
Pintos 주차에 들어왔다..
project_1에서 모든 테스트를 클리어하고, project_2부터 기록을 남기려고 한다.
project 1에 대한 기록
user_program을 구현하기 전, 우선순위 스케줄링에 대해 구현을 진행하였는데
해당 부분은 운영체제의 busy_waiting을 줄이기 위해 쓰레드 들을 어떤식으로 관리해야하는지 구현하였었다.
tick단위로 스케줄링을 구현하고, 우선순위대로 큐에서 쓰레드들을 관리하도록 구현했다.
이 부분에서 중요했었던 건, 우선 순위로 cpu를 선점하는 방식과 공유 자원에 대한 관리였다.
project 2 시작
project_2를 시작 하며, 먼저 Git_Book에 써져있는 소개글 부터 읽어 보았다...
항상 핀토스 프로젝트를 시작할 때 문제를 알겠지만, 무엇을 건들여야 할지 도무지 감이 안잡힌다.
때문에 GDB를 사용하여, 메인에 BREAK_POINT를 걸어두고, pintos의 방대한 코드들이 어떤식으로 돌아가는 지 탐험 해보았다.
탐험을 하며, 알게 된 내용들을 Notion에 기록하며, 천천히 감을 잡아가는데 총 3일이 걸렸다...
이제 내가 무엇을 해야하는지 깨닳아서 신나는 마음에 첫번째 과제인 Argument Passing을 진행하였다.
Argument Passing (1)
먼저 해당 과정을 진행하려면 process_exec() 함수에서 유저 프로그램으로 인자를 어떤 식으로 넘기는 지 확인해야한다.
GDB로 이곳의 흐름을 보고싶어도 이 곳을 도저히 지나가질 않아서 천천히 다시 탐험하다 보니
process_wait()
int
process_wait (tid_t child_tid UNUSED) {
/* XXX: (Hint) The pintos exit if process_wait (initd), we recommend you
* XXX: to add infinite loop here before
* XXX: implementing the process_wait. */
return -1;
}이 부분이 문제엿다.
흐름은 이렇다.
-
process_exec()함수는 부모 프로세스가 새로운 자식 프로세스를 생성할 때 호출된다. -
이후 자식 프로세스는
start_process()->process_exec()->load()등의 흐름을 따라야 하는데 -
이 자식 프로세스를 부모 프로세스가 기다리지 못하고 바로
return -1을 호출하여, 자식 프로세스는 흐름을 이어갈 수 없었다.
따라서 해당 부분에 hint 대로 무한 루프를 만들어서 일단 자식 프로세스가 유저의 인자를 구성해주는 것 부터 구현을 진행해 볼 수 있었다.
process_wait() 수정 완료
int
process_wait (tid_t child_tid UNUSED) {
/* XXX: (Hint) The pintos exit if process_wait (initd), we recommend you
* XXX: to add infinite loop here before
* XXX: implementing the process_wait. */
while(1)
{
}
return -1;
}Argument Passing (2)
위 부분을 구현하니, 드디어 project_exec() 를 들어갈 수 있었다...
저 부분을 찾는데 3일 걸린게 너무 하지만, 오래걸리더라도 이런 식으로 찾은 거 또한 경험이 되어서 다음엔 더 빠르게 진행할 수 있지 않을까 생각한다.
process_exec() 에서 해줘야할 건 유저가 사용한 명령어를 공백에 따라서 나누어 준다. 이걸 유저 프로그램을 메모리에 로드 한 시점에 유저 스택에 push 하여 인자를 넘기는 것이 목표이다.
1. 명령어 파싱
char *file_name 에는 "args-single onearg" 같이 공백으로 구분된 전체 문자열이 들어온다.
이걸 strtok_r() 등을 이용해서 나눠서 argv 배열로 만들어주었다.
//인자 파싱하기
char *token, *save_ptr;
char *argv[MAX_ARGS];
int argc = 0;
// 인자 파싱
for (token = strtok_r (f_name, " ", &save_ptr); token != NULL;
token = strtok_r (NULL, " ", &save_ptr))
argv[argc++] = token;
char *file_name = argv[0];해당 함수를 사용할 때 권장사항이 마침 주석에 적혀있어서 권장 사항대로 문자열을 나눠 주었다.
그리고 해당 문자열이 잘 나누어 지는지, GDB의 print를 통하여 확인하였다.
