[논문리뷰] Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory (2025, Wei et al., Google DeepMind & UIUC)
AI 논문리뷰(AI Paper)
📖 논문 : https://arxiv.org/pdf/2511.20857v1
GitHub / HuggingFace : X (미공개)
학회 / 연구기관 : arXiv:2511.20857 / © 2025 Google DeepMind
Ⅰ. 논문 개요
본 논문은 LLM 에이전트의 ‘자기-진화(Self-evolving) 메모리’ 능력을 정량적으로 평가하기 위한 새로운 벤치마크 Evo-Memory를 제안한다. 기존 연구가 대체로 대화 맥락 저장·검색 수준의 정적 메모리를 다룬 반면, 본 논문은 과거 경험을 저장·검색·진화시키며 점진적으로 더 잘 학습하는 능력(test-time learning)을 핵심 문제로 삼는다.
저자들은 이를 위해 기존 벤치마크를 스트리밍(streaming) task sequence로 재구성하고, LLM이 경험을 재사용하고(memory reuse), 필요시 기억을 정리·갱신(evolution)하며, 추론-행동-메모리 업데이트를 반복하는 구조를 평가할 수 있도록 설계하였다.
Ⅱ. 연구 배경
최근 LLM 에이전트는 브라우저 제어, 도구 사용, 멀티스텝 추론 등 고도화되고 있다. 그러나 대부분의 연구는 단일 세션 안에서의 대화 맥락 관리 수준에 머무르며, 다음과 같은 한계를 갖는다.
-
정적 메모리 한계
기존 연구(MemGPT, SelfRAG 등)는 검색 가능한 factual memory 중심으로,
“이전에 말한 사실을 기억하는가?”에 초점을 두었다. -
경험의 전략적 재사용 결여
LLM은 동일한 유형의 문제를 반복해도 전략을 축적하지 못하고, 매번 처음부터 문제를 푼다. -
테스트 시점(Test-time)에서의 연속 학습 부재
모델이 배포된 이후 사용 과정에서 ‘성능이 더 나아지는지’ 측정하는 체계가 부족했다.
이에 본 논문은 실제 인간형 에이전트처럼 장기간 상호작용 속에서 성장하는 능력, 즉 지속적 적응(continual adaptation)을 평가하는 통합 벤치마크를 제안한다.
Ⅲ. 핵심 제안 및 구조
1. Evo-Memory 벤치마크 개념
Evo-Memory는 기존 정적 데이터셋을 순차적(task stream) 형태로 재배치하여, 에이전트가
① 검색(Search)
② 합성(Synthesis)
③ 진화(Evolve)
를 반복 수행하도록 강제한다.
- Search: 현재 입력에 맞는 과거 경험을 메모리에서 탐색
- Synthesis: 검색된 기억을 하나의 워킹 콘텍스트로 재구성
- Evolve: 문제 해결 후 메모리에 새로운 경험을 저장, 필요 시 기존 기억 삭제·정리
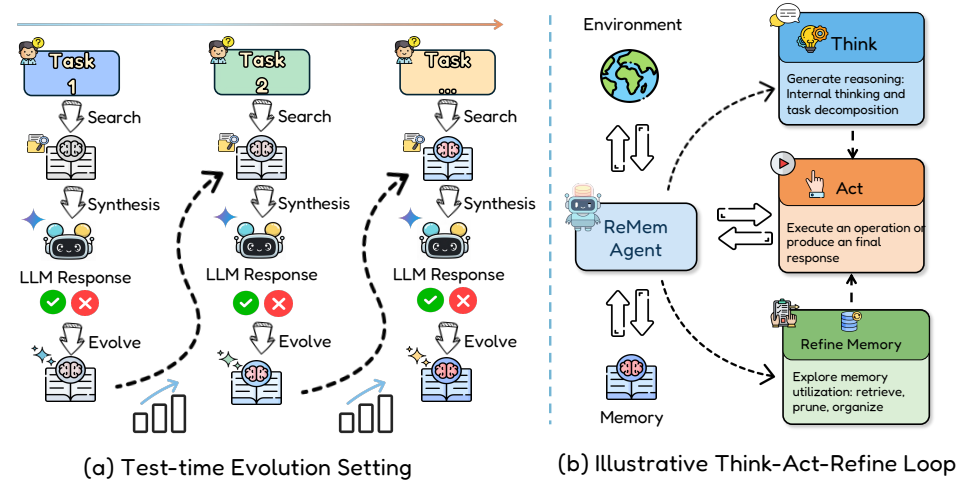
Figure 3 | Overview of the ReMem agent framework. Left: Test-time evolution process where the agent iteratively searches, synthesizes, and evolves its memory across multiple tasks. Right: Agent architecture with three core modules—Think (reasoning and decomposition), Refine Memory (retrieve, prune, organize), and Act (execution)—that interact with the environment and learned memory.
