
네... 구현 완료 했습니다...
힌트를 많이 얻긴 했지만, 이해한 내용을 위주로 작성을 해보려구요.
일단 병렬성 부터 레츠고...
병렬성 처리
병렬을 처리하는 과정이 어려울 줄 알았지만, 마침 CS:APP에서 pthread의 래퍼함수를 제공해주셔서 비교적 코딩은 쉽게 진행할 수 있었다 !
먼저 쓰레드가 뭔지 알아보자 !
쓰레드란 ?
운영체제가 기존 프로세스 안에서 새로운 실행의 흐름을 시작시켜주는 것이다.
만약 웹서버에서 수천 명의 사용자가 동시에 접속할 때, 매번fork()로 프로세스를 만들면 시스템이 감당하지 못한다.
대신 하나의 프로세스 안에서 쓰레드를 수천개를 만들어 동시에 처리하면 훨씬 빠르고 메모리도 절약된다 !
예를 들면, 나의 복제 인간을 만드는 것은fork()이고, 내 인격이 둘 로 쪼개져서 나라는 본체 안에서 두개의 인격이 살아가는 것이다.
23 아이덴티티 영화를 보면 인격 여러 사람이 한 사람안에서 각각 독립적으로 살아간다.
쓰레드도 같은 느낌이다.
fork()는 프로세스를 하나 더 생성하는 것 이지만, 쓰레드는 프로세스 안에서 나눠주면 되기 때문에 비교적 더 빠르고 가볍다 ! 그래서 쓰레드를 쓴다.
정말 헷갈렸었던게 하드웨어의 쓰레드 와 프로세스의 쓰레드는 다른 거니까, 이해도 다르게 해야하는거 아니야...? 라고 생각했는데,
둘 다 다른건 맞다.
그래서 하나의 프로세스 안에서 실행되는 거니까.
병렬성이 아닌 동시성이 아니야 ? 라고 생각했다.
하지만 프로세스의 쓰레드도 결국 하드웨어 쓰레드 위에서 실행되기 때문에,
멀티코어 환경에서는 진짜 병렬적으로 실행 될 수 있다 !
그리고 이 프로세스의 쓰레드를 C언어에서 사용할 수 있도록 만든 것이
pthread 함수이다 !
병렬 처리 함수
void thread_func(void *vargp)
{
int connfd = *((int *)vargp);
Pthread_detach(pthread_self());
free(vargp);
doit(connfd);
Close(connfd);
return NULL;
}pthread 함수도
fork()함수와 비슷하게 쓰레드가 끝나면 정리 해주어야 한다.
c언어의pthread는 커널 쓰레드로 등록된다.
따라서 종료되어도 커널이 이 쓰레드의 리소스를 즉시 해제하지않는다.
여기서 즉시 해제를 하지 않는 다는 말은
시간이 지나면 치우는게 아니고, 삭제를 해줄 때 까지 기다리고 있다는 것이다. (무기한 점유)
그래서fork처럼 좀비가 되진 않지만, 리소스 누수를 방지하기 위해 내가 치워줘야한다 !
그래서 내가 명시적으로 끝날때 까지 기다리는pthread_join()함수와
커널에게 끝다면 알아서 치워달라고 책임을 위임하는pthread_detach()함수가 있다.
명시적으로 기다리게 된다면, 내가 구현 할 병렬 처리가 의미가 없어진다.
따라서, 나는 pthread_detach() 함수로 커널에게 부탁햇다 !
메인 함수
int main(int argc, char *argv[])
{
int listenfd;
int *connfdp;
char hostname[MAXLINE], port[MAXLINE];
pthread_t tid; //thread_id
socklen_t clientlen;
struct sockaddr_storage clientaddr;
init_cache(&cache);
listenfd = open_listenfd(argv[1]);
while(1) {
clientlen = sizeof(clientaddr);
connfdp = Malloc(sizeof(int));
*connfdp = Accept(listenfd, (SA *)&clientaddr, &clientlen);
pthread_create(&tid, NULL, thread_func, connfdp);
}
}연결이 된 소켓 파일들은 독립적으로 사용해야하니 식별자를 malloc을 통해 동적 할당을 하고,
독립적으로 병렬처리를 하기위해 pthread_create 함수로 쓰레드를 생성해준다.
해당 파일은 위에 쓰레드 함수에서 복사를 끝내면 메모리를 해제 해준다 !
cache
프록시 서버 안에 캐시를 두어서, 해당 많이 사용하는 요청이 온다면 서버로 가지않고 캐시에 저장해 놨던 응답을 리턴해 주는 것이다.
완전 똑똑한 생각인거 같다.
