AI
1.[cs23 lec2] Image Classification

idea3은 training set, validation set, 그리고 test set으로 데이터를 쪼개줍니다. 이는 idea1,2와의 차이는 validation set 즉, 검증용을 하나 두고 test set는 실제 돌릴때만 사용을 하는겁니다. idea4는 cross-validation으로 data를 fold들로 쪼개주는 겁니다. 지금 이 예시에서는 ...
2.A2FSeg: Adaptive Multi-modal Fusion Network for Medical Image Segmentation

simple adaptive multi-modal fusion network for brain tumor segmentation
3.Convolutional neural networks in medical image understanding: a survey 논문 리뷰

논문 목표: 의료 영상 이해 분야에서 CNN 및 그 변형의 응용과 방법론에 대한 포괄적인 개요를 제공하는 것
4.MICCAI challenge 2023
brain tumor challenge
5.Deep learning based brain tumor segmentation: a survey 논문 리뷰
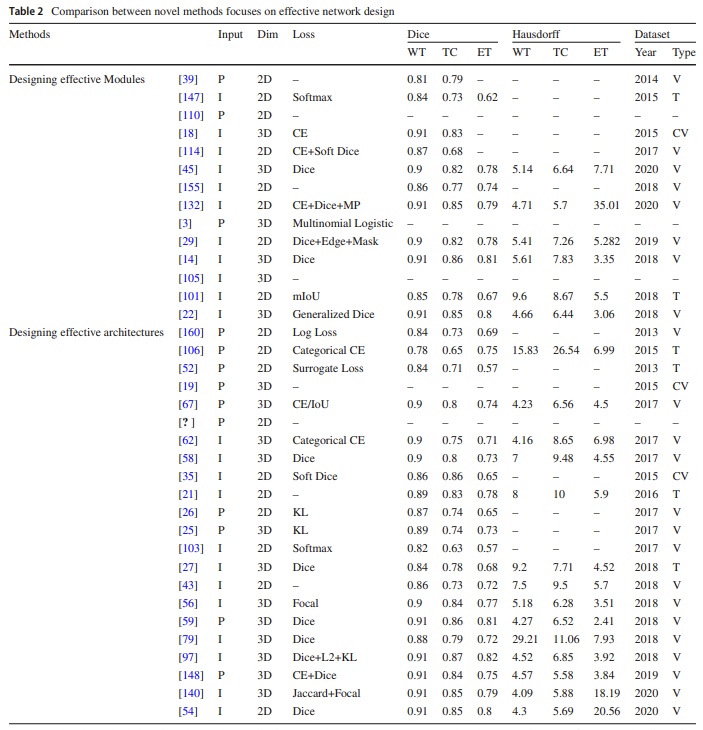
Brain tumor segmentation 뇌 종양 부분에 정확한 경계를 생성 하는 것 MRI 사용 > 한개 이상의 이미지 mo
