[논문리뷰] ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration (2025, Hongjin Su et al.)
AI 논문리뷰(AI Paper)
Ⅰ. 논문 개요
본 논문은 작은 언어모델이 다양한 툴(도구)과 대형 모델들을 효율적으로 조합하여, 단일 거대 모델을 능가하는 지능을 발휘할 수 있는지를 실증한 연구이다.
저자들은 ToolOrchestra라는 새로운 강화학습(RL) 기반 툴 오케스트레이션 기법을 제안하고, 이를 통해 오케스트레이터(Orchestrator)-8B라는 8B 규모의 모델을 훈련하였다.
주요 발견은 다음과 같다.
- 단일 모델이 모든 작업을 처리하는 방식은 비용·지연·정확도 트레이드오프에서 비효율적임
- 작은 오케스트레이터 모델이 다양한 도구와 다른 LLM을 호출하여 문제를 해결하도록 설계하면,
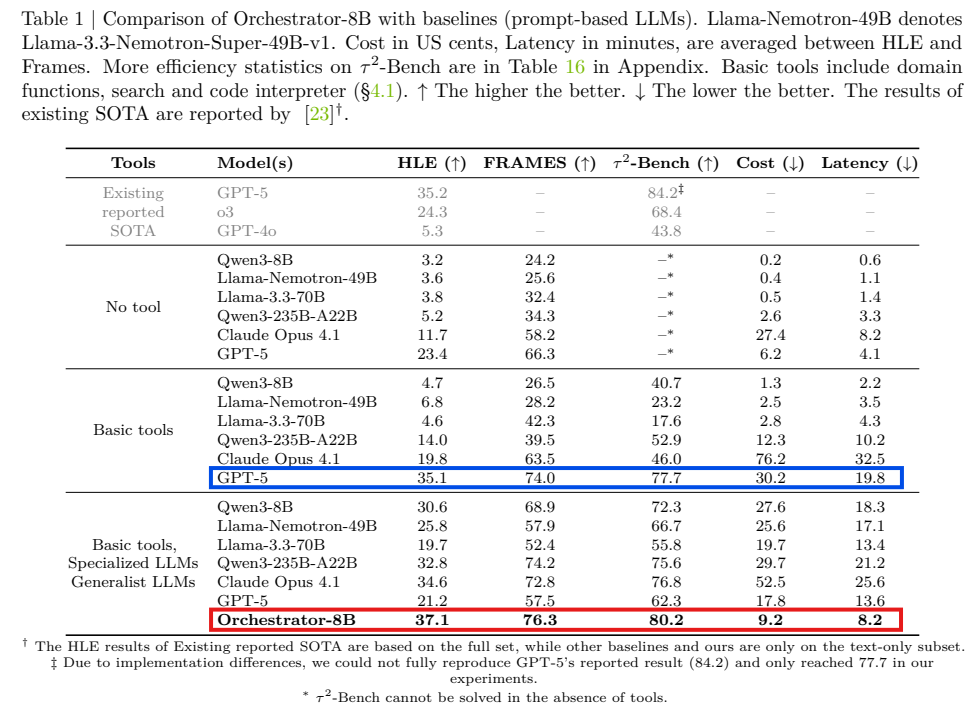
GPT-5보다 적은 비용으로 더 높은 성능을 달성할 수 있음 - 특히 HLE(Humanity’s Last Exam)에서 GPT-5(35.1%)보다 높은 37.1% 정확도를 기록함
기존 연구가 주로 “큰 모델 + 기본 툴” 조합에 머물렀다면, 본 논문은 “작은 모델 + 다양한 툴 + RL 최적화”라는 구조적 혁신을 제시한다.
Ⅱ. 연구 배경
1. 기존 연구 동향
- 다양한 연구들이 웹 검색, 코드 인터프리터, 함수 호출 등 LLM의 외부 도구 활용을 확대해왔다.
- 그러나 대부분은 단일 강력한 모델이 스스로 툴을 사용하는 구조였다.