나도 뭔가 왔다갔다하는 비용이 많이 들면 캐시를 쓰자 ! 라고 생각하는 버릇을 가져야 겠다.
해당 부분은 많이 참고한 부분이여서, 제대로 이해한 부분만 포스팅에 담으려고 한다.
먼저 구조체부터 레츠고...
캐시 구현 구조체
typedef struct {
char uri[MAXLINE];
char object[MAX_OBJECT_SIZE];
int size;
int LRU; // LRU 처리를 위한 필드
int is_used;
pthread_mutex_t lock; // 읽기용
} cache_block;
typedef struct {
cache_block blocks[CACHE_CNT];
pthread_mutex_t global_lock; // 쓰기 삽입 용
} Cache;
Cache cache;요청을 담을
uri와response를 담을object를 정의했다.
캐시에서 일반적으로 쓰이는LRU를 통해 캐시 관리를 해주었으며,
사용을 안할 때 마다 +1 씩 카운트 해주는 방식으로 구성했다.
is_used는 배열로 구성하였기 때문에,
실제로 캐시에 값이 할당 되어있는지 알려주는flag이다.
그리고pthread의mutexx를 사용하여, 캐시 자원에 접근 할 때 충돌이 나지 않도록 하였다.
네... mutex를 사용하였습니다...
해당 방식에 대해서는 화장실 비유가 제일 찰떡인거 같습니다.
mutex ?
- 변기가 떡하니 있으면 아마 화장실이 마려운 사람은 서로 싸우다 변기가 부서질 것이다.
- 따라서 화장실에 잠금 장치를 만들어서 화장실을 사용하는 사람은 문을 잠구도록 한다.
- 그러면 이제 화장실은 굉장히 질서있게 사용된다 !
번외로 세마포어는 여기서 화장실의 갯수가 많아지는 것이다 !
네... 그래서 설명 이어서 하면,
global_lock과 lock을 만들어서,
읽는 중이라면, 해당 배열의 인자를 잠구도록 하고,
쓰는 중이라면, 모든 배열에 대해서 접근을 못하도록 잠궈둔다.
위 방식으로 구현하면, 캐시 자원에 접근 중이거나 수정 중 일때
막 바뀌고 없어지고 최신화되는 불상사가 없다 !
구현 코드
void init_cache(Cache *cache) {
pthread_mutex_init(&cache->global_lock, NULL);
for (int i = 0; i < CACHE_CNT; i++) {
cache->blocks[i].is_used = 0;
cache->blocks[i].LRU = 0;
pthread_mutex_init(&cache->blocks[i].lock, NULL);
}
}
int cache_read(Cache *cache, char *uri, char *buf) {
for (int i = 0; i < CACHE_CNT; i++) {
pthread_mutex_lock(&cache->blocks[i].lock);
if (cache->blocks[i].is_used) {
cache->blocks[i].LRU++; // 사용 안 하면 LRU 증가
if (strcmp(uri, cache->blocks[i].uri) == 0) {
memcpy(buf, cache->blocks[i].object, cache->blocks[i].size);
cache->blocks[i].LRU = 0; // 최근 사용됨
pthread_mutex_unlock(&cache->blocks[i].lock);
return cache->blocks[i].size;
}
}
pthread_mutex_unlock(&cache->blocks[i].lock);
}
return -1;
}
int choose_LRU_block(Cache *cache) {
int max_LRU = -1;
int victim = -1;
for (int i = 0; i < CACHE_CNT; i++) {
if (!cache->blocks[i].is_used) return i;
if (cache->blocks[i].LRU > max_LRU) {
max_LRU = cache->blocks[i].LRU;
victim = i;
}
}
return victim;
}
void cache_write(Cache *cache, char *uri, char *buf, int size) {
if (size > MAX_OBJECT_SIZE) return;
pthread_mutex_lock(&cache->global_lock);
int victim = choose_LRU_block(cache);
pthread_mutex_lock(&cache->blocks[victim].lock);
strncpy(cache->blocks[victim].uri, uri, MAXLINE);
memcpy(cache->blocks[victim].object, buf, size);
cache->blocks[victim].size = size;
cache->blocks[victim].is_used = 1;
cache->blocks[victim].LRU = 0;
pthread_mutex_unlock(&cache->blocks[victim].lock);
pthread_mutex_unlock(&cache->global_lock);
}위에서 말한 이론대로 여기저기 물어보고 참고하여... 어찌저찌 구현에는 성공하였다 !
