
현재까지 프로세스 실행의 저수준 메커니즘(예: 문맥 교환)에 대한 내용은 명확할 것으로 예상된다. 그렇지 않은 경우, 몇 장 전으로 돌아가 해당 내용을 다시 읽어보는 것이 좋다. 그러나 우리는 아직 운영 체제 스케줄러가 적용하는 고수준 정책을 이해하지 못했다. 이제 우리는 이를 이해하고, 다양한 현명하고 열심히 일하는 사람들이 지난 몇 년 동안 개발한 일련의 스케줄링 정책(가끔은 디시플린이라고도 함)을 제시할 것이다.
사실 스케줄링의 기원은 컴퓨터 시스템 이전으로 거슬러 올라간다. 초기 방법론은 운영 관리 분야에서 가져와 컴퓨터에 적용되었다. 이는 어렵지 않게 이해할 수 있는 사실이다. 생산 라인과 다른 인간 활동들도 스케줄링을 필요로 하며, 효율성을 강조하는 많은 공통점이 있다.
그리고 이제 우리가 직면한 문제는 다음과 같다: "핵심은, 스케줄링 정책을 개발하는 방법이다. 어떻게 기본적인 프레임워크를 구성할 수 있을까? 어떤 가정이 필요할까? 어떤 지표가 중요할까? 초기 컴퓨터 시스템에서 사용된 기본적인 방법론은 무엇일까?"
1. Workload Assumptions
정책의 가능한 범위에 대해 이야기하기 전에, 먼저 시스템에서 실행되는 프로세스들, 종종 워크로드(workload)라고 함께하는 일련의 단순화된 가정들을 세우겠다. 워크로드를 결정하는 것은 정책을 만드는 중요한 부분이며, 워크로드에 대해 알 수록 더 세부적인 정책을 만들 수 있다.
여기서 만든 워크로드 가정은 대부분 현실적이지 않지만, 일단 괜찮다. 이후에 조금씩 조정해 나가며, 결국은 완전한 스케줄링 디시플린을 개발할 것이다.
다음과 같은 가정들을 프로세스 또는 작업(job)이라고 불리는 시스템에서 실행되는 프로그램에 대해 세우겠다.
각 작업은 같은 시간 동안 실행된다.
모든 작업은 동시에 도착한다.
한 번 시작하면 각 작업은 완료될 때까지 실행된다.
모든 작업은 CPU만 사용하며, I/O 작업을 수행하지 않는다.
각 작업의 실행 시간이 알려져 있다.
이러한 가정 중 많은 것이 현실적이지 않다고 했지만, 이 장에서는 동일한 실행 시간을 가진다는 가정이 다소 문제가 될 수 있다. 이는 스케줄러가 신비한 지식을 가지고 있는 것처럼 보일 수 있기 때문이다. 이것은 아마 좋을 것이지만 (아마도), 그러한 일은 곧 일어날 가능성이 없다.
2. Scheduling Metrics
워크로드 가정을 세우는 것 외에도, 스케줄링 정책을 비교할 수 있도록 하나 더 필요한 것이 있다. 바로 스케줄링 지표(scheduling metric)이다. 지표란 그냥 무언가를 측정하는 데 사용하는 것으로, 스케줄링에서 의미 있는 여러 지표가 있다. 그러나 우선은 우리의 편의를 위해 하나의 지표, 즉 소요 시간(turnaround time)만 사용하도록 하자. 작업의 소요 시간은 해당 작업이 완료된 시간에서 해당 작업이 시스템에 도착한 시간을 뺀 것으로 정의된다. 더 정확히는 다음과 같다.
소요 시간 Tturnaround은 다음과 같이 계산된다:
Tturnaround = Tcompletion − Tarrival (7.1)
모든 작업이 동시에 도착한다는 가정을 했으므로, 지금은 Tarrival = 0이며, 따라서 Tturnaround = Tcompletion이다. 이 사실은 위에서 언급한 가정들을 완화할 때 바뀔 것이다.
속도 지표는 이번 장에서 주로 다룰 성능 지표이다. 다른 지표로는 Jain의 공정성 지수와 같은 지표가 있지만, 이는 공정성을 측정하는 것이 주된 목적이다. 성능과 공정성은 종종 상충 관계에 있다. 예를 들어, 스케줄러는 성능을 최적화할 수 있지만, 몇몇 작업을 방지하여 공정성을 감소시킬 수 있다. 이런 딜레마는 삶이 항상 완벽하지 않다는 것을 보여준다.
