RNNLM(Recurrent Neural Network Language Model)
간단히 RNN으로 만든 언어모델
- time step이 있어입력길이를 고정하지 않고 사용가능
- 교사 강요(teacher forcing)를 이용해 학습
학습 과정
- 다음 문자 예측
- 예문 : 'what will the fat cat sit on'
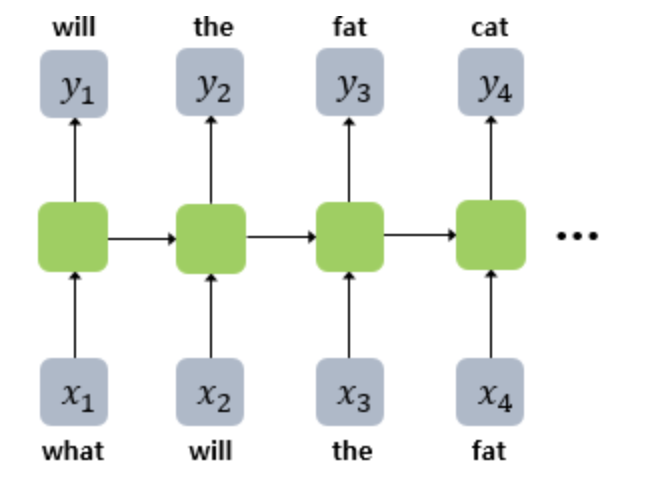
교사강요
- 교사 강요(teacher forcing)란, 테스트 과정에서 t 시점의 출력이 t+1 시점의 입력으로 사용되는 RNN 모델을 훈련시킬 때 사용하는 훈련 기법
- 훈련할 때 교사 강요를 사용할 경우, 모델이 t 시점에서 예측한 값을 t+1 시점에 입력으로 사용하지 않고, t 시점의 레이블. 즉, 실제 알고있는 정답을 t+1 시점의 입력으로 사용 (한 번 잘못 예측하면 뒤에서의 예측까지 영향)
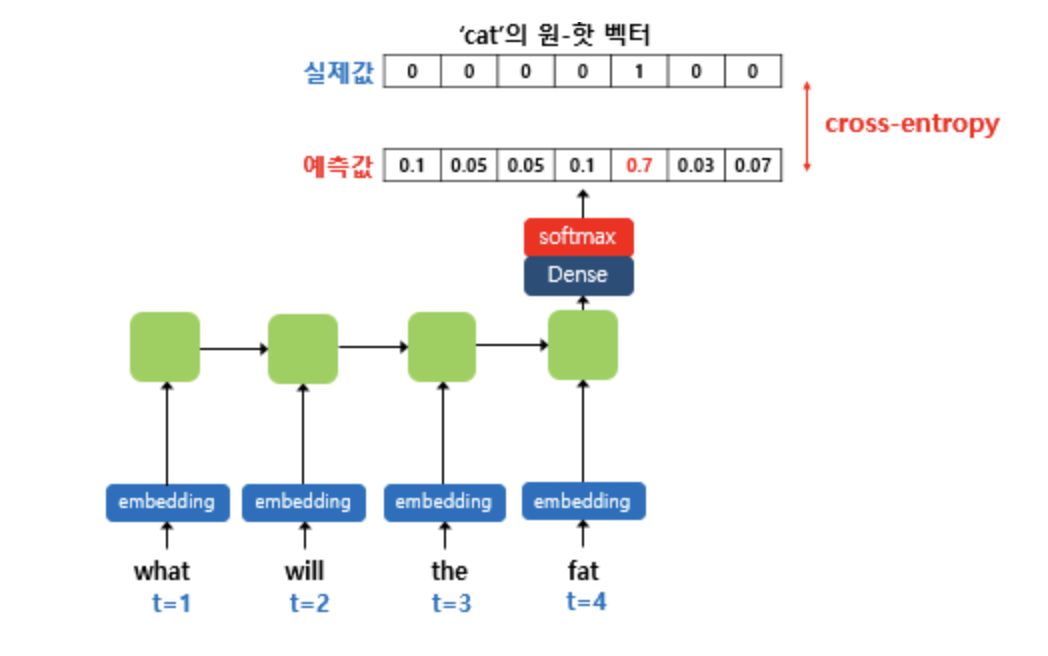
-
출력층에서 활성화함수로 소프트맥스함수 사용 (대충 0이하는 0, 이상은 1 인데 미분 가능)
-
예측한 값과 실제 레이블과의 오차를 계산하기 위해서 손실 함수로 크로스 엔트로피 함수를 사용
크로스엔트로피 (손실함수)
- 모델이 실제 레이블에 가까운 확률을 예측할수록 손실이 감소
- 예측 확률과 실제 레이블 사이의 차이가 클 때 손실이 더 크게 증가
RNNLM의 구조
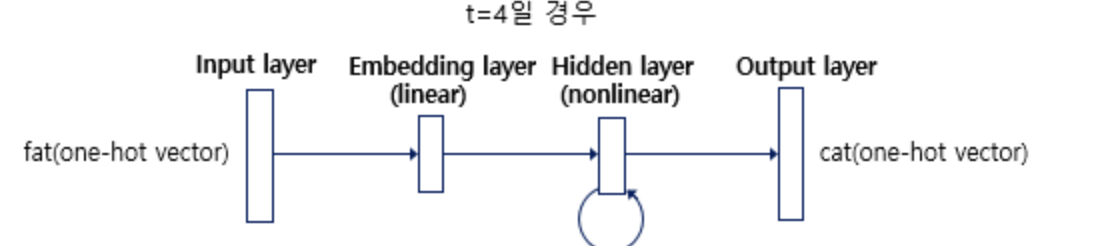
임베딩 층(Embedding Layer)
