
집합 자료형은 해시 함수와 연관성이 있다.
먼저 해시 함수란 ?
해시 함수(hash function)
임의의 길이를 가진 데이터를 입력받아 고정된 길이의 값, 즉 해시값을 출력하는 함수입니다. 해시값은 입력 데이터로부터 유도되기 때문에 동일한 입력은 항상 동일한 해시값을 갖게 됩니다.
위 처럼 해시 함수를 이용하면 자료를 효율적이게 저장할 수 있다.
고정된 값 ?
해시 함수를 이용한 해싱에는 다양한 방식이 존재하는데 모듈러 연산을 통해 자료를 저장하는 방식으로 예를 들어 설명하겠다.
모듈러 연산을 통한 해싱
모듈러 연산
모듈로 연산은 컴퓨팅에서 한 숫자를 다른 숫자로 나눈 후 나눗셈의 나머지 또는 부호 있는 나머지를 반환한다.
예를 들어
이다.

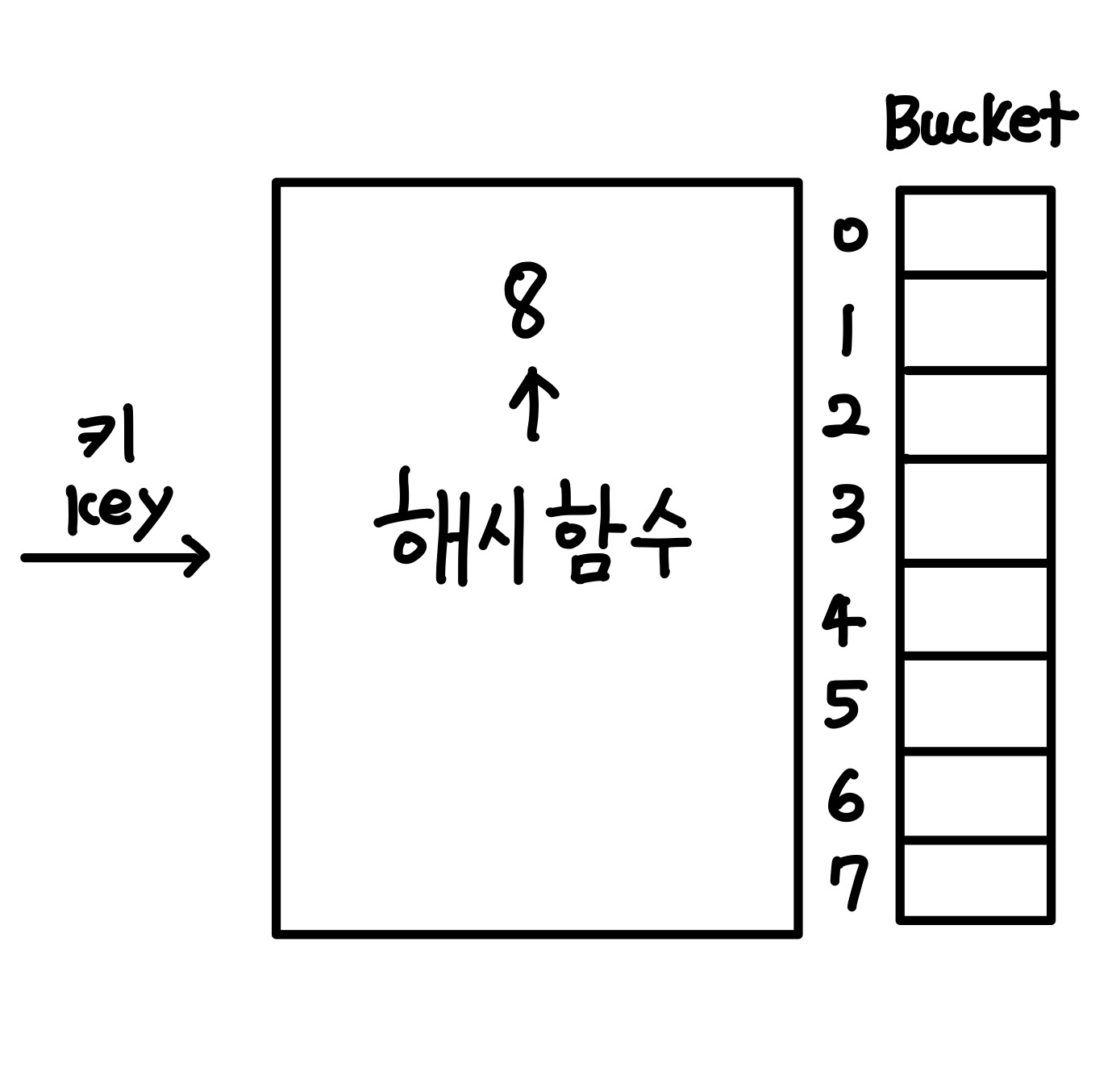
위 그림을 설명하면 key와 value값을 가진 요소가 들어오게 되기 전
해시 테이블의 크기(버킷 수)를 설정해야 한다. 해시 값을 8이라 한다면, 모듈러 연산을 통해 나올 수 있는 수는 0~7이다. 이로 인해서 인덱스는 0부터 7까지, 총 8개의 버킷이 생긴다.
