이전 포스팅에서 쿼리 튜닝으로 SQL 병목을 해결하는 원리까지 알아보았다. Table full scan과 Index range scan을 적절하게 사용해 논리적 I/O를 줄여서 디스크 I/O의 수를 간접적으로 줄이는 것이 쿼리 튜닝의 목적이였다.
또한, 지난 예제들에서 논리적 I/O를 감소시키는 관점에서 Index Range Scan과 Table Full Scan의 차이를 확인할 수 있었다.
하지만 인덱스를 활용한 튜닝을 진행했음에도, 인덱스 자체에 대한 이해는 없이 해당 튜닝이 이루어졌었다. 인덱스가 어떻게 저장되고, 어떤 식으로 탐색이 되는지 원리를 알아야 더 정확한 근거를 가지고 쿼리 튜닝을 진행할 수 있을 것이다.
따라서 이번 포스팅에서는 인덱스의 구조와 원리에 대해서 알아볼 것이다.
B+tree
먼저 인덱스가 페이지(혹은 블록)에 어떻게 저장되는지 알아보자.
MySQL의 스토리지 엔진인 InnoDB 기준으로, 인덱스는 B+tree라는 자료구조로 저장된다(대부분의 엔진이 그렇다고 한다). MySQL 공식문서에서는 B-tree라는 용어를 사용해서 혼동이 왔는데, InnoDB 공식문서에서는 B+tree를 사용한다고 설명하고 있다.

노드
B+tree는 두 가지 타입의 노드를 갖는다.
- 리프 노드 : 트리의 최하단에 있는 노드. 실제 레코드에 대한 포인터와 키를 포함한다. 또한, 키는 정렬된 순서로 저장된다.
- 내부 노드 : 루트 노드 아래에 있는 노드. 키 값 + 자식 노드들에 대한 포인터를 포함
정점 노드는 위 두 가지 노드중 하나가 될 수도 있고, 아닐수도 있다.
InnoDB의 B+tree 구조
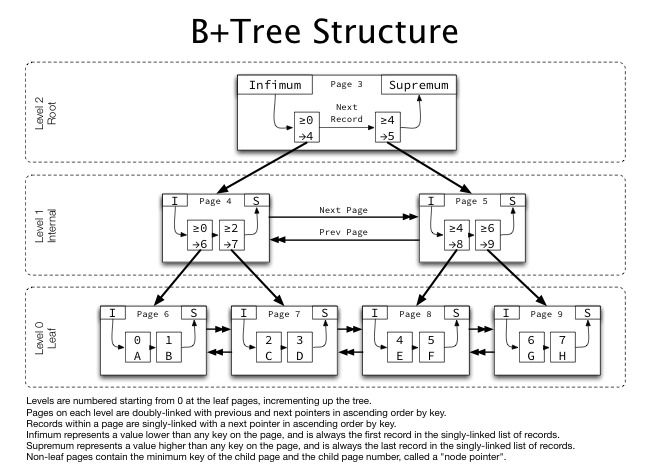
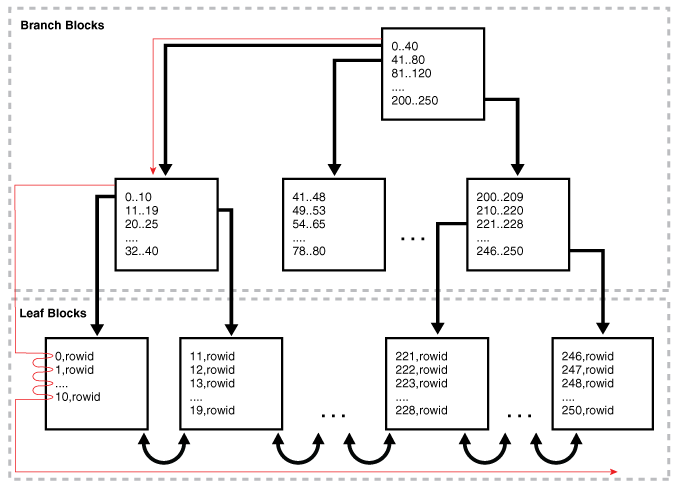
InnoDB는 위에서 설명한 대로, 한 개의 루트 노드, 그리고 내부 노드와 리프 노드로 이루어져 있다. 또한 각각의 노드는 페이지 단위로 이루어져 있다. 여기서 주목할 점은, 같은 레벨의 노드 끼리는 double linked list라는 점이다. 뒤에서 설명하겠지만, 이 것은 노드의 수평적 탐색 방향이 한 방향으로 한정되지 않다는 것을 의미한다.
