Brain tumor segmentation
뇌 종양 부분에 정확한 경계를 생성 하는 것
위치, 형태 불확실성, 낮은 대조 영상, 데이터 불균형의 문제가 있음
글리오마(Glioma)- 글리아(glial) 세포에서 기원한 뇌종양
MRI 사용
한개 이상의 이미지 modality의 입력 이미지-> 종양부분을 자동으로 분할->segmentation map 반환
- gadolinium enhancing tumor-조영제 투여하여 찍힌 종양
- pertumoral edema-종양 주위의 부종
- non-enhancing tumor core-조영제 투여 안하여 찍힌 종양의 core

이 survey 논문은 deep convolutional neural network 강조, 불균형 조건에서의 분할 및 다중 모달리티에서의 학습과 같은 다른 중요한 학습 전략은 언급하지 안함
Background
Challenges
- 위치 불확실성 - 글리오마는 신경세포를 둘러싼 점액 세포에서 변이되므로 정확한 위치를 찾기가 어렵다.
- 형태 불확실성 - 다양한 뇌종양의 모양 및 크기와 같은 형태학적 특성은 큰 불확실성, 종양의 바깥 층은 유체 구조
- 낮은 대비 - image projection and tomography process으로 인해 mri 이미지가 품질과대비가 낮음
- 주석 편향(Annonatation bias) - 개인의 경험에 의존성이 커서 데이터 라벨링 과정중에 주석을 다는 것이 편향될 수 있음
- 불균형 문제
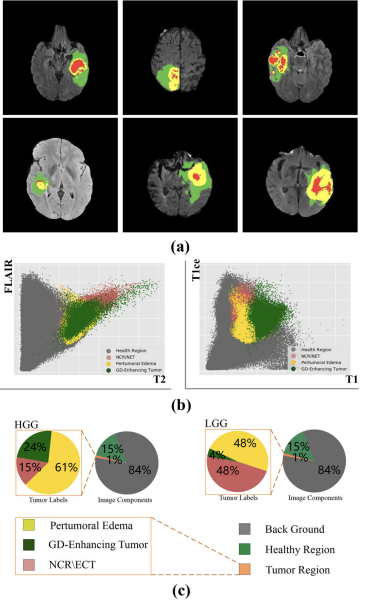
서로 다른 종양 영역에는 불균형한 수의 복셀
Progress
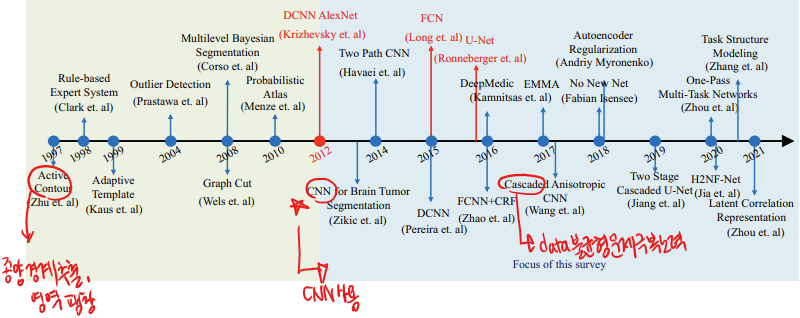
-
90년대 후반 - Hopfield Neural Network with active contours를 사용하여 종양 경계를 추출하고 종양 영역을 팽창
-
그 이후 - 전통적인 기계 학습 알고리즘 사용, 한계 있음
- 전체 종양 영역의 분할에만 중점을 둬서 분할 결과에는 하나의 범주만 존재
- 수동으로 설계된 feature engineering은 사전 지식에 의해 제한되어 완전히 일반화 불가능 3. 모양 불확실성과 데이터 불균형과 같은 어려움에 대응하지 못함
-
2012년 이후부터 - deep neural network를 사용해서 DCNN, FCN, U-Net 구축
-
2017년 이후부터 - data imbalance문제 극복하려고 많은 시도를 함
-
최근 연구 - modality fusion과 modality 누락 처리에 중점
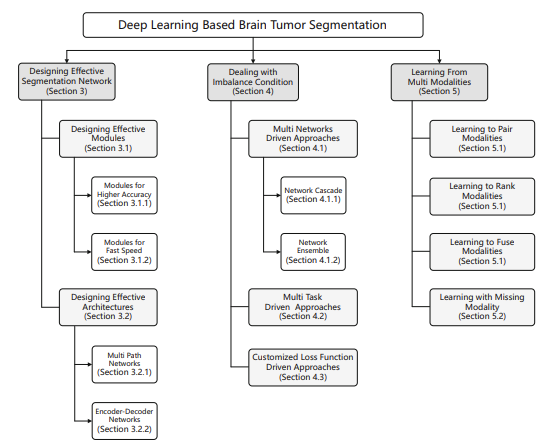
Designing effective segmentation networks
