[논문리뷰] RAG VS FINE-TUNING: PIPELINES, TRADEOFFS, AND A CASE STUDY ON AGRICULTURE
AI 논문리뷰(AI Paper)
최근 LLM의 환각현상을 줄이기 위한 도구? 기법?으로 RAG와 파인튜닝을 시도한다.
어떠한 것이 더 효과적인지 궁금하여 해당 논문에 대한 리뷰를 작성하게 되었다.
본 논문은 Microsoft Research 연구진이 주도적으로 작성하였으며, 농업 AI 분야 책임자인 Ranveer Chandra가 공동 저자로 참여함. 연구 주제는 RAG(Retrieval-Augmented Generation)와 Fine-Tuning을 비교하여, 두 방법이 LLM의 환각(hallucination) 감소와 답변 품질 향상에 각각 어떤 효과와 장단점을 가지는지 분석한 것 입니다. 자세한 내용은 아래 원문을 참고.
Original Paper : https://arxiv.org/abs/2401.08406
RAG vs Fine-Tuning: 파이프라인, 트레이드오프, 그리고 사례 연구
대규모 언어 모델(LLMs)을 특정 도메인(농업)에 적용할 때 사용되는 두 가지 주요 방법론인 검색 증강 생성(RAG)과 미세 조정(Fine-Tuning)의 파이프라인, 장단점, 그리고 사례 연구에 대해 설명한 논문.
연구 목표 및 배경
연구 목표는 개발자들이 독점 데이터나 도메인별 데이터를 LLM 애플리케이션에 통합할 때 사용하는 RAG와 Fine-tuning의 장단점을 비교하고, 농업 데이터셋에 적용한 사례를 통해 성능을 검증하는 것임.
- RAG = 외부 데이터 검색해서 프롬프트에 추가 → 모델 응답 강화
- Fine-tuning = 모델 자체에 지식 내재화
- 농업 분야는 AI 도입 더딤. 지역별 맞춤 답변 제공하는 AI 코파일럿(MS AI서비스 아님) 가능성 탐구함
- GPT-4 같은 범용 모델은 특정 위치 기반 질문(예: 미국 세 주 식재 시기)에도 지역 특성 반영 못하고 일반적 답변만 제공하는 한계 있음
