idea3은 training set, validation set, 그리고 test set으로 데이터를 쪼개줍니다. 이는 idea1,2와의 차이는 validation set 즉, 검증용을 하나 두고 test set는 실제 돌릴때만 사용을 하는겁니다.

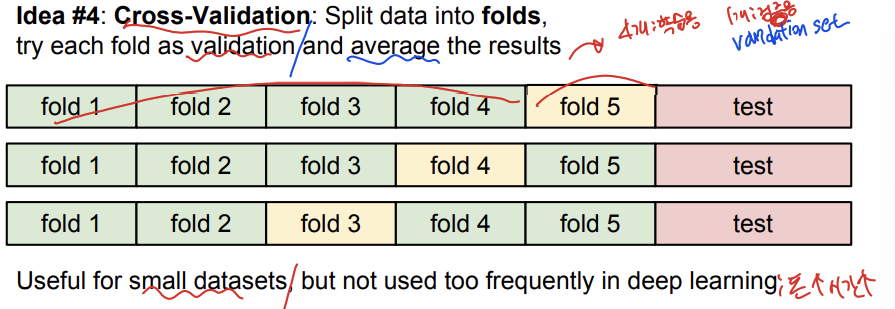
idea4는 cross-validation으로 data를 fold들로 쪼개주는 겁니다. 지금 이 예시에서는 data를 5개의 fold로 나눠서 4개는 학습용 training set, 1개는 검증용 validation set로 두는 것입니다. 이렇게 여러 경우의 수들을 해보고 결과를 평균내서 가장 유용한 경우를 찾아줍니다. 하지만 cross validation은 딥러닝에서 잘 쓰이지 않습니다. 돈과 시간이 많이 들기 때문입니다.
5개의 fold cross validation에서는 몇개의 값을 쓸때 가장 정확도가 높은지를 보기 위한 것입니다. 각 점은 결과값을 가리키고, 이어져 있는 선은 평균, 바는 표준편차를 가리킵니다. 그림에서 보듯이 k가 7일 경우가 가장 정확도가 높은것으로 나옵니다.

k-nearest neighbor는 이미지에서 절대 쓰이지 않습니다. test time이 너무 오래 걸리고 밑의 3개의 이미지들을 보면 , 하나는 가려져 있고, 밀려 있고, 다른 색으로 칠해져 있는데 이 3개의 이미지들 모두 같은 l2거리를 가집니다. l2거리란 두 점 사이의 직선 거리라고 합니다. 따라서 이는 좋지 않은 방법이라는 것을 알수 있습니다.

간단히 정리하자면, 이미지 분류에서 우리는 training set으로 시작해서 test set에서 라벨을 예측합니다. hyperparameter는 모델링할때 사용자가 직접 세팅해주는 값인데 k-nearest neighbor에서는 distance metric(거리함수)와 아까 표에서 본 k의 값이 hyperparameter입니다. validation set을 이용하면서 hyperparameter를 고르고 test set은 딱 한번 맨 마지막에 실행 됩니다.

linear classification
선형 분류에 대해서 알아보겠습니다. 선형 분류는 간단히 말하자면 선을 이용해 집단을 2개 이상으로 분류하는 것을 말합니다.
linear classification에 대해서 식으로 보며는 단순히 행렬과 벡터의 곱입니다.
이 예시에서 보면 이 고양이 이미지는 가로 세로 각각 32개의 픽셀로 이루어져있고, 3개의 색상 이미지를 가지기 때문에 총 3072개의 개수를 가집니다. 이때 결과로는 10개의 class로 분류가 되므로 wx의 결과값은 10입니다. W(가중치 행렬)는 103072로 나오고, x는 30721로 나와서 행렬 곱을 하게 되면 101이라는 결과 값이 나옵니다. 즉 f(x,w)는 101의 값을 얻게 되는 것입니다.

이때 bias값도 등장하게 되는데 이는 데이터 독립적으로 각 클래스에 scailing offset 보정값을 더해주는 것입니다. 이 예시에서는 bias는 10*1이 됩니다.
이를 이용해서 training set에 적용할수 있습니다.
linear classifier를 이용하여 파란 배경이 많은것을 봐서 비행기고 이런식으로 분류를 할수 있게 됩니다. 하지만 linear의 문제는 각 클래스에 대해 단 하나의 템플릿 만을 학습 할수 있다는 점입니다.

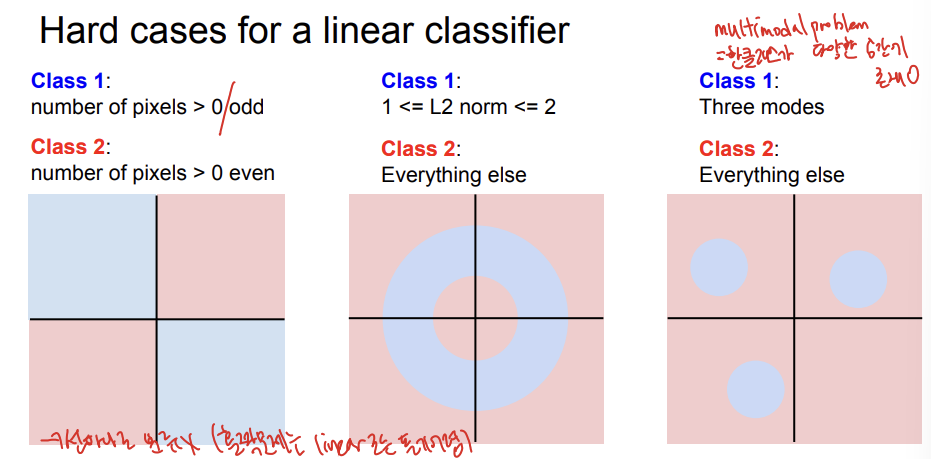
linear classifier를 이용하는데 어려운 경우들이 있는데 첫번째의 경우가 선하나로 분류 되지 않는 경우입니다. 이렇게 홀짝을 따지는 경우는 linear로 풀기 어렵습니다. 또, multimodel problem으로 한 클래스가 다양한 공간에 존재할때 linear로 풀기 어렵습니다.
이 3가지 이미지에서의 w가중치 값들이 나와있는데 이는 좋은지 나쁜지 우리가 말을 할수 있을까요??

이에 대해서는 다음 시간에 가중치 행렬을 어떻게 구하는지를 배워보면서 알아보겠습니다.
발표를 마무리 하겠습니다. 감사합니다.
