이전 포스팅에서는 쿼리 튜닝의 목적(무엇을 해결해야 하는지)에 대해서 알아보았다. 이번에는 쿼리 튜닝이 병목을 어떻게 해결하는지에 대해서 알아보려고 한다.
데이터를 찾는 방법
앞서 쿼리 튜닝이 무엇을 해결해야 하는지에 대해 다음과 같은 결론을 낼 수 있었다.
- 버퍼 풀에서 찾지 못한 데이터를 디스크에서 가져오기위해 물리적 I/O 발생
- 프로세스에 할당된 메모리와 달리, 디스크 데이터는 프로세스에게 열람 권한이 없음. 따라서 시스템 콜이 발생
- 이로 인해 물리적 I/O는 SQL의 병목을 발생시키는 가장 큰 원인이 됨
- 물리적 I/O는 코드 레벨에서 횟수를 제어할 수가 없음
- 논리적 I/O는 쿼리 튜닝을 통해 그 수를 조절할 수가 있음
- 논리적 I/O와 물리적 I/O는 비례관계에 있기 때문에 논리적 I/O의 수를 줄여서 물리적 I/O 수를 감소시킨다
결론 : 쿼리 튜닝의 목적은 논리적 I/O를 줄이는 것이다.
이 목적을 달성하기 위해서는 먼저 DB 엔진이 데이터를 어떻게 찾아오는지 알아야 한다.
- Index Range Scan :
인덱스를 이용한다 - Table Full Scan :
테이블 전체를 스캔한다
DB 엔진은 이 두 방식을 통해 테이블에 접근해서 데이터를 조회하는데, 각각 페이지를 가져오는 방식(I/O 방식)에 차이가 있다. 그렇기 때문에 각각의 I/O 방식과 특성을 이해하고 있어야 내 쿼리가 느린 원인을 찾고, 논리적 I/O의 횟수를 줄일 수 있다.
Index Range Scan vs Table Full Scan
웹에서 발생하는 요청을 처리하는 쿼리 대부분은 전체 테이블에 비해 데이터 수가 가볍기 때문에 인덱스를 설정한 경우가 대부분 효율적인 쿼리로 이루어진다.
이는 쿼리 실행시 발생하는 I/O 의 차이에서 기인한다. Table Full Scan은 테이블 내 모든 데이터를 조회하기 때문에 페이지 I/O가 무수히 일어난다. 하지만 Index Range Scan은 필요한 부분만 조회를 해서 과도한 I/O가 발생하지 않는다. 이같은 내용은 MySQL 공식문서에서도 확인할 수 있다.
MySQL에서

MySQL 공식문서, 특정 컬럼 값을 갖는 row를 빠르게 찾을 때 아주 유효하다는 내용이다
웹 애플리케이션의 경우 테이블 내에서 소수의 데이터를 조회하는 경우가 대다수이기 때문에 인덱스를 생성하면 대부분 개선이 이루어진다. 하지만 통계 쿼리나 배치 작업 등 전체 테이블에서 상당수 데이터를 필요로 하는 경우 인덱싱이 효율적인지에 대해서 의심해봐야 한다. 이는 Table Full Scan시 페이지를 I/O하는 방식에서 알 수 있다.

MySQL 공식문서, 작은 테이블이나 큰 테이블에서 많은 행을 처리할 경우에는 Table full scan이 더 효율적이라는 내용
Single Block I/O vs Multiblock I/O
Table Full Scan은 해당 테이블에 해당하는 페이지(블록)를 모조리 가져와야 하기 때문에 한 번의 시스템 콜에 여러 개의 페이지를 가져와서 메모리 캐시(버퍼 풀)에 적재한다. 이러한 방식의 I/O를 Multiblock I/O라고 한다(다만, MySQL에서 따로 페이지 개수에 따른 I/O 방식을 설명하는 부분은 찾아보기가 힘들었다... 혹시 아는 분이 있다면 댓글로 알려주시면 감사하겠습니다)

MySQL 공식문서에서 설명하는 인덱스 자료구조
Index Range Scan은 인덱스 테이블에서 B-트리 형태로 정렬된 인덱스 중 찾은 인덱스를 가져와 다시 디스크에 해당 row를 요청하게 된다. 그렇기 때문에 하나의 row를 가져오는데 한 번의 I/O가 발생하게 된다. 이러한 방식의 I/O를 Single Block I/O라고 한다.