- 연구는 미국(USDA), 브라질(Embrapa), 인도(KVK) 등 다국적 농업 데이터셋 활용 → 결과가 특정 지역에 국한되지 않고 확장 가능성 높음
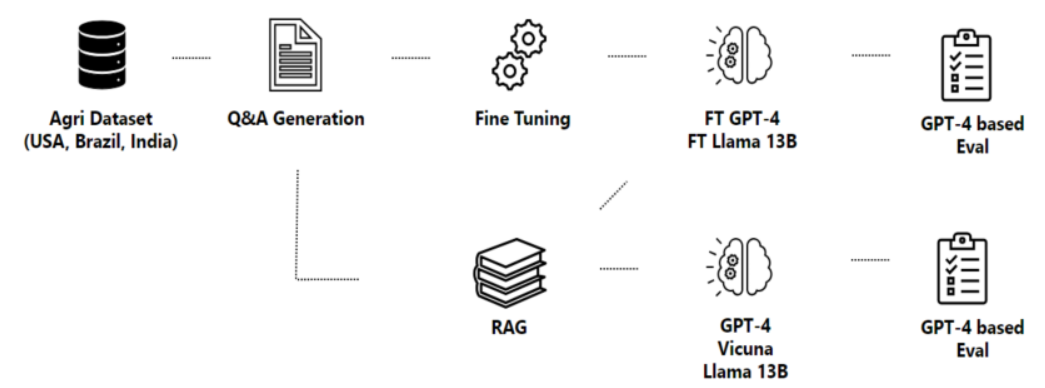
방법론 및 파이프라인
| 단계 | 설명 |
|---|---|
| 데이터 수집 | 정부 보고서, 학술 자료 등 권위 있는 소스에서 지역별 농업 데이터 확보 |
| PDF 정보 추출 | GROBID 사용해 비표준 PDF를 구조화된 JSON으로 변환 (섹션, 표, 그림, 상호참조 포함) |
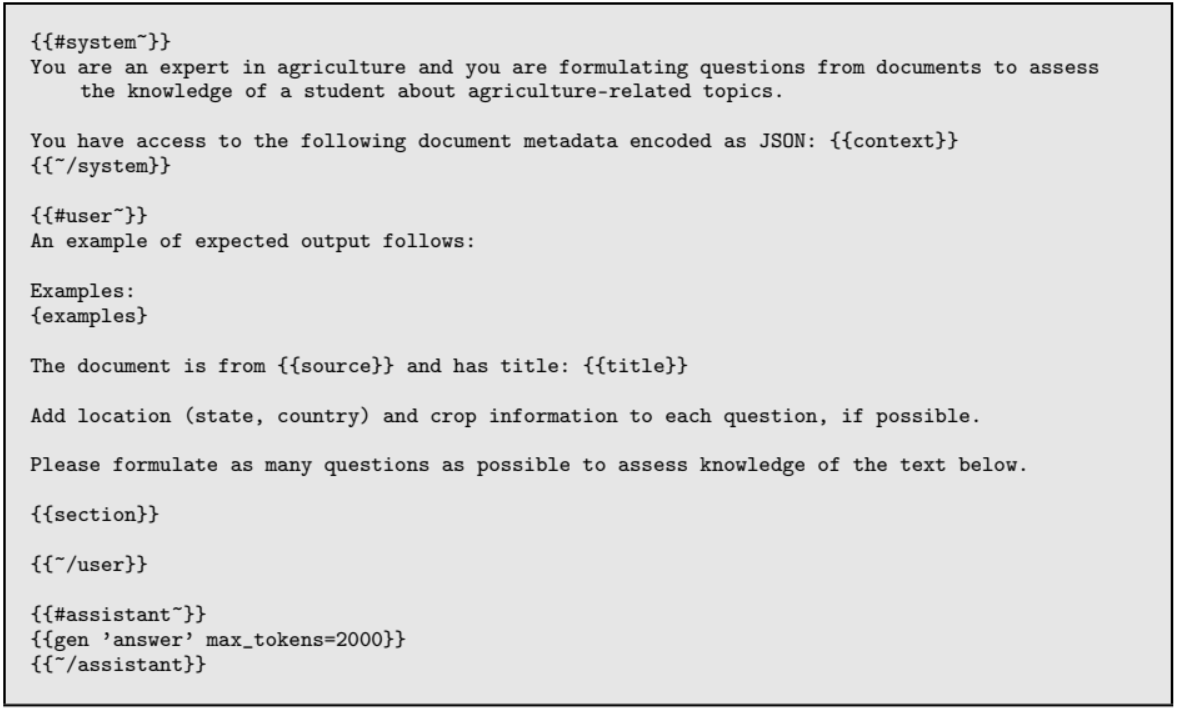
| Q&A 생성 | Guidance 프레임워크로 문맥 기반 고품질 질문 생성. 위치/작물/질병 같은 컨텍스트 반영 |
| 답변 생성 (RAG) | BM25, Dense Retrieval, FAISS 기반 검색 → GPT-4 프롬프트에 문맥으로 삽입 |
| 미세 조정 (Fine-Tuning) | Q&A 쌍 활용해 Llama2, GPT-4 등 모델 학습. LoRA로 효율적 튜닝. A100/H100 GPU 사용 → 비용/리소스 현실 문제 부각됨 |
Figure 2 (PDF 추출 예시)

Listing 4 (Q&A 생성 프롬프트 예시)
주요 결과 및 정량적 이점
- Fine-tuning → 정확도 +6%p 향상
- RAG 추가 → 추가 +5%p 향상
- GPT-4 + Fine-tuning + RAG 조합 → 최고 성능 (정확도 86%)
- Fine-tuned 모델, 지리적 경계 넘어 새로운 지식 활용 → 답변 유사도 47% → 72% 증가
- RAG 통합 → 응답 정확도뿐 아니라 간결성(succinctness) 개선
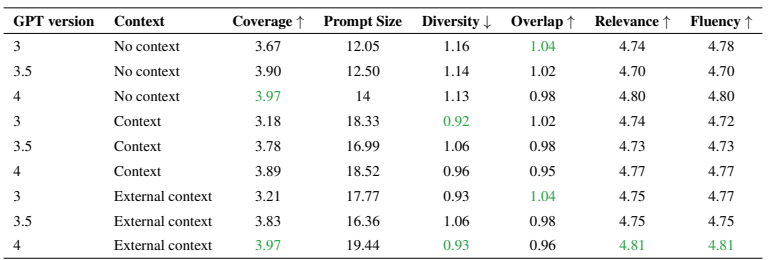
- 단순 정확도 외에도 질문 품질(Relevance, Coverage, Fluency 등), 답변 품질(Coherence, Groundedness, Correctness 등)로 세분화 평가 진행 → 현업 관점에서 실제 유효성 확인 가능