3. First In, First Out (FIFO)
가장 기본적인 알고리즘인 First In, First Out (FIFO) 스케줄링 또는 First Come, First Served (FCFS) 스케줄링은 구현할 수 있는 가장 기본적인 알고리즘이다. FIFO는 몇 가지 긍정적인 특성을 가지고 있는데, 그것은 분명히 간단하며 구현하기 쉽다는 것이다. 또한, 우리의 가정에 따르면 꽤 잘 작동한다.
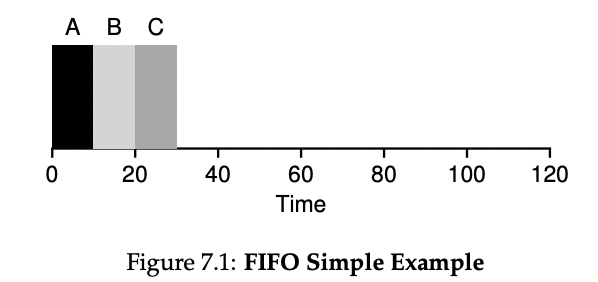
그러나 가정 중 하나를 완화해 보자. 특히, 가정 1을 완화하고, 각 작업이 동일한 시간 동안 실행되지 않는다는 가정을 더 이상 하지 않을 것이다. 이제 FIFO가 어떻게 작동하는지, 어떤 워크로드가 FIFO의 성능을 나쁘게 할 수 있는지 생각해보자.
아마도 당신은 이제 이것을 알아챘겠지만, 그래도 한 번 예를 들어보겠다. 특히, 세 가지 작업 (A, B, C)이 있고, 이번에는 A가 100초 동안 실행되고 B와 C가 각각 10초 동안 실행된다고 가정하자.
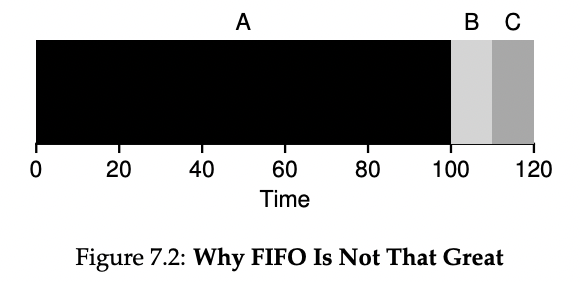
그림 7.2에서 볼 수 있듯이, 작업 A는 B 또는 C가 실행되기 전에 100초 동안 먼저 실행된다. 따라서 시스템의 평균 소요 시간은 높아진다: 고통스러운 110초 (100+110+120/3 = 110).
이러한 문제는 일반적으로 리소스 소비자의 무거운 가축(consumer) 뒤에 상대적으로 짧은 잠재적인 소비자들의 수가 크다는 것을 의미하는 콘보이 효과(convoy effect)로 알려져 있다. 이 스케줄링 시나리오는 식료품 가게에서 단일 줄을 생각나게 할 수 있으며, 앞에 선 사람이 물건을 세 바구니나 구매를 위한 수표를 꺼내는 것을 보면 얼마나 오래 기다려야 하는지 느껴보면 된다.
그래서 우리는 어떻게 해야 할까? 서로 다른 시간 동안 작동하는 작업을 다루기 위해 더 나은 알고리즘을 개발하는 방법은 무엇일까?
4. Shortest Job First (SJF)
컴퓨터 시스템에서 작업 스케줄링을 위해, 운영 연구에서 가져온 간단한 아이디어인 SJF(Shortest Job First) 스케줄링 방식을 사용할 수 있다. 이 방식은 가장 짧은 작업부터 우선적으로 처리하는 방식으로, 직관적이다.

만약 모든 작업이 동시에 도착한다는 가정하에는 SJF가 최적의 스케줄링 방식이 될 수 있다. 그러나 실제 상황에서는 작업 도착 시간이 다르다는 가정을 추가해야 한다. 이 경우 SJF도 문제가 생길 수 있는데, 예를 들어 A 작업이 먼저 도착하고 100초 동안 실행되어야 하는데, B와 C 작업은 10초 동안 실행되어야 하는데 A 작업이 끝날 때까지 기다려야 하는 등의 문제가 발생할 수 있다.
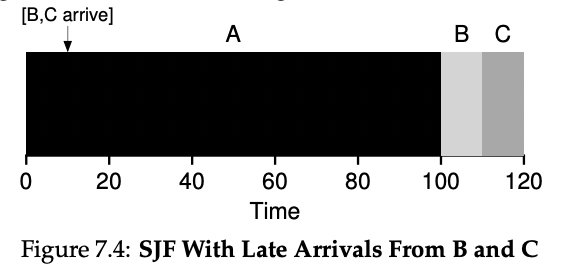
이런 경우 스케줄러는 어떻게 대처할 수 있을까?
