
포스팅 할 정렬 키워드
해당 구현 알고리즘들은 오름차순으로 정렬하는 것을 구현하였습니다 !
정렬 (SORT)
1. 버블 정렬
2. 선택 정렬
3. 삽입 정렬
4. 퀵 정렬
버블 정렬 (Bubble Sort)
버블 정렬은 구현하기 쉬운 정렬이다. 정렬을 할 때 마다 큰 수가 뒤로 빠지는게 거품이 떠오르는거 같다고 해서 붙여진 이름이다.
해당 정렬 알고리즘의 시간 복잡도는 이다.
버블 정렬 과정
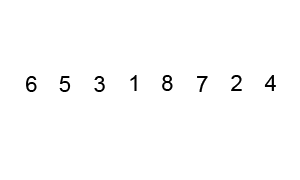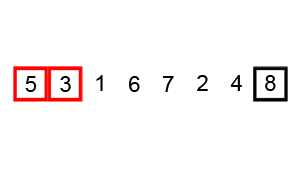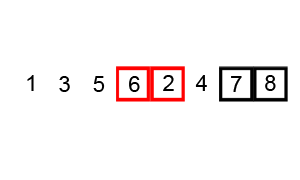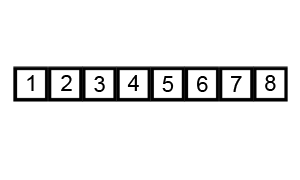
해당 과정의 첫 번째 STEP만 설명하여 이해해보자
먼저 N 은 0부터 시작하고 과정마다 1씩 증가한다.
1. N번째와 N+1번째 수를 비교한다.
2. 비교한 수에서 N번째 수가 더 크다면 자리를 바꾸고 N에 +1을 해준다.
3. 탐색이 다 끝났다면 다음 스탭으로 넘어간다.
다음 STEP때 이전 STEP의 마지막 인덱스는 검사하지 않는다.
이를 코드로 구현하면 이와 같다.
def bubble_sort(arr) :
n = len(arr)
for i in range(n-1, 0, -1) :
for j in range(i):
if arr[j] > arr[j+1] :
arr[j], arr[j+1] = arr[j+1], arr[j]
해당 코드를 구현 할 때 마지막 인덱스를 훑지 않도록 구현하는 것이 핵심인 것 같다.
제일 구현하기 쉬운 정렬이라 하는데, 루프문 조건 설정이 좀 헷갈렸다...
선택 정렬 (Selection Sort)
선택 정렬은 말 선택한 것을 정렬하는 것이다. 요소를 탐색하여 선택 후에 정렬을 거친다. 한번 정렬 할 때 모든 인덱스를 교환하는 버블 정렬과는 차이가 있다.
해당 정렬 알고리즘의 시간 복잡도는 이다.
선택 정렬 과정

해당 과정의 첫 번째 STEP만 설명하여 이해해보자
선택 정렬 과정
1. 첫번째 값을 정하고 그 값 이외의 인덱스를 배열 끝까지 훑는다.
2. 만약 정한 값보다 큰 요소가 나타난다면 정렬을 진행한다.
3. 인덱스를 끝까지 다 훑었다면 다음 스탭으로 넘어간다.
다음 STEP때의 첫번째 값은 이전 STEP의 다음 인덱스 값이 된다.
이를 코드로 구현하면 이와 같다.
def selection_sort(arr) :
n = len(arr)
for i in range(n-1) :
min_idx = i
for j in range(i+1, n) :
if arr[j] < arr[min_idx]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i] 선택 정렬에 대한 구현은 그리 어렵지 않았다.
삽입 정렬 (Insertion Sort)
삽입 정렬은 요소를 선택 후 그 값에 이전 인덱스의 요소가 선택한 요소의 값보다 클 경우 그 인덱스의 뒤에 삽입하는 정렬 방식이다. 해당 정렬 방식이 간단해보이지만, 코드로 구현할 때 삽입을 해야하는 인덱스를 위해 조건이 실행 될 때 마다 인덱스를 밀어내야하는 것이 포인트이다.
해당 정렬 알고리즘의 시간 복잡도는 이다.