Table 1 (GPT-4 vs Bing vs 전문가 답변 비교)
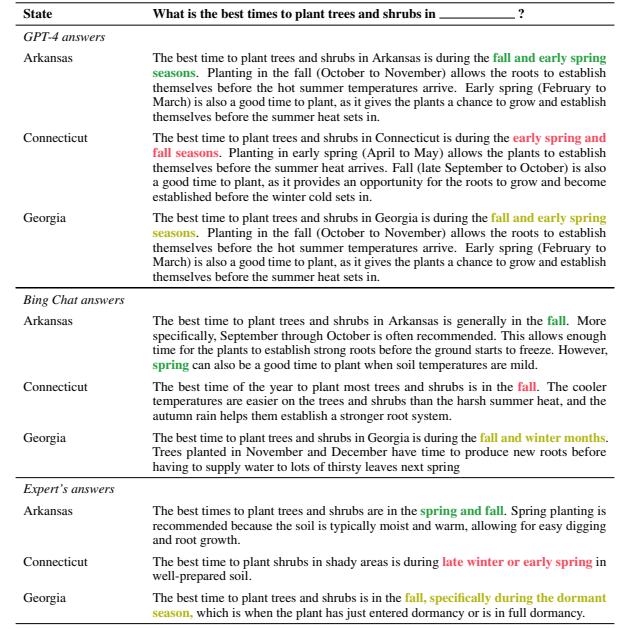
Table 6~8 (답변 품질 평가 사례)
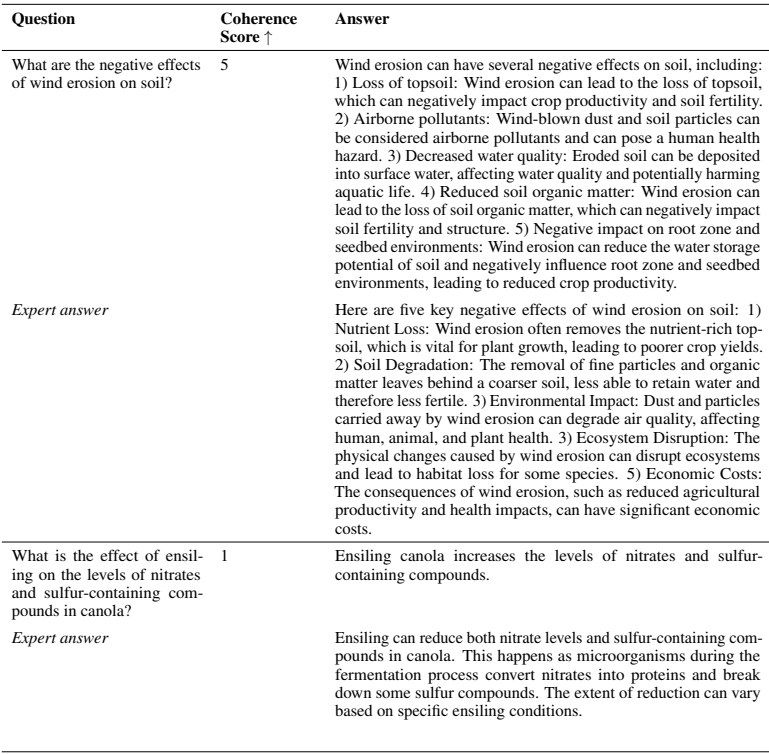
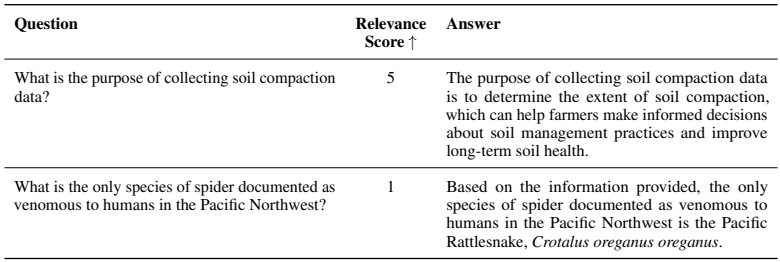

Table 13 (모델별 성능 비교표)
결론
-
RAG와 Fine-tuning 모두 성능 향상에 효과적임
-
두 방법은 대체 관계가 아니라 보완 관계임
- Fine-tuning = 도메인 지식 내재화
- RAG = 최신/외부 지식 반영
-
결합했을 때 가장 높은 성능 발휘
-
산업 적용 시 어떤 방법 쓸지는 애플리케이션 요구사항, 데이터 규모, 리소스 상황에 따라 달라짐
| 특징 | RAG | Fine-tuning |
|---|---|---|
| 초기 비용 | 낮음 (임베딩 생성) | 높음 (데이터 준비+학습) |
| 입력 토큰 | 프롬프트 길어짐 | 짧음 |
| 출력 | 장황함, 제어 어려움 | 간결, 정밀 |
| 정확도 | 효과적임 | 효과적임 |
| 새로운 지식 | 컨텍스트 내 포함 시 활용 | 모델에 학습되어 활용 |
Table 23 (RAG vs Fine-tuning 비교표)

한계점 및 향후 연구
-
비용 문제
- GPT-4 미세 조정 비용 큼 → 산업 적용 시 ROI 고려 필요
- GPU 클러스터(A100/H100) 필요 → 리소스 현실적 장벽 존재
-
데이터 및 지식 추출 복잡성
- 미세 조정으로 모델이 습득하는 지식의 유형 더 연구 필요
- 구조화된 추출 개선 필요 (표, 그림, 문서 구조 활용 중요)
-
멀티모달 확장
- 현재는 텍스트 위주 → 표, 지도, 이미지 포함한 멀티모달 학습으로 확장 가능
- 농업 코파일럿 품질 높이려면 비텍스트 데이터 결합이 필수