5. Shortest Time-to-Completion First (STCF)
문제를 해결하기 위해서는 가정 3(작업이 완료될 때까지 실행됨)을 완화해야 하며, 이를 위해 스케줄러 내부에서 몇 가지 기능이 필요하다. 이전에 타이머 인터럽트와 컨텍스트 스위칭에 대해 논의한 것처럼, 스케줄러는 B와 C가 도착했을 때 A 작업을 선점하고 다른 작업을 실행하고, 나중에 A 작업을 이어서 실행할 수 있다.
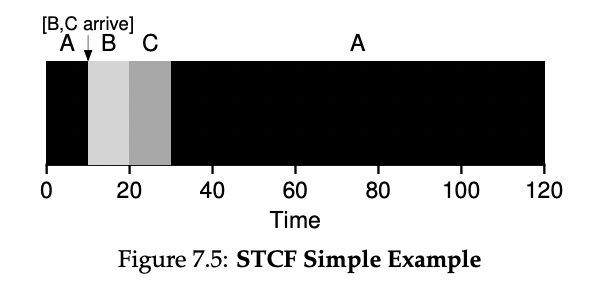
우리가 정의한 SJF는 비선점 스케줄러이므로 위에서 설명한 문제점이 발생한다. 다행히도, 이를 해결하기 위한 선점형 스케줄러가 있는데, 그것은 바로 "Shortest Time-to-Completion First (STCF)" 또는 "Preemptive Shortest Job First (PSJF)" 스케줄러이다. 이 스케줄러는 새로운 작업이 들어오면(새로운 작업을 포함하여) 남은 실행 시간이 가장 짧은 작업을 스케줄링한다. 따라서 위의 예에서 STCF는 A 작업을 선점하고 B와 C 작업을 완료한 후에 남은 A 작업을 실행한다. 그림 7.5는 예시를 보여준다. 이 결과 평균 반환 시간이 크게 개선되었으며, STCF는 위의 새로운 가정에 따라 증명 가능한 최적의 스케줄러이다. 즉, 모든 작업이 동시에 도착할 때 SJF가 최적이라면, STCF의 최적성 뒤에 있는 직관을 이해할 수 있을 것이다.
6. A New Metric: Response Time
이전에 다룬 STCF는 CPU를 사용하는 작업의 길이를 알고, 반응 시간(metric)이 없을 때 효과적이었다. 그러나 이후 시분할 시스템에서 사용자들은 대화형 성능을 요구하기 시작하면서 반응 시간이라는 새로운 metric이 등장하게 되었다.
반응 시간은 작업이 시스템에 도착한 시점부터 스케줄링이 시작된 첫 번째 시점까지의 시간을 말한다. 따라서 STCF와 같은 정책은 반응 시간에서는 그다지 효과적이지 않다.
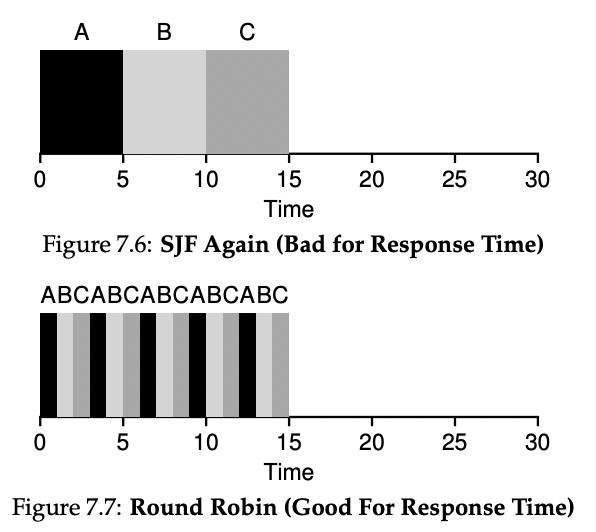
예를 들어, Figure 7.5와 같은 스케줄링을 한다면, 작업 A의 반응 시간은 0초, 작업 B의 반응 시간은 0초, 작업 C의 반응 시간은 10초가 된다.
STCF와 같은 정책은 짧은 작업을 먼저 처리하는 방식으로 스케줄링을 하기 때문에 대화형 성능에서는 좋지 않다. 예를 들어, 사용자가 터미널에서 명령어를 입력하고 있는데, 다른 작업이 그 앞에 끼어들면서 10초간 기다려야 할 수도 있다. 이러한 이유로 반응 시간에 민감한 스케줄러가 필요해졌다.
