
이번 장에서는 가장 잘 알려진 스케줄링 방법인 Multi-level Feedback Queue (MLFQ)를 개발하는 문제를 다룬다. Multi-level Feedback Queue (MLFQ) 스케줄러는 Corbato 등이 1962년에 개발한 Compatible Time-Sharing System (CTSS)에서 처음으로 소개되었으며, 이 작업은 Multics에서의 후속 작업과 함께 ACM에서 Corbato에게 Turing Award라는 최고 명예상을 수여하게 되었다. 이 스케줄러는 그 후로도 계속 개선되어 일부 모던 시스템에서 만나볼 수 있다.
MLFQ가 해결하려는 기본적인 문제는 두 가지이다. 첫째, 짧은 작업을 먼저 실행하여 회전율(turnaround time)을 최적화하려고 한다. 그러나 운영 체제는 일반적으로 작업이 얼마나 오래 실행될지 정확히 모르므로 SJF (또는 STCF)와 같은 알고리즘이 필요한 정확한 정보를 가지고 있지 않다. 둘째, MLFQ는 시스템이 반응적인 사용자(즉, 화면을 보면서 프로세스가 끝나기를 기다리는 사용자)에게 느껴지도록 하여 응답 시간을 최소화하고자 한다. 그러나 Round Robin과 같은 알고리즘은 응답 시간을 줄이지만 회전율 측면에서는 최악이다. 따라서 문제는 일반적으로 프로세스에 대해 아무 것도 모른다는 가정 하에 어떻게 스케줄러를 구성하여 이러한 목표를 달성할 수 있는지이다. 시스템이 실행됨에 따라 스케줄러가 특성을 학습할 수 있는 방법은 무엇인가?
1. MLFQ: Basic Rules
MLFQ는 다중 우선순위 큐를 사용하는 스케줄러이다. 이 큐들은 각기 다른 우선순위 레벨을 가지고 있으며, 실행 가능한 작업은 한 큐에 속해 있다. 더 높은 우선순위를 가진 작업이 먼저 실행되도록 하기 때문에 우선순위가 높은 작업이 먼저 실행된다. 만약 우선순위가 같은 작업이 여러 개라면, 라운드 로빈 스케줄링을 사용하여 순서대로 실행된다.
• Rule 1 : Priority(A) > Priority(B)인 경우 A가 실행된다.
• Rule 2 : Priority(A) = Priority(B)인 경우 A와 B가 RR(라운드 로빈) 스케줄링으로 실행된다.
MLFQ의 스케줄링은 각 작업의 우선순위를 고정적으로 부여하는 것이 아니라, 작업의 실행 특성에 따라 우선순위를 동적으로 변경한다. 예를 들어, 키보드 입력을 기다리는 상태에서 CPU를 반복해서 양보하는 작업은 상호작용 프로세스의 동작 방식과 비슷하므로 우선순위를 높게 유지한다. 반면에 CPU를 오랫동안 집중적으로 사용하는 작업은 우선순위를 낮춘다. 이렇게 함으로써 MLFQ는 작업의 실행 이력을 이용하여 작업의 미래 동작을 예측하려고 시도한다.
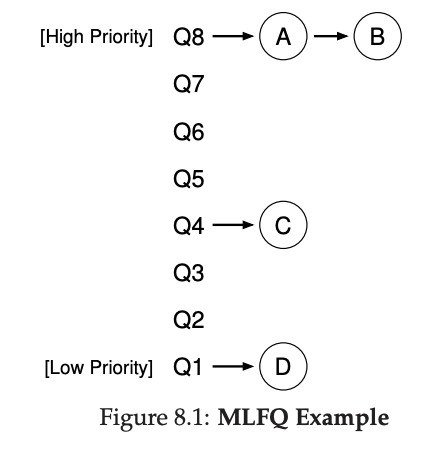
큐의 상태를 시각적으로 나타내면 Figure 8.1과 같이 나타낼 수 있다. 이 그림에서는 높은 우선순위 레벨에 두 개의 작업(A와 B)이 있고, 중간 우선순위 레벨에는 작업 C가, 낮은 우선순위 레벨에는 작업 D가 있다. 이 경우, MLFQ 스케줄러는 A와 B가 가장 높은 우선순위 작업이기 때문에 시간을 번갈아가면서 할당할 것이다. 하지만 우선순위가 낮은 C와 D는 실행될 기회를 전혀 얻지 못할 것이다.
이렇게 큐의 정적인 상태를 보여주는 것만으로는 MLFQ 스케줄러의 작동 원리를 이해하기 어렵다. 우리는 작업의 우선순위가 시간에 따라 어떻게 변하는지 이해해야 한다. 그리고 이것이 다음으로 이어지는 내용이다.