삽입 정렬 과정
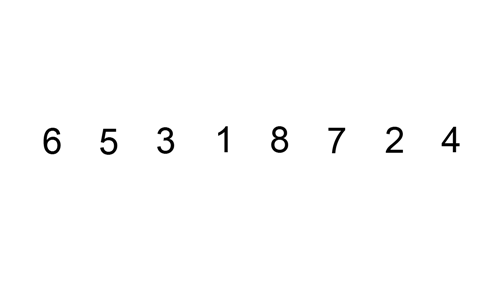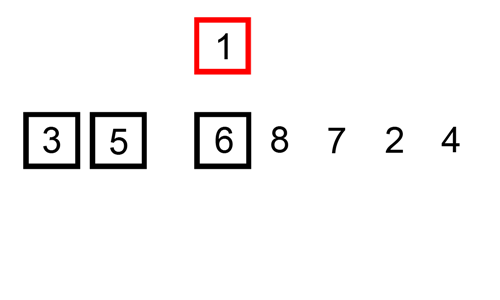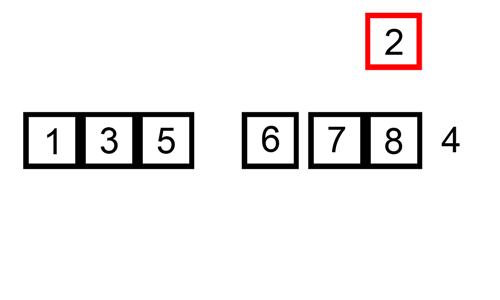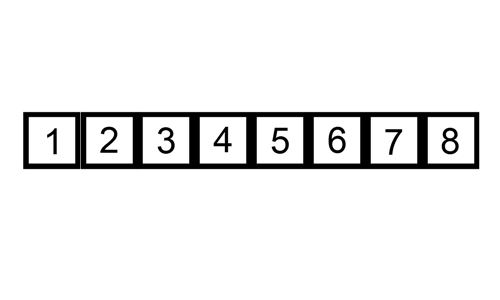
해당 과정의 첫 번째 STEP만 설명하여 이해해보자
삽입 정렬 과정
1. N + 1과 N의 인덱스를 서로 비교한다.
2. 만약 N+1의 값이 N보다 작다면, N을 계속 줄여나가며 값을 계속 비교한다.
N + 1의 값이 N보다 크다면 그 앞에 삽입한다.
3. 위 조건이 일어날 때 비교된 값은 인덱스가 앞으로 밀리게 된다.
이를 코드로 구현하면 이와 같다.
def insertion_sort(arr) :
n = len(arr)
for i in range(1, n) :
key = arr[i]
j = i - 1
while j >=0 and key < arr[j] :
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
설명을 너무 못했는데, 해당 코드 구현은 간단했다.
배열의 처음 값 + 1 에 해당 하는 값을 KEY값으로 저장한다.
해당 인덱스가 0이 될때 까지 계속해서 비교를 진행하며, 조건에 충족 될 시 이전 값의 인덱스를 밀어낸다.
이때 KEY값 보다 작은 값이 등장한다면 그 앞 인덱스에 삽입한다.
퀵 정렬 (Quick Sort)
퀵 정렬은 피봇 값과 분할을 사용하여 구현한 정렬이다. 해당 정렬을 이용하면 시간이 줄어들 것 같지만, 최고의 효율을 낼 수 있는 데이터가 있고, 최악의 효율을 낼 수 있는 데이터가 있다고 한다.
왜 퀵소트인지 의문이듦...
해당 정렬 알고리즘의 시간 복잡도는 최고의 효율을 낼때 이다.
하지만 최악의 경우는 이다.
