
📌 이론적 확률 분포
정의
- 수학적으로 이미 모양이 정해져 있는 분포
특징
- 데이터를 직접 모으지 않더라도 확률의 규칙에 의해 정의됨
- 몇 개의 숫자(파라미터)로 전체 분포의 모양이 결정됨
- 평균: (μ: 뮤)
- 표준편차: (σ: 시그마)
- 분산: σ²
- μ와 σ 두 숫자만 알면 모집단의 성격(위치·흩어짐)을 큰 틀에서 파악할 수 있음
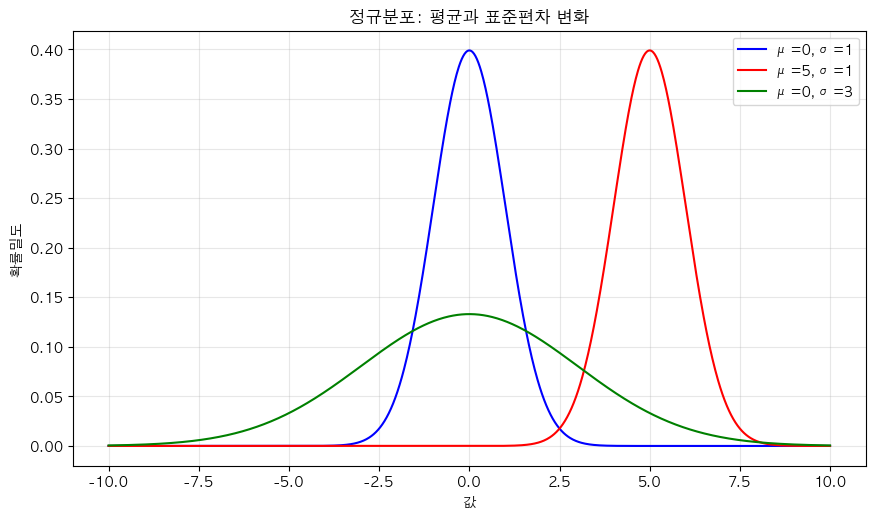
- 파란선: 표준
- 빨간선: 평균이 클수록 오른쪽으로 이동
- 녹샌선: 표준편차 클수록 넓고 낮아짐
예시
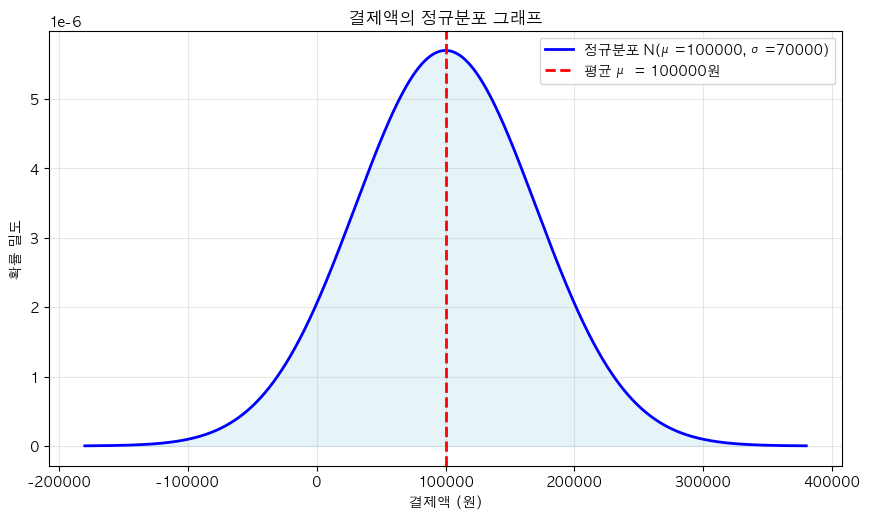
- 결제 데이터
- 평균 결제액(μ): 10만 원 / 결제액 표준편차(σ): 7만 원
- 결제 금액 분포: 주로 10만 원 근처에 집중되어 있고 범위는 3 ~ 17만 원으로 다양함
다른 분포에 대해서는 추후 다룰 예정...
