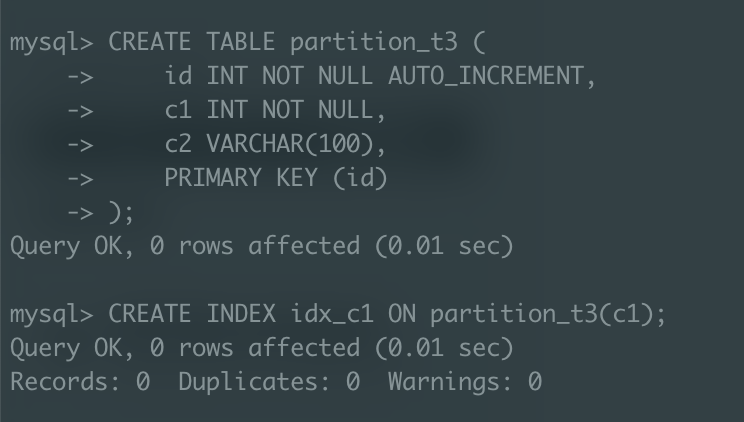
-
각 테이블에 더미데이터 100만개 삽입
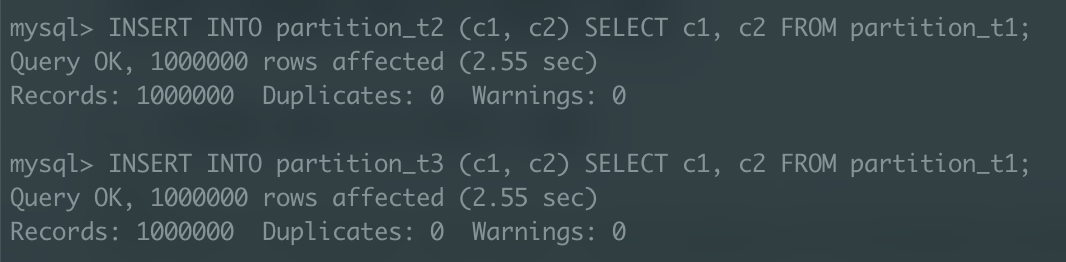
4.partition_t3 테이블 파티셔닝
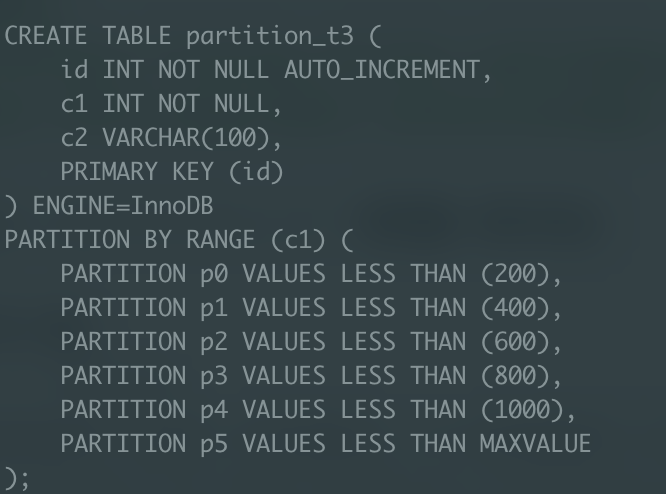
이 때, 위와 같은 방식으로 파티셔닝을 시도하면 다음과 같은 에러 메시지를 마주할 수 있다.

이는 MySQL의 파티셔닝 제약 조건에 의해 발생하는 에러인데, 내용을 살펴보면 파티셔닝 키에는 반드시 해당 테이블의 PK나 Unique Key가 포함되어야 한다고 나와있다.
따라서, c1 컬럼을 파티셔닝 키로 지정하려면, c1을 PK에 포함하거나 유니크 인덱스로 지정해주어야 한다. 또는 PK 제약 조건이 존재하지 않는 테이블을 통해 파티셔닝을 진행해야 한다. 이번에는 파티셔닝을 위해 PK가 없는 테이블을 만들겠다.
