htonl 사용이유
리눅스 같은 리틀엔디안 기반의 바이트 저장 방식을 네트워크 공용 처리방식인 빅 엔디안으로 바꾸기 위함입니다.
그렇다면htonl같은 함수는 OS가 어떤것인지 어떻게 알고 바꿀까? 라는 생각을 해보았고, 결국 그냥 들어온 값을 반대 저장 방식으로 저장할 것 같다는 생각을 하게 되었습니다.
간단한 테스트
간단하게 2번씩 적용시켜가며 테스트 해보았습니다.
# include <netinet/in.h>
# include <cstdio>
int main() {
int a = 0x12345678;
int b = htonl(a);
printf("[%08x][%08x]\n", a, b);
int c = htonl(b);
printf("[%08x][%08x]\n", b, c);
int d = ntohl(c);
printf("[%08x][%08x]\n", c, d);
int e = ntohl(d);
printf("[%08x][%08x]\n", d, e);
return 0;
} 결과
long
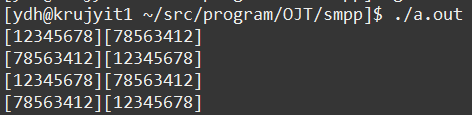
리눅스 기반 os에서 테스트 해보았으며, 같은 함수를 다시 적용했을 때 다시 앞뒤 순서가 바뀌는 것을 확인할 수 있었습니다.
short
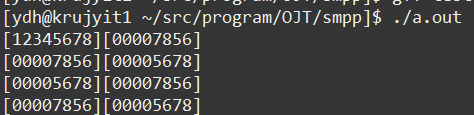
위와 같은 코드를 가지고 함수만 바꾸어 실행해보았을 때 앞의 두 바이트는 0으로 되며 뒤의 두바이트만바뀌는 것을 확인할 수 있습니다.
short -> long
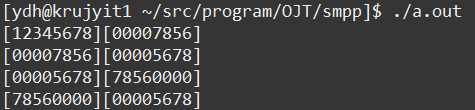
뒤의 두바이트로 정렬되던 부분이 long으로 할땐 앞의 바이트 부터 채우는 것을 확인할 수 있습니다.
만약 htonl과 같은 함수를 두번 실행시키면 어떻게 될까요?
아무래도 리틀엔디안 형식으로 네트워크를 타고 전송되어 잘못된 데이터를 넘겨줄 가능성이 있습니다.
이를 방지하기위해 간단한 encoding, decoding 함수를 구현해보았습니다.
정수를 버퍼에 빅엔디안으로 넣기
void typeEncoding(int num, unsigned char* buffer) {
int size = sizeof(num) - 1;
//1을 뺀 size 전까지 for문을 돌리는 이유는 마지막 인덱스엔 나머지 값을 넣기 위함
for (int i = 0; i < size; ++i) {
buffer[i] = num / pow(BYTE_SIZE, (size - i));
}
buffer[size] = num % BYTE_SIZE;
}
void typeEncoding(short num, unsigned char* buffer) {
int size = sizeof(num) - 1;
//1을 뺀 size 전까지 for문을 돌리는 이유는 마지막 인덱스엔 나머지 값을 넣기 위함
for (int i = 0; i < size; ++i) {
buffer[i] = num / pow(BYTE_SIZE, (size - i));
}
buffer[size] = num % BYTE_SIZE;
}(빅엔디안)버퍼의 값을 정수로 받기
int typeDecoding(int num, unsigned char* buffer) {
int size = sizeof(num) - 1;
int ret = 0;
for (int i = 0; i <= size; ++i) {
ret += buffer[i] * pow(BYTE_SIZE, size - i);
}
return ret;
}
short typeDecoding(short num, unsigned char* buffer) {
int size = sizeof(num) - 1;
short ret = 0;
for (int i = 0; i <= size; ++i) {
ret += buffer[i] * pow(BYTE_SIZE, size - i);
printf("num [%d] buf [%02x]\n", num, buffer[i]);
}
return ret;
}
모르면 공부하고 알게되면 공유하는 개발자