Persistence Framework
- 데이터를 가공하는 자바 <-> 데이터를 저장하는 디비 층을 연결해주는 매개체
- sql mapper와 orm이있다.
JDBC(Java Database Connectivity)
- JDBC는 DB에 접근할 수 있도록 Java에서 제공하는 API
- 모든 Persistence Framework는 내부적으로 JDBC API를 사용한다.
SQL mapper vs ORM
-
SQL Mapper
Object와 SQL의 필드를 매핑하여 데이터를 객체화 하는 기술
객체와 테이블 간의 관계를 매핑하는 것이 아님
SQL문을 직접 작성하고 쿼리 수행 결과를 어떠한 객체에 매핑할지 바인딩 하는 방법 -
ORM
Object와 DB테이블을 매핑하여 데이터를 객체화하는 기술
sql mapper와 orm의 장단점
- SQL Mapper DBMS에 종속적인 문제
- 복잡한 쿼리 직접작성가능
- 테이블 변경시 변경해야하는 부분들이 많다
- 반복되는 코드가 많다
JDBC API사용과 응답결과를 객체로 하나하나 매핑하는 일을 SQL매퍼가 대신 처리해주다
하지만 결국 개발자가 SQL을 직접처리해야하므로 SQL에 의존하는개발을 피할 수 없다
EX) JdbcTemplate, MyBatis
- ORM
- 코드레벨로 다룰수있다
- 컴파일시에 오류를 잡을 수 있다
- 객체지향적인 코드를짤수있다
반복적인 SQL을 직접 작성하지 않음 - jpa는 from절 서브쿼리 작성하지 못한다. 그래서 네이티브쿼리를 이용하든 해야함
- https://github.com/querydsl/querydsl/issues/2607 (이걸로 from절 서브쿼리 사요요할수있다는데 참고해보기)
DBMS에 종속적이지 않음
복잡한 쿼리의 경우 JPQL을 사용하거나 SQL Mapper을 혼용하여 사용 가능
Mybatis vs JPA
- JPA : ORM(Object Relational Mapping) 기술
- Mybatis : Object Mapping 기술
mybatis의 일대다 매핑방식
SQL 중심 개발의 문제점
- 테이블 구조가 변경되면, 코드의 모든 SQL문을 변경된 테이블 구조에 맞게 수정해야한다.
- 흔히 CRUD 라고 말하는 기능은 일반적으로 거의 모든 테이블에서 필요할 것 이다. 100개의 테이블이 존재한다면, 100개의 CRUD 코드가 필요할 것 이다.
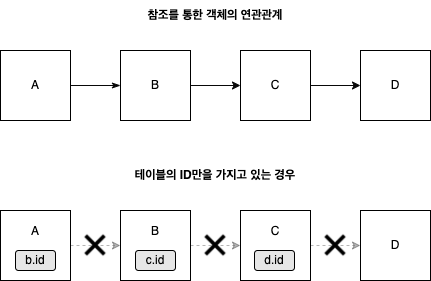
- 객체지향에서 객체간의 연관관계는 참조를 통해 맺어지고, 관계형 데이터베이스에서 테이블간의 연관관계는 외래키로 맺어진다. SQL 중심으로 코드를 작성하면, 객체의 구조를 테이블에 맞춰야 한다. A1가 A2를 참조하는 형태가 아니라, A1가 A2의 식별자(ID값 등)를 가지고 있는 형태로 객체를 모델링 해야한다.