📌 표준정규분포
정의
- N(0,1): 평균이 0이고 표준편차가 1인 표준화된 정규분포
- "이 모집단은 평균이 0이고, 표준편차가 1인 정규 분포를 따른다"고 표현
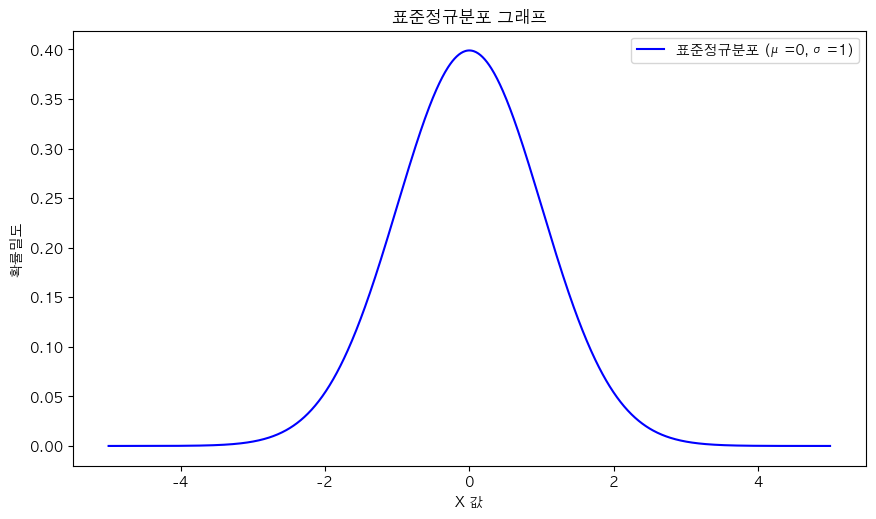
- "이 모집단은 평균이 0이고, 표준편차가 1인 정규 분포를 따른다"고 표현
💡 수 많은 숫자 중 하나를 맞추는건 불가능에 가깝지만, 범위(구간)를 맞추는건 비교적 쉬움
📖 68-95-99.7의 법칙
정의
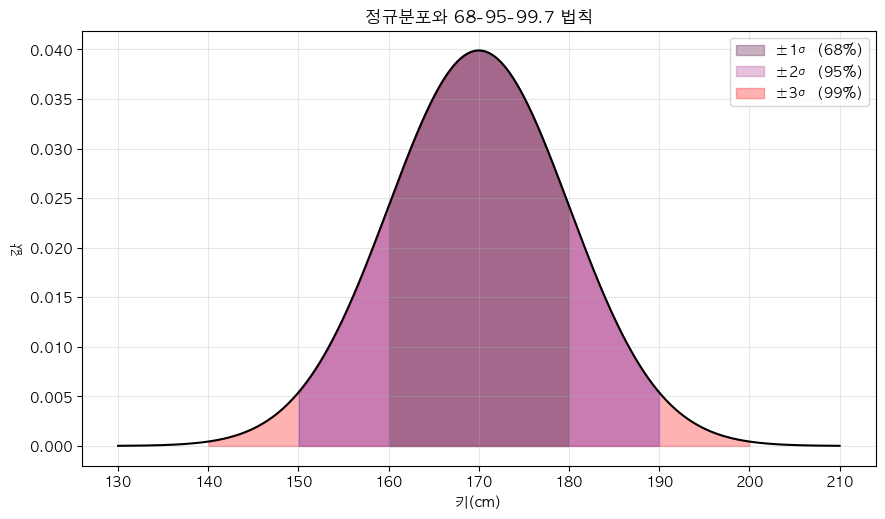
정규분포에서는 데이터가 평균 주변에 몰려있는 성질이 있음
- 평균에서 ±1 표준편차(σ) 구간 안에 약 68%의 데이터가 몰려있음
- 평균에서 ±2 표준편차(σ) 구간 안에 약 95%의 데이터가 몰려있음
- 평균에서 ±3 표준편차(σ) 구간 안에 약 99.7%의 데이터가 몰려있음
즉, 대부분 데이터가 평균 근처에 몰려있고, 멀리 벗어날수록 드묾
🛝 놀이터 비유
평균 = 집
표준편차 = 집으로부터의 거리
- ±1σ: 대부분 아이들은 집 앞 놀이터에서 놂(약 68%)
- ±2σ: 일부 아이들은 시내에 있는 피시방에서 놂(95%)
- ±3σ: 소수 아이들은 멀리 있는 놀이공원에서 놂(99%)
특징
- 68-95-99.7의 법칙은 정규분포에서만 성립됨
