
이번 장에서는 비례적 할당 스케줄러 또는 공정한 할당 스케줄러라고도 불리는 다른 유형의 스케줄러를 살펴볼 것이다. 비례적 할당은 간단한 개념에 기반하고 있는데, 응답 시간이나 반환 시간 최적화 대신 각 작업이 일정한 CPU 시간의 비율을 보장하도록 하는 것이다. Waldspurger와 Weihl의 연구에서 발견된 lottery scheduling은 비례적 할당 스케줄링의 훌륭한 초기 예이다. 기본 개념은 매우 간단하다. 일정 주기마다 추첨을 통해 다음에 실행될 프로세스를 결정한다. 더 자주 실행되어야 하는 프로세스는 추첨에서 이길 확률이 더 높도록 해야한다. 이제 자세한 내용으로 넘어가보자. 그 전에 핵심 개념을 살펴보자. CPU를 어떻게 비례적으로 할당할 수 있을까? 이를 위한 핵심 메커니즘은 무엇일까? 그리고 이러한 방법은 얼마나 효과적일까?
1. Basic Concept: Tickets Represent Your Share
로또 스케줄링의 기본 개념은 티켓(ticket)이다. 티켓은 프로세스(또는 사용자 또는 기타 등등)가 받아야 하는 자원의 비율을 나타낸다. 예를 들어 A와 B 두 프로세스가 있고 A는 75개의 티켓을, B는 25개의 티켓을 가지고 있다고 가정해보자. 따라서 우리가 원하는 것은 A가 CPU의 75%를, B가 나머지 25%를 받는 것이다.

로또 스케줄링은 일정 간격(예: 타임 슬라이스마다)으로 복권을 추첨하여 프로세스가 어떤 작업을 수행할지 결정한다. 복권 추첨은 간단하다. 스케줄러는 총 티켓 수를 알아야 하며(위 예에서는 100개), 이후 당첨 번호를 뽑는다. 당첨 번호는 0부터 99까지의 숫자 중 하나이며, A가 0에서 74까지의 티켓을, B가 75에서 99까지의 티켓을 가지고 있다면 당첨 번호는 A 또는 B가 실행될지를 결정한다. 그리고 해당 프로세스의 상태를 로드하여 실행한다.
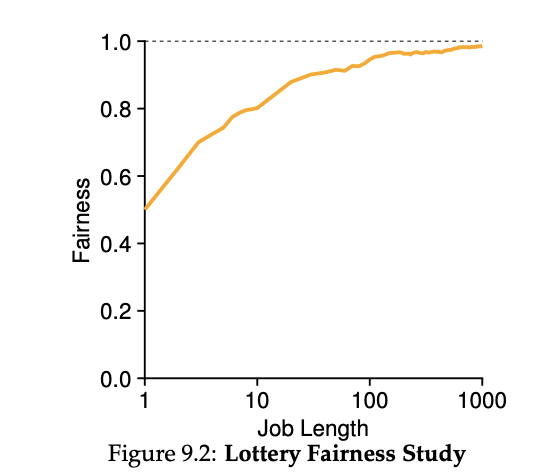
로또 스케줄링에서 무작위성을 사용하기 때문에 원하는 비율을 보장하지는 않지만, 오랜 시간 경쟁을 하면 더 정확한 비율을 얻을 가능성이 높아진다. 예를 들어 위 예에서 B가 원하는 25% 할당량보다 적은 시간을 얻었지만, 경쟁이 계속되면 더 정확한 비율을 얻을 수 있다는 것이다.
2. Ticket Mechanisms
로또 스케줄링에는 티켓이라는 개념이 사용되며, 각 프로세스(또는 사용자 또는 기타)가 받아야 하는 자원의 비율을 나타낸다. 프로세스가 가진 티켓의 백분율은 시스템 자원의 프로세스의 비율을 나타낸다. 예를 들어, A와 B라는 두 개의 프로세스가 있고 A는 75장의 티켓을, B는 25장의 티켓을 가지고 있다면, A가 75%의 CPU 시간을, B가 나머지 25%의 CPU 시간을 받도록 원한다.
로또 스케줄링은 일정 간격(예: 각 타임 슬라이스마다)으로 추첨을 진행하여 이를 확률적으로(결정론적으로는 아니지만) 구현한다. 추첨을 진행하기 위해서는 모든 티켓의 총 수를 알아야 한다. 예를 들어 A가 0에서 74까지의 티켓을 가지고 있고, B가 75에서 99까지의 티켓을 가지고 있다면, 추첨에서 이긴 티켓은 0에서 99까지의 숫자 중 하나이며, 그 숫자에 따라 A나 B가 실행된다. 이후 스케줄러는 해당 프로세스의 상태를 로드하고 실행한다.
