2022 10월에 나온 논문
Introduction
missing modalities를 해결하는 방법은 총 3가지로 나눠진다.
- Multi-modal fusion based algorithms: 모든 사용 가능한 모달리티 세트로만 특성을 학습,구현 쉬움, 누락된 모달리티 데이터에서의 잠재적인 상관관계 정보를 무시
- Modality generation based methods: 생성 모델을 사용하여 누락된 모달리티를 합성(GAN)한 다음 모델 최적화에 완전한 모달리티를 활용, 데이터를 합성하는 데 제한 있음
- Shared knowledge extraction: 직접 MRI 이미지를 합성하는 대신 내재된 다중 모달 특성 또는 통계 정보 사이의 상관 관계를 학습하여 뇌 종양 세그멘테이션을 위한 공유된 표현을 추출, 추출된 공유 특징을 이용하면 일부 모달리티가 누락되더라도 잘 수행, 모달리티별 특징 제거
하지만 다중 모달 특성 간의 상관 관계를 포착하기 어려움
=> 모달리티 간의 정보를 명시적으로 포착하기 위해 spatial-frequency jointly modality contrastive (SFMC) learning scheme를 제안 (MD stage에서)
(전에는 공간만 쓰거나, 주파수 도메인만 쓰거나, 독립적 기능을 분리했지만 성능이 부족함)
이 스키마는 self-supervised learning으로 공간 및 주파수 도메인을 모두 사용하여 모달리티별 정보에 대한 명시적으로 나타내기 가능. 누락된 모달리티 상황에 모달리티 불변 내용 보존 가능
Dual disentanglement framework(D2net) consisting of the MD-Stage and TD-Stage
MD-Stage: 모달리티별 정보 분리, 이용
TD-Stage: MRI 모달리티와 관련이 없는 분리된 종양 특정 지식을 생성
Disentanglement Representation learning
주로 비지도 학습에서 연구 되어 옴
1. GAN
GAN 모델을 활용하여 잠재 공간에서 정보를 모델링하는 것, 단점: 수렴 어렵고 하이퍼파라미터에 민감함
2. encoder-decoder framework 기반으로 독립된 잠재변수 학습
ex. Variational Auto-Encoder (VAE)
=> 둘다 명시적인 지도가 부족하며 성능이 안 좋음
Method