- 모든 데이터가 정규분포를 따르는 것은 아니므로, 히스토그램이나 박스플롯으로 분포 형태를 확인해야 함
- 일반적으로 95% 신뢰구간(-1.96 ~ +1.96)을 사용하며, 이 구간 내 값은 95% 확률로 포함
- 구간이 넓을수록 적중률은 높아지지만, 분석의 유의미성이 떨어질 수 있으므로 최적의 구간 설정이 중요
- 예: 김씨 아저씨의 거주지를 맞출 때, "지구상 어딘가"라고 답하면 적중률은 높지만 의미가 없음
예시
- 혈압이 평균에서 3σ 이상 떨어져 있음 → 희귀 케이스
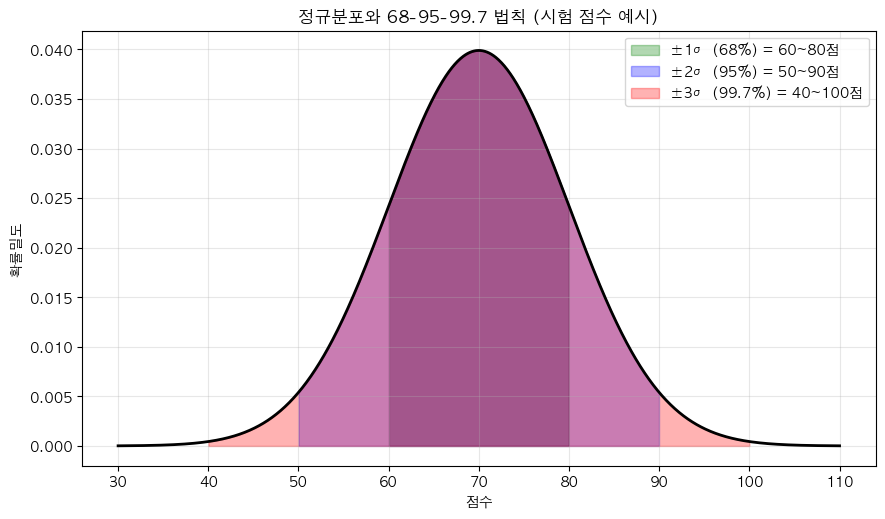
- 시험 점수 평균 = 70점, 표준편차 = 10점
- 68% 학생 점수는 60~80점 안에 있음 (±1σ)
- 95% 학생 점수는 50~90점 안에 있음 (±2σ)
- 99.7% 학생 점수는 40~100점 안에 있음 (±3σ)
📌 t분포(student’s t-distribution)
정의
- 모집단 표준편차(σ)를 모를 때, 표본 표준편차(s)를 대신 사용하여 추론할 때 쓰는 분포
특징
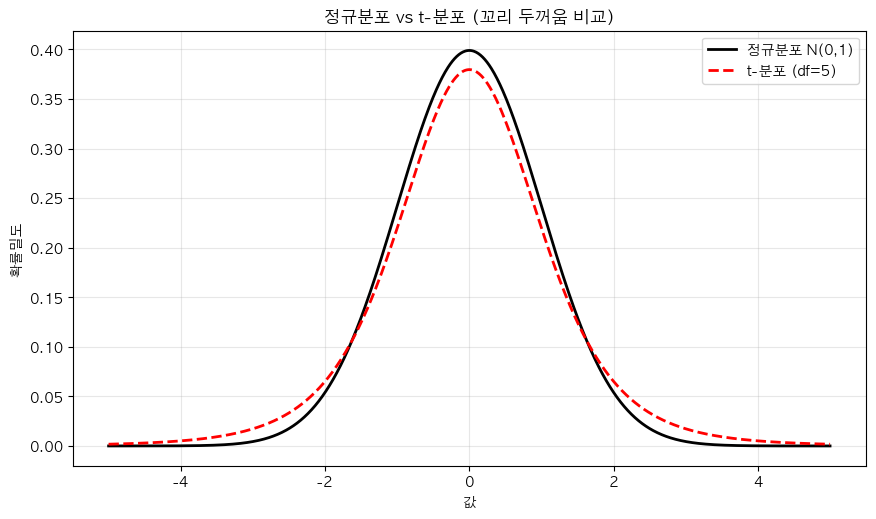
- 정규분포와 비슷한 종 모양이지만 꼬리가 두꺼움
- 이상치를 잘 반영함
- 표본이 많으면 정규분포에 수렴(중심극한정리)
💡 왜 꼬리가 두꺼울까?
