발표
Define the problem addressed and why it matters.
• Discuss the assumptions made in the paper’s approach.
• Outline the technical methodology, then delve into critical details.
• Highlight key findings and experiments.
• Relate the paper to others we've studied (if any exists).
Abstract
전: 공간-시간 분해를 통해 self attention를 전역적으로 계산하는 방법
이 논문: 더 나은 속도, 정확도를 제공하는 비디오 transformer의 지역성 유도 편향을 주장함
계속해서 사전 훈련된 이미지 모델의 강점을 활용함
Introduction
이미지 분류를 주로 컨볼루션 신경망 CNN으로 하다가 Vision Transformer (ViT)의 도입으로 transformer로 전환되고 있다.
이 논문에서는 효율성 면에서 분해 모델을 능가하는 순수 트랜스포머 백본 아키텍처를 비디오 인식을 위해 제시한다. 이 아키텍처는 비디오의 고유한 공간-시간 지역성을 활용하여 이를 달성한다. 공간-시간 거리에서 서로 가까운 픽셀이 상관관계가 있을 가능성이 높기 때문에, 전체 공간-시간 자기 주의는 지역적으로 계산된 자기 주의에 의해 잘 근사될 수 있으며, 이는 계산 및 모델 크기에서 상당한 절감을 제공한다.
Video Swin Transformer는 원래 Swin Transformer의 계층 구조를 따르지만, 지역적 주의 계산의 범위를 공간 영역에서 시공간 영역으로 확장한다. 지역적 주의는 비중첩 윈도우에서 계산되므로, 원래 Swin Transformer의 시프트 윈도우 메커니즘도 시공간 입력을 처리하도록 재구성되었습니다.
우리의 아키텍처는 Swin Transformer에서 적응되었기 때문에 대규모 이미지 데이터셋에서 사전 훈련된 강력한 모델로 쉽게 초기화할 수 있습니다. ImageNet-21K에서 사전 훈련된 모델을 사용한 결과, 백본 아키텍처의 학습률은 랜덤 초기화된 헤드보다 작아야 한다는 것을 발견했다 (예: 0.1배). 그 결과, 백본은 새로운 비디오 입력에 맞추는 동안 사전 훈련된 매개변수와 데이터를 천천히 잊어버려 더 나은 일반화를 이끌어낸다.
Related Works
CNN and variants
C3D는 3d 컨볼루션을 이용하는 11층의 deep network이다. kinetics 대규모 데이터셋에 좋은 결과를 보임, 공간 및 시간 컨볼루션을 분리하면 원래의 3d convolution보다 더 나은 속도, 정확도를 가져옴
Self attention/Transformers to complement CNNs
NLNet: 시각 인식 작업을 위해 self attention을 채택한 최초의 연구
GCNet, DNL은 장거리 의존성을 모델링하기 위해 CNN을 보완하는 구성 요소를 제공함
Vision Transformers
ViT에서 시작.
시공간 지역성 조사한후, 시공간 지역성 편향을 가진 video swin transformer 설명
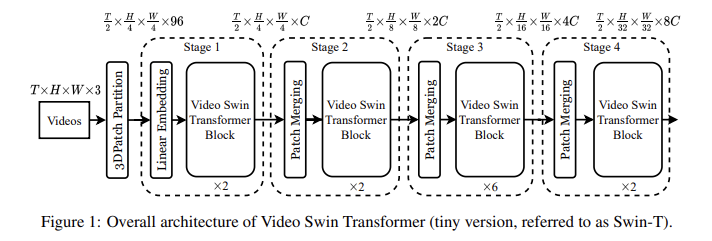
Video Swin Transformer
Architecture