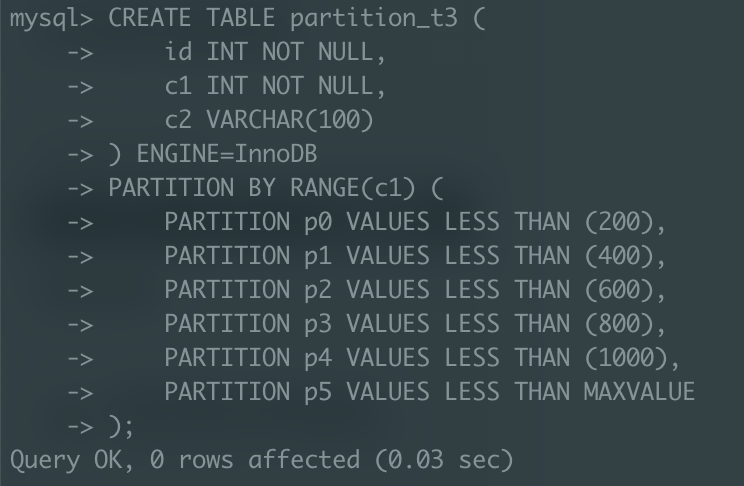
동일한 조건에서 비교하기 위해, t2 테이블의 PK 제약 조건을 해제하고, t2, t3 테이블의 id 컬럼을 삭제해주겠다.
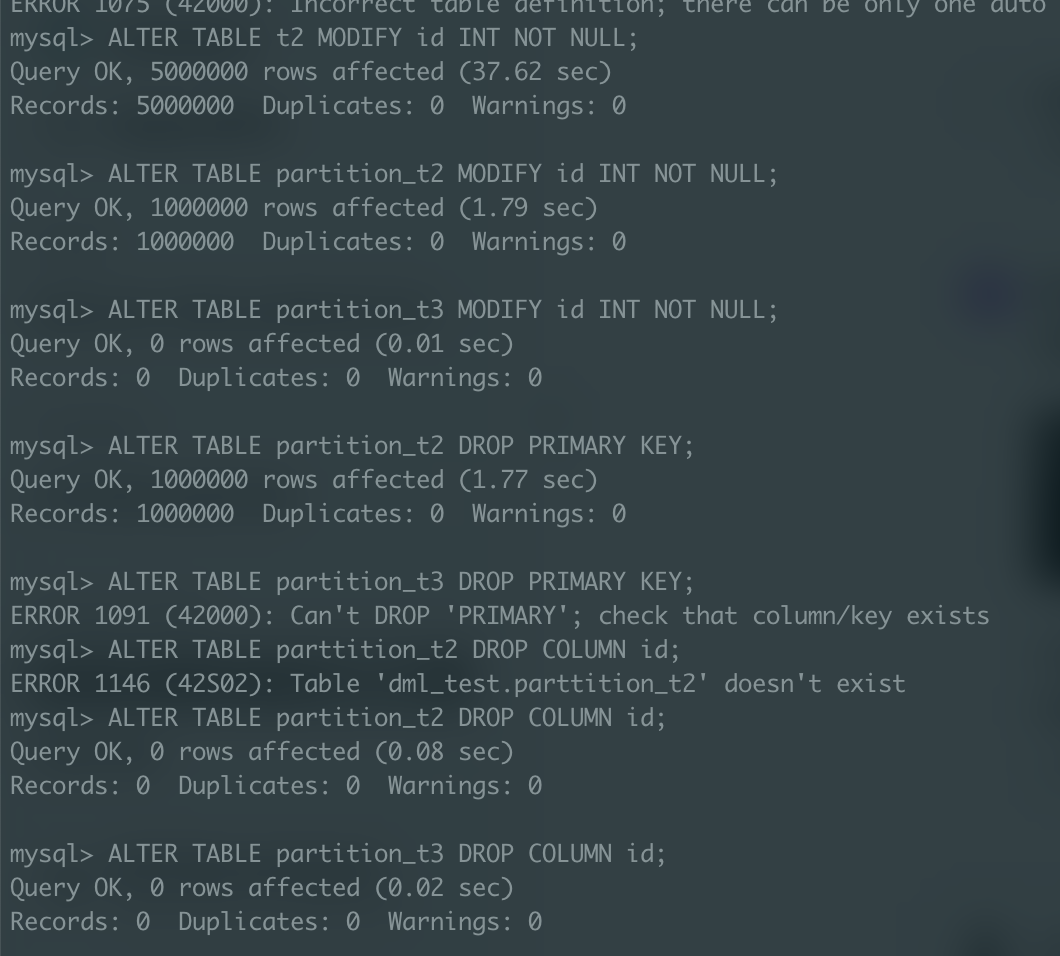
- 100만개 더미데이터 재생성 후, 각 테이블에 범위로 삽입
이제 100만개의 더미데이터를 새로 만든 다음, 각 테이블에 삽입하여 실행 시간을 비교해보겠다.
