
📌 신뢰구간(confidence interval)
정의
- 모집단의 실제 모수(평균 등)가 있을 것으로 추정되는 값의 범위
🚨 왜 값이 아닌 구간일까?
우리가 알고 싶은건 모집단의 평균(μ)이지만, 실제로 알 수 없으니 표본의 평균(𝑥ˉ)울 구해서 추정
그러나 표본의 평균은 매번 달라지므로 μ가 들어 있을 법한 범위를 예측하는 것
계산
[표준정규분포]
- 모표준편차(σ)를 알고 있는 경우: 𝑥ˉ ± z x (σ / √n)
- 𝑥ˉ: 표본 평균
- z: 원하는 신뢰 수준(예: 95%)에 해당하는 z분포의 값
- σ: 모집단의 표준편차
- n: 표본의 크기
[t분포]
- 모표준편차(σ)를 모르는 경우: 𝑥ˉ ± t x (s / √n)
- 𝑥ˉ: 표본 평균
- t: 원하는 신뢰 수준과 자유도(표본 크기 - 1)에 해당하는 t분포 상의 값
- s: 표본의 표준편차
- n: 표본의 크기
특징
- 모집단의 평균(μ)의 값은 고정되어 있고, 표본의 평균은 매번 달라지기에 신뢰구간만 흔들림
- 구간 폭이 좁다: SE가 작음 → 표본의 평균이 잘 안흔들림 → 추정이 안정적
- 구간 폭이 넓다: SE가 큼 → 표본의 평균이 잘 흔들람 → 추정이 불안정적
예시
학생 키 평균 추정:
- 표본평균 = 170cm, 표준편차 = 10cm, n = 100명
- 신뢰구간 95%: 170 ± 1.96 x (10 / √100) = (168cm ~ 172cm)
→ 위는 표본 한개로 만든 구간으로, 이렇게 만든 구간들 중 95%가 모평균을 포함
학생 키 개별값 예측:
- 예측구간 95%: (170 - 1.96σ) ~ (170 + 1.96σ) = (150cm ~ 190cm)
👉 신뢰구간과 예측구간 모두 “불확실성을 고려해서” 범위를 잡는데, 개별 값은 더 불확실해서 구간이 더 넓음
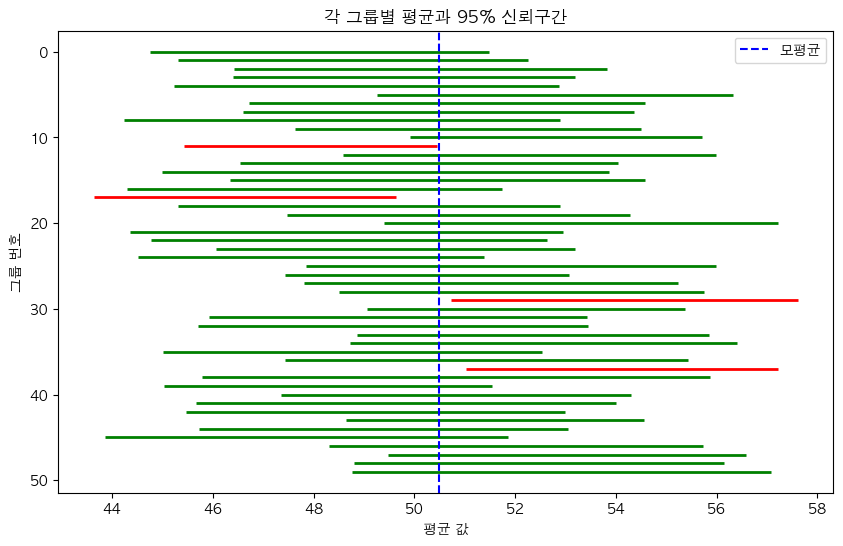
🚨 [주의] 95%의 신뢰 구간이란?
“이번 신뢰구간이 μ를 95% 확률로 담는다” ❌
“이러한 신뢰구간을 100번 만들면, 95번은 μ를 포함한다” ✅
📌 예측구간(prediction interval)
정의
- 표본 일부 중 하나의 값을 뽑았을 때, 특정 확률(예: 95%)로 값이 어떤 구간에 속할 것인지 예측하는 것
계산
- N(μ, σ) → (μ - 1.96σ) ~ (μ + 1.96σ)
예시
-
동전 던지기(동전을 100번 던졌을 때 앞면의 개수의 분포가 정규분포를 이룸)
- μ = 50, σ ≈ 5일때,
- 95%의 예측구간: 50 ± 1.96 x 5 = 40.2 ~ 59.8
즉, 또 다시 동전을 100번 던졌을 때, 앞면의 개수가 40~60개쯤 나올 가능성이 약 95%
-
시험 점수
- 전체 학생 점수: 평균 = 70, 표준편차 ≈ 10 (정규분포)
- 95%의 예측구간: 70 ± 1.96 x 10 = 50.4 ~ 89.6
즉, 새로운 학생이 전학 왔을 때 시험 점수가 50.4 ~ 89.6 사이일 확률이 약 95%
- 현실에서는 정확한 모집단의 데이터를 구할수 없어 표준편차(σ)를 알 수 없음
- 따라서 σ대신 표본의 표준편차 s로 대신 추정
- 표본으로 구한 s는 매번 오차가 있기에 매번 달라져 불확실성이 있음
- 불확실성을 해소하고자 정규분포 대신 t-분포 사용
| 구분 | 신뢰구간 | 예측구간 |
|---|---|---|
| 정의 | 모집단의 모수(예: 모평균)를 추정 | 새로운 개별 데이터 값을 예측 |
| 특징 | - 범위가 좁음 - 모집단 평균과 같이 한정된 값을 추정 - 예: 1억 마리의 개 중 푸들 찾기 | - 범위가 넓음 - 개별 데이터 값은 분산이 크므로 예측 어려움 - 예: 1억 마리의 개 중 뽀삐 한 마리 찾기 |