doit 함수 구현
void doit(int clientfd)
{
int proxyfd;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE], port[MAXLINE], hostname[MAXLINE];
char path[MAXLINE], header_buf[MAX_OBJECT_SIZE];
rio_t rio_server, rio_client;
Rio_readinitb(&rio_client, clientfd);
Rio_readlineb(&rio_client, buf, MAX_OBJECT_SIZE);
sscanf(buf, "%s %s %s", method, uri, version);
parse_url(uri, hostname, path, port);
// 캐시 확인
int cached_size = cache_read(&cache, uri, buf);
if (cached_size != -1) {
Rio_writen(clientfd, buf, cached_size);
return;
}
// 캐시 미스 -> 서버에 요청
proxyfd = Open_clientfd(hostname, port);
Rio_readinitb(&rio_server, proxyfd);
make_header(header_buf, hostname, path, user_agent_hdr);
Rio_writen(proxyfd, header_buf, strlen(header_buf));
// 응답 내용을 버퍼에 저장하며 클라이언트에 전송
int n, total_size = 0;
char cache_buf[MAX_OBJECT_SIZE];
while ((n = Rio_readlineb(&rio_server, buf, MAXLINE)) > 0) {
if (total_size + n <= MAX_OBJECT_SIZE) {
memcpy(cache_buf + total_size, buf, n);
}
total_size += n;
Rio_writen(clientfd, buf, n);
}
// 응답 전체가 MAX_OBJECT_SIZE보다 작을 때만 캐시에 저장
if (total_size <= MAX_OBJECT_SIZE) {
cache_write(&cache, uri, cache_buf, total_size);
}
Close(proxyfd);
}doit함수 또한 캐시를 저장해야하기 때문에 수정해주었다.
OBJECT_SIZE와 CACHE_SIZE가 문제에 명시되어 있었기 때문에,
버퍼를 만들어 접근하기 쉬웠다 !
그럼 이제 카네기 멜론 교수님에게 채점을 맞겨볼 시간이다...
결과
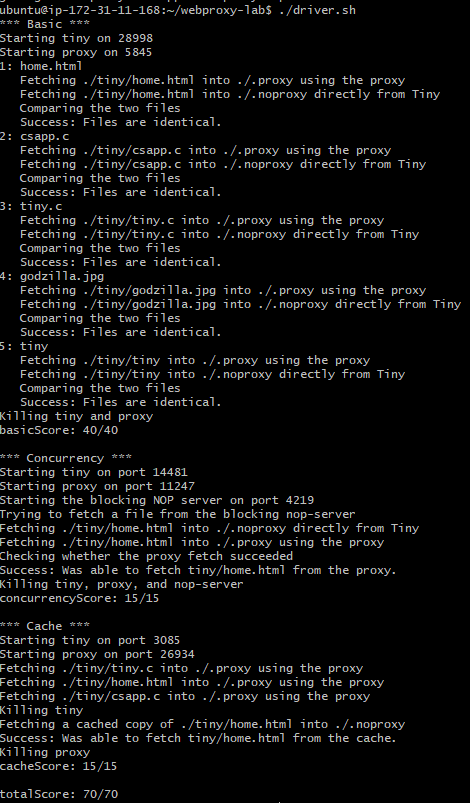
아니 다 만점이라니요...?!???
카네기 멜론 교수님이 다음주 PINTOS 주차 힘드니까 기운내라고 점수를 후하게 주셨다...
그리고 캐시 부분은 mutex를 사용한 꼼수(?)로 만점을 받은 거 같다...
사실 proxy_lab에서는 mutex사용이 금지되어있는데,
내 추측으로는 이렇다.
mutex를 사용하면, CSAPP함수에 구현되어있는lock함수에 대해 사용을 못해봐서, 교육 목적에서 권장을 안함.
- 클라이언트의 요청을 병렬적으로 처리하도록 만들었는데, 결국 캐시에 접근을 거의 무조건 해야함.
이때 뮤텍스로 캐시락을 구현할 경우 병렬적으로 들어온 클라이언트 쓰레드들이 결국 캐시 라는 공유자원 앞에서 줄을 서게됨.
=> 병렬로 구현한 의미가 없어져버림.
그래서 조금 시간을 더 열심히 써서 프록시랩에서 다양한 걸 더 시도할 수 있었으면 어떨까... 라는 생각이 들었다.
가끔 시간을 효율적으로 사용하지 못하고 있을 때,
같은 반 동료 분의 "놀러 왔어요 ?" 라는 말이 메아리 처럼 머리 속을 빙 돈다.
그래서 조금 더 덜 자고, 이 악물고 공부에 더 투자를 해보기로 했다.
위 결심을 가지고 악명 높은 pintos의 늪을 해쳐봐야겠다.
