
드디어 tiny서버 구현이다...
해당 과제를 할 때 모두의 특색이 드러나는 사이트를 만들던데, 나는 "엄마 저는 커서 리바이 병장이 될래요 ! " 사이트를 만들려고 한다.
벌써부터 즐겁네 레츠고 !
main 함수
main 인자
int main(int argc, char **argv)서버를 시작할 때
port는 지정해 줘야하므로argv에 인자를 받아 서버를 연다 !
main 함수 구현
// 포트 인자로 Open_litenfd 함수 호출
// 해당 포트로 오는 요청을 받을 수 있는 listen 소켓을 생성한다.
listenfd = Open_listenfd(argv[1]);
while (1)
{
clientlen = sizeof(clientaddr);
//해당 소켓으로 오는 요청에 대해 connfd 소켓을 생성한다.
connfd = Accept(listenfd, (SA *)&clientaddr,
&clientlen); // line:netp:tiny:accept
// 로그 출력을 위해 Getnameinfo 함수로 구조체에 대한 hostname과 port를 받아옴.
Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE,
0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); // line:netp:tiny:doit
Close(connfd); // line:netp:tiny:close
}
Open_listenfd에 서버를 시작할 때 받은port인자를 넣어listenfd를 생성한다.
=> 해당 과정에서socket(),bind(),listen()이 실행된다.- 모든 포트에서 오는 요청을 받기위해
Accept()함수에서 blocking 된다.
=> 요청이 오면 해당 함수에서connfd를 생성하고,TCP 연결을 수립한다 !- 로그 출력을 위해
Getnameinfo함수에서hostname과port를 받아온 후 이제doit()함수를 실행하여, 서로의 트랜젝션을 주고받는다 !
=> 해당 함수가 종료되면connfd를 닫은 후 서버를 종료한다.
확실히 echo서버를 구현하고나서 본격적으로 구현하다보니 이해가 쉬워졌다 ! 이대로 프록시랩 까지 쭉쭉 달려보자...
Clienterror (에러 출력)
doit()함수에서는 많은 함수가 들어가있기 때문에 다른 부분 함수들을 먼저 설명하고 진행하려고한다.
void clienterror(int fd, char *cause, char *errnum,
char *shortmsg, char *longmsg)
{
char buf[MAXLINE], body[MAXBUF];
// 문자열 포멧팅을 사용하여 버퍼에 출력 결과를 저장 후
// rio_writen을 사용하여 사용자에게 전송
sprintf(body, "<html><title>Tiny Error</title>");
sprintf(body, "%s<body bgcolor=""ffffff"">\r\n", body);
sprintf(body, "%s%s: %s\r\n", body, errnum, shortmsg);
sprintf(body, "%s<p>%s: %s\r\n", body, longmsg, cause);
sprintf(body, "%s<hr><em>The Tiny Web server</em>\r\n", body);
sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-type: text/html\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-length: %d\r\n\r\n", (int)strlen(body));
Rio_writen(fd, buf, strlen(buf));
Rio_writen(fd, body, strlen(body));
}해당 함수는
sprintf함수를 이용해서,body 버퍼에 에러 코드들을 저장하고,buf 버퍼에는 해당HTTP헤더들을 담은 후에Rio_writen을 사용하여 버퍼에 있는 값들을 서버로 전송한다.
한번 쭉 둘러보면, echo 서버를 구현할 때 Rio함수에 대해서 공부하길 정말 잘했다는 생각이 든다...
read_requestthdrs
void read_requesthdrs(rio_t *rp)
{
char buf[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "\r\n")){ //줄이 빈줄 일때까지 계속해서 반복
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
}
return;해당 함수는
Rio_readlineb()함수를 사용하여, 커널 버퍼에 저장된 클라이언트의 요청을 버퍼에 저장한 후에 해당 요청들을 출력한다.
parse_uri (uri 파싱)
int parse_uri(char *uri, char *filename, char *cgiargs)
{
char *ptr;
if(!strstr(uri, "cgi-bin")) {
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
if(uri[strlen(uri)-1] == '/')
strcat(filename, "home.html");
return 1;
}
else{
ptr = index(uri, '?');
if (ptr) {
strcpy(cgiargs, ptr+1);
*ptr = '\0';
}
else
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
return 0;
}
}해당 함수가
HTTP 프로토콜의 핵심인 것 같다고 생각했다.