튜닝 3. PK 제약 조건 해제 및 재생성
PK 제약 조건은 INSERT 쿼리의 성능에 영향을 미치는 요소중 하나이다. 튜닝 1에서 생성한 t3 테이블의 제약 조건을 확인해보면
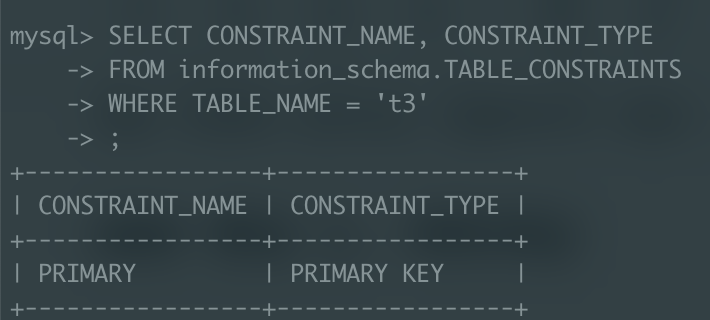
PK에 제약 조건이 걸려있는 것을 확인할 수 있다. id를 AUTO_INCREMENT PK로 지정해서 테이블을 생성했기 때문에 당연한 얘기지만, 어쨌든 PK 제약(= Unique 제약)이 걸려있는 것을 확인했고, AUTO_INCREMENT 제약 또한 삭제해서 INSERT 쿼리를 실행시켜보겠다.
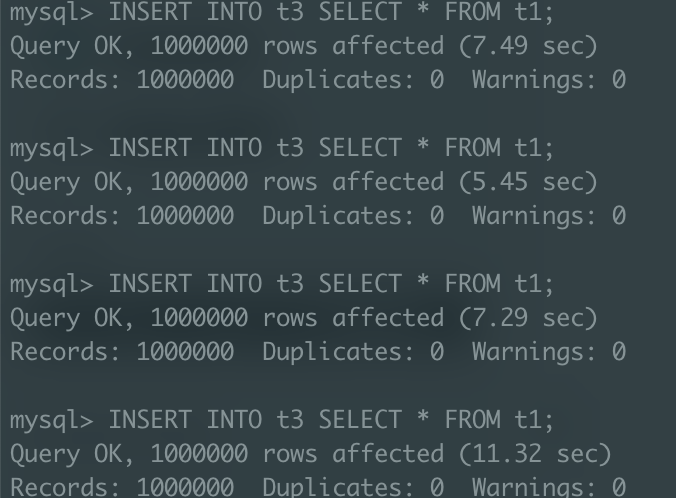
c1 컬럼 세컨더리 인덱스 O
c1 컬럼 세컨더리 인덱스 X

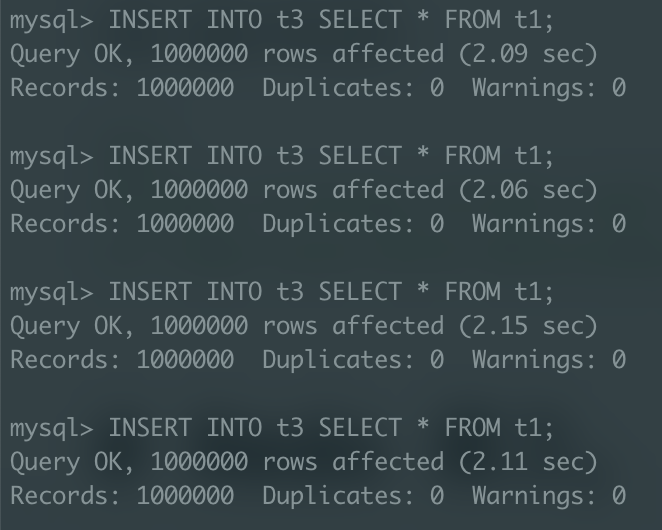
그런데, c1 컬럼에 인덱스가 없는 경우 예상한대로 속도가 개선된 반면, c1 컬럼에 인덱스가 있는 경우에는 실행속도에 별반 차이가 없어보인다. 이는 왜 그럴까?