2. load() 호출
load()를 통해 새로운 사용자 프로그램을 메모리에 로드하고,
이 시점에 setup_stack() 함수로 유저 스택(rsp)이 초기화 된다. 그래서 유저 스택에 위에 나눠준 인자들을 적재해주면 된다.
해당 인자들을 적재하는 것은 push_by_stack() 함수를 만들어서 진행하였다.
3. 유저 스택에 인자 적재
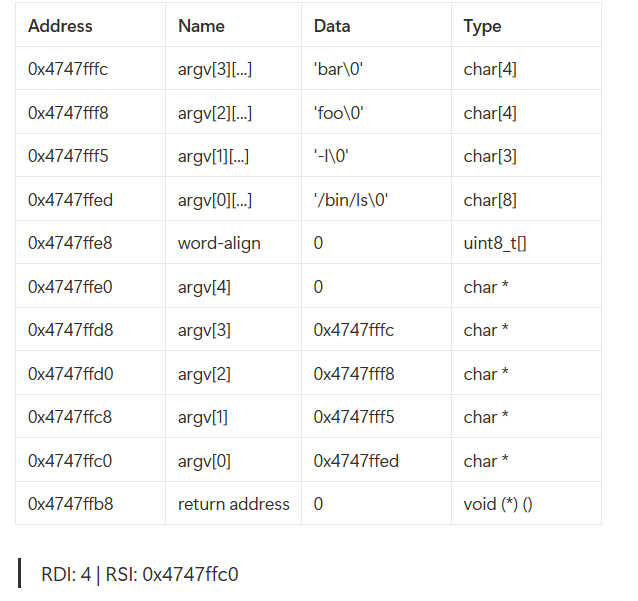
git_book 에 있는 자료를 참고하여 구현을 진행하였다.
- 각 argv[i] 문자열들을 스택에 복사(push)
(스택은 주소가 감소하므로, 문자열들을 역순으로 push)- 문자열들의 주소를 저장해놓고, 다시 char* argv[] 형태로 push
- 마지막에 argv와 argc를 레지스터(rdi, rsi)에 넘김
- 정렬을 위해 8바이트 기준으로 스택 align (padding)도 필요
위 방식 그대로 코드를 구현하였고,
hex_dump() 함수를 통해 인자가 정상적으로 들어가는지 확인하였다.
구현 코드
static void
push_by_stack(struct intr_frame *if_, char *argv[], int argc) {
char *arg_addr[argc];
// 문자열을 스택에 역순으로 push, 주소 기록
for (int i = argc - 1; i >= 0 ; i--) {
size_t len = strlen(argv[i]) + 1;
if_->rsp -= len;
memcpy((void *)if_->rsp, argv[i], len);
arg_addr[i] = (char *)if_->rsp;
}
// align to 8-byte
if_->rsp -= (uintptr_t)if_->rsp % 8;
// argv[i] 포인터 push (역순)
if_->rsp -= 8; // NULL sentinel
memset((void *)if_->rsp, 0, 8);
for (int i = argc - 1; i >= 0; i--) {
if_->rsp -= 8;
memcpy((void *)if_->rsp, &arg_addr[i], 8);
}
// argv의 주소 전달
if_->R.rsi = (uint64_t)if_->rsp;
// argc 전달
if_->R.rdi = argc;
// hex_dump
hex_dump(if_->rsp, (void *)if_->rsp, USER_STACK - if_->rsp, true);
}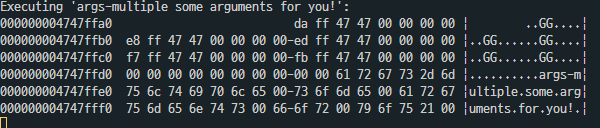
이렇게 스택에 적재가 성공적으로 된 것을 확인하였다.
4. intr_frame 설정 및 do_iret()
intr_frame.rip은 entry_point로,
rsp는 위에서 설정한 유저 스택의 주소로 지정되고,
do_iret()을 호출하여 유저모드로 한다!
따라서 이제
do_iret() 함수로 유저모드로 점프하고 나서 해야할 것들을 구현해야할 차례이다.
이 이후에는 시스템 콜을 건들여야하는데 벌써 설렌다...
이번엔 얼마나 걸릴라나....
일단 이번 포스팅은 여기까지...