각각의uri를 파싱하는 역할을 하는데, 문자에서cgi-bin이 없다면,HTTP METHOD,file_path로 나눠준다.
만약 동적 요청이 왔다면,?문자열을 기준으로 해당file_path와uri를 가져온다.
문자열 응용 함수들이 생각보다 많이 빡쎘다...
serve_static (정적 요청 처리)
void serve_static(int fd, char *filename, int filesize, int is_head)
{
int srcfd;
char *srcp, filetype[MAXLINE], buf[MAXBUF];
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.0 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length : %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
Rio_writen(fd, buf, strlen(buf));
printf("Response headers:\n");
printf("%s", buf);
if (!is_head){
srcfd = Open(filename, O_RDONLY, 0);
// * mmap 을 사용하여 파일 메모리를 매핑하는 방식
// * 속도 면에서 커널의 파일을 읽어오는 건 이게 더 빠름
srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
Close(srcfd);
Rio_writen(fd, srcp, filesize);
Munmap(srcp, filesize);
// *말록을 통한 파일에 동적메모리를 할당하는 방식
// char *buf_m = malloc(filesize);
// Rio_readn(srcfd, buf_m, filesize);
// Close(srcfd);
// Rio_writen(fd, buf_m, filesize);
// Free(buf_m);
}
}정적 요청이 왔다면,
버퍼에hearder값들을 넣어준 뒤에, 서버로 보내준다. 만약 해당 요청이GET요청이라면, 해당하는 파일을 버퍼에 담아 서버로 전송한다 !
이 부분에서 말록으로 진행하는 과제가 있었는데, 실제로 할당하는 속도는 메모리 매핑을 사용하는 방식이 더 빠르고 한다.
serve_dynamic (동적 요청 처리)
oid serve_dynamic(int fd, char *filename, char *cgiargs, int is_head)
{
char buf[MAXLINE], *emptylist[] = { NULL };
sprintf(buf, "HTTP/1.0 200 OK\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Server: Tiny Web Server\r\n");
Rio_writen(fd, buf, strlen(buf));
if (!is_head){
if(Fork() == 0) {
setenv("QUERY_STRING", cgiargs, 1);
Dup2(fd, STDOUT_FILENO);
Execve(filename, emptylist, environ);
}
Wait(NULL);
}
}말 그대로 동적 요청을 처리하는데, 여기서
Fork()가 나온다.
해당 동적요청 파일은 다른 패키지에 있기 때문에 프로세스에서는 접근이 불가능 하다 !
따라서 해당 파일에 대해 접근을 하기위해자식 프로세스를 생성하고, 동적 파일에 접근하여 해당 파일을 실행시킨다.
이때부모 프로세스는자식 프로세스가 모든 일을 마칠 때 까지 기다렸다가, 다 수행하면 해당 프로세스를 죽인다 ! ( 너무 잔인해)
이런 형식으로 동적 요청이 처리된다.
DOIT 함수 (이게 진짜 메인)
void doit(int fd)
{
int is_static;
int is_head = 0;
struct stat sbuf;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE];
rio_t rio;
//connfd 파일 디스크립터 즉, 연결이 되었다면, 연결된 소켓을
// rio함수를 사용하여 buf에 읽어온다.
Rio_readinitb(&rio, fd);
Rio_readlineb(&rio, buf, MAXLINE);
printf("Request headers : \n");
printf("%s", buf);
// 버퍼의 저장된 값을 각각 나눠서 저장해준다.