6.Learning Unified Hyper-Network for Multi-Modal MR Image Synthesis and Tumor Segmentation With Missing Modalities 논문 리뷰
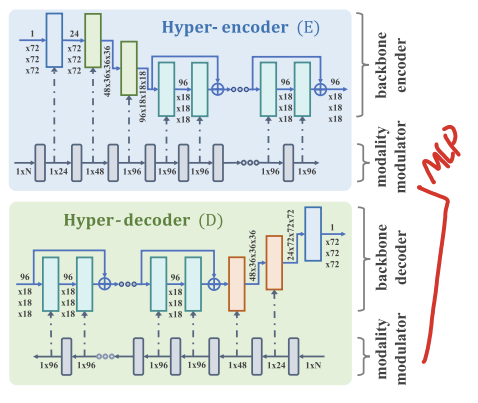
brain segmentation
7.D2-Net: Dual Disentanglement Network for BrainTumor Segmentation With Missing Modalities 논문 리뷰

2022 10월에 나온 논문
8.Ego-Exo4D 논문 리뷰
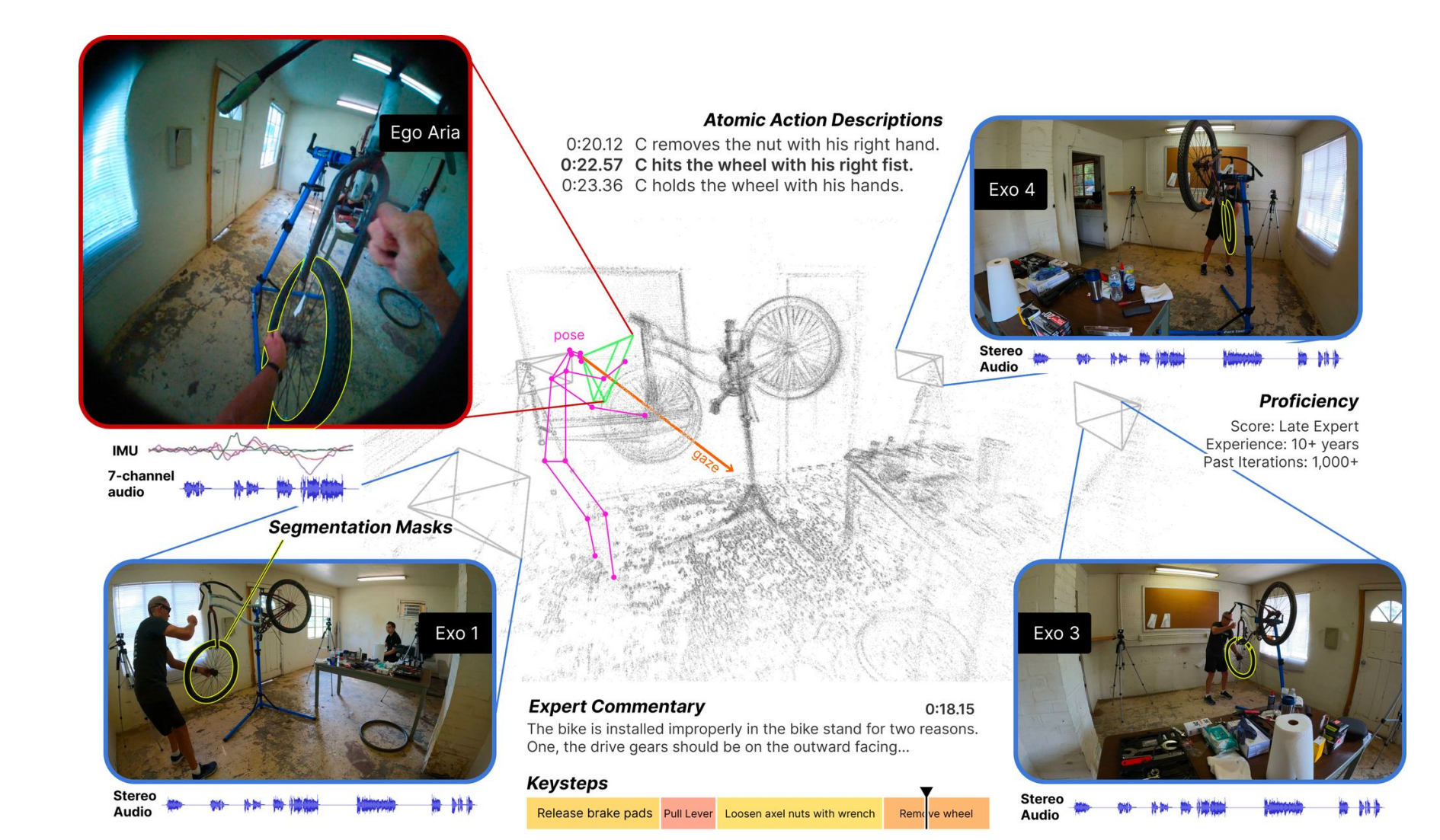
ego-exo 4d 다양하고 대규모인 멀티모달 멀티뷰 비디어 데이터셋
9.NIHSS Score and Arteriographic Findings in Acute Ischemic Stroke 논문 리뷰
NIHSS 점수와 급성 허혈성 뇌졸중에서의 동맥 조영술
10.NIHSS Score 예측
업로드중..
11.The Wisdom of Crowds: Temporal Progressive Attention for Early Action Prediction 논문 리뷰
세부적인 크기에서 점진적으로 샘플링하는 bottleneck-based attention model
12.Learning to See in the Dark 논문 리뷰

low light에서 imaging은 광자수와 SNR이 낮아서 어려움.
