
1. 스택의 이해와 ADT 정의
앞 여러 챕터에 걸쳐 공부한 리스트는 대표적인 선형 자료구조이다.
그리고 이번에 소개하는 스택이란 자료구조도 선형 자료구조의 일종이다.
우리가 배우는 각종 자료구조에 비유할 수 있는 예는 우리 주변에서 쉽게 찾을 수 있고, 또 몇 가지 도구를 이용해서 실물로 직접 구현해 볼수도 있다.
이번에 소개하는 스택도 마찬가지이다.
스택을 설명할만한 사물이 주변에 워낙 많지만 그 중에서도 대표적으로 등장하는 몇 가지는 '쌓아 올려진 상자더미'나 '쟁반 위에 쌓인 접시'가 아닐까 생각한다.
쟁반 위에 접시를 쌓는 것으로 예를 들어보자.
접시를 하나씩 쌓고 어느 순간에 쌓여진 접시를 다시 내리는 과정에서, 먼저 쌓은 접시일수록 나중에 내려지고, 나중에 쌓은 접시일수록 빨리 내려진다.
이렇듯 스택은 나중에 들어간 것이 먼저 나오는 구조이다 보니 '후입선출 방식의 자료구조'라고도 불리고, 영어로 'LIFO(Last-In-First-Out) 구조의 자료구조'라고도 불린다.
자! 이렇게 해서 스택 자료구조에 대한 개념적인 설명을 다하였다.
어떤가! 리스트보다 쉽지 않은가?
실제로 스택은 쉽게 이해할 수 있고 또 쉽게 구현할 수 있는 자료구조이다.
앞서 살펴본 리스트 자료구조의 ADT는 필요에 따라서 그 정의 내용에 약간씩 차이가 있다.
그에 비해 스택의 ADT는 상대적으로 정형화된 편이다.
쟁반과 접시를 가지고 우리가 할 수 있는 일이 무엇이겠는가?
다음 정도 아니겠는가?
- 쟁반에 접시를 쌓는다(넣는다): push
- 쟁반 위에 쌓여진 접시를 내린다(꺼낸다): pop
- 이번에 내릴 접시의 색이 무엇인지 쟁반을 들여다 본다: peek그리고 여기에 하나를 더 추가한다면 다음 정도이다.
- 쟁반이 비었는지 확인한다.특히 스택을 대표하는 넣고, 꺼내고, 들여다 보는 연산을 가리켜 각각 push, pop, peek이라 한다.
때문에 스택의 ADT는 다음과 같이 정의가 되며, 이것이 스택의 보편적인 ADT이다.

자! 이제 ADT도 정의되었으니, 이를 기반으로 스택의 구현을 위한 구조체를 정의하고 헤더파일을 디자인할 차례이다.
그런데 이에 앞서 결정해야 할 사항이 있다.
"스택을 배열 기반으로 구현할 것인가?"
"아니면 연결 리스트 기반으로 구현할 것인가?"스택은 배열을 이용해서도 구현이 가능하고, 또 연결 리스트를 이용해서도 구현이 가능하다.
따라서 우리는 배열 기반의 스택과 연결 리스트 기반의 스택을 모두 구현해볼 것이다.
"연결 리스트도 하나의 자료구조인데, 이것을 이용해서 다른 자료구조를 구현한다고요?"사실 배열도 자료구조이다.
그럼에도 불구하고 리스트의 구현 도구로 사용하지 않았는가?
마찬가지로 연결 리스트도 하나의 자료구조이지만 다른 자료구조의 구현에 사용되는 중요한 도구이기도 하다.
어찌 보면 연결 리스트는 다른 자료구조의 구현에 사용되는 도구로써 더 큰 의미를 지닌다고 볼 수 있다.
자료구조를 계속 공부하다 보면 여러분도 머지않아 그렇게 느낄 것이다.
2. 스택의 배열 기반 구현
앞서 연결 리스트를 구현하면서 우리는 다양한 상황에 대해서 그림을 그렸다.
그리고 그 그림을 기반으로 구현을 완성하였다.
하지만 스택은 그 특성상 리스트만큼 상황이 다양하지 않다.
그저 데이터를 추가하는 상황에 꺼내는 상황만 그림으로 정리하면 된다.
그럼 먼저 데이터를 추가하는 상황을 그림으로 정리해보겠다.
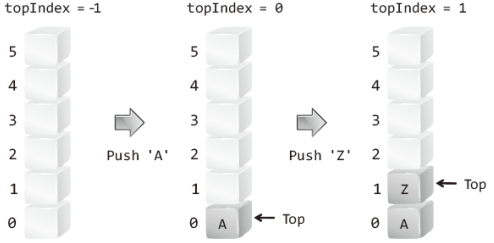
위 그림에서 주목할 것 두 가지는 다음과 같다.
