논문 목표: 의료 영상 이해 분야에서 CNN 및 그 변형의 응용과 방법론에 대한 포괄적인 개요를 제공하는 것
1 Introduction
machine learning 기술(decision tree learing, clustering, K-NN 등)을 활용하기 위해서는 이미지 이해에 필요한 특징을 자동으로 학습하고 추출할 수 있는 지능적인 기계를 만들어야 함
=> 이러한 모델이 CNN(convolutional neural networks)모델
CNN model- convolutional filter로 만들어짐, 효율적으로 의료 이미지 이해하는데 필요한 특징 학습, 추출
2012년 CNN모델 AlexNet 등장
ImageNet Challenge 2012에서 높은 성능을 보임
2 Medical image understanding
2.1 Medical image classification
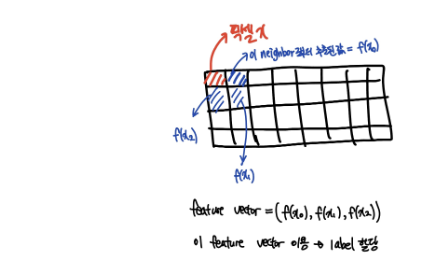
I : image made of pixels
c1, c2, …, cr : the labels
x : each pixel
v: feature vector
2.2 Medical image segmentation
목적: 강한 상관관계를 가지는 영역으로 이미지 나누기
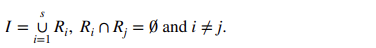
S: 영역의 총 분할 수
Ri: 각 영역
두 영역의 교집합(겹치는 부분) 없음 => 공집합
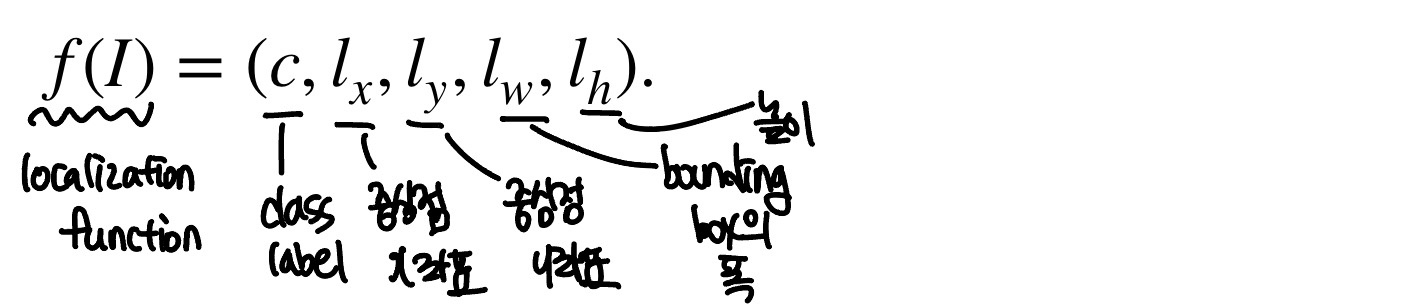
2.3 Medical image localization
Localization= 이미지에서 객체 예측 + bounding box 그리기 + 객체 labeling하기
2.4 Medical image detection
여러 regions of interest(ROI) 주변에 bounding box를 그려서 ROI classification, localization하는 것
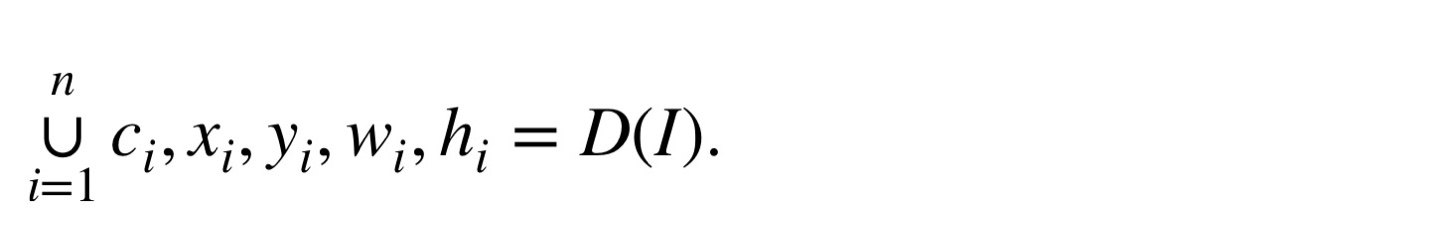
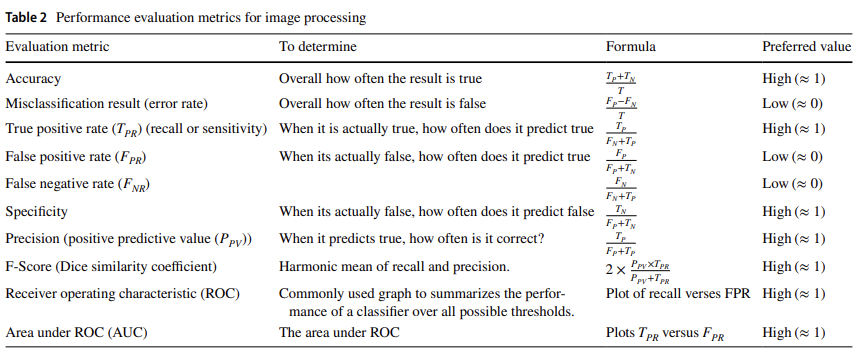
2.5 Evaluation metrics for image understanding
Confusion matrix

Performance metrics
3 A brief introduction to CNNs
- 동물: 눈이 이미지 캡처, 신경을 통해 처리, 뇌로 전송되어서 해석
- CNN: 동물의 시각 기계 모방, 학습 가능한 가중치(weights)와biases를 가진 convolution으로 구성
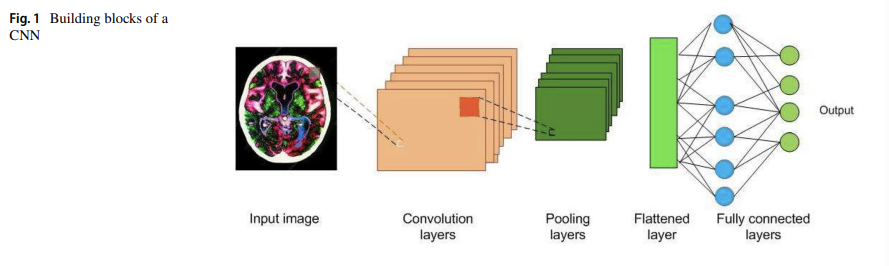
3.1 Convolutional layers
Convolutional layer의 목적: edge, color 등 특징들 추출하는 것
convolutional filter로 구성되어 있음
filter size = n x m x d
forward pass하면 kernel이 input의 너비와 높이를 지나면서 각 filter의 entry와 입력 내적 계산
conv layer의 출력은 activation function layer로 전달됨
3.2 Activation functions or nonlinear functions
실제 세계의 데이터는 대부분 비선형이라서, 데이터를 비선형으로 변환하기 위해 activation function 사용
Sigmoid
입력을 0~1로 압축해서 표현, 큰 양수값 = 1과 가까이, 큰 음수값 = 0과 가까이

Tan hyperbolic
입력을 -1~1로 표현

Rectified linear unit(ReLU)
x가 음수면 0으로 변환
CNN에서 가장 자주 사용되는 nonlinear function, 계산 시간 적게 듬
f(x) = max(0, x)3.3 Pooling
convolved feature을 nonlinear down sampling함
computational power를 줄임, 공간 크기도 줄임, overfitting 제어함
maximum pooling, average pooling이 있음
3.4 Fully connected(FC) layer