13.EnlightenGAN: Deep Light Enhancement Without Paired Supervision 논문 리뷰
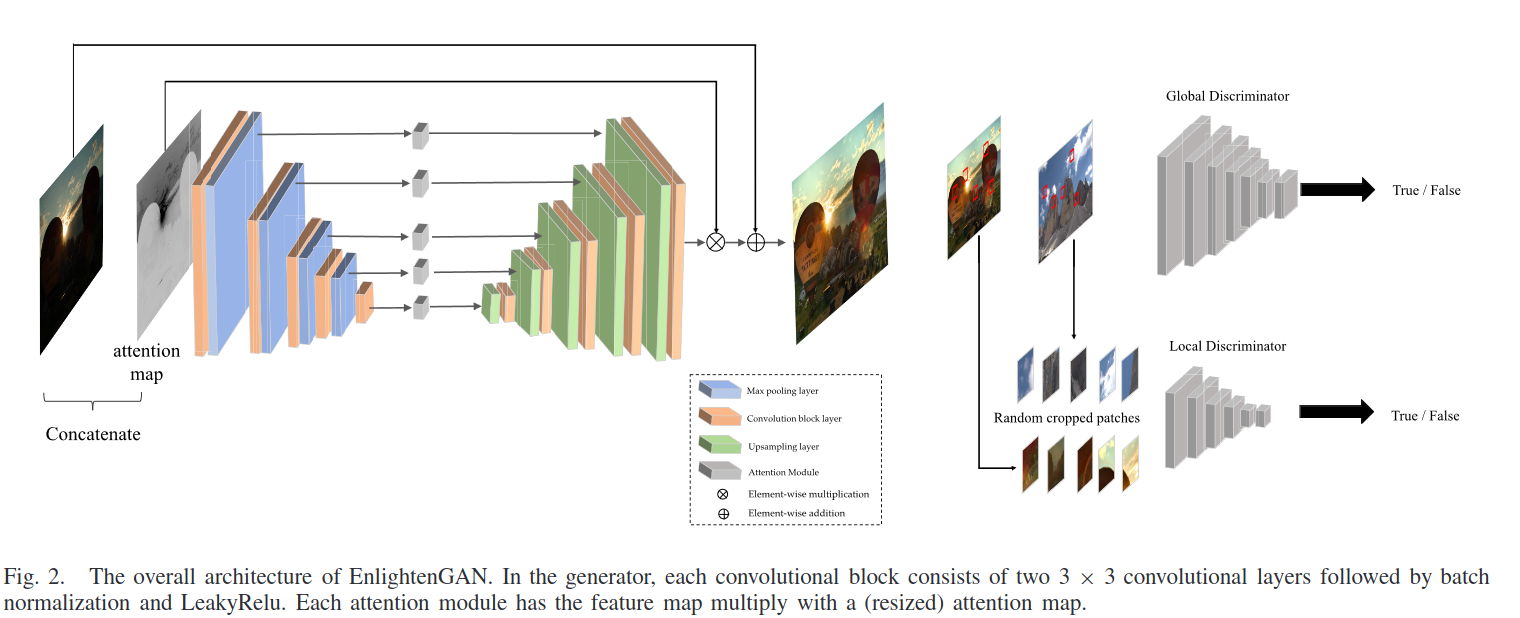
논문 링크
14.SSNet: Synergistic Segmentation of Brain MRI Scans using nnUNetv2 and SAM-track 논문 리뷰
SSNet 모델은 의료 이미지 분할에서 우수한 성능을 보이는 모델인 nnUNetv2와 Foundation model인 SAM-Tracker를 사용하여 구축함.
15.LLNet: A Deep Autoencoder approach to Natural Low-light Image Enhancement 논문 리뷰
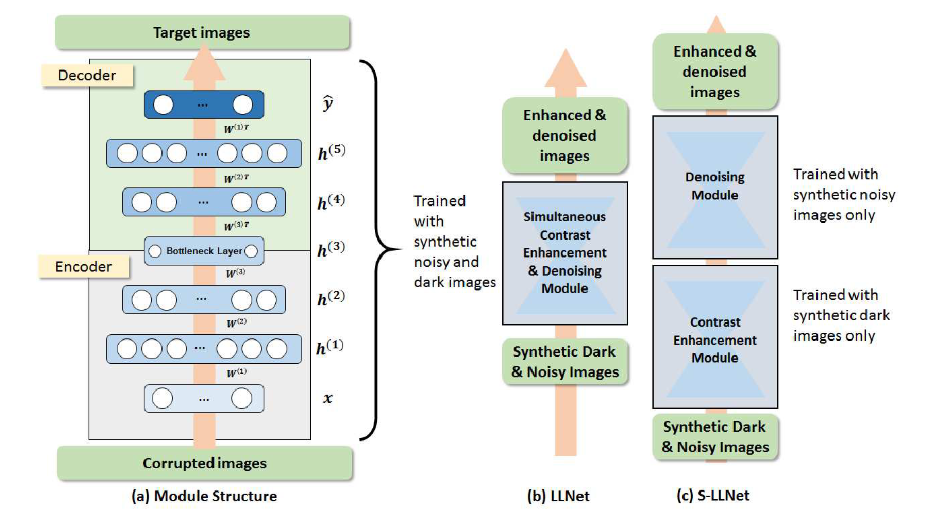
저조도 이미지에서 신호 특징을 식별하고 고조도 범위의 이미지를 과도하게 강조하지 않고 적응적으로 밝히는 autoencoder 기반의 접근 방식을 제안함