이중해체 네트워크 D2-Net을 제안함, 모달리티별 정보 해체 단계 (MD-Stage)와 종양별 영역 해체 단계 (TD-Stage)로 구성되어 있음

- MD-Stage(Modality Disentanglement Stage): 모달리티별 코드를 해체하기 위해 SFMC 학습 방법 제안, 인코더를 사용해서 종양 특징 얻음
a. SFMC (spatial modality contrastive learning 공간 모달리티 대조학습)
주파수 이용해서 동일 모달리티에서 얻은 코드는 유사하게 다른 모달리티에서 얻은 코드는 구별되게 함
b. Tumor Modality Transfer network
모달리티 간의 상관관계를 식별하고 모델이 모달리티별 정보를 캡처해서 일부 모달리티가 누락되어도 성능 향상, 종양 특정 코드를 사용해서 분할할 때 종양 특정 기능 생성 가능
- TD-Stage (Tumor-Region Disentanglement Stage): 종양 특정 기능을 분리하고 이를 이용해서 종합적인 기능을 얻는 것이 목표
a. Decoding for Tumor-Region Segmentation
b. ADT-KD(Attention-based Distillation with Tumor-aware Knowledge Distillation)
attention을 활용해서 선생 모델로부터 종양 관련 지식을 학생모델에게 효과적으로 전달하는 기술, 분할 작업에서 성능 향상
Experiments
Dataset and preprocessing
2018 brats 데이터셋 사용, 모달리티: FLAIR, T1, T1ce, T2
분할 성능 평가: WT (배경을 제외한 모든 영역의 합), TC (네크로틱, 비강화 및 강화 종양의 합), ET (강화 종양) 영역
train: 190개, validation: 95개, 3개의 fold로 cross validation 함
결과
랜덤으로 입력 모달리티 삭제하면서 end-to-end 방식으로 train
WT, TC, ET에 대한 평균 Dice score에서 76.2%, 66.5%, 42.3%의 최고 성능을 달성
여러 모달리티들이 누락되어도 성능이 좋음
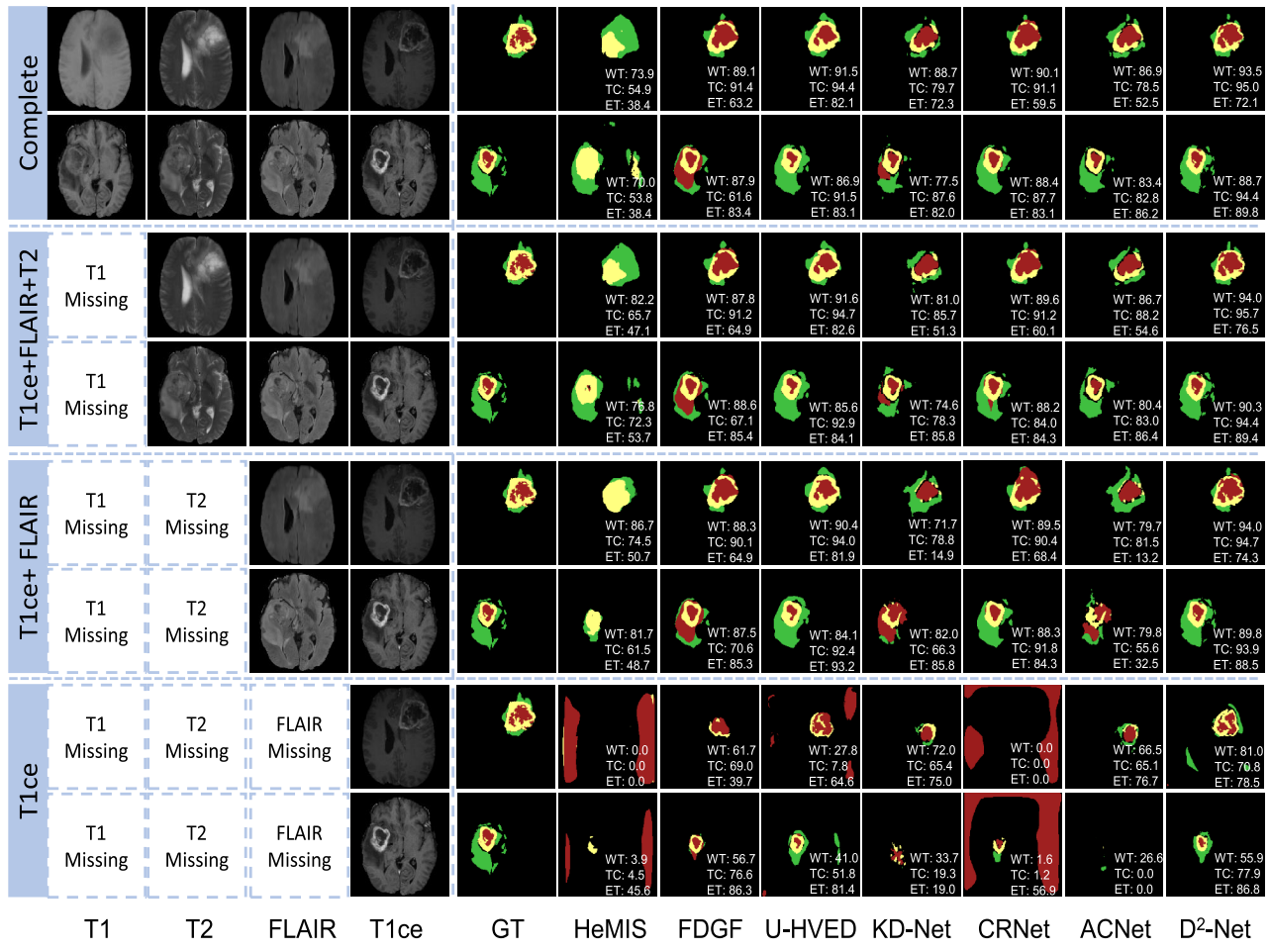
D2-Net이 주로 T1ce 모달리티에 의존하므로 T1ce 모달리티가 누락되면 성능이 안
좋을수도 있음.
