1. Separating the “Chirp” from the “Chat”:Self-supervised Visual Grounding of Sound and Language
Abstract
DenseAV라는 dual encoder grounding architecture
DenseAV는 동영상 시청만으로 고해상도의 semantically 의미 있는 오디오 비주얼 특징을 학습함,
명시적인 위치를 지정하지 않고도 단어의 의미와 소리의 위치를 발견할 수 있음,
두 유형의 연관성을 자동으로 발견하고 구별함
=> 파라미터를 반보다 적게 쓰면서도 sota(ImageBind)를 능가함, semantic segmentation 능력 향상함
Introduction
multimodal association
음성/소리를 각각 시각적 객체와 연결함으로써 grounding하는 것(음성 신호의 단어 "dog"와 짖는 소리 <=> 시각 신호에서 개의 픽셀과 연관되어야 함)
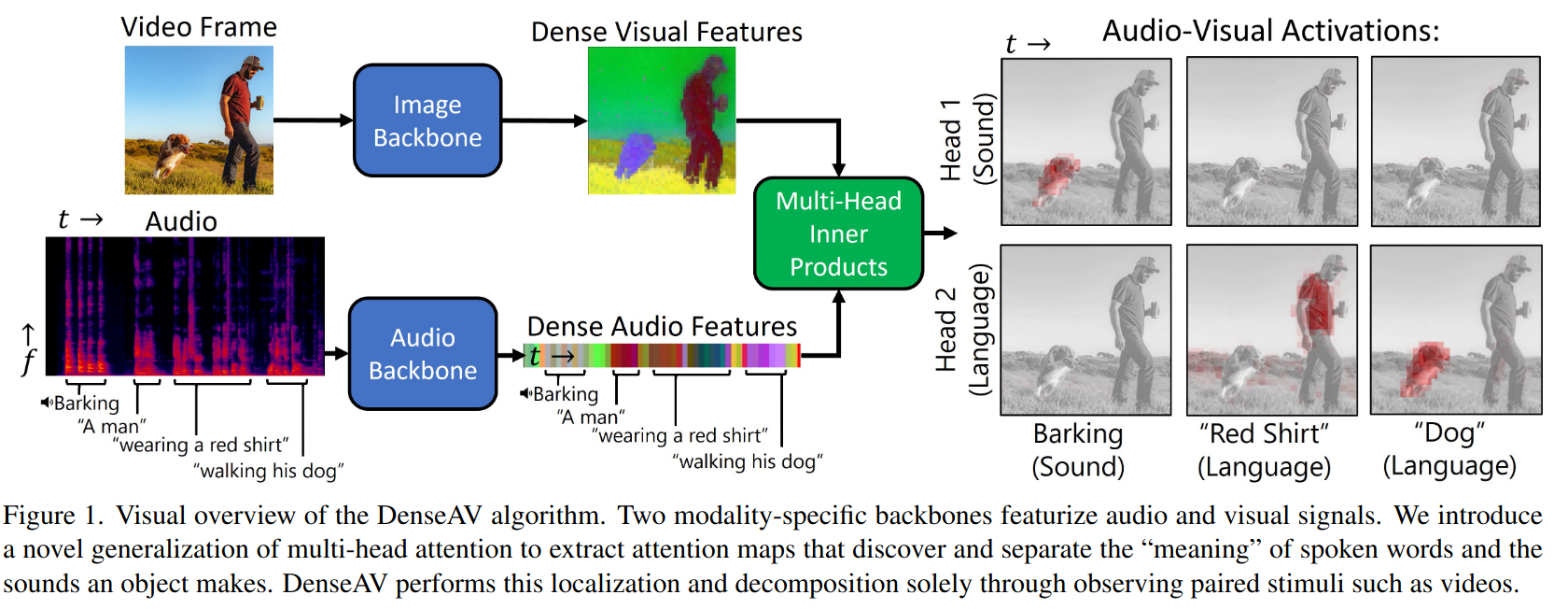
기여점
-
DenseAV라는 이중 인코더 아키텍처로, 오디오와 시각적 특징 사이의 밀집 유사도 볼륨(dense similarity volume)을 계산함
(Fig 1) 이 유사도 볼륨을 통해 한 단어에 대한 시각적-음성적 활성화 강도를 시각화할 수 있음
밀집 유사도 메커니즘-> 여러개의 유사도 볼륨 헤드로 확장한 것