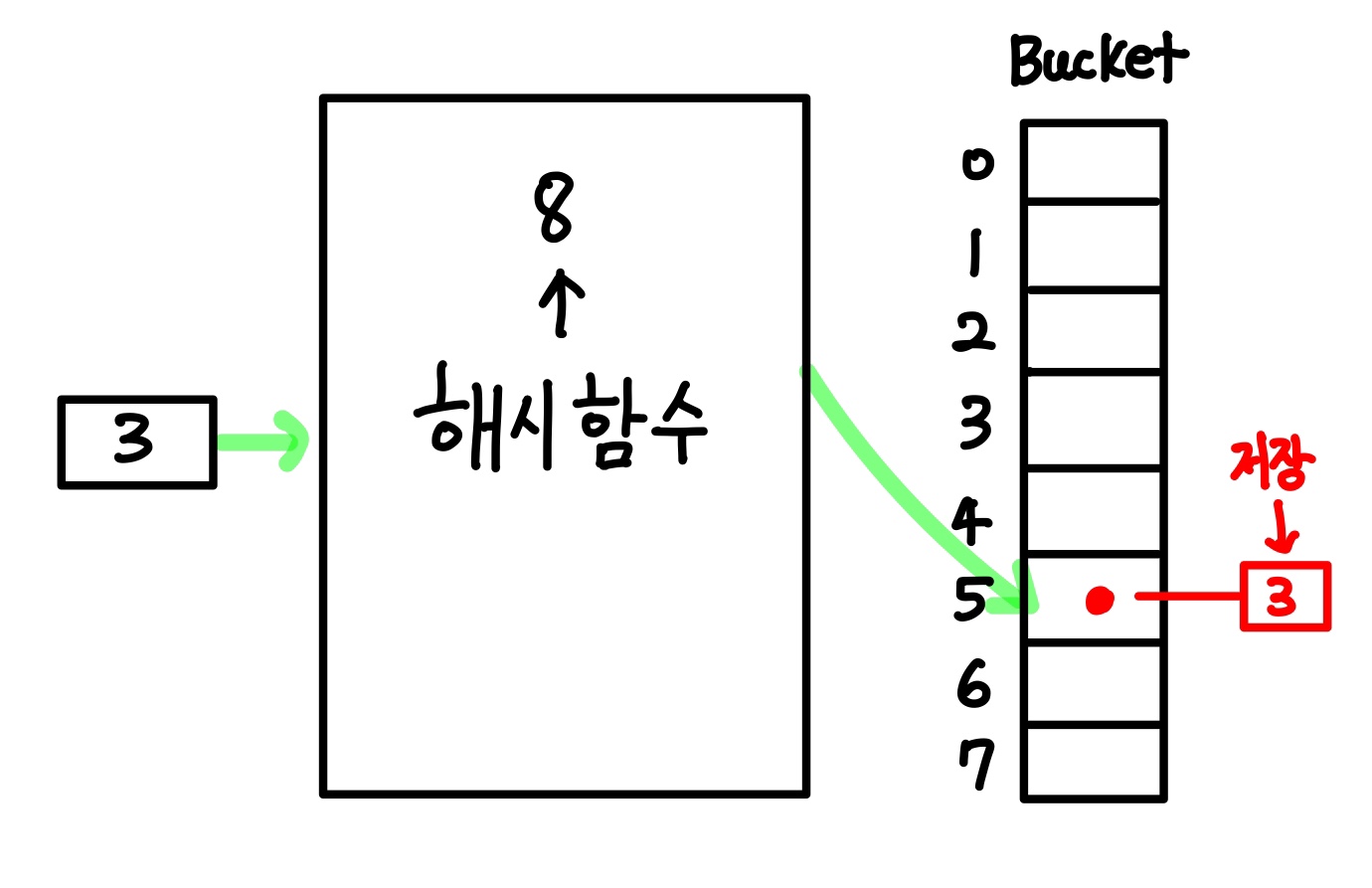
위 그림을 보면 숫자 3 이 키 값으로 들어왔다. 이로인해 해시 함수는 이므로. 버킷의 5번째 인덱스에 값을 저장하게 된다.
그럼 여기서 의문이 들 것이다. 숫자는 그렇지만 같은 키 값을 가진 걸 해싱하지 않으려면 해시값을 1억 정도로 해야 버킷에 안겹치지 않아?
해시 테이블 크기를 1억으로 해도, 겹치는 경우를 배제 할 수 없다. 해당 문제를 해결하기 위해 개방주소법과, 체이닝 기법을 사용한다.
개방주소법과 체이닝에 대해서는 나중에 더 자세히 설명하겠다.
해시와 집합의 연관성 ?
파이썬을 기준으로 설명하겠다. 파이썬으로 코딩을 하다보면 집합 자료형을 접해볼 수 있다.
a = {1,2,3,4,5,5,5}
출력 : {1,2,3,4}
a = [1,2,3,4,5,5,5]
a = set(a)
출력 : {1,2,3,4,5}위와 같이 중복을 허용하지 않는 자료형이다.
집합(set)은 내부적으로 순서를 유지하지 않으며, 인덱스를 기반으로 요소에 접근할 수 없다. 이는 집합이 정렬되지 않은 해시 기반 자료구조이기 때문이며, set[0] 같은 접근은 불가능하다.