인공 신경망과 유사, 각 node는 입력에서 들어오는 모든 연결을 가진다, 각 연결에는 가중치 있음, 출력= 입력*가중치의 합
sigmoid activation function써서 classifier job을 함
3.5 Data preprocessing and augmentation
raw image data는 왜곡되었을수 있어서 전처리가 필요함
전처리 방법: mean subtraction, normalization
성능을 향상시키려면 더 큰 dataset에서 훈련되어야함
horizontal and vertical flips, transformations, scaling 등등
3.6 CNN architectures and frameworks
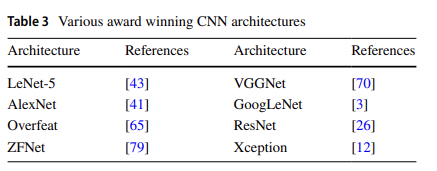
4 CNN applications in medical image classification
4.1 Lung diseases
Interstitial lung disease (ILD)- 폐 기질의 이상으로 인해 폐 조직이 변성되어 호흡 곤란을 유발하는 질환
High resolution computed tomography (HRCT, 고해상도 컴퓨터 단층 촬영 영상) -ILD 구별하는데 사용

4.1.1 Ensemble CNN
폐 주변의 세균의 분류를 위해, Ensemble of rf and overfeat
AUC of 86.8% 달성
(rf: random forest의 약어, 여러 결정 트리를 합쳐서 높은 정확도의 예측을 수행하는 머신러닝 알고리즘)
(overfeat: 합성곱 계층을 사용하여 이미지의 다양한 특징을 추출)
4.1.2 Small‑kernel CNN
커널크기를 2 x 2로 줄여서 (미세한 이미지 특징 캡처=> 더 많은 비선형 활성화 포함) 낮은 수준의 텍스트 정보 캡처, 전체 폐 영역 분류하는데 시간 완전 줄어들고 평균 정확도는 85% 달성
4.1.3 Whole image CNN
smaller image 패치들 사용-> 공간정보 손실 방지
4.1.4 Multicrop pooling CNN
training sample이 작을때의 한계를 극복하기 위해 multicrop pooling을 사용하여 다중 스케일 특징 추출
정확도: 87.4%, AUC: 93%를 달성
4.2 Coronavirus disease 2019 (COVID‑19)
Reverse Transcription Polymerase Chain
Reaction (RT-PCR) 검사를 통해 감염 감지, 매우 복잡, 시간이 많이 소요, 정확도가 높지 않다
딥러닝을 이용해서 chest infection(흉부감염)이 covid-19 때문인지 아닌지 분류함
4.2.1 Customized CNN
초기에는 simple pretrained AlexNet 모델 사용
정확도: 95%
4.2.2 Bayesian CNN
목표: COVID-19 오진을 피하는 것
Monte-Carlo Dropweights Bayesian CNN 사용=> 예측에서 추정된 불확실성과 분류 정확도 간에 강한 상관관계를 설명
4.2.3 PDCOVIDNET
제안: parallel dilated CNN model
Grad-CAM, Grad-CAM++을 사용하여 클래스 구별적인 중요도 맵의 영역을 강조
4.2.4 CVR-Net
제안: multi scale multi encoder ensemble CNN model
geometry based image augmentations and transfer learning 사용 (overfitting 막기 위해), Depth-wise separable convolution 사용
4.2.5 Twice transfer learning CNN
제안: trained twice using transfer learning approach
imagenet dataset에서 먼저 train-> chest X-ray 14 dataset에서 train -> 마지막으로 COVID-19 데이터셋에서 finetuning함
4.3 Immune response abnormalities
Autoimmune diseases(자가면역 질환): 정상적인 신체 부위에 대한 이상한 면역 반응으로 발생