// GET /godzilla.gif HTTP/1.1 이렇게 오면
// GET | /godzilla.gif | HTTP/1.1 이런식으로 공백을 기준으로 끊어줌.
sscanf(buf, "%s %s %s", method, uri, version);
if (strcasecmp(method, "GET") && strcasecmp(method, "HEAD")) { // 대소문자 상관없이 문자열 비교하는 함수. (같으면 0반환)
clienterror(fd, method, "501", "Not implemented", // GET요청이 아니라면 501에러 핸들링
"Tiny does not implement this method");
return;
}
if (strcasecmp(method, "HEAD") == 0){
is_head = 1;
}
read_requesthdrs(&rio); // 해당 리퀘스트에 대한 내용을 출력한다.
//여기서 나온 값들은 대부분 브라우저가 나에게 보낸 값들
// 해당 로그 조회시 나의 크롬브라우저는 http 1.1 사용중.
// 나는 1.0으로 respose
is_static = parse_uri(uri, filename, cgiargs); // uri 분리
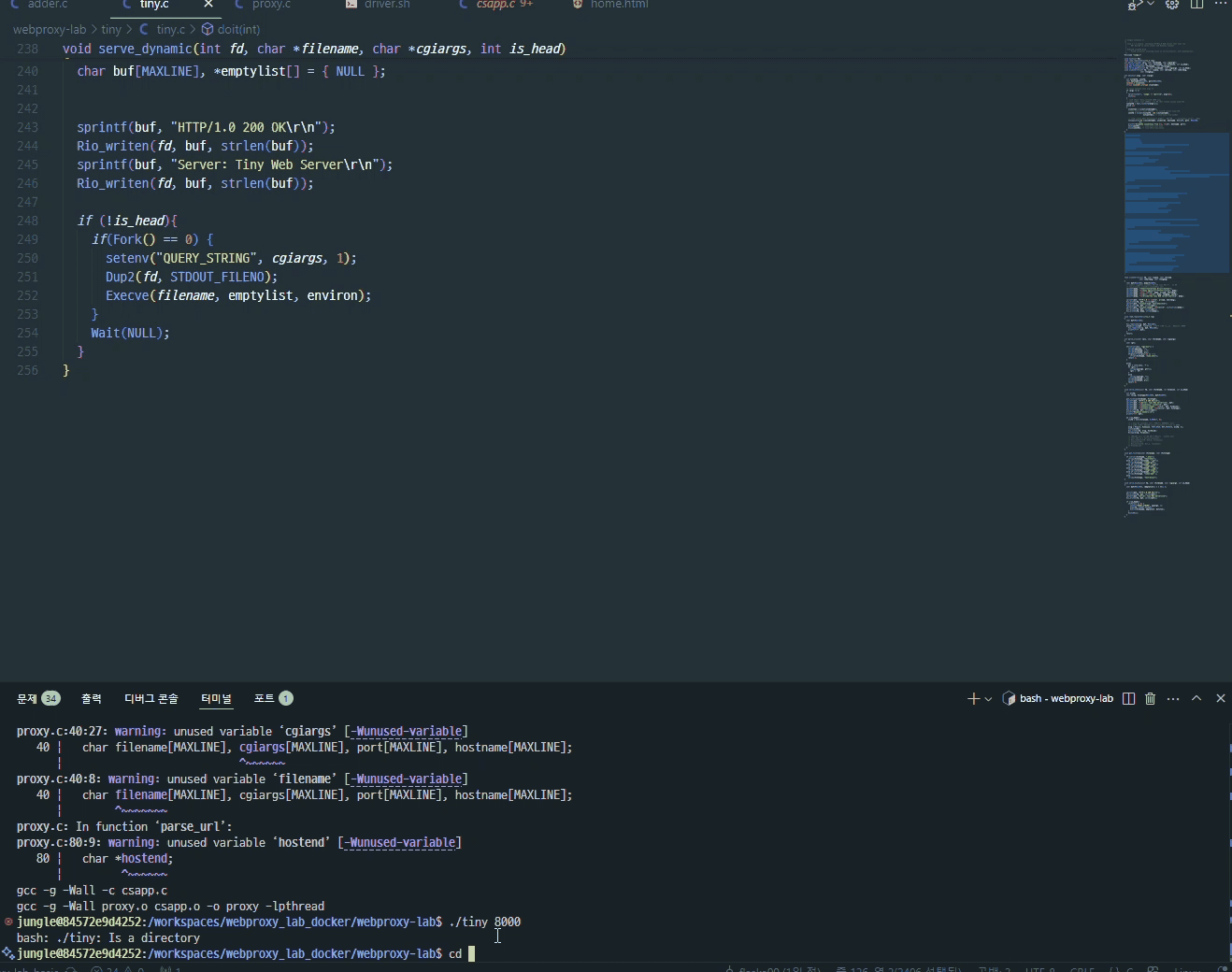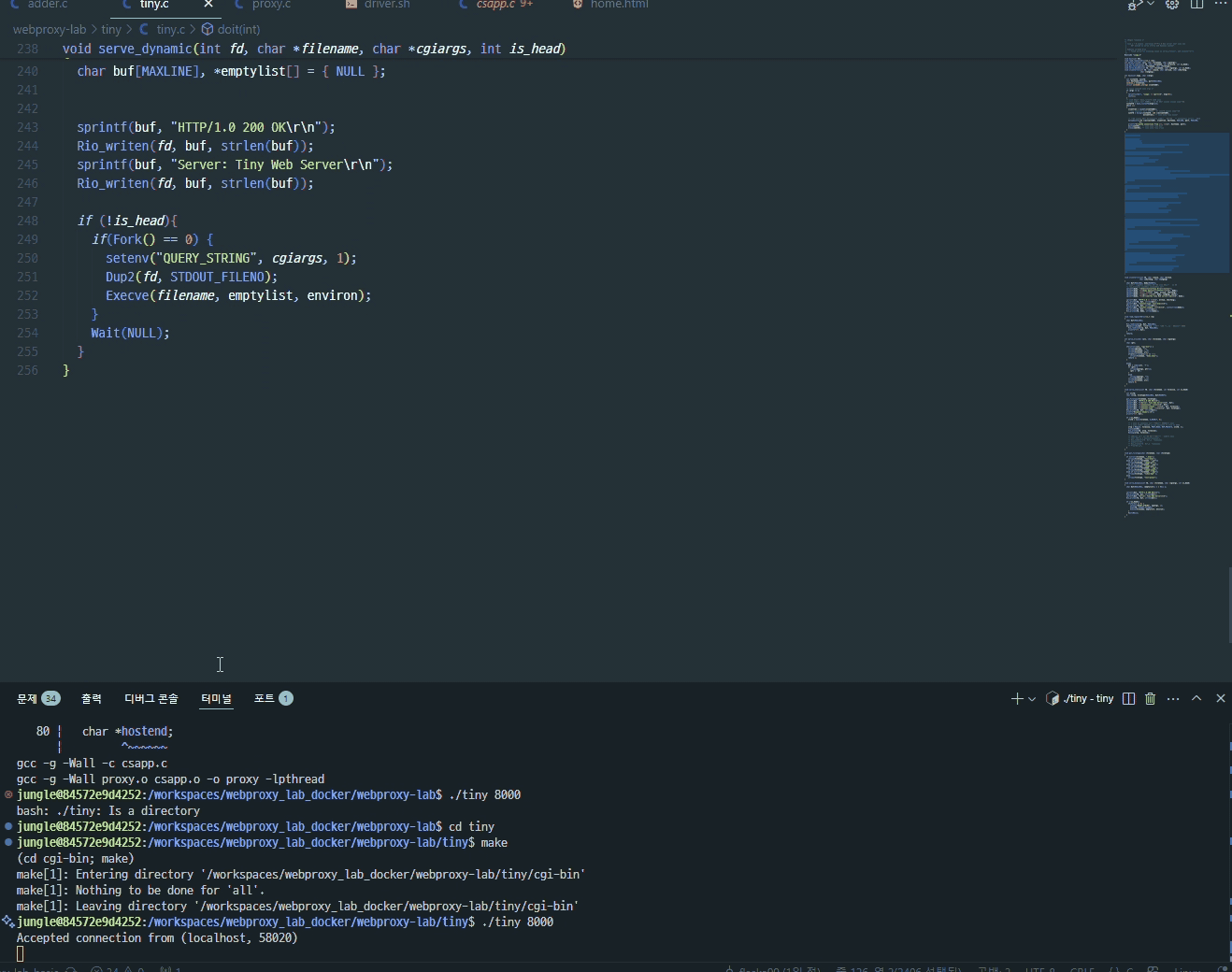