왜 인덱스가 없어 ?
파이썬의 집합(set)은 딕셔너리(dict)와 비슷하게 내부적으로 해시 테이블을 사용한다.
하지만 딕셔너리는 key: value 쌍을 저장하는 반면, 집합은 오직 key만 저장하는 key-only 해시 테이블이다.
집합 자료형의 좋은 점 ?
중복을 허용하지 않아서 좋은 것은 알고 있을 것이다.
추가적으로 자료를 탐색 할 때의 시간복잡도가 이다.
일반적인 리스트 선형 검색
N = [1, 2, 3, 4, 5, 6, 7]
if 1 in N:
print("참")
출력 : 참위 처럼 리스트를 선형 검색하게 된다면, 검색에 대한 시간 복잡도는
최악의 경우 이다.
집합 자료형의 검색
N = [1, 2, 3, 4, 5, 6, 7]
N = set(N)
if 1 in N:
print("참")
출력 : 참해당 코드는 똑같지만, 집합 자료형은 내부적으로 해시 테이블을 사용하므로 평균적으로 검색 시간복잡도는 이다. (최악의 경우 해시 충돌이 많아지면 이 되지만, 일반적인 상황에서는 매우 빠르다.)
검색 시간복잡도가 평균적으로 낮은 자료형인 set에 대해 알아보았다.