InnoDB 인덱스 페이지 구조
InnoDB에서 데이터에 접근하는 최소 단위는 페이지이다. 인덱스 또한 페이지 안에 저장이 되기 때문에 한 페이지에 여러 개의 인덱스가 저장된다. 다음은 InnoDB 공식문서에서 설명하는 내부 노드 + 리프 노드의 페이지 내부구조이다.
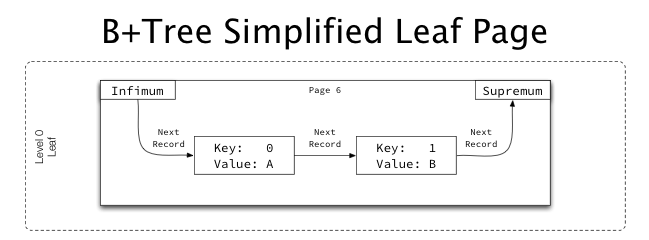
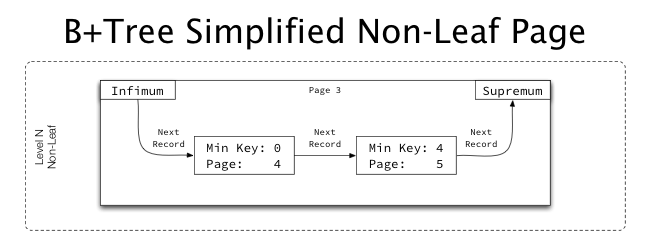
아래는 InnoDB의 전체적인 인덱스 트리 구조이다.
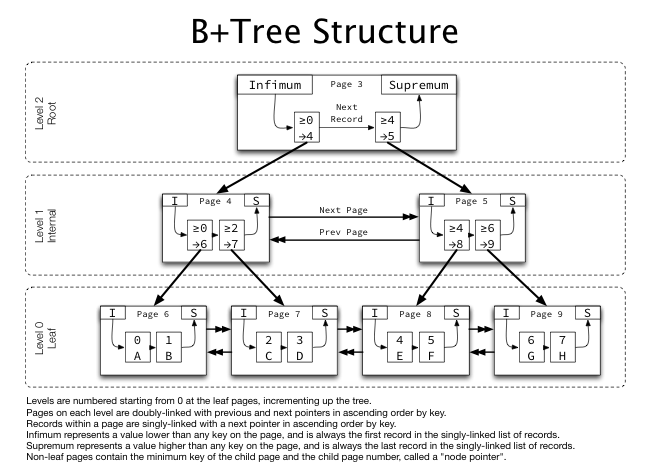
여기서 주목할 것은, 페이지 끼리는 double linked list이지만 페이지 내부는 single linked list라는 점이다. 이로 인해 인덱스 트리를 오름차순으로 생성할지, 내림차순으로 생성할지, 그리고 인덱스 트리를 탐색하는 방향에 따라서도 SQL의 성능에 영향이 간다.
이에 대한 자세한 내용은 이 글을 보면 이해가 잘 될 것이다.
인덱스의 탐색
InnoDB가 인덱스를 어떻게 생성하고 탐색하는지 알아보았다. 이번에는 인덱스트리의 탐색구조를 알아보자.
인덱스는 말 그대로 색인이다. 우리가 일상에서 읽는 아날로그 책의 색인을 떠올려 보면, 어떤 정보의 색인(PK, 혹은 인덱스를 설정한 컬럼값)이 있고 해당 정보가 나오는 쪽수(위치)를 통해 해당 정보로 찾아갈 수 있게 된다.
DB에서 사용하는 인덱스도 마찬가지다. 인덱스 트리에서 인덱스를 탐색하고, 인덱스로부터 실제 데이터(혹은 실제 데이터의 위치)를 얻어서 실제 데이터가 있는 페이지(블록)에 접근한다.
Index Range Scan
이전 포스팅에서 Table Full Scan과 Index Range Scan을 비교한 적이 있다.
지금까지 사용했던 Index Range Scan은 어떤 방식으로 인덱스 트리를 탐색할지 알아보자.
수직적 탐색
인덱스 트리를 위에서 아래로 탐색하는 과정이다. 특정 키 값 또는 범위에 해당하는 데이터를 찾기 위해 인덱스 레벨을 내려가며 탐색한다.