=> DenseAV에 두 개의 헤드를 부여하고 언어와 소리를 포함하는 데이터셋으로 학습시키면 헤드들이 언어와 소리를 구분할 수 있음
head 1- 보이는 물체에서 나오는 개 짖는 '소리'에 집중
head 2- 보이는 물체를 지칭하는 '개'라는 단어에 집중 -
오디오 클립과 비디오 프레임 사이의 요약 유사도 점수를 생성할 때 사용하는 "집계함수(aggregation function)"의 중요성을 강조함
-
새로운 데이터셋 for evaluating speech and sound
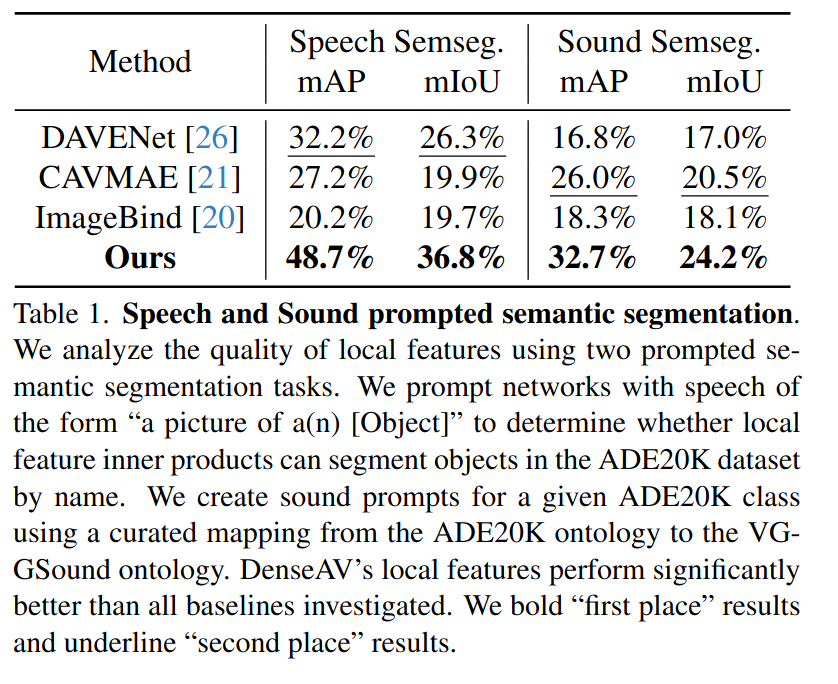
ADE20K 데이터셋의 고품질 분할 mask를 기반으로 데이터셋을 구축하고 binary mask 예측 작업에서 mAP(평균 정밀도_mean average precision)와 mIoU(평균 교차 합집합_mean intersection over union)를 측정함
(다른 방법들 보다 훨씬 단순한 방법임)
Methods
DenseAV는 모달리티 간의 상호 정보를 포착하는 밀집된 모달리티별 특징을 학습하게 된다.
DenseAV는 두가지 모달리티별 깊은 특징 추출기로 구성된다.
Audio Backbone: 오디오 클립에서 시간적으로 변화하는 오디오 특징, Image Backbone: 임의로 선택된 한 프레임에서 공간적으로 변화하는 비디오 특징을 생성함