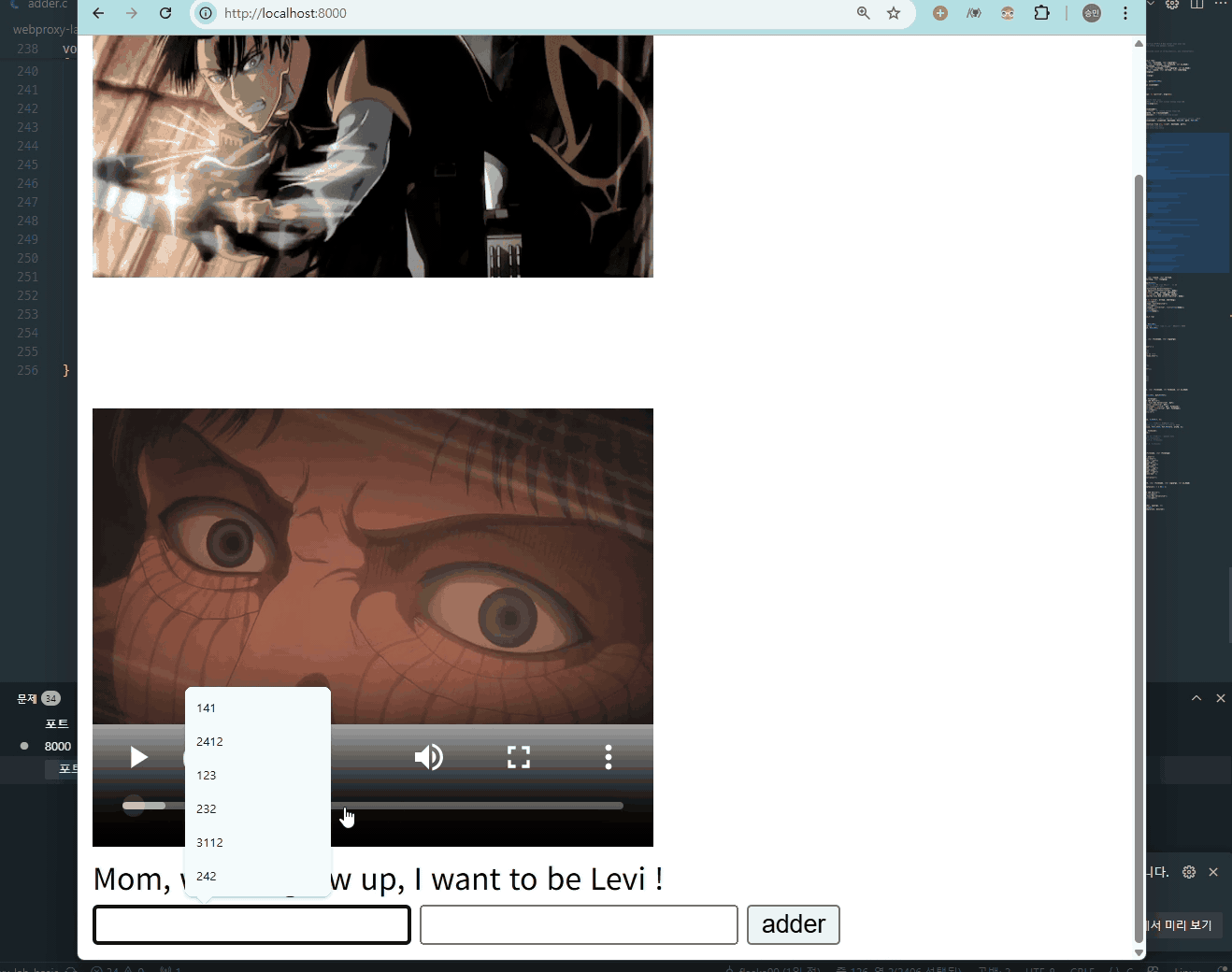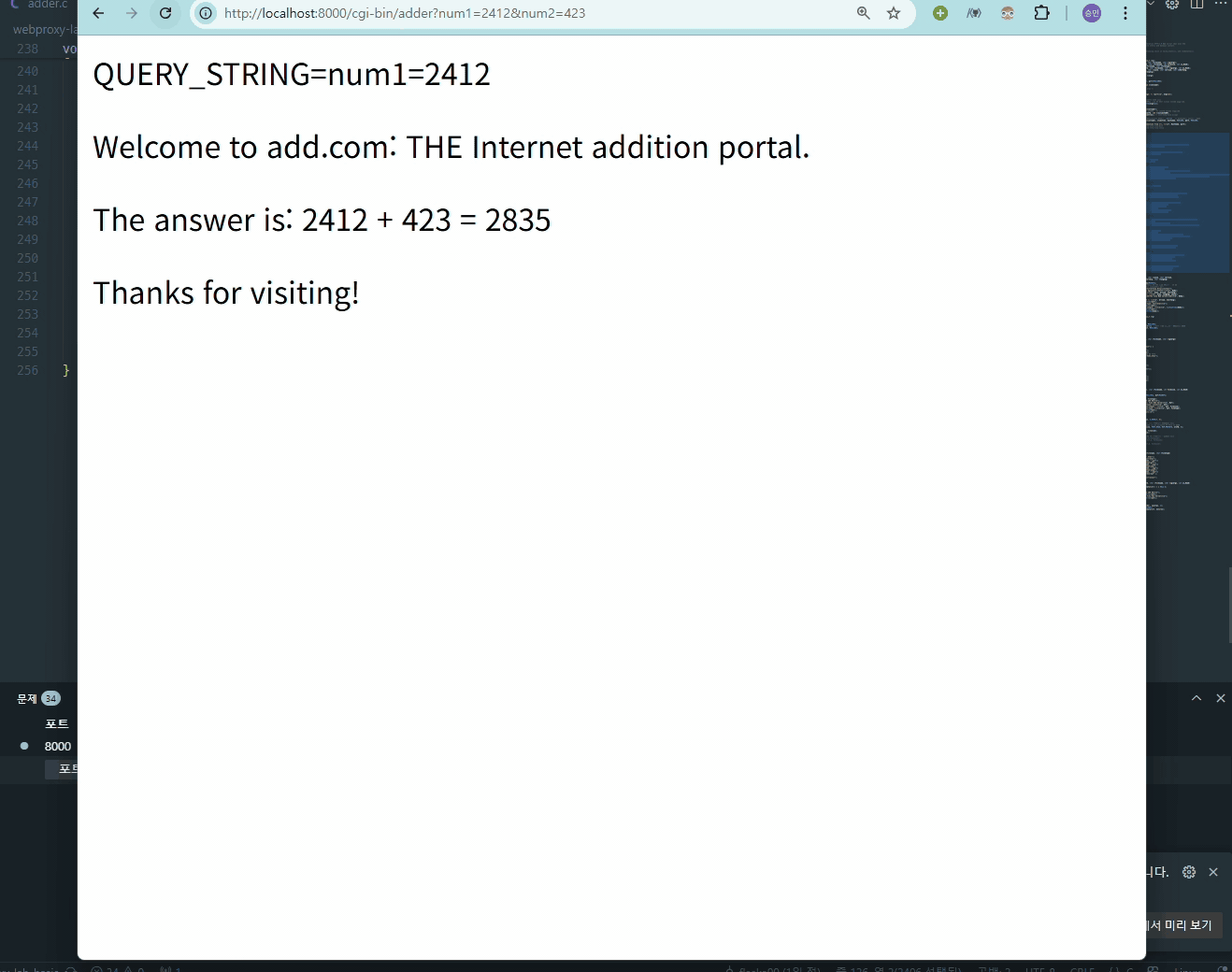
// GET /cgi-bin/adder?num1=3&num2=5 HTTP/1.1
// -> uri = "/cgi-bin/adder?num1=3&num2=5"
// → filename = "./cgi-bin/adder"
// → cgiargs = "num1=3&num2=5"이런식으로 처리됨.