PK가 없는 테이블의 클러스터링 키
MySQL은 기본적으로 테이블의 PK를 클러스터링 키로 지정하여 PK 기반 검색시에 빠른 성능을 보장하는데, 위 경우 PK 제약을 해제함에 따라서 MySQL 스토리지 엔진인 InnoDB는 다음과 같은 기준으로 PK를 대체해 클러스터링 키가 될 컬럼을 선정하게 된다.
- NOT NULL 옵션의 유니크 인덱스(UNIQUE INDEX) 중에서 첫 번째 인덱스를 클러스터링 키로 선택
- 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후, 클러스터링 키로 선택
위 예시 상황에서는 InnoDB 스토리지 엔진이 적절한 클러스터링 키 후보를 찾지 못하는 상황이기 때문에 2번처럼 내부적으로 레코드의 일련번호를 생성하여 클러스터링 키를 가지게 된다.
즉, 기존 4개 컬럼 + 클러스터링 키를 위한 내부적인 AUTO_INCREMENT ID까지 사실상 5개의 컬럼을 가진 테이블이 되는 것이다. 그럼에도 불구하고, 세컨더리 인덱스가 없는 두번째 경우는 PK 제약 O + 세컨더리 인덱스 X의 경우보다 실행 속도 면에서 개선된 부분을 보여주었는데, 이는 PK 제약 조건으로 걸리는 시간 > 클러스터링 키를 위한 내부 ID 생성 시간으로 이해할 수 있다.
그렇다면 세컨더리 인덱스가 있는 첫번째 경우에는 왜 저런 결과가 나왔을까?
더 정확한 비교를 위해 세컨더리 인덱스가 존재하는 케이스는 PK가 있던 t3 테이블과 똑같은 구조의 t5 테이블을 만들어서 각 10번씩 100만 건의 레코드를 INSERT하여 실행 속도를 비교해보겠다.
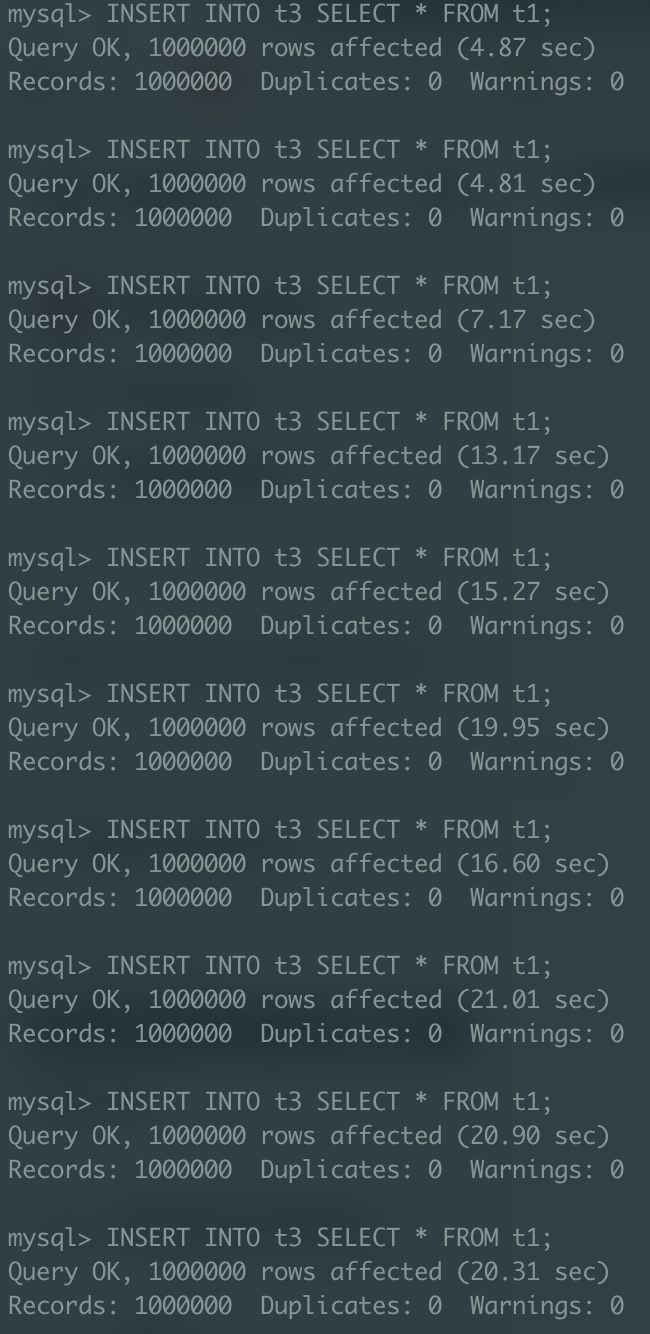
t3(PK 제약 X)
t5(PK 제약 O)
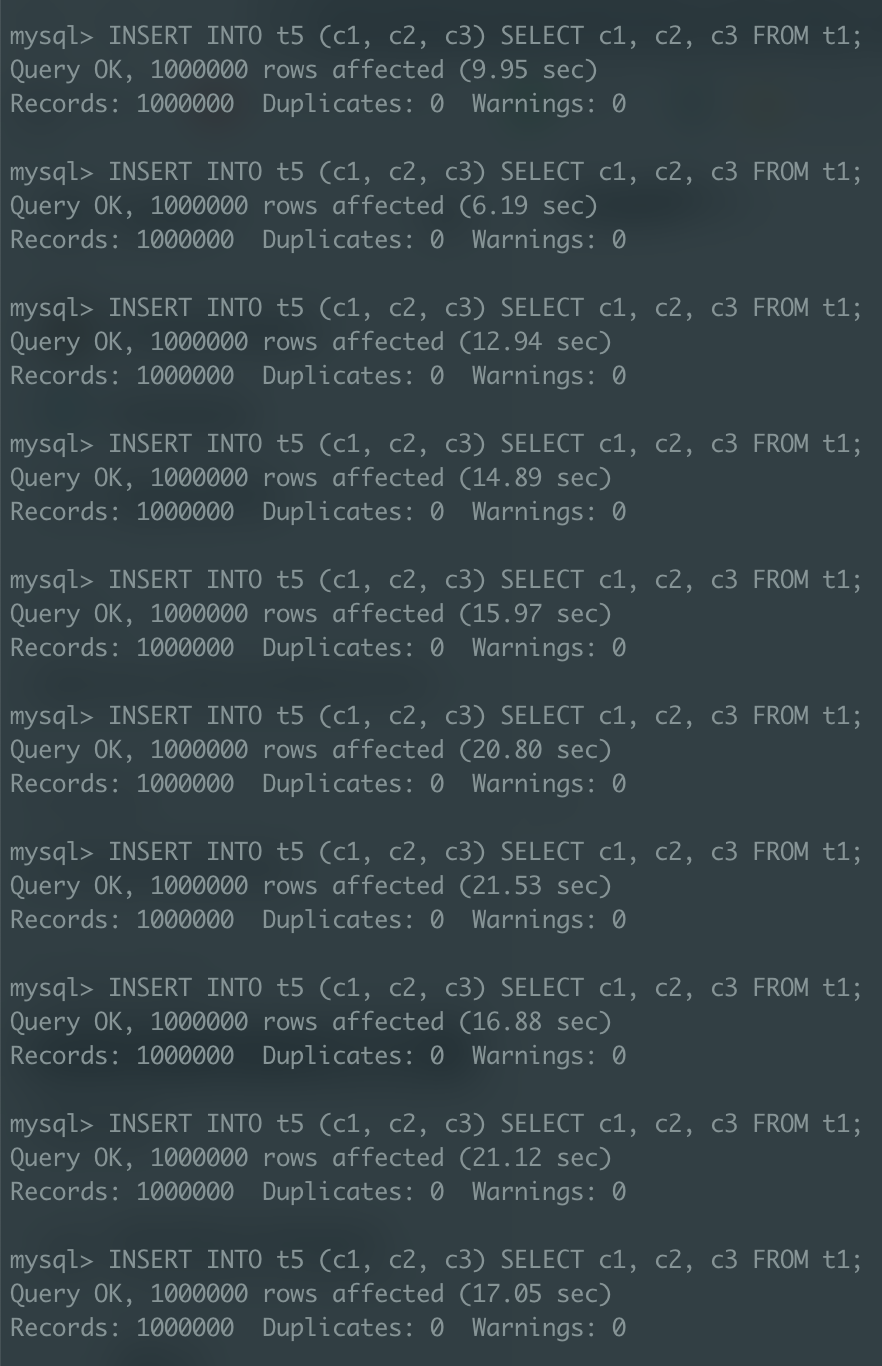
두 케이스 모두 인덱스의 사이드 이펙트로 인해 테이블에 레코드가 쌓이면서 실행 속도가 증가하는 모습을 보인다.