꼬리가 두껍다는 건 극단적인 값(평균에서 멀리 떨어진 값)이 나올 확률이 더 크다는 뜻
- 모집단의 σ를 몰라 모르기 때문에 s로 추정해야 함
- s는 표본은 뽑을때마다 달라서 불확실성이 있음
- 따라서 평균에서 멀리 벗어난 값이 나올 가능성을 더 크게 반영
📌 표준화(z-score)
정의
- 다른 단위의 데이터를 평균=0, 표준편차=1를 기준으로 바꾸는 과정
계산
-
개별 데이터 값(x)을 표준화할 때
- z = (x − μ) / σ
- z: 표준화
- x: 변수
- z = (x − μ) / σ
-
표본평균(𝑥ˉ)을 표준화할 때
- z = (xˉ − μ) / SE
- x-: 표본평균
- SE: 표준오차
- z = (xˉ − μ) / SE
특징
- 실무 데이터는 평균과 퍼짐 정도가 다 달라 하나의 기준으로 통일하여 비교
- z(표준화)는 상대적 지표로 희귀성을 비교할 수 있음(절대적 우열 x)
- z값이 클수록 드문 값임
- 데이터가 정규분포에 맞지 않을 경우 억지로 맞추려고 하면 착시가 발생함(예: 평균 연봉이 실제와 다름)
예시
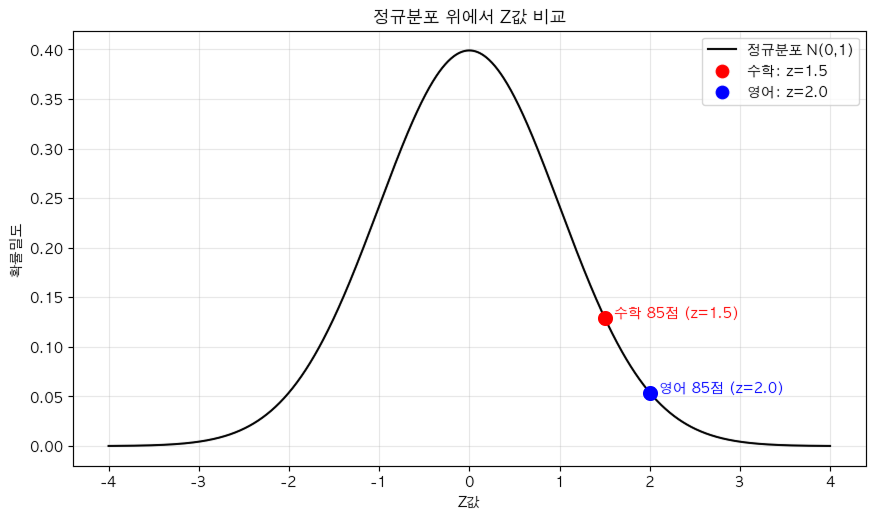
- 시험 점수의 표준화 → 정규분포라고 가정
- 수학 시험: 학생 A 점수 x = 85, 평균 μ = 70, 표준편차 σ = 10 / z = 1.5
- 영어 시험: 학생 B 점수 x = 85, 평균 μ = 75, 표준편차 σ = 5 / z = 2.0
영어 시험의 z값이 더 높아 수학 시험보다 더 희귀한(드문) 값
📌 표본오차(sampling error)
정의
- 표본조사 결과와 실제 모집단 결과 사이에 생기는 차이
표본은 무작위로 뽑히기에 모집단을 100% 대표하지 못하는 것이 당연
특징
- 표본의 크기가 작을수록 오차가 커짐
- 표본의 크기가 클수록 모집단을 잘 대표하기에 오차가 줄어듦
- 오차는 자연스러운 현상으로 실수나 에러가 아님
예시
- 표본의 크기가 작을 경우:
- 실제 전국(모집단) 학생들의 평균 키는 170cm이지만, 우리 반 학생(표본)들의 평균 키는 160cm로 오차가 존재
- 표본의 크기가 클 경우:
- 실제 전국(모집단) 학생들의 평균 키는 170cm이지만, 서울시 학생들의 평균 키는 168cm로 오차가 존재
📌 표준오차(standard error, SE)
정의
- 표본의 평균은 뽑힐 때마다 달라지는데, 그 흔들림(변동성)의 크기를 수치로 나타낸 것(즉, 표본의 평균들의 표준편차)
계산
- SE = σ / √n
- σ = 모집단 표준편차(현실에서는 보통 표본표준편차 s를 사용)
- n = 표본 크기
특징
- n이 커질수록 분포의 폭이 좁아지고, SE(표본의 평균들의 흔들림)가 작아짐
정리
| 구분 | 표본오차 (Sampling Error) | 표준오차 (Standard Error) |
|---|---|---|
| 의미 | 표본평균과 모평균의 실제 차이 | 표본평균이 흔들리는 정도(표본평균의 표준편차) |
| 계산 | 실제 모집단 평균을 알아야 함 | 공식으로 추정 가능 (σ/√n) |
| 성격 | 실제 차이 (한 번 뽑은 표본에서 발생) | 이론적 추정치 (여러 번 뽑는다고 가정한 변동성) |
| 예시 | 모집단: 170, 표본: 172 → 오차 2 | 표본 1의 평균: 170, 표본 2의 평균 173, ... |
- 표본오차: “이번에 내가 뽑은 표본의 값이 진짜랑 얼마나 차이 나나?”
- 표준오차: “앞으로 표본을 여러 번 뽑는다면, 표본평균은 평균적으로 얼마나 흔들릴까?”
📌 대수의 법칙(큰수의 법칙)
정의
- 표본이 커질수록 우연이 줄어들고, 표본평균의 값이 모평균에 가까워진다는 법칙
예시
-
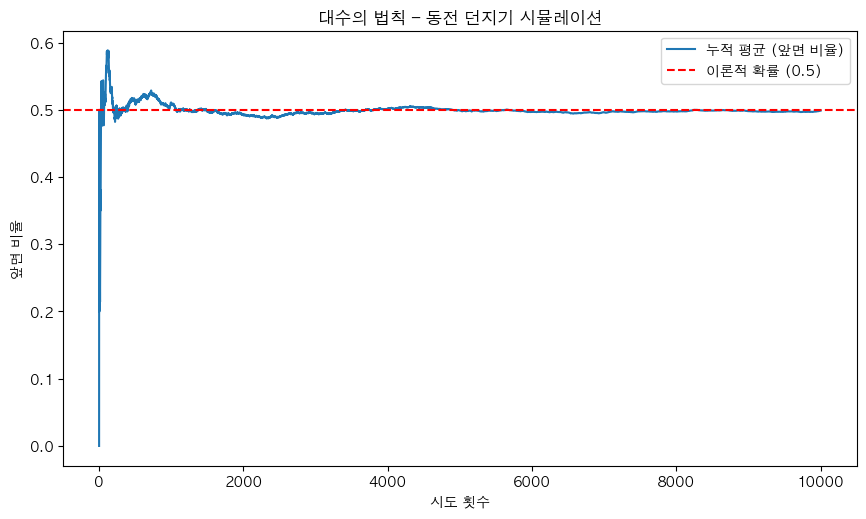
동전 던지기
- 동전을 던져서 앞면이 나올 확률 = 50%(이론)
- 10번 던지면 앞면이 5번쯤 나올 것 같지만, 실제로는 1번일 수도, 10번일 수도 있음 → 앞면이 나올 비율이 0%~100%까지 다양
- 그러나 던지는 횟수를 100번, 1,000번, 10,000번으로 늘리면 → 앞면이 나올 비율은 50%에 점점 가까워짐
-
홈페이지 일일 방문자(DAU)
- 하루 방문자 수는 신규 업데이트, 한정 상품 판매, 이벤트 등 다양한 이슈로 인해 크게 변동함