16.Low-Light Image Enhancement with Normalizing Flow 논문리뷰
normalizing flow model을 이용하여 저조도 이미지와 정상적으로 노출된 이미지간의 매핑 관계를 일대다 관계로 모델링 하는 것을 제안함
17.[인공지능 응용] Transformer
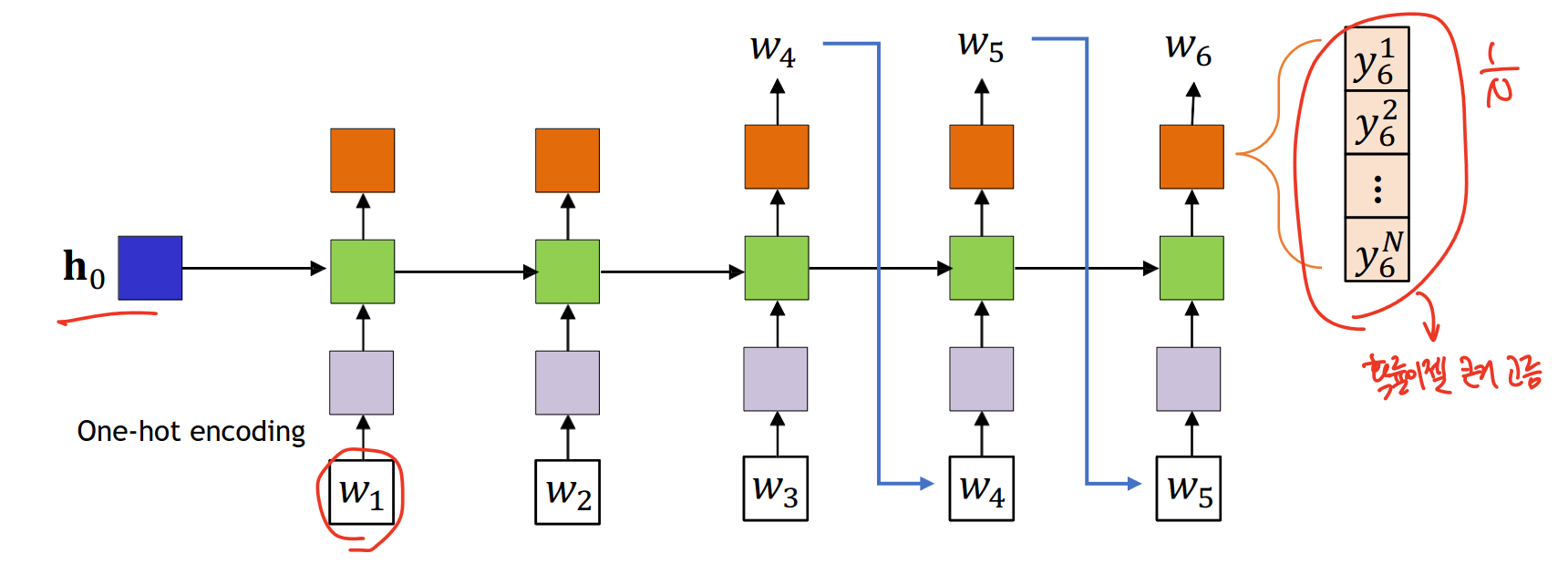
논문 링크 Sequence to Sequence model의 문제점
18.[인공지능 응용] Diffusion
Discriminative model Generative model
19.[인공지능 응용] NeRF
NeRF가 무엇인가? 물체를 찍은 여러장의 이미지를 입력받아 새로운 시점에서의 물체 이미지를 만들어내는 모델
20.[AI] DarkLight

이렇게 resnet101과 resnext101 모델을 돌려야한다. ARID 데이터 셋으로 finetuning을 해야하는데 ARID 데이터셋을 다운받아서 내 서버의 가상환경에 다운로드해주었다.