Index Range Scan에서 발생하는 수직적 탐색은, 리프 노드 탐색의 시작점이 되는 부분까지 수직적 탐색으로 이동하게 된다.
수평적 탐색
인덱스 노드 내에서 같은 레벨의 노드를 탐색하는 과정이다. 다음과 같은 경우 수평적 탐색이 일어나게 된다.
범위의 시작점을 찾은 후, 해당 리프 노드에서부터 시작하여 지정된 범위에 해당하는 리프 노드를 수평으로 탐색합니다. 범위의 끝에 도달할 때까지 이 탐색을 계속한다.
클러스터드 인덱스, 넌 클러스티드 인덱스
클러스터드 인덱스

클러스터드 인덱스는 InnoDB 테이블의 데이터를 저장하는 인덱스이다. 크게 두 가지 특징이 있으며 다음과 같다.
- 실제 데이터의 물리적인 저장 순서와 같이 저장된다.
- 리프노드에 PK와 함께 실제 데이터가 인덱스 페이지에 저장된다.
이러한 특징은 데이터 검색 시에 유리한 구조를 만들어준다.
-
인덱스와 실제 데이터의 물리적인 순서가 같기 때문에 더 적은 개수의 페이지에 접근하게 된다.
-
클러스터드 인덱스와 함께 실제 데이터가 저장되어 있기 때문에, 인덱스를 탐색한 후 다시 디스크에 접근할 필요가 없다.
넌클러스터드 인덱스

MySQL 공식문서에서는 클러스터드 인덱스 이외의 인덱스를 Secondary Index라고 한다. 편의상 넌클러스터드 인덱스라고 부르겠다. 넌클러스터드 인덱스는 클러스터드 인덱스와 다르게 실제 데이터에 대한 키 값(보통 PK)과 인덱스 컬럼의 값만 저장되어있다. 탐색 범위에 해당하는 값을 찾으면, 함께 저장되어있는 인덱스 키 값으로 실제 데이터에 대한 접근을 진행하는 셈이다.
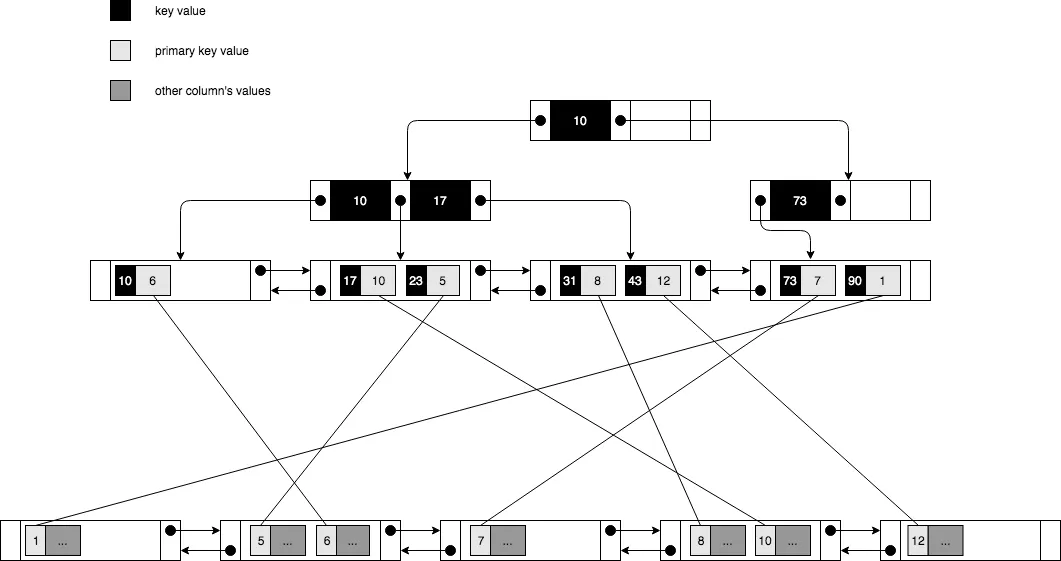
위와 같은 구조로 저장되어있기 때문에 넌클러스터드 인덱스의 경우 I/O가 발생하는 횟수가 훨씬 많다. 이는 물리적인 순서와 관계없이 인덱스 컬럼값을 기준으로 정렬되어있기 때문이다.
클러스터링 팩터(CF)
클러스터링 팩터는 인덱스의 정렬 순서와 실제 데이터의 물리적인 순서가 얼마나 일치하는지를 나타내는 값이다.