시퀀셜 액세스 vs 랜덤 액세스
시퀀셜 액세스 : 논리적 혹은 물리적으로 연결된 순서에 따라 차례대로 페이지(블록)을 읽는 방식(순차적으로 스캔)
랜덤 액세스 : 논리적 혹은 물리적인 순서를 따르지 않고 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식
시퀀셜 액세스는 Table full scan에서 사용된다. 읽어야 할 익스텐트의 첫 번째 페이지부터 순서대로 읽는 것이다.
랜덤 액세스는 Index range scan에서 사용된다. 인덱스 테이블에서 인덱스가 가리키는 목표 페이지 위치로 곧바로 접근하게 된다.
예시
추상적인 예시 하나를 들어보겠다. 100만 건의 데이터가 있는 테이블에서 50만 건의 데이터를 조회하는 경우와 100 건의 데이터를 조회하는 경우 를 생각해보면 이 두 방식이 어떤 경우에 효율적인지 알 수 있다.
첫 번째 경우는 Table Full Scan이 유리할 것이다. 이 쿼리를 Index Range Scan으로 실행했을 경우, 50만 건의 Single I/O가 발생하게 된다. 반면에 Table Full Scan의 경우 여러 개의 페이지(블록)을 한 번의 I/O에서 처리하기 때문에 훨씬 더 적은 횟수의 디스크 I/O가 발생할 것이다.
두 번째 경우는 Index Range Scan이 유리할 것이다. 100개의 데이터를 찾기 위해서 테이블 전체를 스캔하게 되면, Buffer Pool에서 테이블 전체 데이터를 찾고, 존재하지 않는 데이터의 수 만큼 물리적 I/O가 발생하는 비효율적인 상황이 벌어진다. 반면에 Index Range Scan은 Buffer Pool에서 못찾은 I/O 웹 애플리케이션에서 일어나는 트랜잭션은 BCHR 99%를 달성할 수 있도록 튜닝하는 것을 목표로 잡으면 좋다고 한다!
❗ 인덱스 적용시 사이드 이펙트 ❗
하지만 CREATE/UPDATE/DELETE가 활발한 테이블의 경우, 무지성으로 인덱스를 생성하는 것은 지양해야 한다.
DB의 테이블 스페이스에 인덱스를 위한 공간적 비용이 발생하는 점, 인덱스의 자료구조(B-tree)로 인해 인덱스의 생성, 수정, 삭제에 시간적 비용이 발생하는 점 등을 고려해서 인덱스를 생성하는 것에 대한 의사결정을 진행해야 한다.
이 부분은 인덱스 자체에 대한 더 깊은 이해가 필요하기 때문에, 참고하기 좋은 블로그 링크를 달아두고 나중에 자세히 다룰 예정이다.
SQL 예제
이제 위에서 익힌 Table full scan과 Index range scan를 예제를 통해서 구체화시켜볼 차례다.
데이터는 더미 데이터 생성 포스팅에서 생성한 것을 사용한다.
통계 쿼리
쿼리 설명
최근 한달 간 가장 많은 콘텐츠(게시물 + 댓글)를 생산한 사용자를 찾는 쿼리이다.
예상대로라면, 테이블 내 많은 row를 조회하기 때문에 Table full scan이 더 우수한 성능을 보일 것이다.
SQL
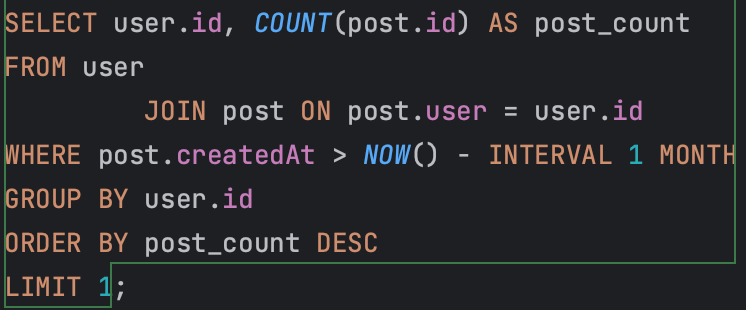
table full scan
실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | post | null | ALL | user | null | null | null | 99552 | 33.33 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | user | null | eq_ref | PRIMARY | PRIMARY | 8 | community.post.user | 1 | 100 | Using index |
아무런 튜닝 없이 실행한 순정 상태의 쿼리 실행계획이다.
type 컬럼에서 All이라는 내용이 보이는데, post 테이블을 table full scan하고 있는 것을 알 수 있다.