21.[Video Swin Transformer] 논문 리뷰
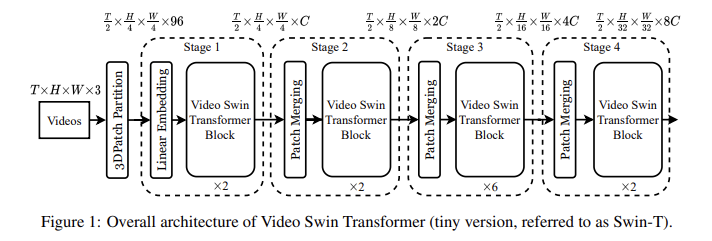
전: 공간-시간 분해를 통해 self attention를 전역적으로 계산하는 방법이 논문: 더 나은 속도, 정확도를 제공하는 비디오 transformer의 지역성 유도 편향을 주장함계속해서 사전 훈련된 이미지 모델의 강점을 활용함이미지 분류를 주로 컨볼루션 신경망 CN
22.Deep Audio-Visual Learning Survey 논문
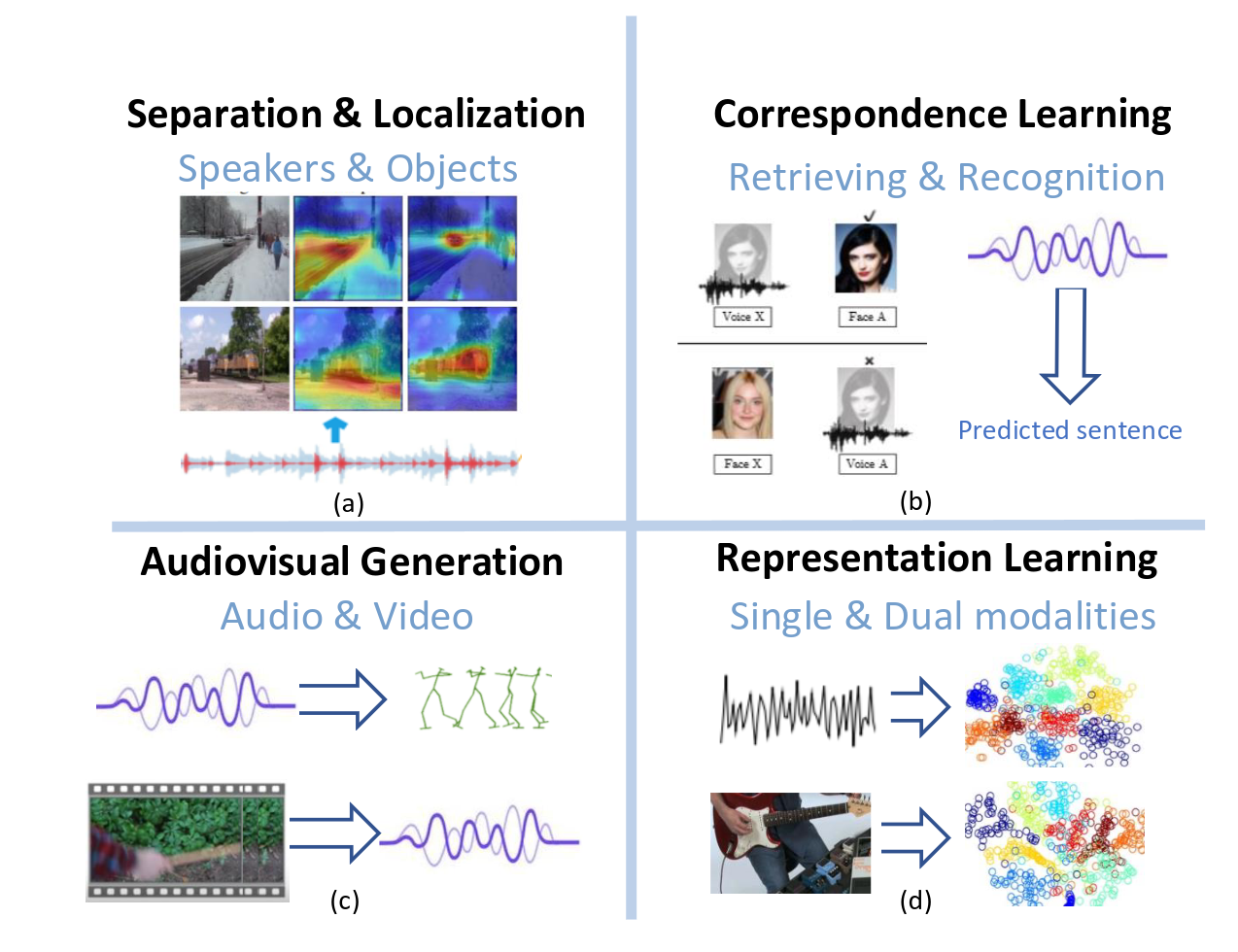
오디오와 비주얼 모달리티 간의 관계를 활용하는 오디오-비주얼 학습이 주목을 받고 있습니다.