Figure 3 에 따르면 전체 구조는 Think → Act → Refine Memory 의 3단계 루프로 구성되는 것이 핵심이다.
2. ExpRAG: 경험 기반 검색(baseline)
저자들은 단순하지만 강력한 기준선 모델 ExpRAG를 제시했다.
- 과거 경험을 텍스트로 저장
- 현재 입력과 가장 유사한 k개 경험을 검색
- 해당 경험을 in-context prompt로 삽입해 문제 해결
- 결과를 다시 메모리에 누적
즉, ‘경험을 불러와 보여주는 확장된 ICL(In-context learning)’ 구조이다.
3. ReMem: 제안된 핵심 프레임워크
ReMem은 본 논문의 핵심 기여로, 기존 ReAct 등의 추론 방식에 메모리 정제(Refine) 기능을 추가했다.
- Think: 내부 추론 경로 생성
- Act: 행동 실행 또는 최종 답변 생성
- Refine: 불필요한 경험 삭제, 중요한 경험 재구조화
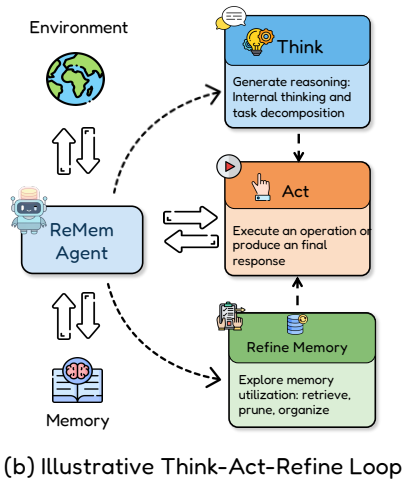
Refine 단계가 도입되면서, 모델은 실패 경험도 정제하여 저장하거나 폐기할 수 있어 장기적으로 안정적인 학습 곡선을 만든다.
Ⅳ. 주요 실험 및 결과
1. 데이터셋 구성
실험은 단일턴 및 멀티턴 환경을 모두 포함한다.
- Single-turn: AIME-24/25, GPQA-Diamond, MMLU-Pro, ToolBench
- Multi-turn: ALFWorld, BabyAI, ScienceWorld, PDDL 등
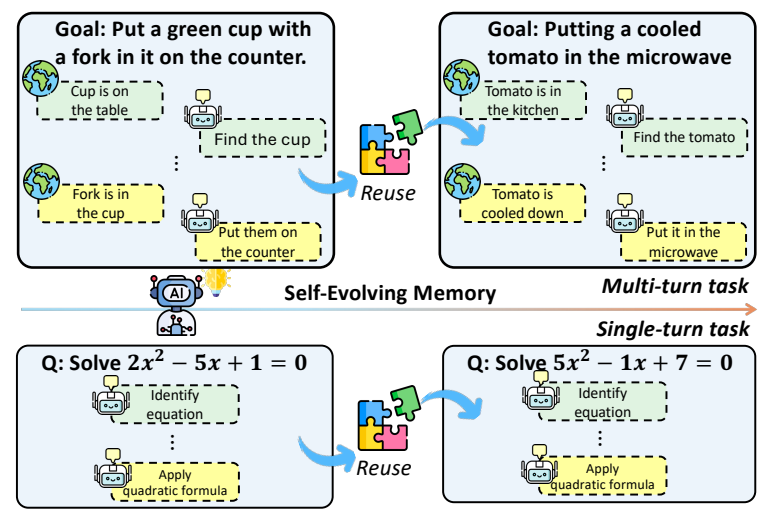
Figure 2 | Illustration of different task types and experience reusing. A stateful agent encounters both multi-turn tasks (e.g., embodied manipulation) and single-turn tasks (e.g., solving equations), and should learn reusable experiences from past experiences.
2. 주요 비교군
ReAct, Amem, SelfRAG, MemOS, Mem0, Dynamic Cheatsheet 등
다양한 메모리 기반·비기반 에이전트와 비교했다.