첫 3번의 INSERT 작업은 유의미하게 PK 제약이 없는 t3 테이블 쪽의 성능이 앞섰으나, 이후에는 속도 차이가 유의미하게 나지 않는다.
인덱스로 인해 테이블에 레코드가 쌓이면서 INSERT 실행 속도가 점차 늘어난다는 점을 빼면,=
결론
단순히 실행 속도 측면에서 해석할 경우, PK 제약을 해제할 경우 일반적인 PK를 가지고 있는 테이블보다 더 빠른 INSERT 작업이 가능할 것으로 보인다.
Redo 로그
Redo 로그 비활성화 vs 활성화 상태 100만 건 INSERT 비교
리두 로그를 비활성화 시킨 후 100만 개의 레코드를 4번씩 적재하고, 다시 활성화 시킨 후 똑같은 작업을 실행해서 속도 차이를 비교해보겠다.
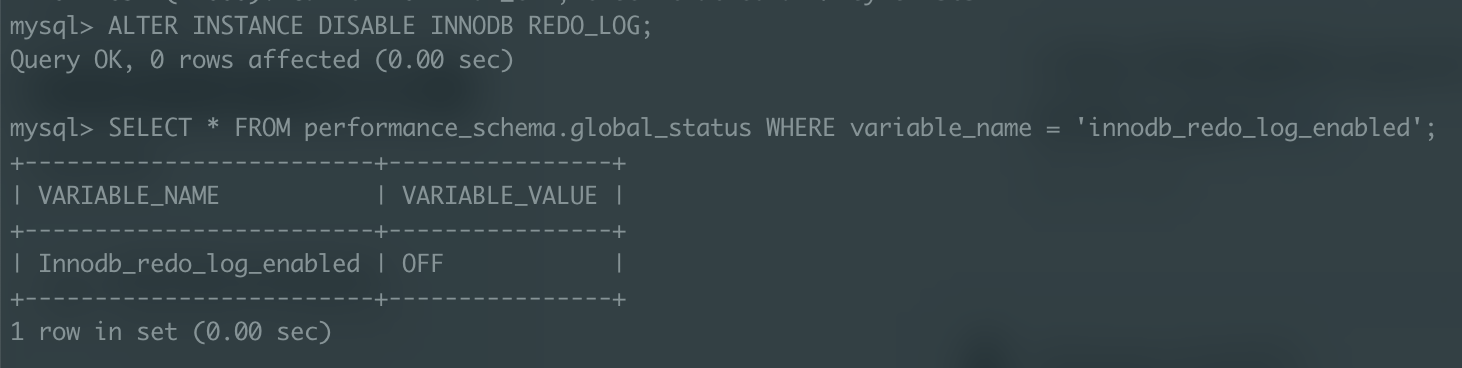
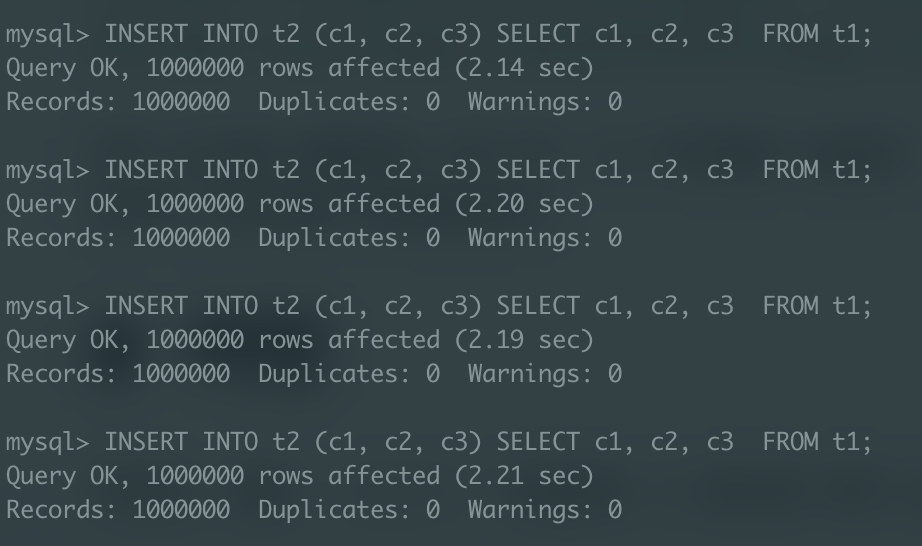
리두 로그 비활성화