1. Multi-Headed Aggregation of Similarities(유사성의 다중 헤드 집합)
DenseAV의 주요 차별점은 시각 및 오디오의 특징 추출기의 "지역" 토큰을 직접 감독하는 손실함수라는 것이다.(다른 연구에서는 전역 정보를 한번에 비교함)
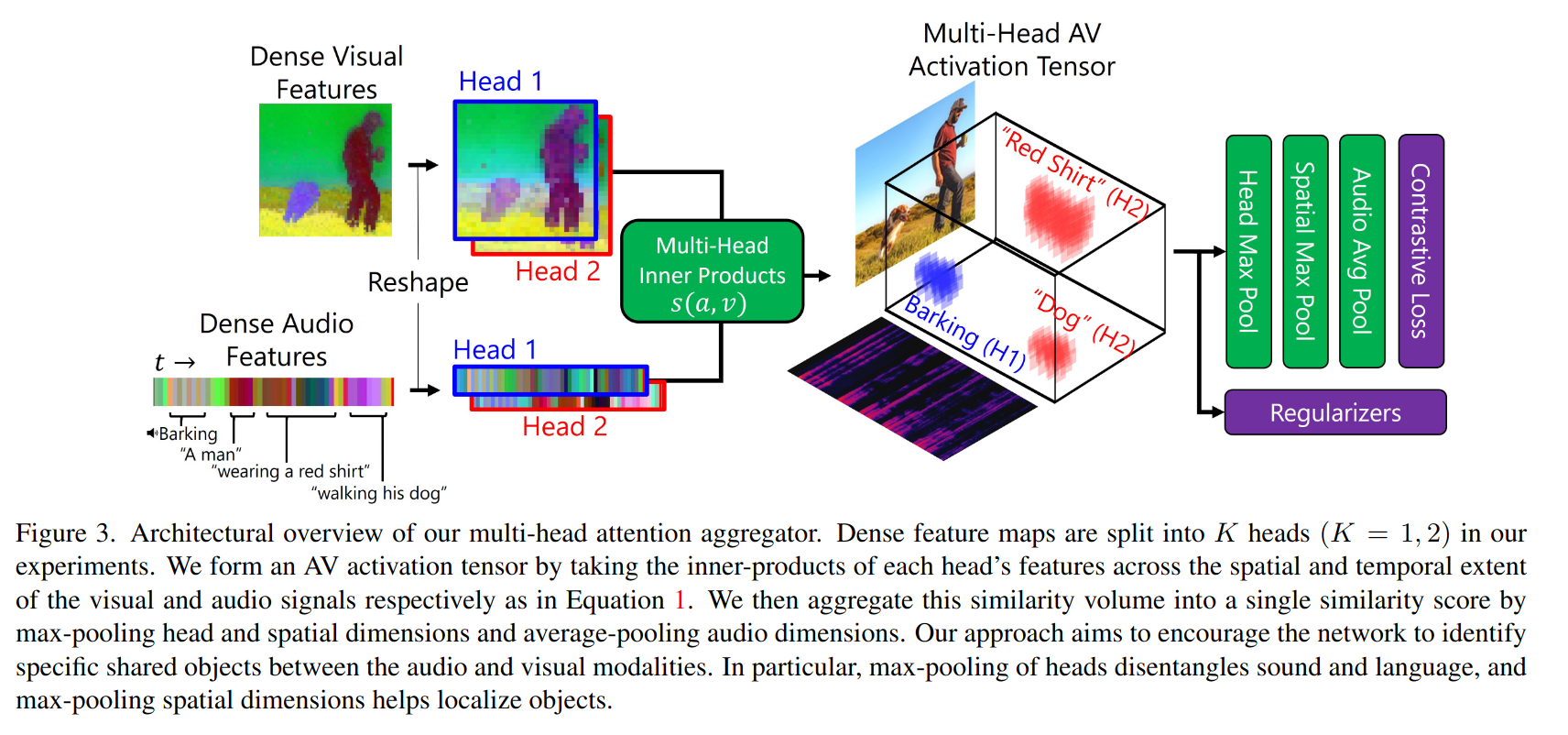
오디오와 시각 정보 사이에서 각각의 부분들이 얼마나 강하게 연결되어 있는지를 계산함
위 그림에서처럼, 오디오에서의 특정 소리(개 짖는 소리)가 비디오에서 개의 모습과 연결 될 수 있으니 이 둘간의 내적을 통해 "유사성 볼륨"을 만듦
이 유사성 볼륨은 하나의 숫자로 요약해서 그 신호쌍이 얼마나 잘 맞는지 계산함, 평균 풀링, 최대 풀링을 결합하여 짧은 소리나 작은 시각적 객체도 중요한 결합으로 다뤄짐
또, 여러 개의 헤드를 사용하여 다양한 방식으로 연결함
2. Loss
오디오와 시각 신호 간의 유사성을 이용하여 대조 손실 contrastive loss를 구성함
두 신호가 서로 잘 맞는 (postive 쌍), 잘 안 맞는 (negative 쌍)
temperature-weighted InfoNCE 손실로, postive 쌍끼리는 유사하게 학습시키고, negative 쌍 끼리는 유사하지 않도록 학습시킴