신체의 면역 체계가 건강한 세포를 공격
human epithelial-2 (HEp-2) 세포에서 Immunofluorescence(IIF)를 사용하여 자가면역 질환을 진단 - 패턴 인식
4.3.1 CUDA ConvNet CNN
전처리 수행 using histogram equalization and zero-mean with unit variance
제안: Cafe library and CUDA ConvNet model architecture
4.3.2 Six‑layer CNN
전처리, augmentation으로 정확도 향상
framework-> image preprocessing, network training, feature extraction 세단계로 구성
4.4 Breast tumors 유방암
mammograph로 진단 가능

4.4.1 Stopping monitoring CNN
stop monitoring by using AUC on validation set - 계산 시간 줄이기 위해서
4.4.2 Ensemble CNN
AlexNet과 비슷한데 imagenet에서 pretrain됨, 특징 추출-> train할 때 SVM classifier 사용
4.4.3 Semi‑supervised CNN
4개의 모듈 사용: feature extraction (21개의 특칭 추출), data weighing(노이즈 최소화하기 위해서) ,division of cotraining data labeling, sub patches extraction of ROIs
4.5 Heart diseases
Electrocardiogram (ECG)-심장의 이상 감지

4.5.1 One-dimensional CNN
1차원 CNN으로 구성-세 개의 conv layers와 두 개의 FC layers로 이루어짐
4.5.1 Fused CNN
제안: 공간 및 시간 데이터를 모두 사용하는 Fused CNN architecture
두 CNN을 사용, 하나는 spatial, 하나는 temporal을 따릅니다. 각각의 CNN은 개별적으로 실행
4.6 Eye diseases
4.6.1 Gaussian initialized CNN
초기 train 시간은 Gaussian initialization으로 감소 가능, weighted class weights 사용해서 overfitting 방지
4.6.2 Hyper parameter tuning inception‑v4
제안: 자동으로 hyper parameter tuning inception-v4 (HPTI-v4) model
CLAHE를 사용한 전처리와 Bayesian 최적화 방법 사용
4.7 Colon cancer (대장암)
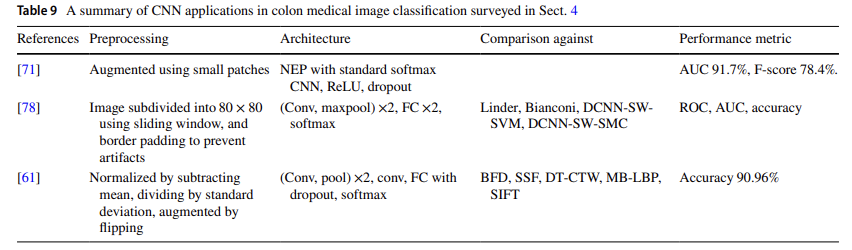
4.7.1 Ensemble CNN
small patch 이용-> train data 양을 늘리고 이미지의 작은 핵에 localize-> 성능 향상
4.8 Brain disorders
Alzheimer’s disease (AD)
4.8.1 Fused CNN
제안: 2차원 CNN, 3차원 CNN(Z방향이 중요해서) fusion
CT 이미지의 geometric normalization 수행 (CT가 MRI에 비해서 두꺼워서)
4.8.2 Input cascaded CNN
입력 연결 CNN을 사용하여 뇌 종양의 다단계 분류를 수행하였고, 증강 및 미세 조정을 통해 데이터 부족 문제를 극복
5 CNN applications in medical image segmentation
5.1 Brain tumors
MRI사용, high level feature을 추출해야 하므로 어려움
5.1.1 Small kernel CNN
Patch-wise training and use of small filter sizes (3 × 3) 사용한 glioma들 분할 모델
high, low glioma 각각 훈련
5.1.2 Fully blown CNN
MRI 2D 이미지를 사용-> 뇌 구조 분할
Markov random field 적용
5.1.3 Multipath CNN
Two pathways (convolution, deconvolution) 사용-> 자동으로 MS 병변 분할