- 인덱스 0의 배열 요소가 '스택의 바닥'으로 정의되었다.
- 마지막에 저장된 데이터의 위치를 기억해야 한다.우선 인덱스 0의 배열 요소를 스택의 바닥으로 둔 이유는 다음과 같다.
"인덱스 0의 요소를 스택의 바닥으로 정의하면, 배열의 길이에 상관 없이 언제나 인덱스 0의 요소가 스택의 바닥이 된다."그리고 위 그림에서는 가장 최근에 저장된, 다시 말해서 가장 위에 저장된 데이터를 Top으로 가리키고 있으며, 이 Top이 가리키는 위치의 인덱스 값을 변수 topIndex에 저장하고 있다(실제로 Top은 변수 topIndex를 의미한다).
이렇듯 마지막에 저장된 데이터의 위치를 별도로 기억해 둬야 다음과 같이 push 연산과 pop 연산을 쉽게 완성할 수 있다.
- push: Top을 한 칸 올리고, Top이 가리키는 위치에 데이터 저장
- pop: Top이 가리키는 데이터를 반환하고, Top을 아래로 한 칸 내림이렇듯 배열 기반 스택은 그 구조가 단순하다.
따라서 pop의 과정을 설명하는 그림을 별도로 그리지는 않겠다.
이로써 push와 pop에 대해 이해하였고 앞서 ADT도 정의하였으니, 이를 기반으로 스택의 헤더파일을 정의하겠다.
ArrayBaseStack.h
#ifndef __AB_STACK_H__
#define __AB_STACK_H__
#define TRUE 1
#define FALSE 0
#define STACK_LEN 100
typedef int Data;
typedef struct _arrayStack
{
Data stackArr[STACK_LEN];
int topIndex;
} ArrayStack;
typedef ArrayStack Stack;
void StackInit(Stack * pstack);
int SIsEmpty(Stack * pstack);
void SPush(Stack * pstack, Data data);
Data SPop(Stack * pstack);
Data SPeek(Stack * pstack);
#endif이어서 위의 헤더파일에 선언된 함수들을 구현할 텐데, 그 구현이 결코 어렵지 않다.
스택을 표현한 다음 구조체의 정의를 보면 StackInit 함수를 무엇으로 채워야 할지 알 수 있다.
typedef struct _arrayStack
{
Data stackArr[STACK_LEN];
int topIndex;
} ArrayStack;이 중에서 초기화할 멤버는 가장 마지막에 저장된 데이터의 위치를 가리키는 topIndex 하나이다.
따라서 StackInit 함수는 다음과 같이 간단히 정의한다.
void StackInit(Stack * pstack)
{
pstack->topIndex = -1; // topIndex의 -1은 빈 상태를 의미함
}topIndex에 0이 저장되면, 이는 인덱스 0의 위치에 마지막 데이터가 저장되었음을 뜻하는 것이 된다.
따라서 topIndex를 0이 아닌 -1로 초기화 해야 한다.
이어서 SIsEmpty 함수의 정의를 보자. 이 함수는 스택이 비어있는지 확인할 때 호출하는 함수이다.
스택이 비어있는 경우 topIndex의 값이 -1이니, 이 함수는 다음과 같이 정의되어야 한다.
int SIsEmpty(Stack * pstack)
{
if(pstack->topIndex == -1) // 스택이 비어있다면
return TRUE;
else
return FALSE;
}이제 스택의 핵심인 SPush 함수와 SPop 함수를 보일 차례인데, 이 둘 역시 다음과 같이 간단히 정의가 된다.
void SPush(Stack * pstack, Data data) // push 연산 담당 함수
{
pstack->topIndex += 1; // 데이터 추가를 위한 인덱스 값 증가
pstack->stackArr[pstack->topIndex] = data; // 데이터 저장
}Data SPop(Stack * pstack) // pop 연산 담당 함수
{
int rIdx;
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
rIdx = pstack->topIndex; // 삭제할 데이터가 저장된 인덱스 값 저장
pstack->topIndex -= 1; // pop 연산의 결과로 topIndex 값 하나 감소
return pstack->stackArr[rIdx]; // 삭제되는 데이터 반환
}혹시나 해서 말하지만, 꺼낸다는 의미의 pop에는 삭제와 반환의 의미가 함께 담겨 있다.
꺼냈으니 삭제가 된 것이고, 꺼냈으니 반환도 이뤄지는 것 아니겠는가?
그래서 위의 주석에는 '삭제'라는 표현이 들어가 있다.
그리고 topIndex의 값을 근거로 하여 데이터를 저장하니, 이 변수에 저장된 값을 하나 감소시키는 것만으로도 데이터의 소멸은 완성이 된다.