오디오와 시각 구성요소로 나누어 B개의 postive쌍, B개의 신호와 다른 신호들간을 비교하여 B^2-B개의 negative 쌍을 형성함
Experiments
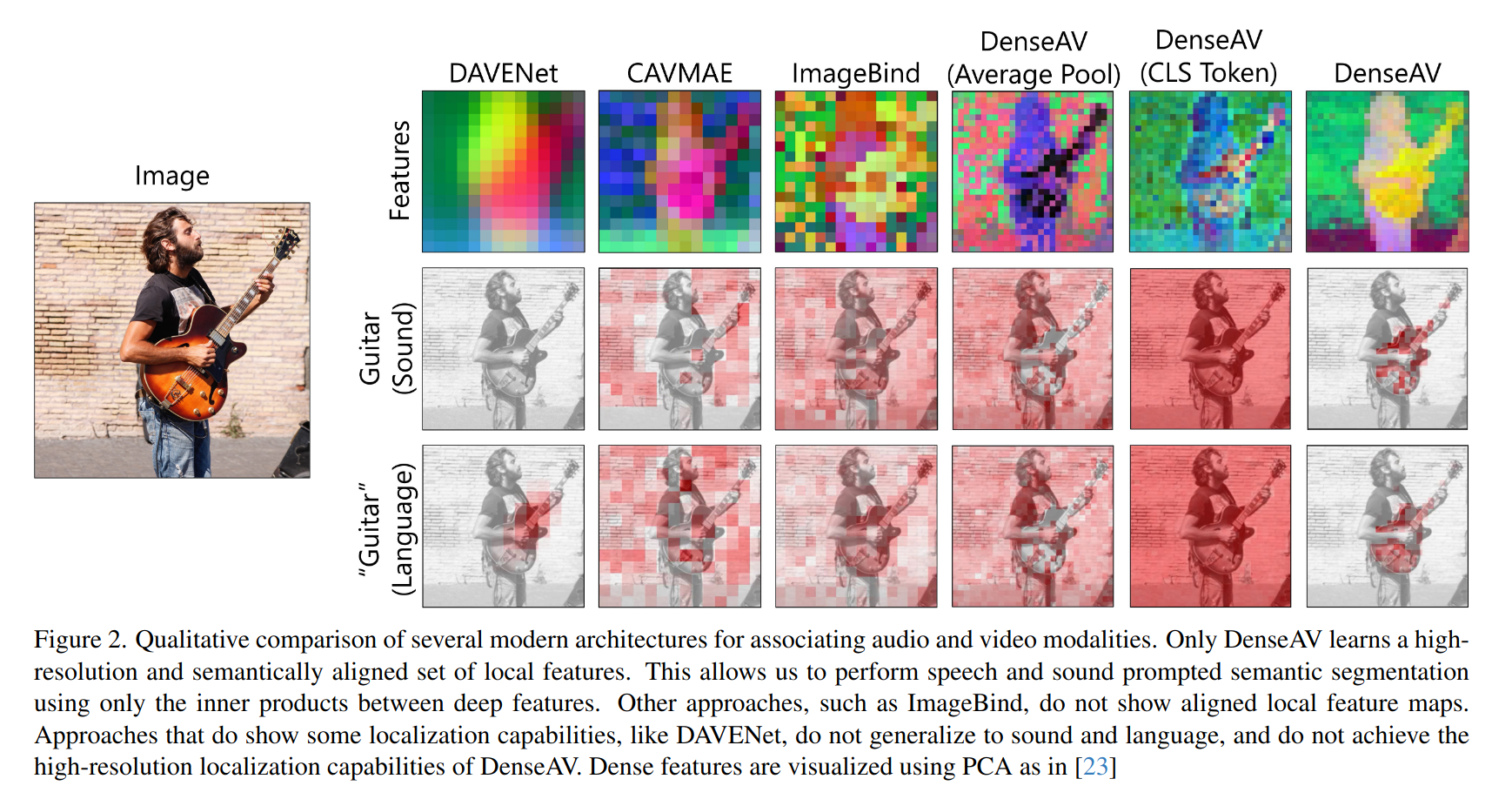
DenseAV는 speech랑 sound에 의미적 분할을 잘 할 수 있는 유일한 구조이다.
2. SoundingActions: Learning How Actions Sound from Narrated Egocentric Videos
paper link
CVPR 2024

Abstract
narration이 있는 실제 환경의 1인칭 시점 비디오에서 동작의 소리를 학습하는 새로운 self supervised embedding을 제안함
기존 방법- 오디오,비주얼 상관 관계가 있는 주석 달린 데이터에 의존함(큐레이션된 데이터 특성상 학습할 수 있는 소리 나는 행동의 범위가 제한될 위험있음)
MC3(multimodal contrastive-consensus coding)- 모든 모빌리티 쌍(오디오, 언어, 비전)이 일치할 때 이들간의 연관성을 강화하고 한쌍이라도 일치 하지 않으면 연관성을 악화함
데이터셋으로는 Ego4D, EPIC-Sounds를 사용함
Introduction
일상적인 인간활동을 담은 비디오가 주어질 때, 소리 나는 행동이 어떻게 보이고 들리는지에 따라 clustering 되는 교차 모달 표현을 학습하는 것이 목표이다.