23.Audio-Visual Dataset
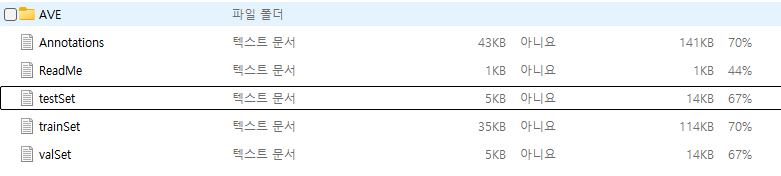
페이지 링크: Audio-Visual Event Localization in Unconstrained Videos=> 이 링크에 있는 데모 영상을 보면 이해가 쉽습니다.AVE 데이터셋을 다운로드 해보니, 이런식으로 trainset, testset, valset, ann
24.데이터셋 다운로드
이번에는 AudioSet을 다운 받아봤습니다.논문링크AudioSet에 대한 논문입니다.
25.Audiovisual Masked Autoencoders
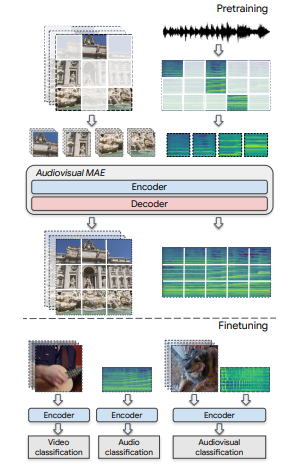
Intro 비디오에 존재하는 오디오비주얼 정보를 활용하여 자기 지도 표현 학습을 개선할 것을 제안합니다. => 오디오비주얼 다운스트림 분류 작업에서 상당한 개선을 달성할 수 있으며, VGGSound와 AudioSet에서 최첨단 성능을 능가함 비디오와 오디오의 상관관계를 활용하여 데이터 표현 학습을 잘하는 것이 목표입니다. masked autoencodin...
26.ICML audio 관련 논문 정리
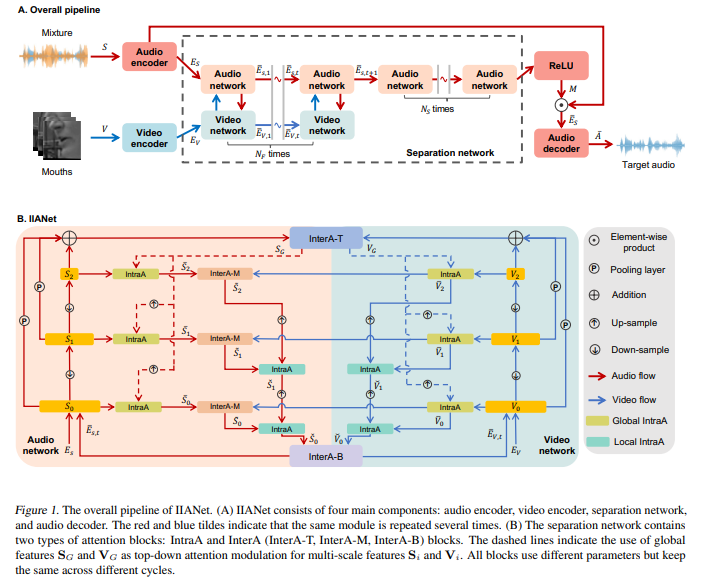
audio-video
27.CVPR 논문 리스트들

HOI는 다수의 인간과 다수의 객체와의 상호작용을 모델링하는 것 이를 위한 데이터셋으로HOI-M3도 있음, 3D추적을 정확하게 제공하며 여러 인간과 객체를 다룬다.
