
📌 확률변수(random variable)
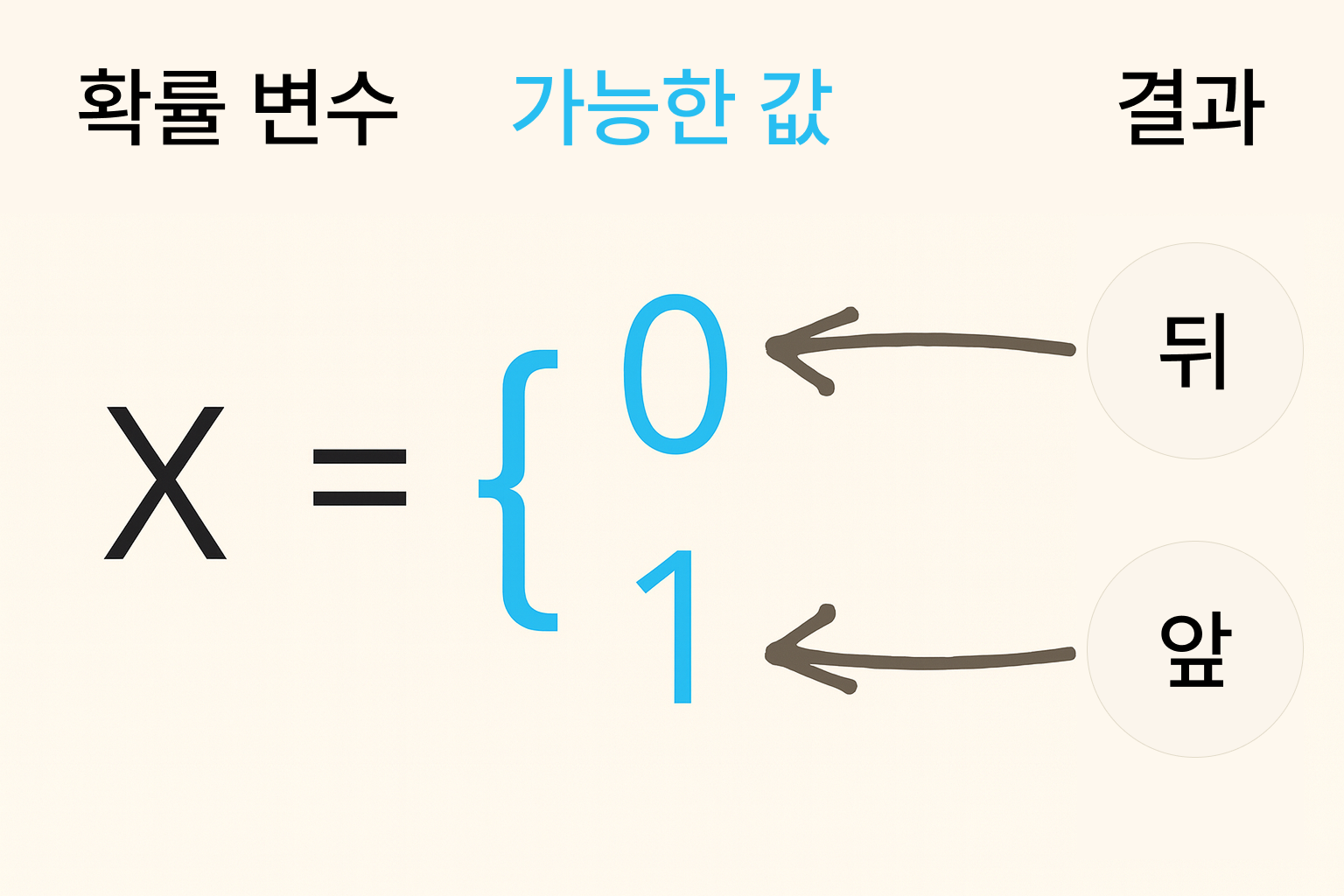
정의
- 어떤 실험 결과에 숫자를 대응시킨 규칙(함수)
특징
- 결과를 계산하기 쉽도록 수치화
- 대문자 X, Y, Z등으로 표시
예시
- 동전 던지기:
- 앞면=1, 뒷면=0
- 상품 구매 여부:
- 구매=1, 미구매=0
- 주사위 던지기: {1, 2, 3, 4, 5, 6}
- 확률변수 Y = “나온 눈” → Y=1, Y=2, …등으로 표현할 수 있음
🚨 주사위를 두 번 던져서 2가 두 번 나오면 (X=2, X=2)일 뿐, 2+2=4가 아님
- 확률변수 Y = “나온 눈” → Y=1, Y=2, …등으로 표현할 수 있음
이산형 확률 변수
- 세어지고, 딱딱 떨어지는 값만 가질 수 있는 확률변
- 주사위 눈: 1~6
- 동전 앞뒤: 0,1
연속형 확률 변수
- 구간 안에서 무수히 많은 값을 가질 수 있는 확률변수
- 사람의 키: 170.0001cm
- 결제금액: 10,000원
→ 겉보기엔 이산형 확률 변수처럼 보일 수 있으나, 통계적으로는 “연속형”으로 간주실무 데이터에서의 확률 변수
-
수치형 컬럼(구매 금액, 나이, 체류 시간 등) → 그대로 사용
-
범주형 컬럼(성별, 회원등급, 구매 채널 등) → 매핑을 통해 수치화 필요
-
💡 확률변수(결과)를 모아봤더니 어떠한 패턴이 나타남 → 확률분포로 연결됨
📌 확률분포
정의
- 확률변수가 가질 수 있는 값들이 얼마나 자주 나타나는지 보여주는 그림
관점
- 이론적 확률 분포: 이론적으로 미리 아는 확률
- 주사위 각 눈이 나올 확률: 1/6
- 동전 앞뒤면이 각각 나올 확률: 1/2
- 실제 데이터 분포: 실험을 통해 나온 결과