개 털을 자를때 나는 가위 소리, 손톱으로 팔을 긁는 소리와 같이 드문 시나리오를 포함하려고 함
이 task의 어려운 점: 일부 보이는 행동은 소리를 안 내고, 일부 소리는 화면 밖에서 발생하는 걸 수도
또 다른 소리들은 화면에 보이는 물체(교통 소음)와 상관 있을 수도 있지만, 카메라를 착용한 사람의 눈에 보이는 행동과는 직접적인 관련이 없을 수도 있음
이런 식으로 일반적인 상관관계는 잘 포착하지만 행동에 특화된 상관관계를 포착하지 못하는 경향이 있음
=> 멀티모달 consensus 임베딩 접근 방식을 제안
1인칭 비디오 데이터셋- 나레이션도 같이 있다고 가정
오디오,비주얼,언어 모두에서 맞는 비디오 샘플을 찾고 그렇지 않은 경우에는 연관성을 멀리함
이를 통해 두 데이터셋 모두에서 정답 label과 일치하는 소리나는 행동을 더 잘 발견함
Method (Multimodal Contrastive-Consensus Coding)
Ego4D라는 실제 데이터에서 오디오 label 없이(narration만으로) 모델을 train,
Ego4D와 EPIC-Sounds라는 두가지 데이터셋에서 test를 진행함 (33000개의 비디오 클립에 전문가가 직접 주석을 달아준 새로운 데이터셋을 만들어)
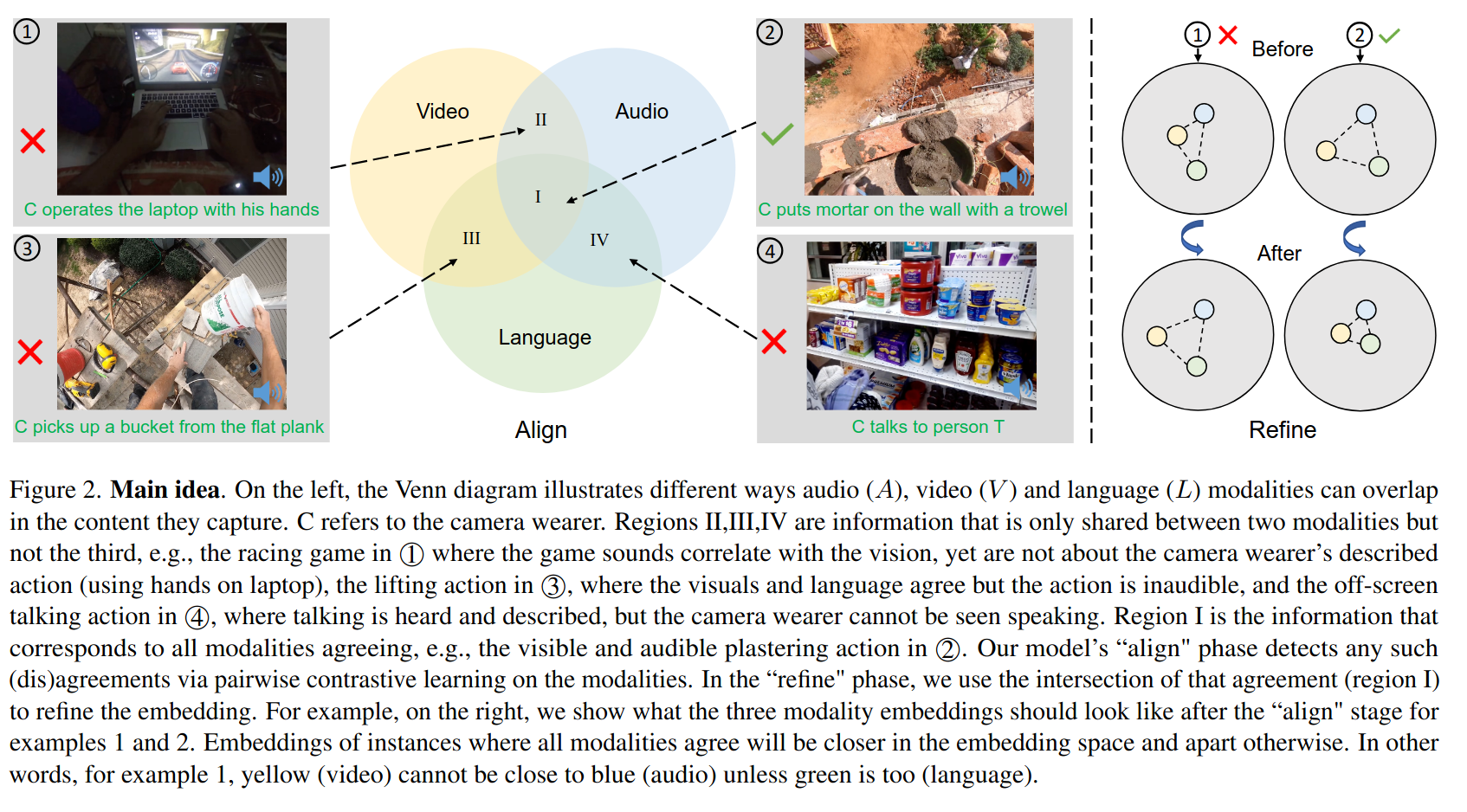
1,3,4 예시는 모든 모달리티가 일치하는 경우
모델의 align(정렬) 단계에서는 모달리티 간의 일치를 모달리티 간의 쌍별 대조학습을 통해 탐지함
refine(정제) 단계에서는 I의 교차점을 사용하여 임베딩을 refine한다.