7. Round Robin
이전까지 우리는 turnaround time(작업 종료까지 걸리는 시간)을 최적화하는 스케줄러(SJF, STCF)와 response time(작업이 도착한 시점부터 최초 실행까지 걸리는 시간)을 최적화하는 스케줄러(RR)를 소개했다. 그러나 이전에 소개한 가정들을 완화해야 한다. 첫 번째로 가정된 것은 모든 작업이 CPU만 사용한다는 가정이었는데, 이번에는 작업이 I/O도 수행할 수 있다는 가정을 추가할 것이다. 이 가정을 완화하는 것은 다음 섹션에서 이야기할 예정이다. 두 번째로 가정된 것은 각 작업의 수행 시간이 미리 알려진다는 것이었다. 이것도 완화해야 하는데, 이것은 나중에 이야기할 예정이다.
RR 스케줄링은 매우 짧은 시간 단위로 작업을 분할하여 CPU를 공정하게 할당하는 방식으로 response time을 최적화하는데 유용하다. 그러나 이 경우 turnaround time은 SJF나 STCF보다 더 나쁘다. 이는 각 작업을 작은 양만큼 실행하고 다음 작업으로 넘어가기 때문에 긴 작업이 길어지기 때문이다. 따라서, 우리는 시스템 설계자로서 언제 컨텍스트 스위칭 비용을 상환하는 것이 적절한지, 너무 짧은 시간 단위로 작업을 분할하지 않도록 유의해야 한다.
또한, 작업의 수행 시간이 알려지지 않았다면, RR 스케줄링은 매우 어렵다. 이 경우 작업이 언제 종료될지 알 수 없으므로 시간 분할에 사용할 시간을 결정할 수 없다. 따라서 이러한 문제를 해결하기 위해 다른 스케줄링 알고리즘이 필요하다.
8. Incorporating I/O
이번 장에서는 스케줄러가 프로세스들의 CPU 시간 배정 방법을 결정하는 방법에 대해 다룬다. 스케줄러는 프로세스의 CPU 사용 시간을 어떻게 분배할 것인지, 어떤 프로세스를 먼저 실행시킬 것인지를 결정해야 한다. 이번 장에서는 프로세스의 CPU 시간을 각각의 작은 단위로 나눠서 관리하는 Round-Robin 스케줄링과, 각 프로세스의 CPU 요구 시간을 최소화시키는 Shortest Job First 스케줄링, 두 가지 스케줄링 방법을 다룬다.
또한, 프로세스들이 모두 I/O를 수행한다는 가정을 제외하는 방법에 대해 다루고, 프로세스들의 I/O 작업을 어떻게 스케줄링할지에 대해서도 설명한다. I/O 작업이 실행되는 동안 CPU를 사용할 수 없으므로, 스케줄러는 다른 프로세스를 실행시켜 CPU 자원을 효율적으로 사용하도록 결정해야 한다. 또한 I/O 작업이 완료되었을 때는 해당 프로세스를 ready 상태로 전환시켜 다시 CPU 자원을 사용하도록 스케줄링해야 한다.
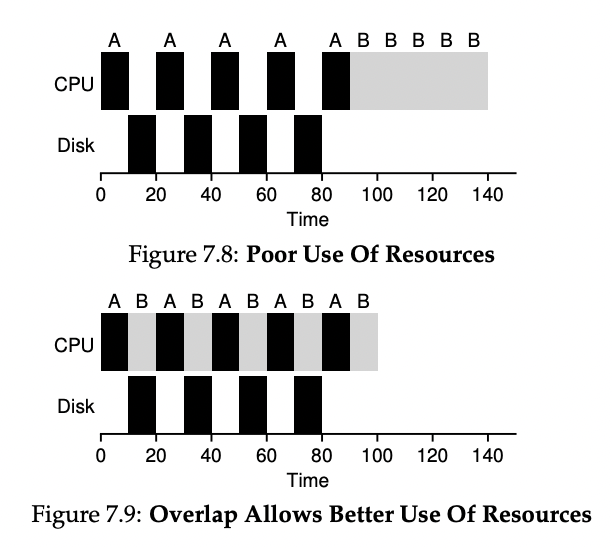
이러한 작업을 수행하기 위해서는 각 프로세스의 CPU 시간을 작은 단위로 나누어 처리하고, I/O 작업을 수행하는 동안 다른 CPU-intensive한 프로세스를 실행시켜 CPU 자원을 효율적으로 사용해야 한다. 이를 통해 스케줄러는 프로세스의 CPU 요구 시간을 최소화하면서 CPU 자원을 효율적으로 사용할 수 있도록 결정한다.