28.ActionFormer: Localizing Moments of Actions with Transformers 논문 리뷰
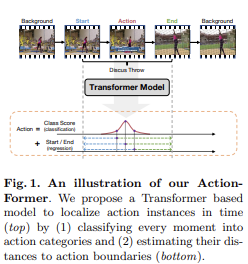
논문 링크ActionFormer:트랜스포머 네트워크를 비디오에서의 Temporal Action Localization(TAL)에 적용하는 모델임(TAL은 시간 내의 액션을 식별하고 그 카테고리를 단일 샷으로 인식하는 것)
29.AVSegFormer: Audio-Visual Segmentation with Transformer 논문 리뷰
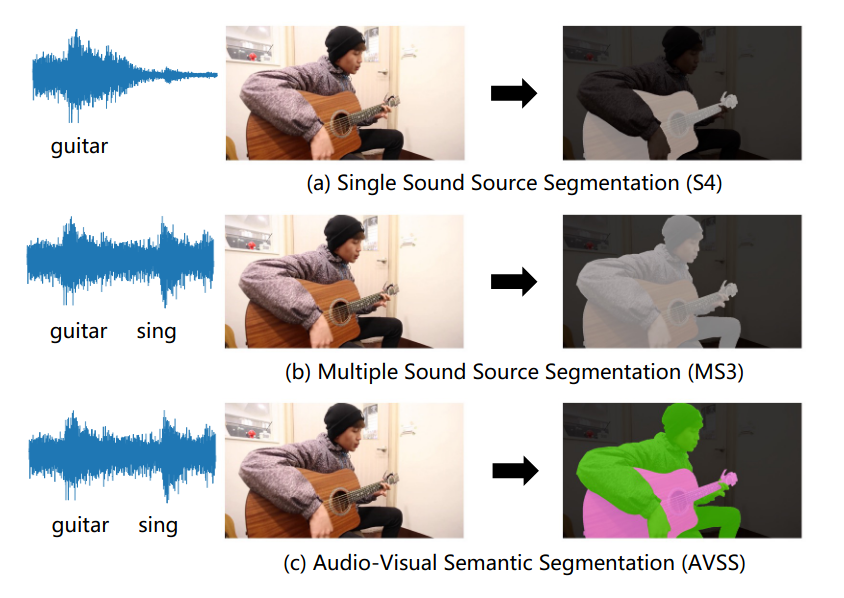
AVSegFormer 논문 링크Audio-visual segmentation(AVS)는 주어진 비디오에서 소리 나는 물체의 위치를 찾아내고 분할 하는 것을 목표로 함하지만 대부분의 방법들은 여러 상황에 세밀한 상관 관계를 동적으로 잘 처리하지 못한다. AVSegForm