- 주사위를 100번 던졌더니 3은 20번, 6은 10번 나옴
- 동전을 30번 던졌더니 앞은 25번, 뒤는 5번 나옴
실무에서는 이론적 확률분포를 모르기에 데이터를 모아서 실제 분포를 관찰하고, 적합한 이론적 분포를 가정하여 모델링 진행(추후에...)
특징
- 그림(막대·곡선)으로 표현해 직관적임
- 실험 횟수가 적으면 실제 분포와 이론 분포 차이가 크지만, 반복 횟수가 많아질수록 실제 분포가 이론 분포에 가까워짐(대수의 법칙)
예시
-
이산형 분포(막대그래프): 개별 값에 대한 확률
- 동전을 100번 던졌을 때 각각의 결과(앞면, 뒷면, 앞면, 앞면, ..., 앞면)를 보기 좋게 그림으로 표현
- 앞면: 70번, 뒷면: 30번
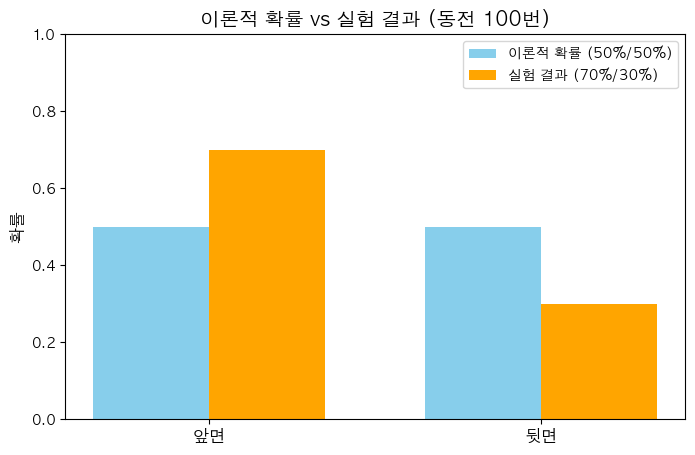
- 동전을 100번 던졌을 때 각각의 결과(앞면, 뒷면, 앞면, 앞면, ..., 앞면)를 보기 좋게 그림으로 표현
-
연속형 분포(곡선과 면적): 구간에 대한 확률
- LOL 게임 플레이어 중 하루에 1시간 이상 2시간 미만 플레이한 확률을 그림으로 표현
- 1초 이상 1시간 미만 플레이: 300명, 1시간 이상 2시간 미만 플레이: 1,000명
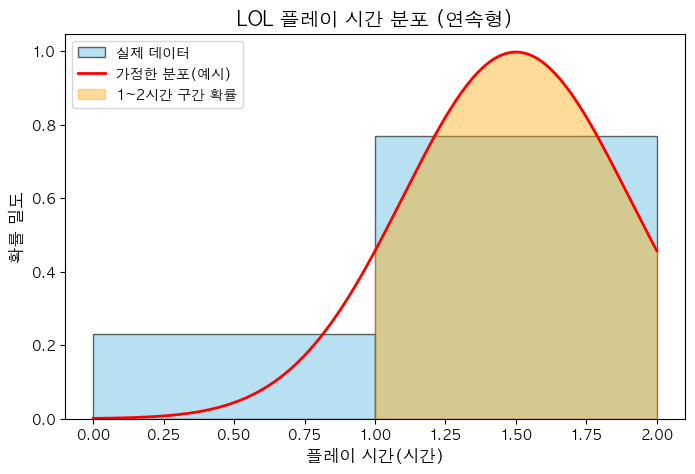
- LOL 게임 플레이어 중 하루에 1시간 이상 2시간 미만 플레이한 확률을 그림으로 표현
💡 개별 값이 아닌 구간을 보는 이유
- 연속형 분포에서는 특정 값 하나의 확률=0
- 예: 정확히 60.000000초를 플레이할 확률은 0에 가까움
- 따라서 개별 값이 아니라 구간 단위로 확률을 계산
📌 기대값 E(X)
정의
- 어떠한 실험을 여러번 반복했을 때 평균적으로 나오길 기대되는 값