// 정적콘텐츠면 1 반환, 동적 콘텐츠면 0 반환.
if (stat(filename, &sbuf) < 0) { // 해당 파일이 존재하는지 확인하는 시스템콜
// 성공 시 1 , 실패 시 0 반환
clienterror(fd, filename, "404", "Not found",
"Tiny couldn't find this file"); // 파일이 없다면 404에러 헨들링
return;
}
if(is_static) { // 정적 콘텐츠이면
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode)){
// 일반파일인지 확인, 파일의 소유자가 읽기 권한을 가졌는지 확인
clienterror(fd, filename, "403", "Forbidden",
"Tiny couldn't read the file");
return;
}
// .html, .jpg, .csss 같은 파일을 클라이언트에게 전송
serve_static(fd, filename, sbuf.st_size, is_head);
}
else {// 동적 콘텐츠라면
if (!(S_ISREG(sbuf.st_mode)) || !(S_IXUSR & sbuf.st_mode)) {
// 일기 파일인지 확인, 실행권한을 가졌는지 확인
clienterror(fd, filename, "403", "Forbidden",
"Tiny couldn't run the CGI program");
return;
}
// 동적 콘텐츠를 생성 후 그 출력을 클라이언트에게 전송
//fork() + execve() + dup2() + wait() 등을 활용
serve_dynamic(fd, filename, cgiargs, is_head);
}
}
- 요청 라인 읽기 (GET /index.html HTTP/1.1)
=>HTTP 요청을 버퍼에 읽어온다.- 메소드 파악 (GET인지 HEAD인지)
=> 다른 메서드라면501 error리턴- 헤더 출력
=> HTTP 헤더를 한 줄씩 읽고 무시하거나 로그 출력한다.- URI → 파일명/인자 분리(위에 설명한 파싱 함수가 진행)
- 파일 존재 여부 확인
=>stat()시스템 콜을 사용하여 확인- 정적 콘텐츠 vs 동적 콘텐츠 판단
=> 각각의 맞는 함수로 동작을 반환한다.
해당 함수는 위에 구현했던 함수의 집합체이다...
그러니까 HTTP 요청들을 잘 파싱해서, 에러를 출력하거나 그에 맞는 요청을 해주는 역할이다 !
구현하다보니 맨날 웹에서 무슨 동작이 일어나는지 모르면서 구현했던 거 같다...
뭔가 우주의 비밀을 알아버린 기분...
결과
일단 구현햇으니까 맛 좀 봐야겠다.
내가 만든 엄마 저 리바이 병장이 될래요 ! 사이트이다.
html을 만들 때 utf-8로 한글로 출력하니 동적 요청을 진행할 때 쿼리스트링이 깨져서 결국 영어로 쓰기로 타협을 보았다...
이걸로 tiny_web서버의 과제도 클리어 했다 !
c 언어로 구현해 본 아주 귀한 경험이였다 !!!
이제 proxy_lab 드가보자....

죽지 마라. 살아남아라.