퀵 정렬 과정
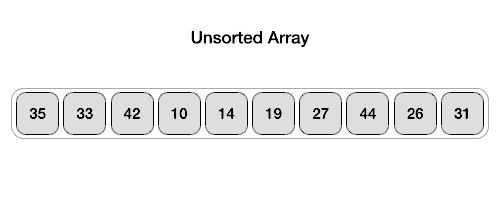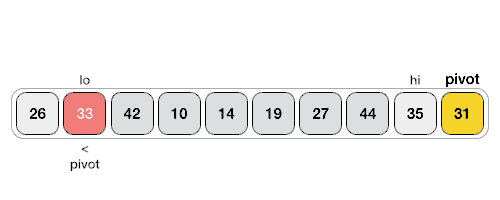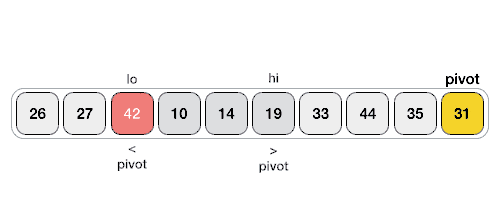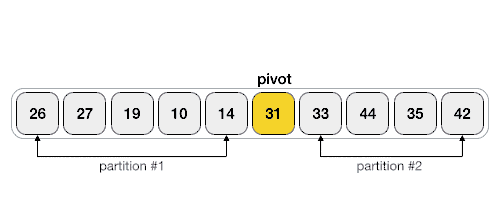
해당 과정을 이해해보자 !
퀵 정렬 과정
1. 가운데 값을 Pivot으로 정한 후 해당값과 비교한다.
2. 이때 lo와 hi가 있다.
lo : 탐색이 시작될 떄 항상 먼저 탐색한다. 이때 Pivot보다 큰 수를 찾는다면 중지
hi : lo의 탐색이 중지되면 탐색을 시작한다. 이때 Pivot보다 작은 수 를 찾는다면 중지
3. lo와 hi 모두 탐색이 중지 되었다면 서로 중지된 인덱스의 값을 교환한다. 값을 교환한 후에는
lo + 1 , hi - 1 을 해준다.
4. lo > hi 의 조건이 충족 되었을때 해당 인덱스들의 기준으로 배열을 분할 한 후 배열 한개 만 남을 때 까지 해당 탐색을 진행한다.
이를 코드로 구현하면 이와 같다.
def quicksort(arr, low, high):
# 재귀 종료 조건: 정렬할 구간의 길이가 0 또는 1이면 이미 정렬된 상태
if low >= high:
return
# 중앙값을 피벗으로 선택: 현재 부분 배열의 중간 인덱스의 값을 피벗으로 사용
pivot = arr[(low + high) // 2]
# pl은 왼쪽에서 시작, pr은 오른쪽에서 시작
pl = low
pr = high
# pl과 pr이 서로 교차할 때까지 반복하며 요소들을 피벗을 기준으로 분할
while pl <= pr:
# 왼쪽에서부터 시작해서 피벗보다 작은 원소들은 그대로 두기 위해,
# arr[pl]이 피벗보다 작으면 올바른 위치에 있으므로 pl을 오른쪽으로 이동
while arr[pl] < pivot:
pl += 1
# 오른쪽에서부터 시작해서 피벗보다 큰 원소들은 그대로 두기 위해,
# arr[pr]이 피벗보다 크면 올바른 위치에 있으므로 pr을 왼쪽으로 이동
while arr[pr] > pivot:
pr -= 1
# 만약 pl과 pr이 아직 교차하지 않았다면,
# 두 포인터가 가리키는 원소는 서로 잘못된 위치에 있으므로 교환
if pl <= pr:
arr[pl], arr[pr] = arr[pr], arr[pl]
# 교환한 후, pl은 오른쪽으로, pr은 왼쪽으로 이동시킴
pl += 1
pr -= 1
# 여기까지 오면 배열은 두 부분으로 분할됨:
# - low ~ pr: 피벗보다 작거나 같은 값들
# - pl ~ high: 피벗보다 큰 값들
# 재귀 호출: 왼쪽 부분과 오른쪽 부분에 대해 각각 정렬 수행
quicksort(arr, low, pr)
quicksort(arr, pl, high)
재귀 함수의 개념만 알았지 구현을 하지 않다보니...
퀵 정렬을 구현하다가 몇 시간을 날려버린 것 같다. 정렬들 중 재귀함수로 구현되는 정렬인 병합 정렬과 같이 시간복잡도가 적을 것이라 예상했지만, 직접 그려보며 구현 해보다 보니, 왜 최악의 경우가 있는지 알 것 같다.
이상으로 시간 복잡도가 이 걸리는 정렬 알고리즘들을 정리 해보았다.