로또 스케줄링은 티켓을 다양한 방법으로 조작할 수 있는 몇 가지 매커니즘을 제공한다. 하나는 티켓 화폐 개념이다. 이를 사용하면 티켓 세트를 사용하여 사용자가 자신의 작업 간에 티켓을 자유롭게 할당할 수 있으며, 시스템은 이러한 화폐를 전역 값으로 자동 변환한다. 또 다른 유용한 매커니즘은 티켓 이전이다. 이전을 사용하면 프로세스가 일시적으로 티켓을 다른 프로세스에게 양도할 수 있다. 마지막으로 티켓 인플레이션은 때로 유용한 기술이 될 수 있다. 인플레이션을 사용하면 프로세스가 일시적으로 소유하는 티켓 수를 임시로 높일 수 있다.
3. Implementation
로또 스케줄링의 가장 놀라운 점은 그 구현의 간단함이다. 랜덤 숫자 생성기, 시스템의 프로세스를 추적할 데이터 구조(예를 들어, 리스트), 전체 티켓 수가 필요하다. 프로세스를 리스트에 유지한다고 가정해 보자. 다음은 세 개의 프로세스 A, B, C로 구성된 예제이며, 각각의 티켓 수가 있다.

스케줄링 결정을 내리기 위해서는 먼저 전체 티켓 수(400)에서 랜덤한 숫자(우승자)를 선택해야 한다. 300이라는 숫자를 선택한다고 가정해 보자. 그런 다음, 단순한 카운터를 사용하여 우승자를 찾기 위해 리스트를 탐색한다(그림 9.1 참조). 코드는 프로세스 목록을 거치면서 각 티켓 값을 카운터에 더하고, 이 값이 우승자보다 큰 경우 현재 목록 요소가 우승자이다. 우승 티켓이 300이라는 예제에서는, 카운터는 A의 티켓을 나타내는 100으로 증가한다. 100은 300보다 작기 때문에 루프가 계속된다. 그 다음에는 카운터가 150(B의 티켓)로 업데이트되고 여전히 300보다 작아서 루프가 계속된다. 마지막으로 카운터는 400(C의 티켓)로 업데이트되며, 300보다 크므로 우리는 C(우승자)를 가리키는 현재를 반환한다.
이 프로세스를 가장 효율적으로 만들기 위해서는 일반적으로 리스트를 티켓 수가 가장 많은 것부터 가장 적은 것까지 정렬된 순서로 구성하는 것이 좋다. 정렬은 알고리즘의 정확성에 영향을 미치지 않지만, 대부분의 티켓을 가진 몇 개의 프로세스가 있는 경우, 가장 적은 수의 리스트 반복을 수행하도록 보장한다.
4. How To Assign Tickets?
로또 스케줄링에서 해결해야 할 문제 중 하나는 작업에 어떻게 티켓을 할당할 것인가이다. 이 문제는 티켓이 할당된 방식에 따라 시스템 동작이 크게 달라지기 때문에 해결하기 어렵다. 사용자가 최선을 알고 있을 것이라고 가정해서 사용자마다 일정 수의 티켓을 할당하고, 사용자는 실행하는 작업에 대해 원하는대로 티켓을 할당하는 방식이 있다. 그러나 이러한 해결책은 실제로는 해결책이 아니다. 따라서 작업 집합이 주어졌을 때 "티켓 할당 문제"는 여전히 해결되지 않은 문제이다.
5. Stride Scheduling
Stride scheduling은 deterministic fair-share scheduler로서, lottery scheduling과는 다르게 randomness 대신 stride 값과 pass value를 사용해 프로세스를 스케줄링한다. 각 프로세스는 inverse proportion에 따른 stride를 가지며, 스케줄링 시 가장 pass value가 낮은 프로세스가 선택된다.
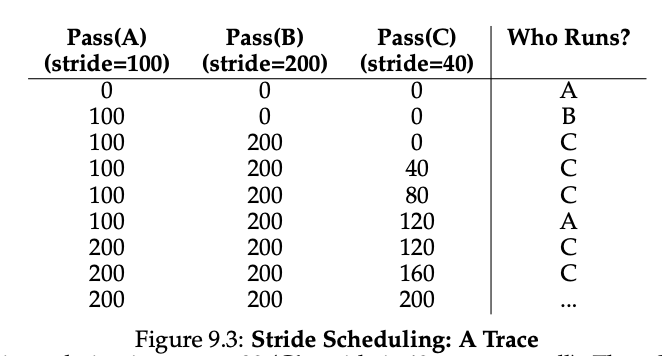
예를 들어, ticket 값이 100, 50, 250인 A, B, C 프로세스의 stride 값은 100, 200, 40이 된다. 이 방법은 모든 프로세스가 한 번씩 실행될 때까지 기다리는 데에 정확하게 맞추어진 비율을 보장한다. 하지만 global state가 필요하다는 단점이 있다. 새로운 job이 들어오면 그것의 pass value를 어떻게 할 지 결정해야 한다. 이에 비해 lottery scheduling은 각 프로세스마다 global state가 없으므로 새로운 job이 들어오면 ticket 값만 업데이트하면 된다는 장점이 있다.