2. Attempt #1: How To Change Priority
MLFQ는 작업의 우선순위를 동적으로 변경하여 작업이 속한 큐를 조절한다. 이를 위해 작업의 특성을 고려하여 스케줄러는 다음과 같은 우선순위 조정 알고리즘을 사용한다.
• Rule 3: 새로운 작업이 시스템에 들어오면 가장 높은 우선순위(최상위 큐)에 배치된다.
• Rule 4a: 작업이 한 번의 시간 슬라이스 동안 실행 중이면 우선순위가 감소하여 하나 낮은 우선순위 큐에 배치된다.
• Rule 4b: 작업이 시간 슬라이스가 끝나기 전에 CPU를 양보하면 우선순위는 유지된다.
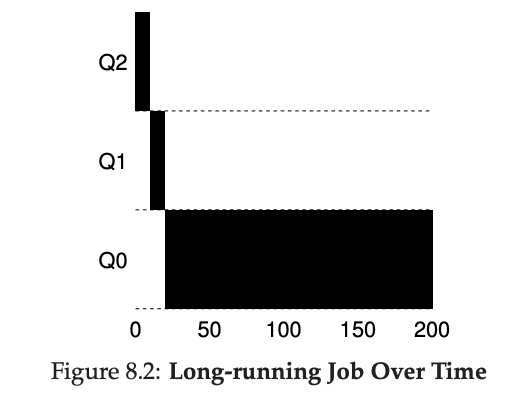
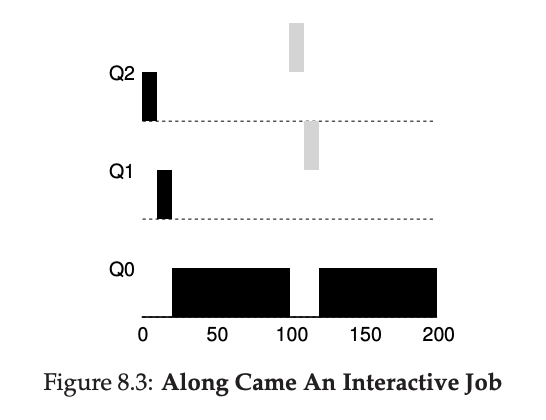
하지만 이러한 알고리즘에도 여러 가지 문제점이 있다. 예를 들어, 시스템 내에 "너무 많은" 상호작용 작업이 있으면 CPU 시간을 모두 소비하여 장기간 실행되는 작업이 CPU를 받지 못해 굶어 죽을 수 있다.
이 문제를 해결하기 위해서는 장기간 실행되는 작업이 적어도 어느 정도의 CPU 시간을 확보할 수 있도록 스케줄링해야 한다.
또한, 스케줄러를 속이기 위해 프로그램을 개조하는 "게임"을 할 수 있는 똑똑한 사용자도 있다. 예를 들어, 시간 슬라이스가 끝나기 전에 I/O 작업을 실행하여 CPU를 양보하면 작업은 같은 큐에 남아 더 많은 CPU 시간을 할당받을 수 있다.
이러한 방법으로 CPU 시간을 거의 독점하는 작업이 존재할 수 있다.
마지막으로, 프로그램이 시간이 지남에 따라 행동 방식이 변경될 수 있다는 문제가 있다. 예를 들어, CPU를 많이 사용하는 작업이 상호작용 작업으로 전환될 수 있다.
이러한 경우에도 현재 알고리즘은 해당 작업을 다른 상호작용 작업과 동등하게 다루지 못하게 된다.
3. Attempt #2: The Priority Boost
장기간 실행되는 CPU-bound 작업이 굶어 죽지 않도록 보장하기 위해 우선순위를 주기적으로 높여줄 수 있다. 이를 위해서는 다음과 같은 알고리즘을 추가해야 한다.
• Rule 5: 일정 시간 S가 지나면, 시스템 내 모든 작업을 최상위 큐로 이동시킨다.
이렇게 함으로써 두 가지 문제가 해결된다. 첫째, 작업들은 CPU 시간을 공유하여 서비스를 받게 되며, 굶어 죽지 않는다. 둘째, CPU-bound 작업이 상호작용 작업으로 전환되면 우선순위를 높여줌으로써 제대로 처리할 수 있다.
하지만 시간 S의 값을 어떻게 설정해야 할지는 여전히 문제이다. 이 값이 너무 높으면, 장기간 실행되는 작업이 굶어 죽을 수 있으며, 너무 낮으면 상호작용 작업이 충분한 CPU 시간을 얻지 못할 수 있다.