이제 마지막으로 SPeek 함수를 정의할 차례인데, 이 함수는 SPop 함수와 달리 반환한 데이터를 소멸시키지 않으므로 다음과 같이 간단한 정의가 가능하다.
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
return pstack->stackArr[pstack->topIndex];
}프로그램을 구현하다 보면 스택이 반환할 다음 데이터를 확인할 필요가 간혹 있다.
그런데 그때마다 pop 함수를 호출하면 확인과 동시에 소멸이 되니, 확인은 하되 소멸시키지 않는 함수가 필요하다.
그래서 위와 같이 peek 연산을 담당하는 함수를 스택의 정의에 포함하기도 한다.
그럼 지금까지 소개한 함수들을 하나의 소스파일로 묶고, 이를 확인하기 위한 main 함수를 제시하겠다.
그런데 아래의 main 함수에서는 SPeek 함수를 호출하지 않으니, 궁금하다면 코드를 조금 수정해서 그 결과를 확인하기 바란다.
ArrayBaseStack.c
#include <stdio.h>
#include <stdlib.h>
#include "ArrayBaseStack.h"
void StackInit(Stack * pstack)
{
pstack->topIndex = -1;
}
int SIsEmpty(Stack * pstack)
{
if(pstack->topIndex == -1)
return TRUE;
else
return FALSE;
}
void SPush(Stack * pstack, Data data)
{
pstack->topIndex += 1;
pstack->stackArr[pstack->topIndex] = data;
}
Data SPop(Stack * pstack)
{
int rIdx;
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
rIdx = pstack->topIndex;
pstack->topIndex -= 1;
return pstack->stackArr[rIdx];
}
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
return pstack->stackArr[pstack->topIndex];
}ArrayBaseStackMain.c
#include <stdio.h>
#include "ArrayBaseStack.h"
int main(void)
{
// Stack의 생성 및 초기화 ///////
Stack stack;
StackInit(&stack);
// 데이터 넣기 ///////
SPush(&stack, 1); SPush(&stack, 2);
SPush(&stack, 3); SPush(&stack, 4);
SPush(&stack, 5);
// 데이터 꺼내기 ///////
while(!SIsEmpty(&stack))
printf("%d ", SPop(&stack));
return 0;
}실행결과에서는 입력된 데이터가 역순으로 출력됨을 보이고 있다.
그리고 이것이 스택의 가장 중요한 특성이다.
3. 스택의 연결 리스트 기반 구현
기능적인 부분만 고려를 한다면 배열은 대부분 연결 리스트로 교체가 가능하다.
배열도 연결 리스트도 기본적인 선형 자료구조이기 때문이다.
앞서 구현한 스택에서 배열을 연결 리스트로 변경할 경우, 연결 리스트가 갖는 특징이 그대로 스택에 반영된다.
하지만 연결 리스트를 기반으로 스택을 구현한다고 하면 부담을 느끼는 경우가 많다.
연결 리스트도 어려운데 이것을 이용해서 스택을 구현해야 하기 때문에 뭔가 두 배로 고민을 해야 한다고 생각하기 때문이다.
여러분도 그렇게 느낀다면 다음과 같이 생각을 바꾸자.
"스택도 연결 리스트이다."
"다만 저장된 순서의 역순으로 조회(삭제)가 가능한 연결 리스트일 뿐이다!"사실 우리는 이와 유사한 성격의 연결 리스트를 구현한 경험이 있다.
새로운 노드를 꼬리가 아닌 머리에 추가하는 형태로 구현한 연결 리스트가 바로 그것이다.
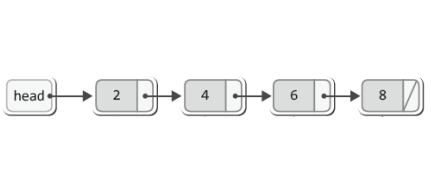
이렇듯 메모리 구조만 놓고 보면 이것이 스택을 구현한 것인지, 단순 연결 리스트를 구현한 것인지 알 수 없다.
다만 위이 그림과 같은 메모리 구조를 바탕으로 push 연산과 pop 연산이 포함된 ADT를 갖는다면 이것이 스택이 되는 것이다.
그럼 위의 연결 리스트 모델과 앞서 정의한 스택 ADT를 기준으로 연결 리스트 기반의 스택을 구현해 보겠다.
위의 그림에서 보이듯이 스택을 구현하기 위해서 필요한 것은 포인터 변수 head 하나이니, 연결 리스트 기반의 스택을 위한 헤더파일은 다음과 같이 정의할 수 있다.