리두 로그 활성화
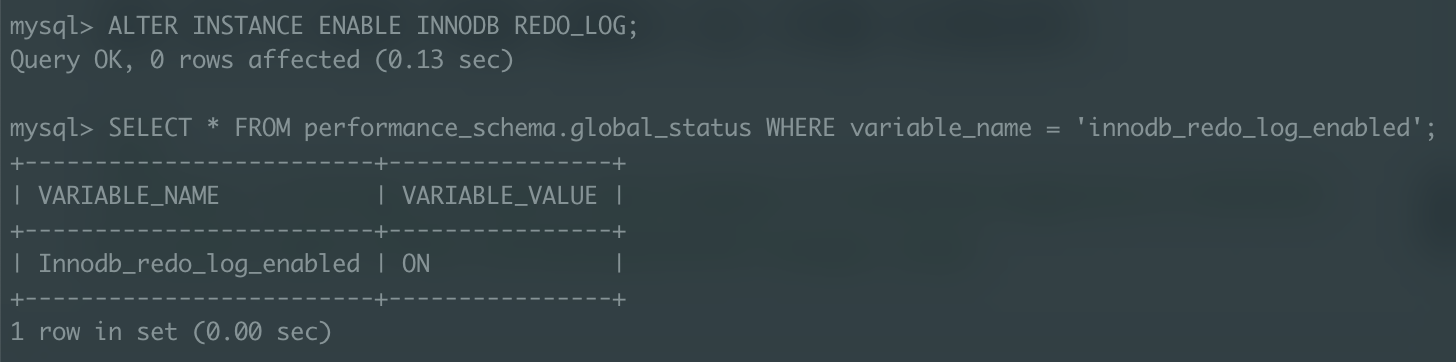
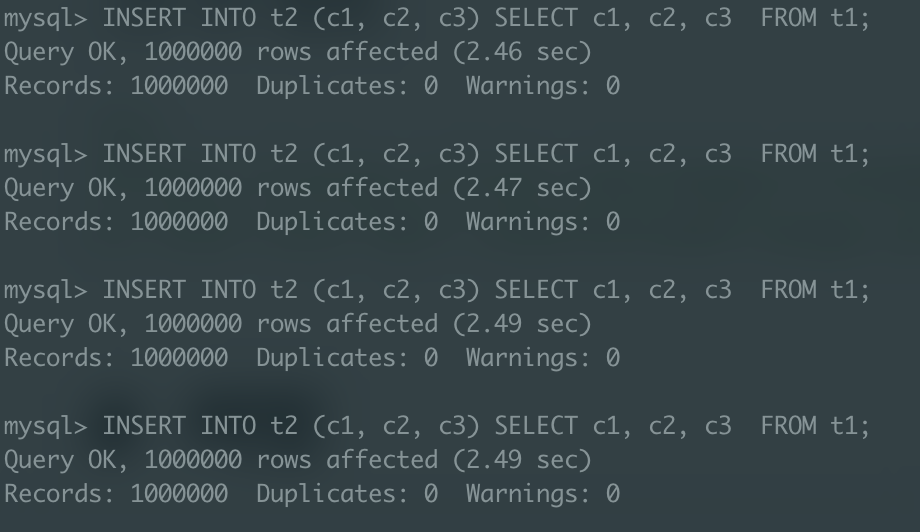
당연히 리두 로깅을 생략했기 때문에 리두 로그 비활성화 상태에서 실행한 작업이 빠를 것이라 예상할 수 있고, 실제로 실행 속도가 평균적으로 10% 정도 빠르게 나타났다.
Undo 로그
Undo 로그 비활성화 vs 활성화 상태 100만 건 INSERT 비교
마무리
이번 포스팅에서는 DML중 INSERT의 튜닝에 대해서 다뤄보았다. UPDATE, DELETE도 있지만, INSERT만 다룬 이유는 INSERT의 수행 빈도가 가장 높기도 하고, 튜닝 요소 또한 맨 처음 살펴본 것 처럼 매우 많기 때문이다. 또 Lock과 커밋은 이번에 다루지 않았는데, 이 둘은 연관성이 짙고 같이 설명하는게 좋을 것 같아서 다음 포스팅에서 다루려고 한다.
참고