- 툴을 사용할 때 “언제 어떤 툴을 쓰는 것이 비용 대비 성능이 최적인지”를 체계적으로 학습한 사례는 부족했다.
2. 기존 접근의 한계
논문은 다음 두 가지 주요 한계를 지적한다.
-
Self-enhancement bias / Other-enhancement bias
- GPT-5가 오케스트레이터로 설정되면 GPT-5-mini만 반복 호출
- Qwen 계열이 오케스트레이터이면 GPT-5만 무조건 호출
- 즉, 특정 모델만 호출하거나 의존하는 경향을 나타냄
Figure 3 | Tool-calling preferences exhibited by a prompted off-the-shelf or RL-trained model. GPT-5 tends to call GPT-5-mini most of the time, while Qwen3-8B relies heavily on GPT-5.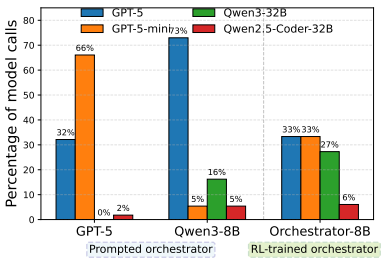
-
사용자 선호·비용·지연을 반영하지 못함
- 어떤 사용자는 비용 절감, 어떤 사용자는 로컬 툴 선호
- 기존 모델은 이런 선호 기반의 툴 선택·전략을 배울 수 있는 구조가 없음
3. 해결하고자 한 문제의식
- 작은 모델이 다양한 툴/LLM을 최적으로 조합하여 ‘복합 AI 시스템(compound AI)’ 형태로 고성능을 낼 수 있는가?
- 툴 선택을 RL로 학습시켜 비용·정확도·선호를 동시에 최적화할 수 있는가?
Ⅲ. 핵심 제안 및 구조
논문의 핵심 기여는 ToolOrchestra라는 RL 기반 툴 오케스트레이션 프레임워크와
이를 통해 훈련된 Orchestrator-8B 모델이다.
1. 오케스트레이터 구조 개요
사용자 질의 → 오케스트레이터가 “추론(reasoning)” → 필요한 툴을 선택하여 “액션(tool call)” → 툴의 결과 관찰(observation) → 반복 → 최종 답변 생성
Figure 2 | Overview of Orchestrator. Given a task, Orchestrator alternates between reasoning and tool calling in multiple turns to solve it. Orchestrator interacts with a diverse tool set, including basic tools (web search, functions such as get_flight_status, etc.), specialized LLMs (coding models, math models, etc.) and generalist LLMs (GPT-5, Claude Opus 4.1, etc.). In training under ToolOrchestra, Orchestrator is jointly optimized by outcome, efficiency and preference rewards via reinforcement learning.
2. 통합 툴 호출(Unified Tool Calling)
모든 툴은 JSON 기반 공통 인터페이스로 관리한다.
- 기본 툴: 웹 검색(Tavily), 로컬 검색(Faiss), 코드 인터프리터
- 전문 모델: Qwen-Math, Qwen-Coder, GPT-5-mini 등
- 범용 모델: GPT-5, Claude Opus, Qwen3-32B 등
오케스트레이터는 단일 포맷으로 모든 모델·함수·API를 호출한다.
3. 강화학습(RL) 기반 훈련
(1) 보상 설계 (Reward):
논문 핵심은 “정답률만 높이는 것이 아니라 효율성까지 최적화하는 보상 구조”이다.
- Outcome reward: 문제를 해결했는가 (정·오답)
- Efficiency reward: 비용(cost), 지연(latency)을 최소화
- Preference reward: 사용자 툴 선호를 따랐는가
(예: “API 쓰지 말고 로컬 검색 위주로 써라”)
보상 공식은 다음과 같다.
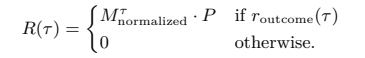
여기서 P는 사용자 선호 벡터이며, ToolOrchestra의 철학적 핵심이다.