3. 실험 결과 요약
(1) Single-turn 성능 개선
Table 1 | Cross-dataset results of diverse memory architectures across models on the single-turn reasoning and question answering datasets. Categories are separated by horizontal rules; results (Exact Match↑ and API/Acc↑) compare zero-shot, agentic, adaptive, procedural, and proposed memory methods.
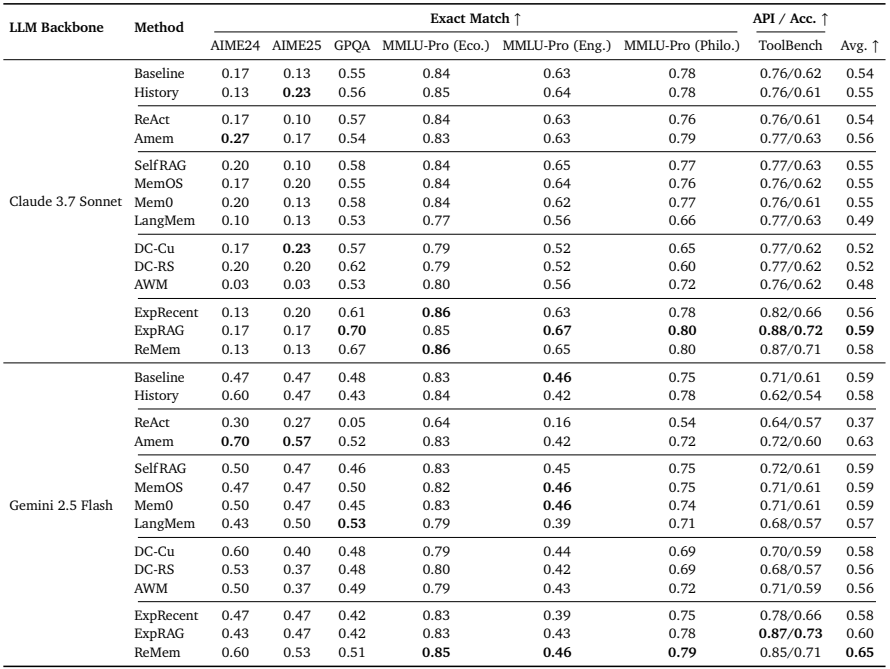
Gemini 2.5 Flash 기준:
- ReMem 평균 Exact Match: 0.65 (최고 수준)
- ExpRAG도 단순 구조임에도 매우 강력: 0.60
(2) Multi-turn 목표 달성률 대폭 향상
Table 2 | Cross-environment results across four embodied reasoning benchmarks (Alf World, BabyAI, PDDL, ScienceWorld). Each dataset reports success (S) and progress (P) rates. Bold indicates the best (including ties) per column. The last two columns show averaged S and P across datasets.
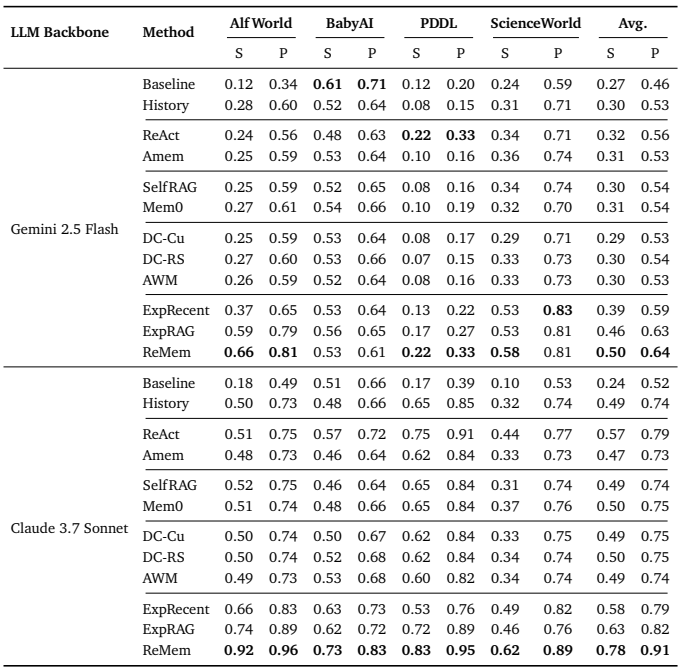
Claude 3.7 Sonnet 기준 BabyAI:
- Baseline Success 0.51 → ReMem 0.92
- ScienceWorld에서도 큰 폭 개선(0.24 → 0.62)
(3) 메모리 진화가 효율성을 향상
Figure 5 | Average steps to complete tasks across four benchmarks. We compare four methods: History, ExpRecent, ExpRAG, and ReMem. Lower is better. ReMem consistently requires fewer steps to complete tasks across all datasets, demonstrating more efficient task execution.