예시를 보면, 모든 모달리티가 일치하면 임베딩 공간에서 서로 가깝고, 그렇지 않은 경우에는 멀어짐
즉, 1번 예시에서는 녹색(언어)가 가까워지지 않으면 노랑(비디오), 파란색(오디오)는 서로 가까워질수 없음
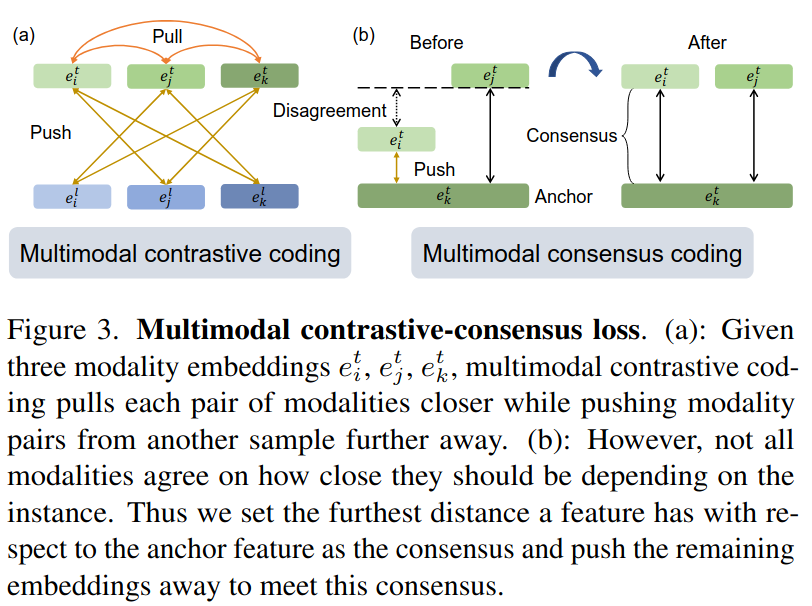
Multimodal contrastive-consensus coding
-
Multimodal Contrastive Coding
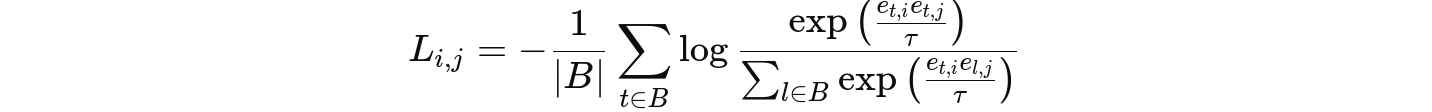
B: 배치크기, T: 온도
이 손실은 같은 샘플에서 나온 모달리티를 postive 쌍으로 처리하여 가까이 끌어당기고, 다른 샘플의 모달리티는 negative쌍으로 멀리 떨어뜨림
총 손실= 모든 모달리티 쌍에 대한 손실을 더한 값 -
Multimodal Consensus Coding
Contrastive 손실은 일시적으로 동시에 발생하는 모든 모달리티를 가깝게 함. 이는 모든 모달리티가 일치 하지 않는 경우에 문제가 됨
=> 이를 위해 Consensus coding도 추가하여 사용함
1): 비교할 기준이 되는 anchor modality (Ma)를 선택함
2): anchor modality와 다른 모든 모달리티 간의 코사인 유사도 점수를 계산함
3): consensus score(ct)는 쌍별 점수가 모두 높을 때만 높고, 적어도 하나의 모달리티가 anchor 모달리티와 일치 하지 않는다면 낮음. consensus 점수를 얻어서 모든 모달리티가 이 consensus를 따르도록 강제하는 손실을 설계함
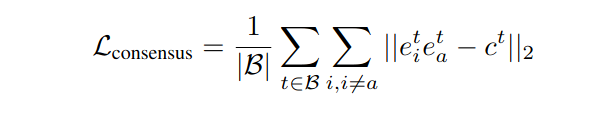
=> 총 손실은 contrastive loss+ consensus loss