ListBaseStack.h
#ifndef __LB_STACK_H__
#define __LB_STACK_H__
#define TRUE 1
#define FALSE 0
typedef int Data;
typedef struct _node // 연결 리스트의 노드를 표현한 구조체
{
Data data;
struct _node * next;
} Node;
typedef struct _listStack // 연결 리스트 기반 스택을 표현한 구조체
{
Node * head;
} ListStack;
typedef ListStack Stack;
void StackInit(Stack * pstack); // 스택 초기화
int SIsEmpty(Stack * pstack); // 스택이 비었는지 확인
void SPush(Stack * pstack, Data data); // 스택의 push 연산
Data SPop(Stack * pstack); // 스택의 pop 연산
Data SPeek(Stack * pstack); // 스택의 peek 연산
#endif위의 헤더파일에 선언된 함수의 종류와 그 기능은 앞서 보인 배열 기반 스택의 경우와 다르지 않다.
내부구현이 배열에서 연결 리스트로만 바뀌는 것이니 이는 당연한 일이다.
연결 리스트를 제대로 공부했다면 위의 헤더파일에 선언된 함수들을 직접 정의할 수 있을 것이다.
그럼 우선 StackInit 함수와 SIsEmpty 함수부터 소개하겠다.
void StackInit(Stack * pstack)
{
pstack->head = NULL; // 포인터 변수 head는 NULL로 초기화된다.
}int SIsEmpty(Stack * pstack)
{
if(pstack->head == NULL) // 스택이 비면 head에는 NULL이 저장된다.
return TRUE;
else
return FALSE;
}위의 함수 정의에서 보이듯이, 포인터 변수 head는 새로 추가된 노드를 가리켜야 하므로, 비어 있는 상태를 표현하기 위해서 NULL로 초기화를 진행하였다.
그리고 스택이 비어 있는 경우 head에는 NULL이 저장되므로, head가 NULL일 때 TRUE를 반환하도록 SIsEmpty 함수를 정의하였다.
이어서 SPush 함수와 SPop 함수를 정의할 차례인데, SPush 함수는 리스트의 머리에 새 노도를 추가하는 함수이니 다음과 같이 정의해야 한다.
void SPush(Stack * pstack, Data data)
{
Node * newNode = (Node*)malloc(sizeof(Node)); // 새 노드 생성
newNode->data = data; // 새 노드에 데이터 저장
newNode->next = pstack->head; // 새 노드가 최근에 추가된 노드를 가리킴
pstack->head = newNode; // 포인터 변수 head가 새 노드를 가리킴
}반대로 SPop 함수는 포인터 변수 head가 가리키는 노드를 소멸시키고, 소멸된 노드의 데이터를 반환해야 하므로 다음과 같이 정의해야 한다.
Data SPop(Stack * pstack)
{
Data rdata;
Node * rnode;
if(SIsEmpty(pstack)) {
printf("Stack Memory Error!");
exit(-1);
}
rdata = pstack->head->data; // 삭제할 노드의 데이터를 임시로 저장
rnode = pstack->head; // 삭제할 노드의 주소 값을 임시로 저장
pstack->head = pstack->head->next; // 삭제할 노드의 다음 노드를 head가 가리킴
free(rnode); // 노드 삭제
return rdata; // 삭제된 노드의 데이터 반환
}이어서 마지막으로 SPeek 함수를 보이겠다.
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack)) {
printf("Stack Memory Error!");
exit(-1);
}
return pstack->head->data; // head가 가리키는 노드에 저장된 데이터 반환
}이로써 연결 리스트 기반의 스택도 완성하였다.
그럼 지금까지 소개한 함수들을 하나의 소스파일에 묶고, 이를 확인하기 위한 main 함수와 그 실행결과를 보이겠다.
ListBaseStack.c
#include <stdio.h>
#include <stdlib.h>
#include "ListBaseStack.h"
void StackInit(Stack * pstack)
{
pstack->head = NULL;
}
int SIsEmpty(Stack * pstack)
{
if(pstack->head == NULL)
return TRUE;
else
return FALSE;
}
void SPush(Stack * pstack, Data data)
{
Node * newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = pstack->head;
pstack->head = newNode;
}
Data SPop(Stack * pstack)
{
Data rdata;
Node * rnode;
if(SIsEmpty(pstack)) {
printf("Stack Memory Error!");
exit(-1);
}
rdata = pstack->head->data;
rnode = pstack->head;
pstack->head = pstack->head->next;
free(rnode);
return rdata;
}
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack)) {
printf("Stack Memory Error!");
exit(-1);
}
return pstack->head->data;
}ListBaseStackMain.c
#include <stdio.h>
#include "ListBaseStack.h"
int main(void)
{
// Stack의 생성 및 초기화 ///////
Stack stack;
StackInit(&stack);
// 데이터 넣기 ///////
SPush(&stack, 1); SPush(&stack, 2);
SPush(&stack, 3); SPush(&stack, 4);
SPush(&stack, 5);
// 데이터 꺼내기 ///////
while(!SIsEmpty(&stack))
printf("%d ", SPop(&stack));
return 0;
}