4. 학습 데이터셋 ToolScale
논문은 매우 중요한 기여로 ToolScale이라는 대규모 synthetic agentic 데이터셋을 제작했다.
Figure 4 | Overview of ToolScale data synthesis pipeline. Starting from a domain, LLM will (1) firstly generate domain-specific database and tool APIs to simulate the environment and (2) then generate diverse user tasks together with their corresponding golden actions.
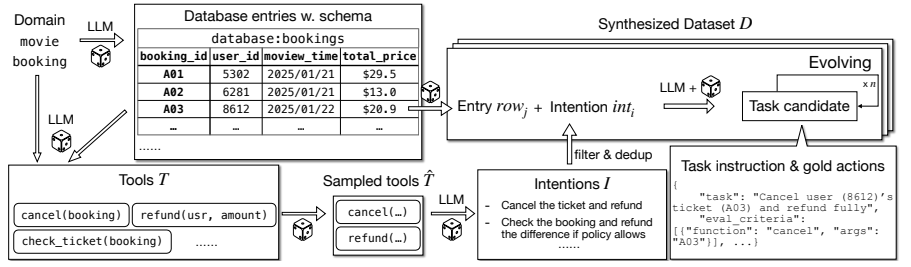
- 도메인별 DB·API 생성
- 작업(Task) 생성 + 정답 함수 호출(ground truth) 생성
- 복잡도 증가(Evolution)
- 품질 검증 후 학습 데이터로 사용
총 10개 도메인, 수백~수천 개의 데이터 구성
Table 5 | Statistics of ToolScale: the number of tools, database entries, and tasks per domain.

Ⅳ. 주요 실험 및 결과
논문은 3개 대표적 고난도 벤치마크에서 실험한다.
1. Humanity’s Last Exam(HLE)
- GPT-5: 35.1%
- Claude Opus: 34.6%
- Qwen3-235B: 32.8%
- Orchestrator-8B: 37.1% (SOTA)
→ 8B 모델이 GPT-5를 능가
2. FRAMES (Retrieval + Reasoning)
FRAMES 란, 여러 문서를 찾아보고, 사실을 조합해서 답하는 능력 평가를 말한다.
쉽게 말하면 "구글로 여러 페이지를 찾아보고, 모두 읽은 뒤 종합해서 한 문장으로 답하기" 이다예시
질문 : “2010년에 상을 받은 감독이 2018년에 만든 영화의 주연 배우는 누구인가?”
처리과정 :
→ 위키 문서 3~5개를 직접 찾아야 하고
→ 감독 정보 + 수상 기록 + 영화 정보 + 배우 정보
→ 이렇게 여러 사실을 엮어해야 정답이 나온다.
- GPT-5: 74.0%
- Claude Opus: 72.8%
- Orchestrator-8B: 76.3%
→ Orchestrator-8B 모델이 가장 높은 평가를 받음
3. τ²-Bench (Function-calling benchmark)
τ²-Bench 란, 사용자 질의에 대해 문제를 해결하기 위해 필요한 기능을 호출하거나 적절한 도구를 얼마나 잘 쓰는지 평가하는 지표이다.
쉽게 말하면 "나사를 조이기위해 드라이버나 전동드릴을 찾는 것처럼 작업에 필요한 적절한 도구를 골라 쓰는 능력" 을 평가하는 것이다.예시
질문 : "내 데이터 초과됐는지 체크해주고, 초과되었으면 데이터팩 구매해줘."