30.Audio-Visual grounding 정리
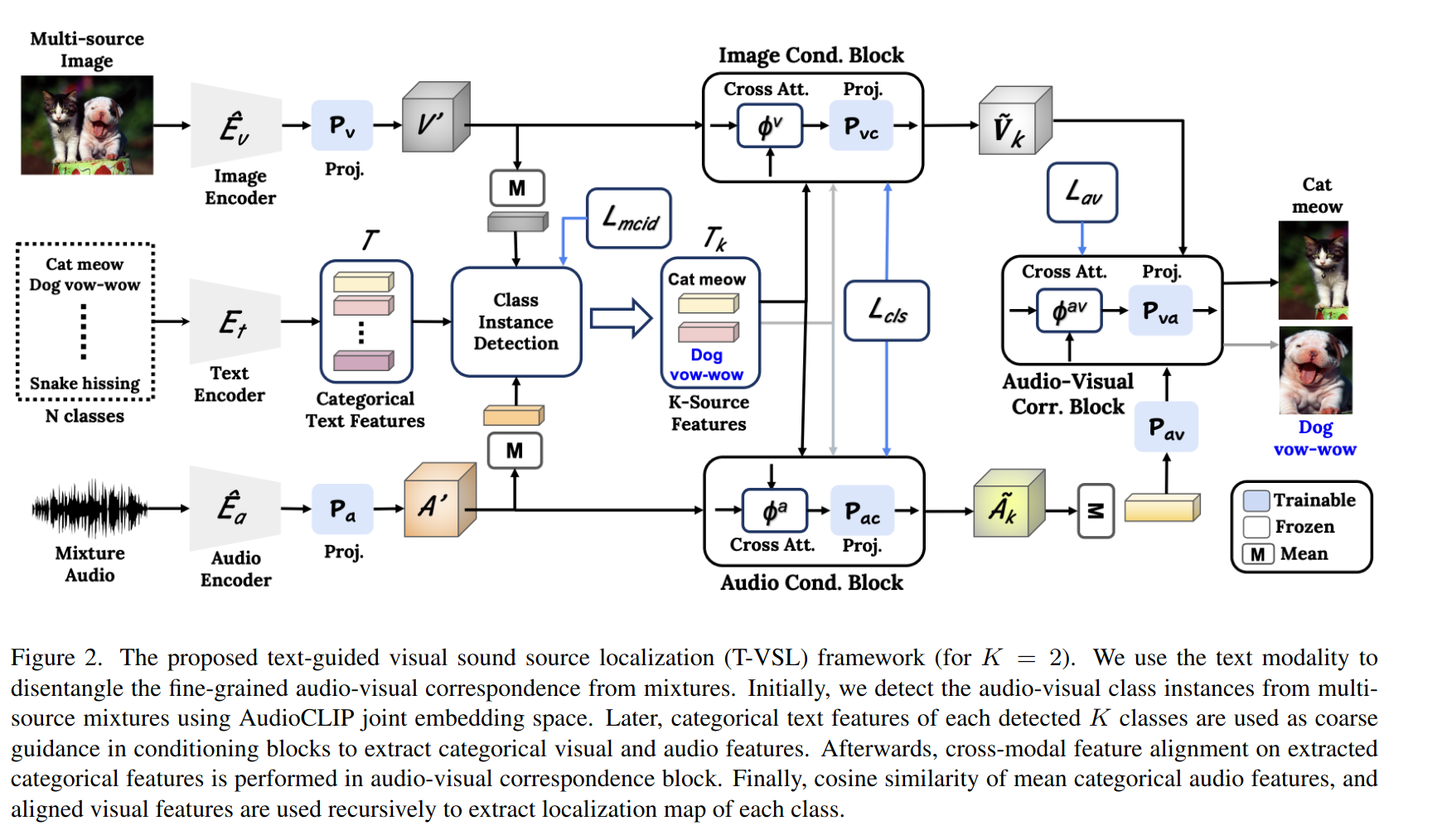
Separating the "Chirp" from the "Chat" 논문 링크T-VSL 논문 링크MIMOSA 논문 링크소리와 영상 간의 관계(audio-visual correspondence)를 이용하는데, 여러 소리가 섞이면 성능이 저하되어 각 소리가 나는 물체의
31.미팅 3
multisource의 논문들 independent하게도 어려운데 dependent하게 해보자 비슷한 논문 있는지 찾아볼 것 (손뼉이 마주쳐야지 소리가 남- 관계에 초점) Audio clip의 소리 annotation이 뭔지(물체 그 자체인 지, 확장된 단어인 지) a
32.Sound 관련 논문 리뷰
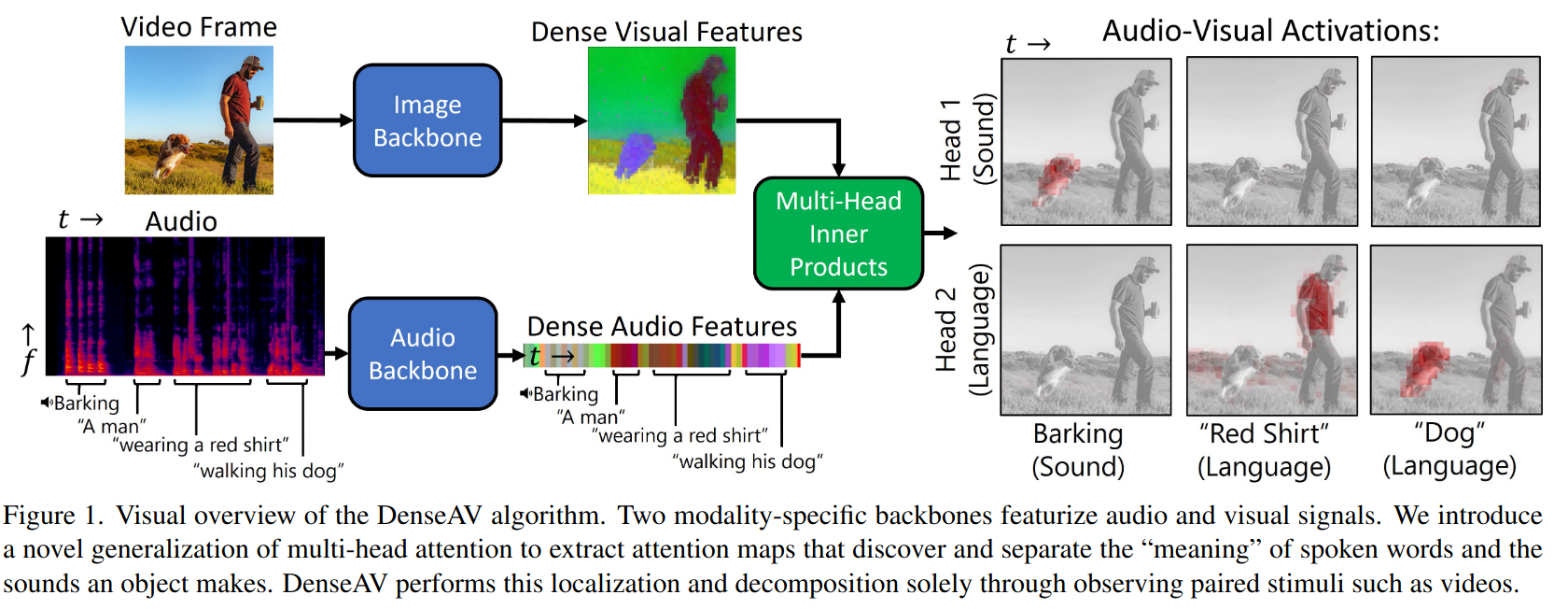
CVPR 2024/ ECCV 2024