- designing effective modules: 1. high level semantic을 학습하고 타겟 localize하기, 2. 네트워크 매개변수 양을 줄여서 train 속도를 높여 계산 시간과 자원을 절약하는 것
- designing network architecture: simple-channel network->multi-channel network, fully connected layers->fully convolutional network, simple network-> deep cascaded network로 (feature learning 능력 향상, 더 정확하게 분할 하기 위해)
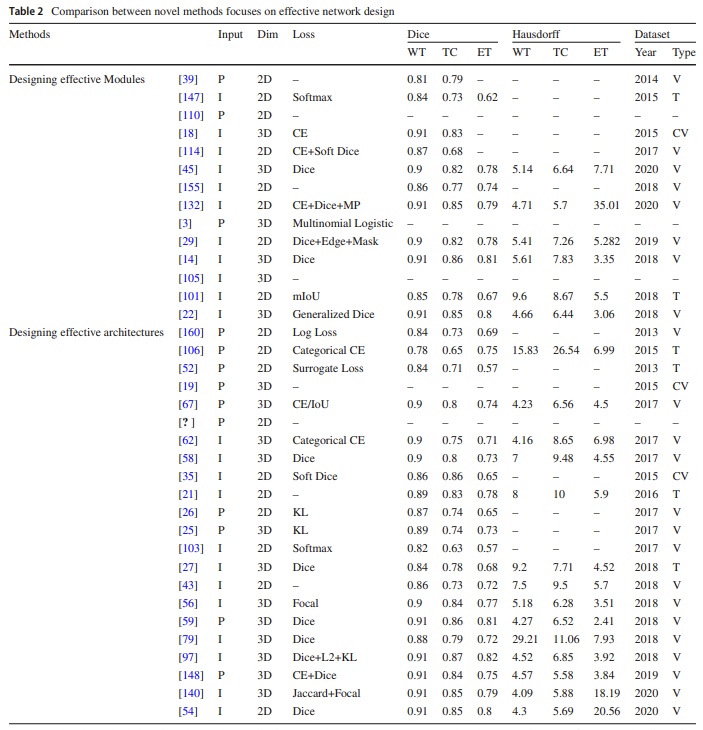
Designing specialized modules
- Modules for higher accuracy
- AlexNet 같은 구조를 쓰다가 convolutional block을 쌓으면서 네트워크의 깊이를 늘리는 방식 (convolutional layer을 많이 쌓으면 파라미터를 늘리게 되고 세부 정보를 잘 포착)
커널의 크기를 5이상 -> 3으로 줄임 or 다양한 크기의 커널 사용
문제 = 쌓은 레이어의 수가 증가함에 따라 네트워크가 깊어지면 훈련 과정에서 gradient explosion, vanishing 문제-찾아보기!!! - Resnet- residual connection을 도입 (컨볼루션 모듈의 입력을 출력에 추가하여 gradient 문제를 해결)
문제 = 공간 해상도가 낮은 문제 있음
+DenseNet- residual connection-> dense connection으로 (계산 메모리를 많이 쓰는 단점 있음) - standard convolutional layer-> dilated convolutional layer로 바꿈
장점: 1. 추가 parameter를 도입하지 않고 수용 영역을 확장, 2. 공간 해상도 손실 줄임
따라서 분할 할 객체의 위치를 원래 입력 공간에서 정확하게 localization 가능
but 작은 구조물의 잘못된 위치 및 분할 문제는 아직 해결되어야 함
=> multi-scale 팽창 convolution 또는 atrous 공간 피라미드 풀링 모듈을 설계하여 객체의 세세한 세부 사항을 묘사하는 semantic 컨텍스트를 캡처하도록 제안
- Modules for efficient computation
복잡한 모듈을 설계하면 정확한 세그멘테이션을 달성할 수 있지만, 계산 자원 많이 필요, 학습 시간이 김 => 모듈 설계에서 light weight idea를 생각함
-
입력 데이터를 재배열하여 (6도 회전된 데이터 샘플) 시각적 유사성이 높은 샘플이 메모리에서 더 가까이 배치해서 I/O 통신을 가속화 시도.
