type vs dtype
X = [[1,5,4,3,2]] X.type<class 'numpy.ndarray'>
X.dtypedtype('int64')
type: X 자체의 타입을 출력함
dtype: X 내부의 원소들의 타입을 출력함
Ndim
ndarray의 dimention을 알려줌. 1차원이면 1, 2차원이면 2, 이런 식으로.
[[]] -> 2
[] -> 1shape
ndarray의 차원을 튜플 형태로 제공한다. 2 x 3일 경우, (2,3) 이런 식으로.
y = np.zeros((2, 3, 4))
y.shape
(2, 3, 4)
y.shape = (3, 8)
y
array([[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.]])np.vstack
vstack을 사용할 때는 1개의 argument만 할당해야 한다.
따라서 여러 개의 무언가를 할당할 시에는 싱글 리스트로 묶어준 후 함수를 사용한다.
B = np.vstack([a1.T,a2.T,a3.T,a4.T])
그렇지 않을 시 아래와 같은 오류가 발생한다.
TypeError: _vhstack_dispatcher() takes 1 positional argument but 4 were given
np.concatenate
concatenate를 사용할 때는 여러개를 할당하기 위해 소괄호로 묶어주어야 한다.
B = np.concatenate((a1.T,a2.T,a3.T,a4.T))
그렇지 않으면 아래와 같은 오류가 생긴다.
TypeError: only integer scalar arrays can be converted to a scalar index
+추가 )
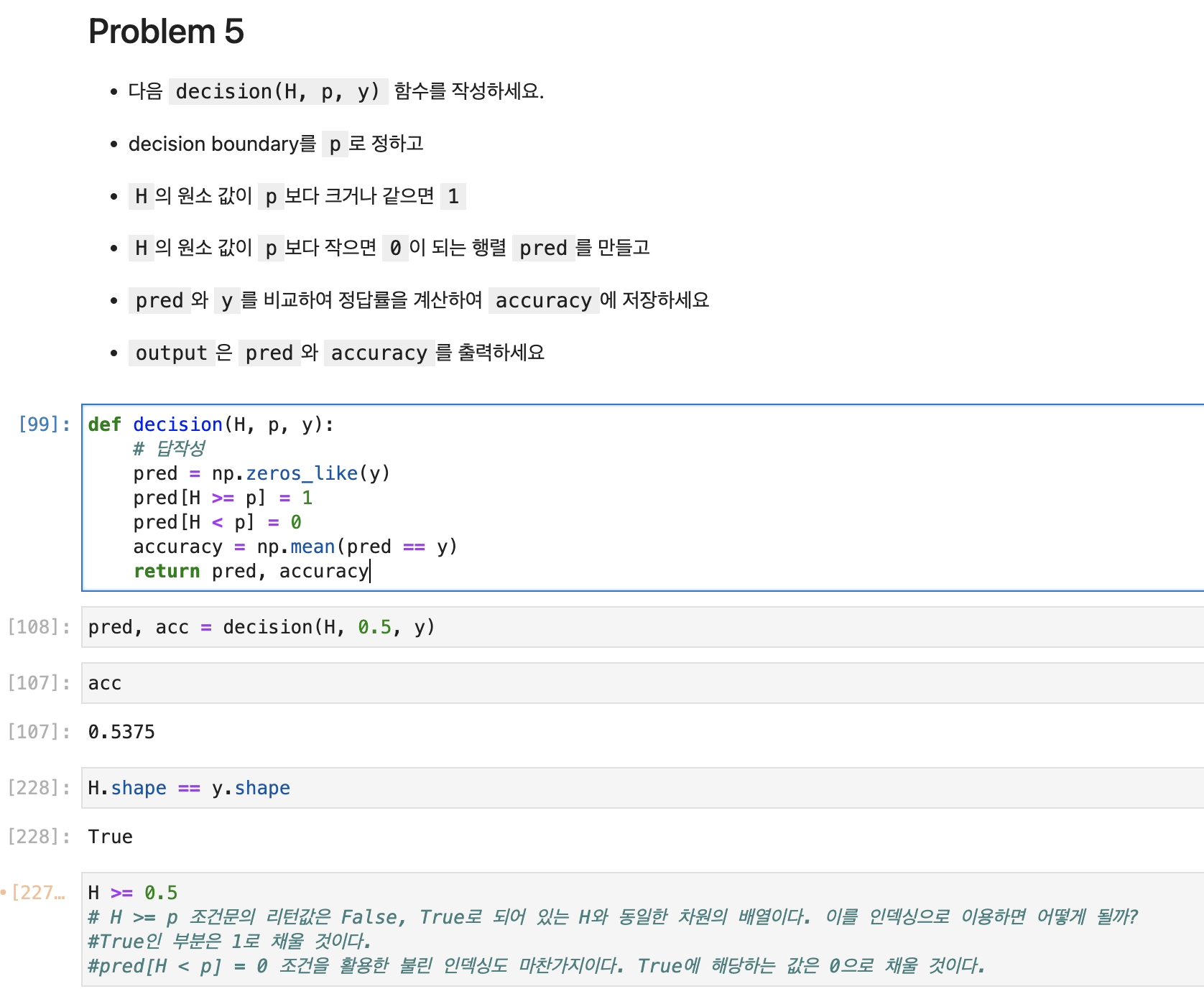
boolean indexing
numpy와 직결된 문제는 아니지만 알아두면 좋을 것 같아서 소개한다.
아래는 조건 인덱싱을 활용한 예제이다.
-
먼저 배경은 이렇다. y를 np.zeros_like(ytrian)을 통해 ytrain과 똑같은 차원의 0으로 채운 빈 numpy array를 생성한 상황이다.
-
본론으로 들어가보자. 이 예제에서는 인덱싱을 할 때 ytrain==4 라는 조건을 두었다.
즉, ytrain array 내부에서는 ytrain==4 조건을 만족하는 부분이 있을 것이다. 그 조건을 충족하는 원소들의 자리를 y의 인덱스로 하여 사용하는 것이다.
결론적으로 이를 활용하여 y[ytrain==4]인 자리의 원소를 1로 바꾼다.
-
예를 들어 ytrain = [[4, 4, 9, 9]] 의 형태를 가진 array라고 가정해보자.
-
ytrain==4 를 실행해보면 다음과 같은 결과가 나온다.
--> array(([True],[True],[False],[False])) -
ytrain==4의 조건을 충족하는 즉, True인 ytrain[0],ytrain[1]의 자리를 y의 인덱스로 활용하여 y array 해당 인덱스 자리의 원소는 1로 업데이트 된다.
y = np.zeros_like(ytrain) y[ytrain==4]=1 #ytrian이 4인 자리들은 1로 변환 y[ytrain==9]=0
다음 코드를 보며 boolean indexing을 이해해보자.
- 출력 셀 :