이 손실은 합의 점수가 낮은 임베딩은 서로 멀리 밀어내고, 합의 점수가 높은 임베딩은 가까이 끌어당겨, 임베딩이 더 잘 정렬되도록 만듦
Experiments
-
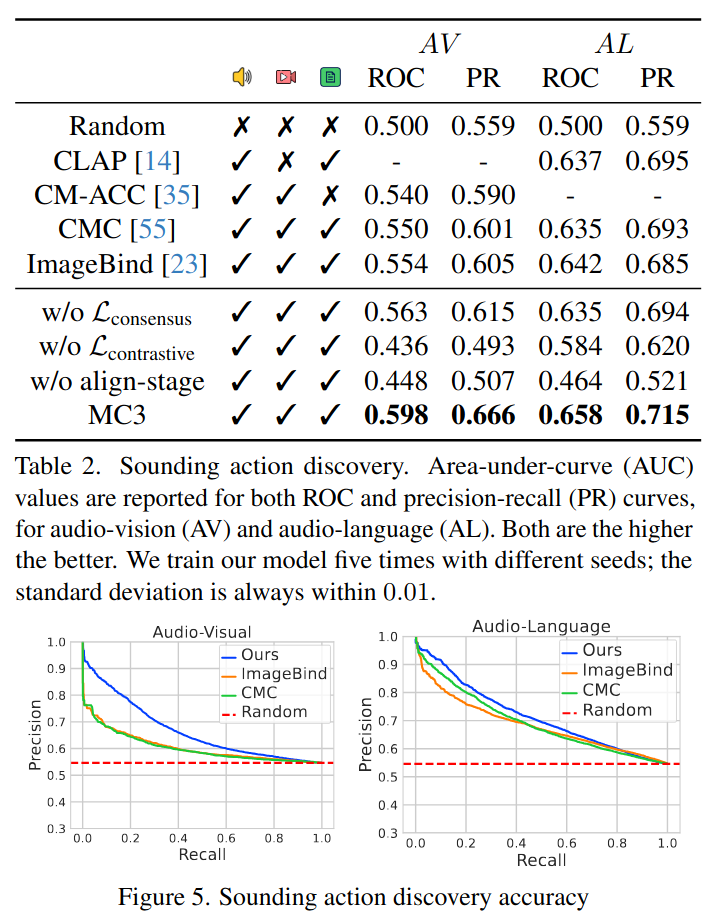
Sounding Action Discovery
어떤 행동이 소리를 낼까? 에 답하기 위해 소리 나는 행동을 발견하는 것이 목표
점수: 비디오의 행동이 소리를 낼 가능성을 나타냄
-
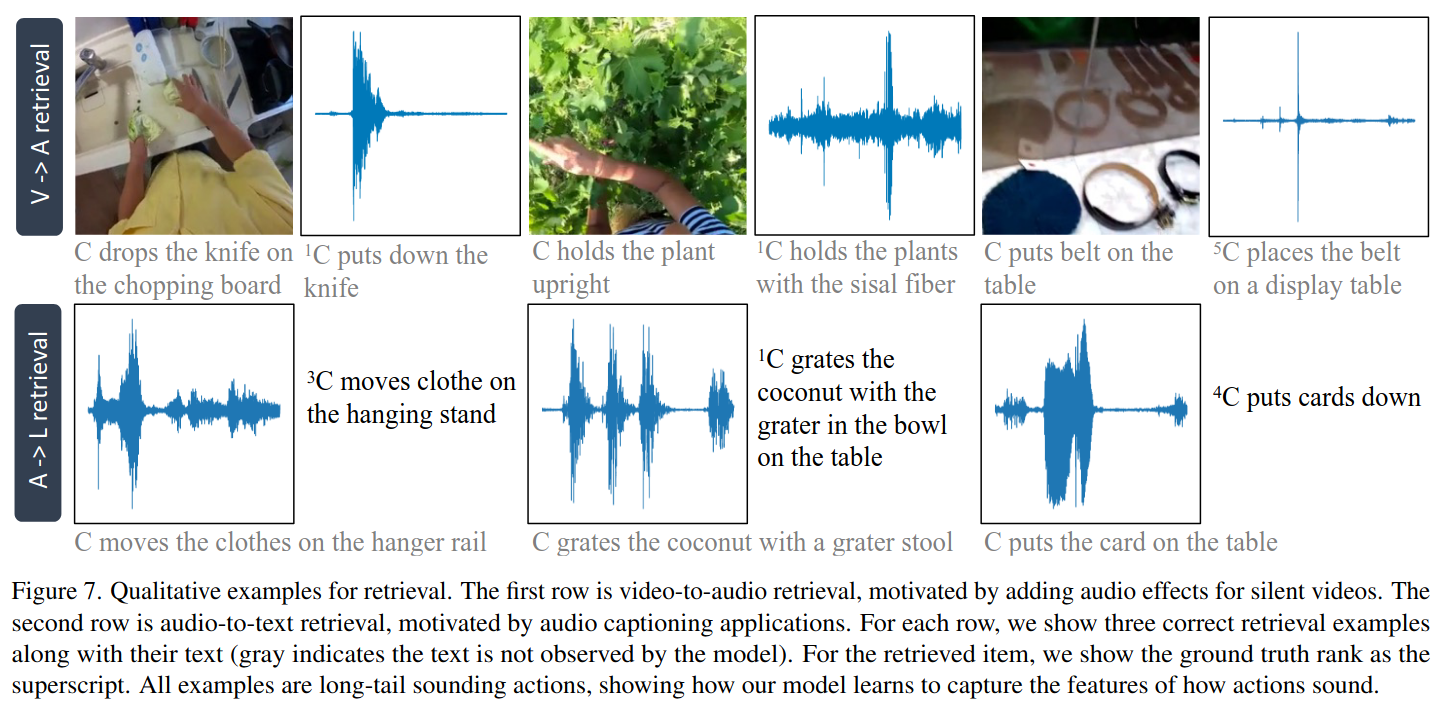
Sounding Action Retrieval
한 모달리티를 이용해서 다른 모달리티를 찾아내는 방법임
(소리가 없는 비디오에 맞는 음향 효과를 추가하거나, 소리만 듣고 어떤 행동이 일어나는지 설명하는 자막을 찾는 것)
실험: 비슷한 행동들을 묶어서 그룹을 만들고, 각 그룹에서 일부는 쿼리(검색 요청)에 쓰고, 나머지는 검색 대상(찾아낼 예시들)으로 사용함. 쿼리에서 어떤 행동을 보여주면, 그와 비슷한 행동을 검색해내는 방식임
=> 좋은 성능을 보임
비디오-> 오디오 보다 오디오->비디오가 더 어려움
오디오는 종종 여러 행동에 공통적으로 나올 수 있는 소리를 내기 때문에 모호함
-
Audio Classification on EPIC-Sounds
Epic-Sounds는 주방 환경에서 발생하는 소리를 분류하는 어려운 오디오 분류 데이터셋
1번이랑 다르게, 오디오 clip만 입력으로 씀

3. Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
paper link
webpage link
2번 논문의 후속작, ECCV 2024
Abstract
새로운 주변 소음 인식 오디오 생성 모델, AV-LDM 제안함, 소리 없는 비디오가 주어지면, 모델은 retrieval-augmented generation을 사용하여 시각적 컨텐츠와 의미적, 시간적으로 일치하는 오디오를 생성함