-
입력 데이터를 다루는 대신에 계산 비용을 줄이기 위해 다운샘플링 채널이 감소된 U-Net 변형함
=> 이 두 방법은 계산자원이 줄었지만, 학습 정보를 잃고 정확도 감소함 -
U-Net에 reversible block 추가 -> 가역 블록을 사용하면 역전파 중에 필요한 정보를 직전 레이어의 출력에서 직접 가져와 사용하기 때문에 중간 결과를 별도로 저장할 필요가 없음, 메모리 줄어듦
-
MBConvBlock(Mobile Reversible Convolution Block)-가역 블록을 더 확장
Designing effective architectures
- Multi-path architecture
다중 경로 네트워크는 서로 다른 규모의 다양한 경로에서 다른 특징을 추출할 수 있음
large scale path= global 특징을 잘 학습, small scale path = local 특징을 잘 학습
-
Havaei - 다양한 kernel 사이즈 사용, local pathway:7x7 convolutional kernel, global pathway:13x13 kernel
-
Castillo - 다양한 patch 사이즈 사용, 3 pathway CNN- low (15 × 15), medium(17 × 17), normal (27 × 27) resolutions
-
Kamnitsas - 입력에서 patch의 다른 사이즈를 고려하는 이중 경로 network 사용
=>최근에는 multi-scale CNN 추세
- Encoder–decoder architecture
patch로만 매핑을 정확하게 하는건 어려움
문제 1. 단일 및 다중 경로 네트워크의 세그멘테이션 성능은 입력 패치의 크기와 품질에 영향 많이 받음 2. 특징-레이블 매핑은 대부분 마지막 fully connected layer에 의해 수행, fully connected layer는 특징을 완전히 표현 불가능, 비용 증가
=> 최근에는 encoder-decoder network 사용
-
Jesson - multi scale loss function을 사용해서 standard FCN 확장함
FCN의 한계: 레이블 도메인의 컨텍스트를 명시적으로 모델링하지 않음 -
boundary aware fully convolutional neural network
목표: 전체 종양의 경계 정보를 이진 분류 문제로 학습하고 모델링하는 것 -
U-Net - FCN의 중요한 변형, 특징을 캡처하기 위한 수축 경로와 정확한 localization을 가능하게 하는 대칭 확장 경로로 구성
장점: 전통적인 FCN에 비해 수축 및 확장 경로 간의 skip connection (skip connection은 수축 경로-> 확장 경로로 특징 맵을 전달하고 두 경로의 특징 맵을 직접 연결, 원래 이미지 데이터는 수축 경로의 레이어에 세부 정보를 복원하는 데 도움을 줌) -
V-Net - 수정된 3D 버전의 U-Net, 원래 볼륨 데이터에서 정보를 추출하기 위해 customized Dice coefficient 손실 함수 사용
Segmentation under imbalanced condition
불균형 -> 뇌 종양의 하위 영역의 픽셀 수, 환자 샘플 수 (HGG (High-Grade Glioma: 빠르게 성장하는 치명적인 악성 종양) 사례의 수가 LGG (Low-Grade Glioma: 느리게 성장하는 덜 악성 종양) 사례보다 훨씬 많음)
전문가들에 의해 도입된 레이블 편향도 존재
Multi-network driven approaches
Multi-network system은 두가지로 나뉨
1. Network cascade
- 정의: 연속적으로 연결된 네트워크에서 상류 (upstream) 네트워크의 출력이 하류 (downstream) 네트워크로 입력으로 전달되는 것
- 구조: 특징을 추출하는 상류 네트워크, 입력을 세분화하고 미세 구분 분할하는 하류 네트워크
- 예시: WNet->TNet->ENet
Whole Tumor를 분할하는 WNet이 Whole Tumor의 segmentation 결과를 TNet에 전달하고, TNet은 Tumor Core를 분할, TNet의 세그멘테이션 결과는 Enhancing Tumor의 세그멘테이션을 위해 ENet에 전달
한계: 불균형 데이터로 인한 간섭을 피할 수 있는 장점이 있지만, 상류 네트워크의 성능에 많이 의존함. 상류 결과를 하류의 입력으로 쓰여서 다른 이미지 영역을 보조 정보로 사용할 수 없어 종양 위치 감지와 같은 다른 작업에는 적합하지 않을 수 있음
- Network ensemble
- 기존 single deep neural network의 단점: 성능이 hyperparameter 선택에 매우 영향을 받는다는 것
- 정의: 여러 네트워크의 세그멘테이션 출력을 합치는 것