- 이산형: E(X) = Σ [값 × 확률]
- 반복형: E[X] = ∫ x f(x) dx
특징
- 실험을 여러 번 반복할수록 평균은 기대값에 점점 가까워짐(대수의 법칙)
예시
-
주사위 굴리기
- 주사위를 한 번 던지면 → 1~6 중 하나가 나옴
- 여러 번 던져 평균 계산 → 평균값은 점점 3.5에 수렴
- 이때 3.5를 주사위를 여러 번 던질 때 평균적으로 기대되는 값이라고 함
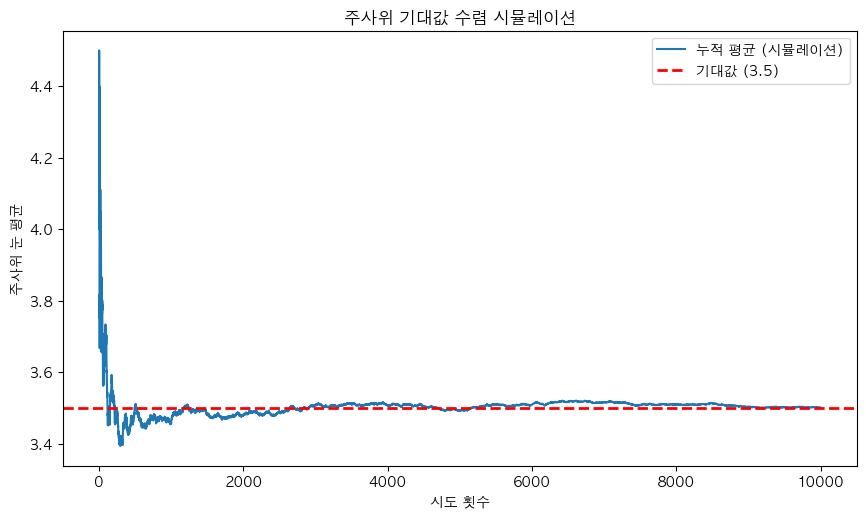
-
광고 클릭률
- 배너 광고가 1,000번 노출되었을 때, 클릭할 확률은 5%
- 배너를 클릭했을 때 회사가 얻는 수익 = 2,000원
E[X]=(2,000×0.05)+(0×0.95)=100원
👉 즉, 광고를 한 번 노출할 때 평균적으로 100원의 수익을 기대할 수 있음
-
결제 금액
- 고객의 50%는 10,000원 결제, 30%는 30,000원 결제, 20%는 100,000원 결제
E[X]=(10,000×0.5)+(30,000×0.3)+(100,000×0.2)=5,000+9,000+20,000=34,000원
👉 즉, 고객 한 명이 결제할 때 평균적으로 34,000원 정도 결제할 것으로 “기대”할 수 있음
- 고객의 50%는 10,000원 결제, 30%는 30,000원 결제, 20%는 100,000원 결제
🚨 평균과 기대값
평균: 실제로 내가 가지고 있는 데이터로 계산한 값(실험 횟수에 따라 결과가 달라짐)
- 주사위를 5번 던져서 (2, 6, 1, 3, 2)가 나왔다면 평균은 2.8
기대값: 여러번 실험한 결과들의 평균이 수렴하는 값(이론적으로 정의)
- 주사위를 무한히 던지면 평균이 3.5에 가까워짐