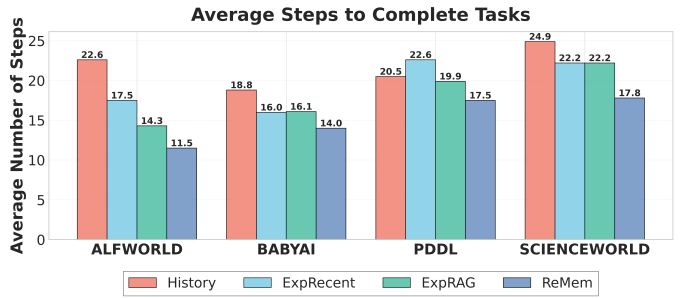
예: ALFWorld 평균 step 수
- Baseline 22.6 → ReMem 11.5 (약 49% 감소)
(4) 작업 난이도 변화에도 안정성 유지
Table 3 | Comparison of memory-based agents under different sequence difficulty directions. Each cell reports Success (S) and Progress (P). Easy→Hard and Hard→Easy indicate task order transitions, and averages (Avg) summarize per-direction performance.
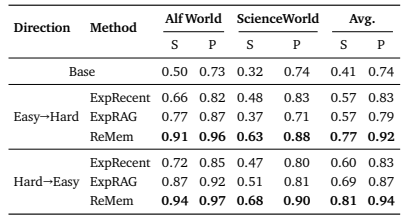
Hard→Easy 시퀀스에서도 누적 성능 유지
ReMem Success 평균 0.81, Progress 0.94
(5) 실패 경험 포함 시의 영향
Table 4 | Results with both successful and failed task experiences on Alf World and ScienceWorld. Each cell reports Success (S) and Progress (P). Horizontal rules separate method families. Bold numbers denote the best results per metric within each model.
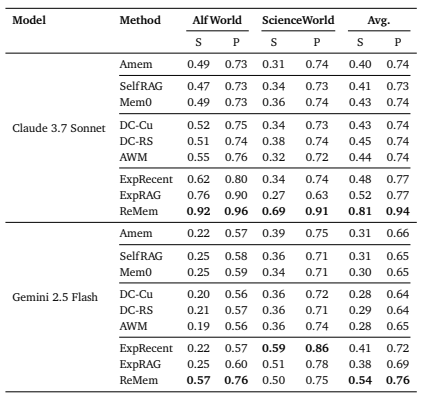
ReMem만이 실패 기록에도 성능 유지
다른 모델은 실패 경험 누적으로 성능 하락
Ⅴ. 논의 및 한계
1. 시사점
- 메모리를 단순한 저장소가 아니라, 능동적으로 재구성하는 지능적 요소로 바라봐야 함을 제시한다.
- 작은 모델일수록(예: Flash-Lite), test-time evolution의 효과가 크게 나타나 경량 모델 고도화 전략으로도 적합하다.
- ReMem은 실제 인간의 “경험 기반 문제 해결” 방식과 유사한 메타인지(meta-cognitive) 구조를 모사한다.
2. 한계
- 실험은 주로 텍스트 기반 또는 제한된 embodied 환경에 국한됨.
- 여러 모델(API)의 비용 문제로 open-weight 모델 실험은 상대적으로 부족.
- 메모리 크기 제한에 따른 최적의 pruning 전략은 추가 연구 필요.
3. 후속 연구 가능성
- 멀티모달 기억(Self-evolving multimodal memory)
- 장기 의사결정에서의 메모리 강화학습 결합
- Fail-aware memory evolution 체계화
Ⅵ. 결론
본 논문은 LLM 에이전트가 경험을 ‘기억–재사용–진화’하는 과정 자체를 평가하는 최초의 체계적 벤치마크를 제안하며, 향후 자기-개선(Self-improving) LLM의 연구 방향을 명확히 제시한다.
ReMem은 단순한 retrieval·reasoning 모델을 넘어, 기억을 스스로 재구성하는 능동적 에이전트 구조로서 향후 LLM 기반 자율 시스템 발전의 중요한 기반으로 평가된다.
한 줄 결론
“이 논문은 LLM이 스스로 배우는 ‘에이전트 시대’를 여는 메모리 평가 표준을 제시했다.”