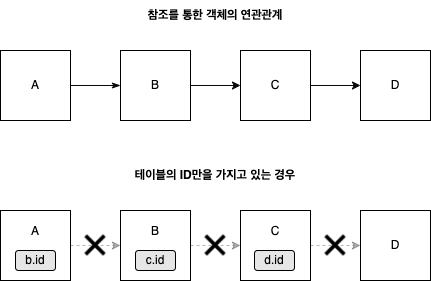
객체는 자유롭게 객체 그래프를 탐색해야하지만, 테이블 행의 ID를 통한 간접 참조는 이를 불가능하게 한다. 물론 Join 쿼리등을 사용하여 객체가 객체를 참조하는 모양으로 객체를 생성할수는 있겠으나, 쉽지 않다. 즉, 객체간 참조를 통한 연관관계 설정이 어렵다. 그러니까 A.B.C.D.getX() 이런것이 가능해야 하는데 테이블의 ID만을 가지고 있는 경우 MYBATIS같은 경우는 객체의 구조를 테이블에 맞춰놨기 때문에 이러한 연관관계 참조가 어렵다 - 하나의 객체를 불러오자고 너무 많은 테이블들을 매핑해야한다
예를들어 A테이블을 가져오기 위해서 연관되어 있는 테이블들이 많다면 이들도 매번 다 연결을 해주어야하는데 코드가 복잡해지고 테이블이 많아질수록 이것이 부담스러워진다 - 진정한 의미의 계층 분할이 어렵다
실제 객체간의 연관관계와 상관없이, 쿼리문에 따라 객체 그래프의 탐색 범위가 제한된다. 실제 객체 그래프와 관련 없이, 실제 쿼리문이 어떤 테이블을 가져오느냐에 따라 탐색할 수 있는 범위는 제한된다. 그렇기 때문에 쿼리문에 대해 얻어진 객체에 대해 어떠한 필드를 얻는 상황이 있다고 가정할때 그 필드가 NULL일수도있다. 신뢰할 수 없기 때문에 문제가 발생한다
JPQL
-
JPQL(Java Persistence Query Language) 는 JPA (Java Persistence API) 의 일부로 정의된 플랫폼(DBMS) 독립적인 객체지향 쿼리 언어 입니다.
JPQL 은 관계형 데이터베이스의 엔티티에 대한 쿼리를 만드는데 사용됩니다.
SQL에 크게 영향을 받아 SQL 문과 비슷하지만 데이터베이스의 테이블에 직접 연결되는 것이 아니라 JPA 엔티티에 대해 동작합니다.
그래서 JPQL 의 쿼리에는 테이블이 아닌 엔티티에서 표현하고 있는 컬럼의 이름을 써줘야 합니다.
@Query(value = "SELECT u.pathName as pathName, DATE(u.date) as date, u.visitCount as visitCount " + "FROM UserStatistics u GROUP BY DATE(u.date), u.pathName, u.visitCount") -
JPA는 엔티티 객체를 중심으로 개발을 하므로 SQL을 사용하지 않는다.
하지만 SQL을 사용해야할 때가 필요한데, 바로 검색쿼리를 사용할 때 이다.
JPA는 엔티티 객체를 중심으로 개발하므로 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색해야 한다.⇒ 필요한 데이터만 데이터베이스에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요하다. JPA는 JPQL(Java Persistence Query Language)를 제공한다.
JPQL과 JPA의 관계
- JPA는 JPQL을 분석해서 적절한 SQL을 만들어서 데이터베이스에서 데이터를 조회하게 된다
JPQL과 SQL 차이점
- JPQL엔티티 객체를 대상으로 쿼리한다.
SQL은 데이터베이스 테이블을 대상으로 쿼리한다.
예제1
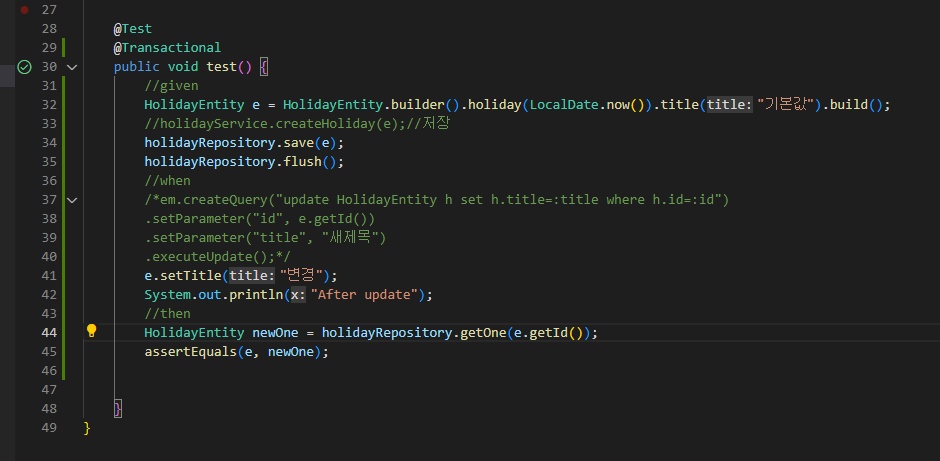
- 44번째줄을 holidayService로 바꾸면 에러가 발생한다.
(a와 newOne이 같지 않다는 에러 출력)
어떤차이가 있는것일까? - em.create~로 update jpql을 날리는 것과 set으로 변경감지를 일으키는 것은 어떤차이가 있을까?