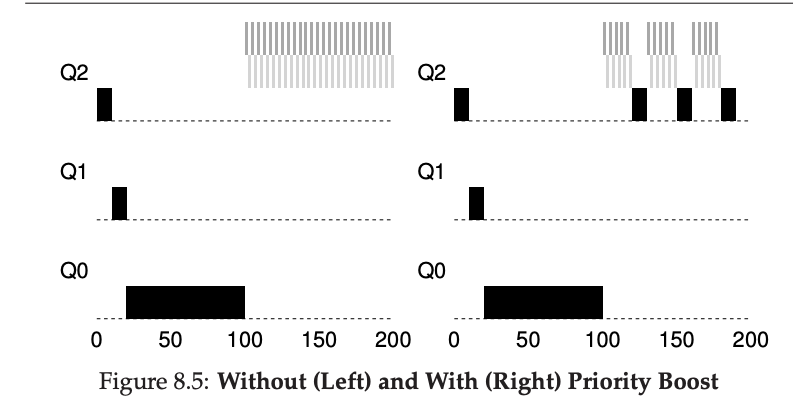
예를 들어, Figure 8.5 (6페이지)에서는 우선순위 부스팅이 없는 경우와 50ms마다 우선순위 부스팅이 있는 경우를 보여준다. 우선순위 부스팅이 없는 경우, 두 개의 상호작용 작업이 도착하면 장기간 실행되는 작업이 굶어 죽게 된다. 하지만 우선순위 부스팅이 주기적으로 일어나면, 장기간 실행되는 작업은 일정한 간격으로 최상위 큐로 이동하여 일시적으로 실행될 수 있게 된다.
4. Attempt #3: Better Accounting
우리는 이제 마지막 문제를 해결해야 한다: 스케줄러 게임을 방지하는 방법이 무엇인가? 문제의 근본적인 원인은 Rule 4a와 4b이다. 이 규칙은 작업이 CPU 시간 할당량을 모두 사용하지 않고 CPU를 반납하면 우선순위를 유지하도록 한다. 이 규칙을 어떻게 수정해야 할까?
해결책은 MLFQ의 각 레벨에서 CPU 시간을 더 잘 추적하는 것이다. 프로세스가 특정 레벨에서 얼마나 많은 시간 슬라이스를 사용했는지 추적함으로써, 한 레벨에서 할당량을 모두 사용하면 다음 우선순위 큐로 강등시키는 것이다. 여러 번 CPU를 반납하여 시간 슬라이스를 모두 사용했는지, 한 번에 사용했는지 여부는 중요하지 않다.
따라서, 우리는 Rule 4a와 4b를 다음과 같은 하나의 규칙으로 다시 작성한다.
• Rule 4: 작업이 특정 레벨에서 시간 할당량을 모두 사용하면 (CPU를 반납한 횟수와 상관없이), 우선순위가 낮아진다(다음 우선순위 큐로 이동한다).
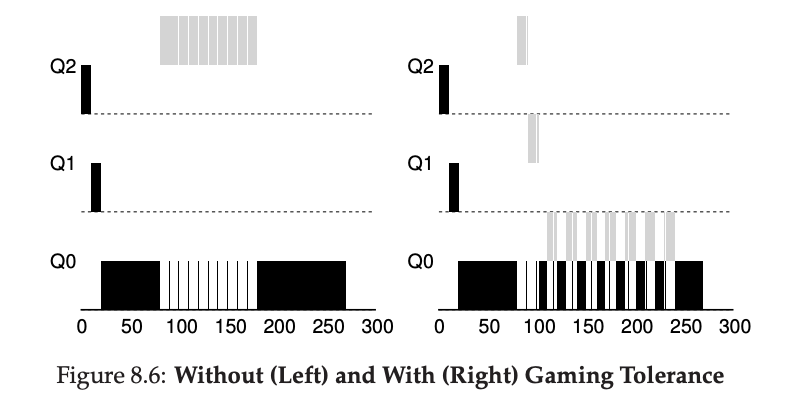
예를 들어, Figure 8.6 (7페이지)은 예전 Rule 4a와 4b로 스케줄러 게임을 시도한 워크로드와 새로운 Rule 4로 게임을 방지한 경우를 비교한 그래프를 보여준다. Rule 4가 없으면, 프로세스는 시간 슬라이스가 끝나기 직전에 I/O를 발생시켜 CPU 시간을 독점할 수 있다. 그러나 보호 기능이 있는 경우, 프로세스는 I/O 동작과 관계없이 천천히 큐에서 내려가며 CPU를 부당하게 독점할 수 없다.