Ego4D,EPIC-KITCHENS라는 두개의 영상 데이터셋 사용
Ego4D-Sounds(120만개의 clip)도 도입함
Introduction
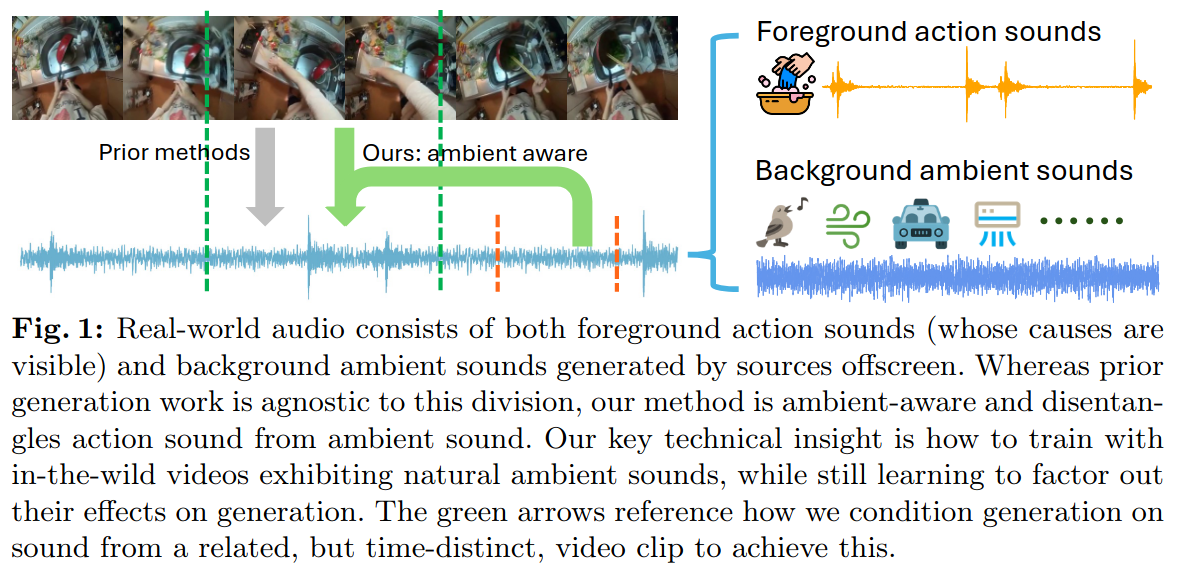
비디오의 오디오를 생성할 때 비디오에 나타나지 않는 주변 소음은 시각적 연관이 없는 경우도 많음. 대부분 기존 방법은 행동 소리와 주변 소리를 분리하지 않고 전체로 다우러, test시 주변 소리의 생성이나 무작위 소리 생성으로 이어짐
이를 해결 하기 위해=>
행동 소리: 시간상 매우 국한 되어있음
주변 소음: 시간에 걸쳐 지속적임
학습 중에는 입력 비디오 클립 외에도 동일한 긴 비디오의 다른 시간대에서 추출한 오디오 클립을 생성 모델의 조건으로 사용함
또 대규모 ego 데이터셋을 사용하면 1. 손-물체 상호작용을 더 잘 관찰 가능 2. timestamp가 있는 나레이션 제공

"action-ambient joint generation" = 학습 데이터에서 비슷한 장면의 오디오를 가져와서 행동 소리와 주변 소리를 함께 생성
"action-focused generation"= 주변 소음이 거의 없는 오디오를 가져와서 행동소리에만 집중함-> 행동 소리만 선명하게 생성하고 배경 소음은 최대한 줄이는 형식
key point = action sound are highly localized in time, but ambient sounds tend to persist across time
=> During training this model uses same long video as the input video clip but from different timestamps
use latent diffusion model