처리과정 :
→ check_data_usage(user)
→ 초과된 경우 purchase_data_pack(user, plan)
→ 결제 성공 확인 check_payment(status)
-
GPT-5(Tool 사용): 77.7%
-
Orchestrator-8B: 80.2%
→ Orchestrator-8B 모델이 GPT-5(Tool 사용) 모델 보다 높은 수치를 기록
4. 비용(Cost)·지연(Latency) 효율성
HLE 기준:
- GPT-5(tool 사용): 비용 30.2¢, 지연 19.8 min
- Orchestrator-8B: 비용 9.2¢, 지연 8.2 min
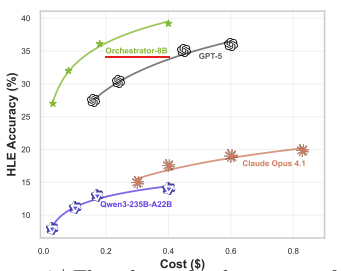
Figure 6 | The relationship between perfor- mance and cost. Compared to strong mono- lithic LLM systems, Orchestrator (ours) achieves the best cost-effectiveness
→ 성능은 높고 비용은 1/3
5. 도구 호출 패턴 분석
Figure 5 | The proportion of tool calls made by LLMs to solve a task (averaged across HLE, Frames and 𝜏2-bench). Qwen-32B refers to Qwen3-32B and Coder-32B refers to Qwen2.5-Coder-32B-Instruct. Compared to other strong foundation models, Orchestrator-8B makes more balanced tool calls, and does not exhibit strong biases toward a particular tool or model.
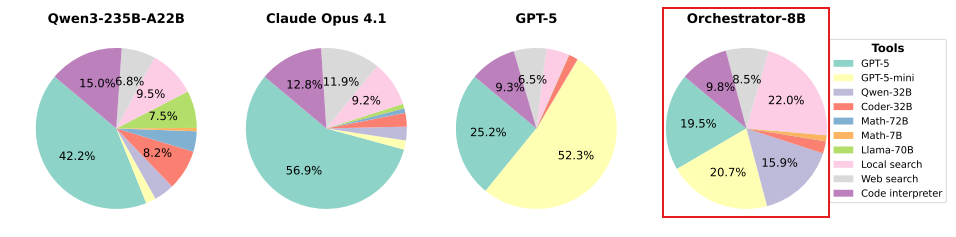
- 다른 모델들은 특정 모델만 과도 호출(GPT-5 또는 GPT-5-mini)
- Orchestrator-8B는 다양한 툴을 균형 있게 호출
- 비용 대비 최적 조합 선택 능력이 탁월함
Ⅴ. 논의 및 한계
1. 시사점
- LLM 성능의 본질은 단일 모델의 파라미터 크기가 아니라 ‘외부 지능과의 조합 전략’임을 의미
- “작은 모델이 강한 모델을 잘 사용하도록 만드는 것이 미래 AI 아키텍처의 핵심”
- Compound AI 시스템의 효율·성능 한계를 동시에 돌파한 사례
2. 한계점
- RL 학습 비용이 여전히 크다 (H100 GPU 16개로 대규모 반복 학습)
- 툴 설명 품질이 정확하지 않을 경우 성능 저하 가능
- 실제 산업 환경의 API 오류·지연을 완전히 반영하지 못함
- Complex tool chains에서 debugging 비용 발생 가능
3. 후속 연구 방향
- 툴 간 협력(cooperation) 최적화
- 에이전트 간 멀티 오케스트레이션 구조
- 실제 웹 환경에서의 robust tool-use 강화
- 모델 설명 자체를 자동 생성하여 투명성 강화
Ⅵ. 결론
본 논문은 다음과 같은 명확한 기여를 남긴다.
- 작은 모델(8B)이 다양한 툴·대형 모델을 orchestration하여 GPT-5를 능가할 수 있음 실증
- 정답률·비용·지연·사용자 선호를 모두 고려하는 RL 기반 보상 구조 제안
- Compound AI 시스템으로의 패러다임 전환에 결정적 증거 제시
- 'Orchestrator-8B' 모델이 3가지 평가지표와 비용 효율성에서 'Claude Opus 4.1'과 'GPT-5' 를 모두 앞섰다.
한 줄 결론
“미래의 고성능 AI는 거대한 하나의 모델이 아니라, 작은 모델이 여러 도구를 지능적으로 조율하는 ‘오케스트라형 AI’가 되지 않을까?”