클러스터드 인덱스의 경우 당연히 CF가 좋다고 할 수 있고, 넌클러스터드 인덱스는 경우에 따라서 천차만별이라고 할 수 있다. 넌클러스터드 인덱스의 CF를 개선하면 당연히 랜덤 I/O가 줄어들 것이기 때문에 쿼리 성능 개선이 이루어지겠지만, 이는 최후의 수단으로 남겨두는 것이 좋다고 한다.
복합 컬럼 인덱스
지금까지는 단일 컬럼 인덱스에 대한 내용을 주로 다루었다. 그런데 인덱스는 단일 컬럼 인덱스만 존재하는 것은 아니다. 여러 개의 컬럼을 합쳐서 인덱스를 만들 수도 있는데, 이 때 가장 중요한 것은 합칠 때 선두에 오는 컬럼이다.

MySQL 공식문서 예제를 통해서 쉽게 이해해보자.
MySQL 또한 복합 컬럼 인덱스를 생성할 수 있다. 최대 16개의 컬럼까지 합쳐서 생성할 수 있으며 인덱스의 컬럼 순서가 올바르게 구성될 경우, 여러 쿼리에서 성능을 가속화시킬 수 있다고 한다.

위 쿼리에서는 test 테이블의 last_name, first_name 컬럼으로 복합 인덱스를 생성하고 있다.
last_name, first_name으로 인덱스가 생성되면, 인덱스 트리에서는 last_name순으로 정렬이 되고, 같은 last_name을 갖는 인덱스 끼리는 first_name 순으로 정렬이 된다.
이러한 구조를 가지고 인덱스를 활용하고자 하면, 인덱스는 다음과 같은 쿼리에서 작동한다.
last_name에 대한 조건이 포함된 쿼리last_name과first_name을 모두 조건으로 하는 쿼리
만약 first_name만 포함된 쿼리의 경우, 이 복합 인덱스는 활용하지 못한다. 인덱스 탐색의 시작점을 찾지 못하는데, 1차적으로 last_name 기준 정렬이 되어있기 때문.
예시
first_name이 "철X"인 경우를 찾는다고 가정하자. "철X" 라는 이름을 가진 사람은 last_name이 김, 이, 박, 최 무엇이든 될 수 있다. 그런데 인덱스는 last_name을 기준으로 먼저 정렬이 되어있기 때문에 김씨는 김씨끼리, 이씨는 이씨 끼리 모여있다. "철X"를 찾기 위해서는 김씨, 이씨, 박씨, 최씨 인덱스를 모조리 뒤져서 찾는 수 밖에 없다.
반면에 김씨 성을 가진 "철X"를 찾는 것은 간단하다. 우선, last_name으로 정렬이 되어있기 때문에 김으로 정렬되어있는 범위를 찾는다. last_name을 찾은 다음은 first_name으로 정렬되어있기 때문에 "철X"로 시작하는 지점을 쉽게 찾을 수 있다.
정리하자면 다음과 같다.
- 복합 컬럼 인덱스는 가장 좌측에 있는 컬럼을 기준으로 우선 정렬 된다.
- 두 번째, 세 번째, 네 번째 ... 그 다음 컬럼 순대로 정렬이 이루어진다.
- 복합 컬럼 인덱스를 이용하기 위해서는 좌측 접두사(prefix)형태로 조건을 걸어야 한다.
col1,col2,col3의 복합 인덱스인 경우, (col1),(col1,col2), (col1,col2,col3) 의 형태로 조건을 걸어야 사용이 가능하다. (col1,col3) 등과 같은 방식으로 사용하면 복합 인덱스를 사용할 수 없다.
결론
인덱스의 원리와 동작 방식에 대해서 알아보았다.
인덱스는 매우 복잡하고 방대한 주제이다. 그렇기 때문에 이번 포스팅에서는 놓친 부분도 많을 것으로 예상되는데, 더 공부를 해서 내용을 채워보겠다.
이번 포스팅에서는 Index Range Scan만 다루었지만 Index Skip Scan, Index Full Scan 등 인덱스를 활용한 다양한 인덱스 트리 탐색 방식이 있다. 다음 포스팅에서 이에 대해 다룰 예정이다.
이번 기회로 인덱스를 어느 정도 이해하게 되었다고 생각하는데, 인덱스를 제대로 알고나면 어떤 식으로 설계해야 할지 감이 잡히는듯 하다. 여기서 인덱스 튜닝을 통해서 얻고자 하는 최종적인 목표는 랜덤 I/O 횟수의 감소임을 잊지말자.
참고