- 하지만 10년 치 데이터를 모아 평균을 내면, 서비스의 안정적인 방문자 수를 알 수 있음
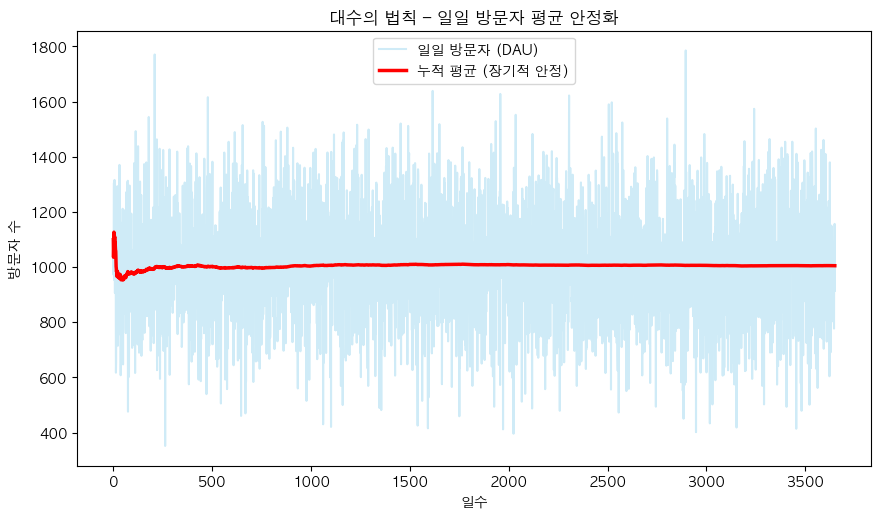
💡 표본이 많아질수록 결과가 안정되고, 모집단의 평균에 수렴함
📌 표본 설계
원칙
- 표본이 작으면 신뢰구간의 폭이 넓고 표본이 크면 신뢰구간의 폭이 좁아짐
- 신뢰구간의 폭을 반으로 줄이기 위해 표본 수를 4배 늘려야함
💡 √n 법칙
- SE(표준오차) = σ / √n
- σ = 모집단 표준편차(현실에서는 보통 표본표준편차 s 사용)
- n = 표본 크기
n을 2배로 늘리면 → SE는 1/√2배 (약 0.71배)
n을 4배로 늘리면 → SE는 1/√4배 = 1/2배
즉, 신뢰구간 폭을 절반으로 줄이려면 n을 4배로 늘려야 함
n = 100 → 폭 = 4
n = 400 → 폭 = 2
- 신뢰구간의 폭을 반으로 줄이기 위해 표본 수를 4배 늘려야함
주의
- 대표성/무작위성이 없는 표본이면 n이 커져도 의미 없음 (편향(Bias) 문제)
- 편향(Bias)이 있다면?
- 예: 키를 조사하는데 농구부만 뽑음 → 평균이 실제보다 크게 측정
이 경우 n을 아무리 늘려도 틀린 결론에 수렴하게 됨
👉 따라서, n을 크게 만드는 것만으로는 충분하지 않고, 표본을 제대로 뽑는 것(무작위성)이 더 중요함
- 예: 키를 조사하는데 농구부만 뽑음 → 평균이 실제보다 크게 측정
- 편향(Bias)이 있다면?
📌 표본 설계 체크리스트
1️⃣ 표본틀(프레임) 정의
- 분석 목적과 필요성 명확히 설정
- 어떤 가설을 검증하기 위해 분석을 진행하는지 구체적으로 정의
2️⃣ 표본 추출 방식 선정
- 단순무작위, 층화추출, 군집추출, 체계추출 중 목적에 맞는 방식 선택
3️⃣ 독립성 보장
- 동일한 대상이 중복 수집되지 않도록 관리
4️⃣ 시점/채널 편향 방지(독립성)
- 특정 시점이나 채널에 데이터가 과도하게 쏠리지 않도록 주의
5️⃣ 목표 오차폭(E)과 표본 크기(n) 계산
- z: 신뢰수준에 따른 z값(예: 95% → z=1.96)
- σ: 모집단 표준편차(또는 추정값)
- E: 허용 가능한 오차(오차 한계)