심지어 사용 가능한 인덱스에 user id가 있는데도 불구하고 table full scan을 선택하여 페이지를 가져오고 있다.
-> Limit: 1 row(s) (actual time=363.309..363.309 rows=1 loops=1)
-> Sort: post_count DESC, limit input to 1 row(s) per chunk (actual time=363.308..363.308 rows=1 loops=1)
-> Table scan on <temporary> (actual time=362.487..363.023 rows=9999 loops=1)
-> Aggregate using temporary table (actual time=362.486..362.486 rows=9999 loops=1)
-> Nested loop inner join (cost=15476.31 rows=33181) (actual time=0.940..335.851 rows=100000 loops=1)
-> Filter: (post.createdAt > <cache>((now() - interval 1 month))) (cost=3863.07 rows=33181) (actual time=0.919..22.633 rows=100000 loops=1)
-> Table scan on post (cost=3863.07 rows=99552) (actual time=0.899..18.085 rows=100000 loops=1)
-> Single-row covering index lookup on user using PRIMARY (id=post.`user`) (cost=0.25 rows=1) (actual time=0.003..0.003 rows=1 loops=100000)총 실행 시간은 363.309ms이다.
Index range scan
힌트를 사용한 SQL
user 인덱스를 사용하도록 옵티마이저 힌트를 사용해서 실행 계획을 살펴보겠다.
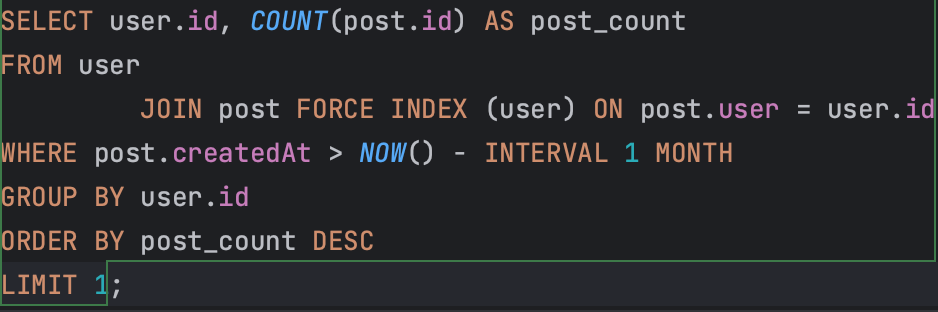
이제 실행 계획을 살펴보자.
실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | user | null | index | PRIMARY | PRIMARY | 8 | null | 9854 | 100 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | post | null | ref | user | user | 8 | community.user.id | 9 | 33.33 | Using where |
key 컬럼을 보면 옵티마이저 힌트대로 user 인덱스를 사용하고 있다.
-> Limit: 1 row(s) (actual time=175.398..175.398 rows=1 loops=1)
-> Sort: post_count DESC, limit input to 1 row(s) per chunk (actual time=175.397..175.397 rows=1 loops=1)
-> Stream results (cost=37212.70 rows=31478) (actual time=0.234..174.760 rows=9999 loops=1)
-> Group aggregate: count(post.id) (cost=37212.70 rows=31478) (actual time=0.233..173.937 rows=9999 loops=1)
-> Nested loop inner join (cost=34064.90 rows=31478) (actual time=0.144..170.037 rows=100000 loops=1)
-> Covering index scan on user using PRIMARY (cost=1009.65 rows=9854) (actual time=0.044..1.455 rows=10000 loops=1)
-> Filter: (post.createdAt > <cache>((now() - interval 1 month))) (cost=2.40 rows=3) (actual time=0.014..0.016 rows=10 loops=10000)
-> Index lookup on post using user (user=`user`.id) (cost=2.40 rows=10) (actual time=0.014..0.016 rows=10 loops=10000)그런데 실행 시간은 예상과 다른 결과가 나왔다. Table full scan보다 약 두 배 빠른 175ms 라는 실행 시간이 나왔다.
원인 분석
왜 옵티마이저는 Table full scan을 선택하였는가?
옵티마이저는 속도가 더 느린 Table full scan을 선택하였는데, 이게 어떻게 된 것일까. MySQL 공식문서에 따르면 Table full scan은 다음과 같은 상황에서 발생한다고 되어있다.