- 원-핫 벡터: 현 시점의 입력 단어는 원-핫 인코딩 벡터의 형태로 모델에 제공됩니다. 원-핫 벡터는 단어 집합의 크기만큼의 차원을 가지며, 해당 단어를 나타내는 인덱스의 위치만 1로, 나머지는 0으로 구성
- 임베딩 층의 역할: 임베딩 층은 이 원-핫 벡터를 입력 받아, 각 단어를 더 낮은 차원의 밀집 벡터로 매핑 -> 입력 차원 수 낮춤
- 임베딩 행렬: 임베딩 층에서는 원-핫 벡터와 임베딩 행렬(가중치 행렬)을 곱하여 임베딩 벡터를 생성.
임베딩 행렬의 크기는 , : 단어 집합의 크기(원-핫 벡터의 차원), :임베딩 벡터의 차원
여기서, 는 시간 에서의 단어의 임베딩 벡터, 는 해당 시간에서의 입력 단어의 인덱스(또는 원-핫 인코딩 벡터)를 나타냄
함수는 임베딩 행렬에서 에 해당하는 임베딩 벡터를 찾아내는 연산
은닉 층(Hidden Layer)
이전에 학습 한 것과 동일, 부분만 로 바뀜
출력 층(Output Layer)
1. 는 모델 예측값으로, 각 차원은 해당 인덱스의 단어가 다음 단어일 확률을 0과 1 사이의 값으로 나타낸다
2. 는 실제 다음 단어를 나타내는 원-핫 벡터인 실제값 에 가까워져야 합니다.
3. 과 사이의 차이를 최소화하기 위해 교차 엔트로피(cross-entropy) 손실 함수를 사용
4. 역전파 과정을 통해 RNNLM의 가중치 행렬과 임베딩 벡터 학습
softmax 함수 (활성함수)
- 벡터의 각 요소를 음수가 아닌 [0, 1]의 실수로 매핑
- 결과 값들의 합이 1이 되도록 변환

이것저것 해보는 중