첫번째 질문
repository와 service의 차이
-
저 코드자체가 전 좀 헷갈려요
일단 41번째줄에서 변경이 되잖아요
그럼 변경감지에의해 쓰기저장소에 쌓였다가 마지막줄에서 쿼리가 나갈거예요 근데 45번째 줄이면 아직
코드가 끝나진 않았으니 쿼리가 안나가는거 아닌가요?
하지만 1차캐시에 변경된 객체를 조회해 오겠죠
그래서 newOne이랑 e는 같아요! -
하지만 이번엔 holidayService를 생각해볼게요.
holidayService의 결과를 생각해보면 e와 newOne이 달랐어요
newOne이 변경된 객체를 가져와야하는데 기본값을 가져와요..
왜그러는걸까요..? -
service는 마바로 이어지는 거여서 그럼
service의 내부를 보면 마바인 mapper로 저장 -
41번째 이후에 em.flush를 넣으면 객체 참조값은 다르지만 내용은 같게 된다
-
매번 쿼리를 날리는게 아니라.. flush를 만나거나해야.. 쿼리를 날리게 되는구나
jpa와 spring data jpa의 차이
jpa를 사용하는 이유
- 애플리케이션을 객체지향 언어로 개발하고 관계형 데이터베이스로 관리한다면 객체-관계형간의 차이를 해결하기 위해 JPA를 사용한다.
spring data jpa를 쓰지 않고 jpa를 사용한다면?
- JpaRepository를 상속받지 않고 대신 @Repository를 쓰고, EntityManager를 사용하는것을 의미한다
- findById와 같은 기본 메서드들은 SimpleJpaRepository을 상속받기때문에 그 안에서 EntityManager를 사용해서 요청을 보낸다.
두번째 질문
update jpql과 set으로 변경감지를 일으키는 것의 차이
em.(기본제공메서드) vs em.createQuery의 차이
- em.findall, findById 등 기본적으로 제공되는것들은 호출하면 sql이 실행되고...
em.createQuery로 직접 만들어서 쿼리날리는 것을 보고 "jpql을 작성한다"라고합니다.
기본적으로 제공되는것들은 sql이 실행되는거라 em.flush같은 것들을 실행해주지 않고
em.createQuery는 즉, jpql쿼리를 실행하는거기때문에 em.flush이 호출됩니다. - em.flush() : 디비 내용과 영속성 컨텍스트를 동일하게 만드는 것
- em.flush() -> jpql쿼리 실행의 순서이다..(동일성을 보장하기 위해서였던가?)
세번째 질문
다음 메서드에서 왜 newOne은 update된 값을 받아오지 못하는것일까?
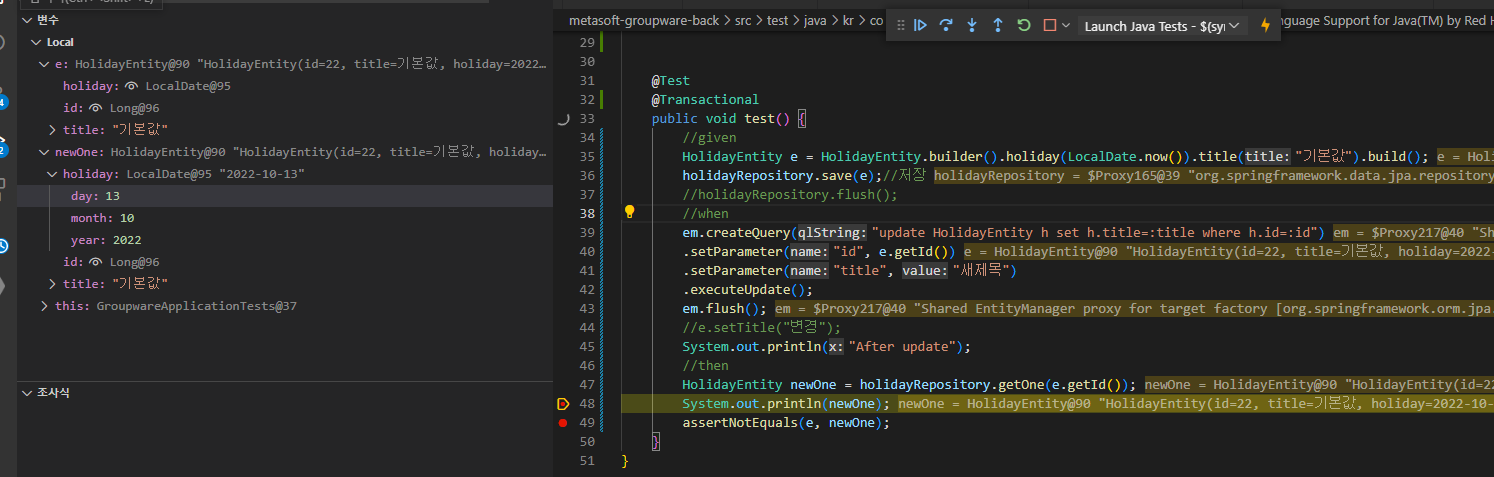
- em.flush()만 하는게 아니라 em.clear()도 해야한다
em.flush
- 영속성 컨텍스트의 변경 내용을 DB 에 반영하는 것을 말한다.