MySQL 공식문서 - Table full scan이 일어나는 경우
- 테이블 크기가 매우 작은 경우
- ON절이나 WHERE절에서 활용할 수 있는 효과적인 인덱스가 없을 경우
- 인덱스가 커버해야하는 범위가 클 경우 -> 탐색하는 데이터의 조건이 전체 테이블에서 많은 수의 row가 쿼리에서 탐색하는 데이터의 조건에 부합하는 경우
- key가 낮은 카디널리티를 갖는 경우 -> 특정 키 값에 집중되어 있을 경우 해당 키 값을 반복해서 읽어야하기 때문에 효율성이 떨어진다고 판단

MySQL 공식문서 - Table full scan
위 공식문서 설명에서도 Table full scan은 테이블이 작아서 Buffer pool에 모두 담기는 경우, 대규모 테이블에서 모든 사용 가능한 데이터를 집계하고 분석하는 경우에 사용된다고 한다.
이를 고려했을 때, 이 예제에서 Table full scan이 선택된 근거는 3번째 경우에 해당할 것이다. 전체 테이블에 비해 createdAt 필드가 1달 이내인 조건에 해당되는 row가 30% 이상에 달한다. 그렇기 때문에 실행계획의 cost에서도 Table full scan의 비용이 더 낮게 산정된 것을 알 수 있다. 옵티마이저는 비용 기반으로 실행 계획을 선택하는 것을 잊지말자.
하지만, 전체 쿼리 실행 속도는 Index range scan이 빨랐다.
그럼 더 빠른 Index range scan이 효과적인 것 아닌가?
post 테이블의 데이터를 I/O하는 실행계획 구문을 가져와서 비교해보자.
-
Table full scan
-> Filter: (post.createdAt > <cache>((now() - interval 1 month))) (cost=3454.32 rows=33181) (actual time=0.291..24.809 rows=100000 loops=1)
-> Table scan on post (cost=3454.32 rows=99552) (actual time=0.188..19.860 rows=100000 loops=1) -
Index range scan
-> Filter: (post.createdAt > <cache>((now() - interval 1 month))) (cost=2.40 rows=3) (actual time=0.014..0.016 rows=10 loops=10000)
-> Index lookup on post using user (user=user.id) (cost=2.40 rows=10) (actual time=0.014..0.016 rows=10 loops=10000)
Table full scan은 10만 개의 데이터를 1번의 loop에 모두 탐색하여 필요한 row(한 달 이내 post)를 필터링하는데 총 24.809 ms의 실행시간을 기록하였다.
Index range scan는 10만 개의 데이터를 10개씩 1만 번에 나눠서 I/O를 진행하고 있다. 실행 시간을 계산해보면 0.015(평균치) * 10000 = 약 150ms의 실행 시간이 걸렸음을 알 수 있다.
결과적으로 위 예시처럼 큰 테이블에서 많은 row(10만 개중 33181개)를 탐색해야 하는 경우에는 Table full scan이 더 빠른다는 것을 확인할 수 있다.
속도차이가 나는 이유
-
Index range scan실행 계획에서 user 테이블에Join하는 구간을 보면, 약 20ms 밖에 소요되지 않은 것을 알 수 있다. post 테이블에서 user 테이블을 join 할 때, user 테이블을 모두 탐색하지 않고 곧바로 필요한 row를 찾을 수 있기 때문이다. -
Table full scan의 경우 정렬을 위해서 임시 테이블을 생성하여 중간 결과를 저장한 다음, 이 테이블을 다시 스캔하여 row를 정렬하고 있다. Index는 이미 정렬된 값이기 때문에 이 부분에서도 차이가 난다.
결론
쿼리의 특성을 파악해서 큰 데이터 셋에서 소량의 레코드를 찾기 위해서는 Index Range scan, 전체 테이블 크기 대비 많은 레코드에 접근하는 경우에는 Table full scan이 대체로 좋다는 것을 알고 가면 될 것 같다. 이 차이는 모두 디스크 I/O의 횟수 차이에 기인하는 것을 잊지 말자.
예제와 함께 쿼리 튜닝은 어떻게 I/O 병목을 해결하는지 알아보았다. 다음 포스팅에서는 지금까지 사용한 인덱스가 무엇인지 알아보고, 이를 활용한 튜닝에 대해서 더 자세히 알아보려고 한다.
참고