TPR이랑 FPR은 향상, DSC는 더 안좋게 나옴
5.1.4 Cascaded CNN
라벨이 불균형 한 경우-> two phase training (global contextual feature, local detailed feature 동시에 학습)
5.1.5 Multiscale CNN
multiscale CNN, 2D CNN 사용해서 계산 시간 줄임, 3개의 patch size 사용
5.1.6 Multipath and multiscale CNN
더 작은 kernel과 multiscale architecture을 결합-> 뇌 병변 분할을 수행하는 모델
5.2 Breast cancer
5.2.1 FCNN
ROI segmentation 사용 in fast scanning deep CNN (FCNN), conv, max pool layer에서 반복적인 계산 안할 수 있음
5.2.2 Probability map CNN
probability map을 사용-> 반복적인 영역 분할, 병합
5.2.3 Patch CNN
patch-based CNN + superpixel 기술 결합
5.3 Eye diseases
5.3.1 Greedy CNN
backpropagation 대신에 greedy approach of boosting 사용해서 순차적으로 학습
여러 필터를 학습-> 가중치 분류 오차를 최소화하기 위해 boosting 적용
5.3.2 Multi label inference CNN
multi label inference CNN 사용-> 망막 혈관 세분화 분할
RGB fundus 이미지에서 녹색 채널을 추출-> 혈관이 녹색 채널에서 높은 대비를 나타내는 특성을 이용
5.4 Lung
5.4.1 U net
이미지 전처리-> 뼈 그림자를 제거하고 간단한 U-Net 아키텍처를 사용
6 CNN applications in medical image detection
6.1 Breast tumors (유방종양)
6.1.1 GoogLeNet CNN
patch-based classifcation 사용, Otsu's algorithm 사용해서 계산 시간 줄임
6.2 Eye diseases
6.2.1 Dynamic CNN
랜덤으로 가중치 설정 -> 학습 가속화, 성능 향상
매 train epoch마다 큰 의료 이미지 pool에서 동적으로 선택된 샘플 사용
6.2.2 Ensemble CNN
12개의 CNN ensemble
각 CNN의 출력 확률을 평균 -> 각 픽셀에서 혈관 확률을 정함
6.3 Cell division
6.3.1 LeNet CNN
객체의 중심 이동과 augmentation이 성능 향상
목적: scratch assay에 발생하는 세포 분열을 자동으로 감지하고 측정
7 CNN applications in medical image localization
7.1 Breast tumors
7.1.1 Semi‑supervised deep CNN
라벨이 지정되어 있는 data가 별로 없을 때 사용
라벨이 지정된 데이터를 사용 -> 먼저 라벨이 지정되지 않은 데이터를 자동으로 라벨링 -> deep CNN을 train
7.2 Heart diseases
7.2.1 Pyramid of scales localization
기관의 크기가 환자별로 다양할때 성능 좋음
MRI 이미지에서 심장의 좌심실(Left Ventricle)의 위치를 지정하기 위해서
7.3 Fetal abnormalities (태아 이상)
7.3.1 Transfer learning CNN
base CNN의 낮은 layer의 정보 사용, 이미지의 많은 cross domain에서 학습
transfer learning- train 시간을 줄이고, 학습하는데 적은 데이터 이용, overfitting 줄임, 성능 향상
8 Conclusion
- 의료 이미지 class imbalance 문제- positive class가 잘 없고, 주로 모든 이미지들이 normal class에 속하기 때문
=> data augmentation을 사용 - 적합한 CNN architecture 고르는 것, 전처리 방법 중요
- CNN의 크기와 깊이가 클수록 -> 큰 메모리 차지, 계산 비용 증가