- 이것을 해도 1차캐시의 내용은 비워지지 않는다
- 1차 캐시의 내용을 비우는 em.clear()가 필요하다
Member member = new Member();
member.setId(101L);
member.setName("HelloJPA");
System.out.println("*********Before*********");
entityManager.persist(member);
System.out.println("*********After*********");
Member findMember1 = entityManager.find(Member.class, 101L);
System.out.println("findMember id = " + findMember1.getId());
System.out.println("findMember name = " + findMember1.getName());
transaction.commit();- em.persist() : 저장 시점에 데이터베이스에 저장되는 것이 아닌 1차 캐시에 저장이 된다.
- 1차캐시에 있는 것을 조회해 오기 때문에 조회 쿼리가 나가지 않는다.
즉, save를 하면서 1차캐시에 저장이 되고, flush가 된다음, em.createQuery를 실행시키고
em.clear()을 하게 되면 영속성컨텍스트가 비게 되면서 조회를 해올때 디비에서 해오게 된다.
@Test
@Transactional
public void test(){
Demo d = Demo.builder().title("제목1").build();
demoRepository.save(d);//1차 캐시에 저장
//jpql 실행 전 flush실행 -> db에 커밋을 날림
//디비에 현재 제목1에 대한 demo가 저장된 상태
em.createQuery("update Demo d set d.title=:title where d.id=:id")
.setParameter("id", d.getId())
.setParameter("title", "새제목")
.executeUpdate();
//업데이트쿼리를 날림. jpql은 바로 db에 쿼리를 날림. 더티 체킹의 경우는 1차캐시의 내용과 메서드끝부분의 엔티티의 상태를 비교함.
//조회를 하면 1차캐시에서 부터 찾기때문에 update된 새제목<의 demo 엔티티를 가져와야함
Demo newDemo = demoRepository.getById(d.getId());
System.out.println(newDemo.getTitle());
}- set메서드를 이용하여 엔티티 상태변경
-> 더티 체킹으로 1차캐시의 엔티티와 메서드 마지막의 엔티티의 상태를 비교하여 마지막에 쿼리를 날린다 - jpql로 update쿼리를 날리는경우
jpql 실행전에 flush한 후에 db에 직접 update쿼리를 날려서 엔티티를 받아온다
네번째 질문
영속성 컨텍스트에 이미 있는 엔티티를 JPQL로 다시 조회해올 경우 어떻게 처리될까?
- 영속성 컨텍스트에 이미 들어있으면, JPQL로 조회해온 member는 그냥 버려진다는 것이다.
새로 조회해온 결과를 기존 영속성 컨텍스트에 덮어쓰지 않는 이유는 영속 상태인 엔티티의 동일성을 보장해야하기 때문이다. - JPQL실행 전에는 영속 상태인 엔티티의 동일성을 보장하기 위해 JPQL 실행 전에 플러시를 수행한다.
정리
- em.flush(), 엔티티 매니저로 조회 쿼리를 하는 녀석들은 영속성 컨텍스트에 걔가 존재하는지 확인하고 없는 경우에 DB와 통신해서 가져옵니다.
jpql로 검색하는 경우는 반대로 동작하는데요, DB에서 먼저 PK에 해당되는 녀석을 가져온 후 영속성 컨텍스트에 이미 PK가 있는 녀석이 있다면, DB에서 가져온 녀석을 버립니다. 왜냐하면 영속성 컨텍스트에서 관리되고 있다는 것은 이미 자바 메모리 상에서 비즈니스 로직을 타서 수정이 되고 있을 가능성이 있기 때문이에요!
출처
https://donnaknew.tistory.com/3
https://cornswrold.tistory.com/332
https://velog.io/@evelyn82ny/JPA-vs-Spring-Data-JPA
https://joont92.github.io/jpa/JPQL/
https://hudi.blog/static/548f59d6de64a519ca6d5f071c28acf7/7921f/direct-indirect-reference.png
https://thefif19wlsvy.tistory.com/249
{kind=link}