- 장점: 여러 네트워크를 합칠때 훈련할 매개변수의 가설 공간을 확장하고 (여러 모델의 함수를 고려할 수 있어 더 견고함) 데이터 불균형으로 인한 성능 저하도 개선 가능
- 예시: Ensembles of multiple models and architectures (EMMA)- DeepMedic, FCN, U-Net의 세그멘테이션 결과를 앙상블하고 최종 세그멘테이션을 가장 높은 신뢰 점수로 결과 나타냄
=> ensemble은 다양한 네트워크에서 결과를 집계하여 최종 세그멘테이션 결과를 향상시키기 위한 부스팅 전략, BraTS2018 우승자는 10개의 모델을 앙상블하여 최고의 단일 네트워크 세그멘테이션과 비교하여 성능을 1%를 추가로 향상함
Multi-task driven approaches
- 기존 단일 작업 학습의 단점: 단일 작업의 train 목표가 어떤 task에서의 잠재적 정보를 무시할 수 있음
- 주요 설정: 여러 task 간에 공유될 수 있는 low level feature 표현
- 장점: 1. 서로 관련된 도메인 정보를 공유하여 학습을 촉진, 업데이트된 정보를 잘 획득 2. mutual restraint(상호 제한성)- 동시에 여러 작업을 학습하는 모델은 더 일반적인 표현을 학습하여 overfitting의 위험을 줄이고 시스템의 일반화 능력 향상
- 예시: 1. brain tumor segmentation task를 3가지 sub-region task로 나눠서 학습, 3가지의 다른 loss 함수 사용하는 방식 2. 입력 데이터를 재구성하는 것. 인코딩된 특성은 보조 디코더를 사용하여 원래 입력으로 복원 가능
Customized loss function driven approaches
- 기존 단점: 많이 imbalance한 데이터 셋에서는 학습중의 기울기가 dominate한 경우(=적은 클래스에 대한 기울기가 반영 되지 않는 경우)가 많음
기울기를 조절하기 위해 customized loss function(사용자 정의 손실 함수)를 제안함 - 예시: 1. 손실 함수를 살짝 바꿔 가장자리 픽셀에 더 많은 가중치를 부여함, 2. 학습된 특성이 공간 정보를 최대한 유지할 수 있도록 공간 손실 함수를 설계함, 3. 균형 문제에 대응하기 위해 focal 손실을 사용함, 이 외에도 combination loss set (cross-entropy + soft dice loss) 사용
Utilizing multi modality information
MRI의 다양한 modality는 각기 다른 조직에 중점을 둠
사용 가능한 모달리티의 완전성에 대해 2가지로 나뉠수 있음
Learning with multiple modalities
Brats challenge에는 다중 모달리티 세트로 T1, T1ce, T2 및 Flair과 같은 입력 데이터 모달리티를 포함
다중 모달리티 학습 방법의 목적은 3가지로 나뉨
1. Learning to Rank-관련성에 따라 정렬되어 높은 관련성을 가진 모달리티를 학습 하는 것, modality-task modeling으로도 불림, 각 모달리티를 단일 CNN으로 변환해서 추출 결과도 독립적, 최종 반환된 손실은 입력 데이터의 scoring과 유사하며 스코어에 따라 세그멘테이션이 수행
2. Learning to Pair- modality-modality pairing: 모든 두 모달리티를 페어링하고 모든 페어링 조합을 다운스트림 네트워크로 보냄, 정확한 세그멘테이션을 달성하기 위해 최적의 조합을 선택
3. Learning to Fuse- 최근 연구들은 fuse에 집중, 앞선 두개와 다르게 정확한 세그멘테이션을 위해 각 모달리티에서 추출된 feature를 fuse, 공간 및 채널 attention을 기반으로 한 퓨전 모듈을 사용, attention 메커니즘은 유용한 feature를 강조하고 중복되는 feature를 억제하여 정확한 segmentation함
Dealing with missing modalities
실제로는 완전하고 고품질의 다중 모달리티 데이터셋을 획득하는 것이 매우 어려운 경우가 많음
- T1 모달리티를 입력으로 사용하여 Flair 모달리티를 생성, 생성된 Flair 데이터는 원래 T1 데이터와 함께 downstream segmentation 네트워크에 전달
- 단일 모달리티 입력의 다양한 시나리오에 대한 강도 보정 알고리즘 제안. 이를 통해 합성 데이터에서 종양 및 비종양 영역을 분할 더 쉬움
Future trends
- Self, weak and semi-supervised training with fewer labels
- Neural architecture search based segmentation-도메인 지식 (종양 정도, 종양 형태)을 신경 아키텍처 검색 알고리즘과 결합
- Protect patient’s privacy- 환자의 개인 정보를 보호하기 위한 개인 정보 보호 학습 framework
