JPA
1.Transactional 전파
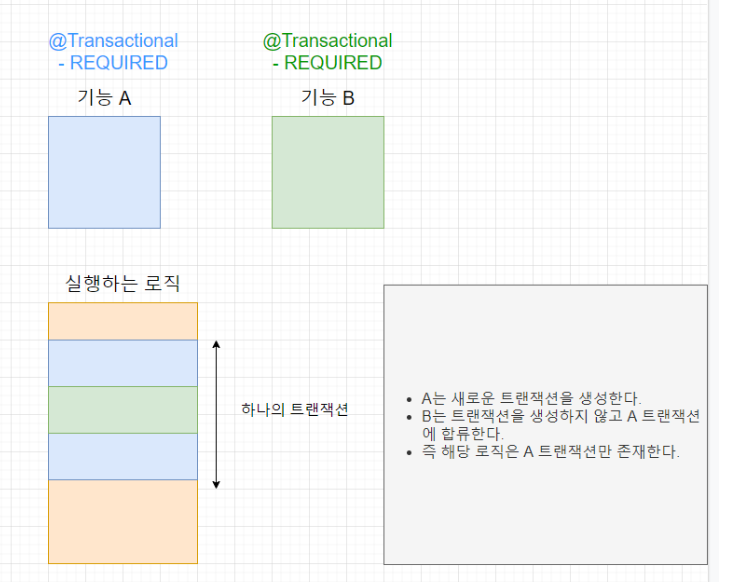
클래스 단에 @Transactional 선언 -> 해당 클래스의 모든 메서드에 @Transactional이 적용된 효과메서드단에 @Transcational 선언 -> 메서드 하나를 트랜잭션으로 보고 메서드 중간에 에러가 생기면 롤백하는 등 처리를 해준다부모메서드에 @T
2.쓰기 지연 저장소
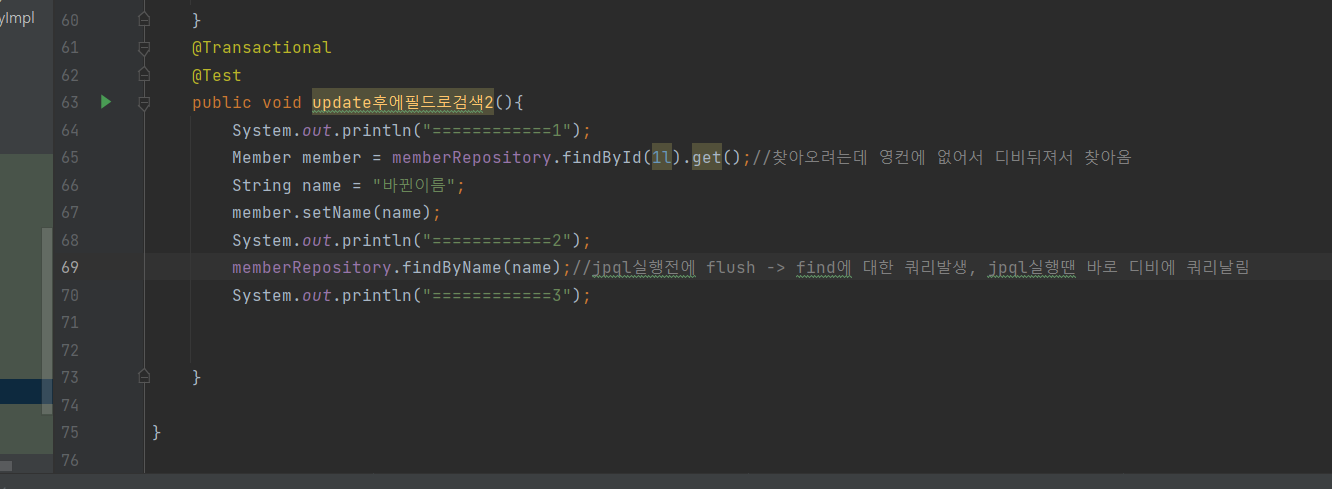
한 트랜잭션안에서 이뤄지는 UPDATE나 SAVE의 쿼리를 쓰기지연 저장소에 가지고 있다가 트랜잭션이 커밋되는 순간 한번에 DB에 날리는 것을 말한다.이로써 얻을 수 있는 장점은 DB커넥션 시간을 줄일 수 있고, 한 트랜잭션이 테이블에 접근하는 시간을 줄일 수 있다는
3.JPQL
JPQL(Java Persistence Query Language) 는 JPA (Java Persistence API) 의 일부로 정의된 플랫폼(DBMS) 독립적인 객체지향 쿼리 언어 입니다.JPQL 은 관계형 데이터베이스의 엔티티에 대한 쿼리를 만드는데 사용됩니다.S
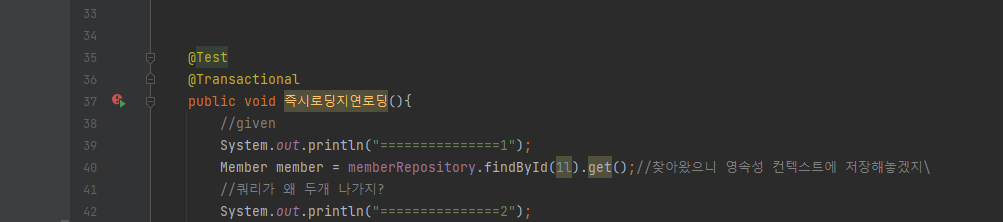
4.영속성 컨텍스트
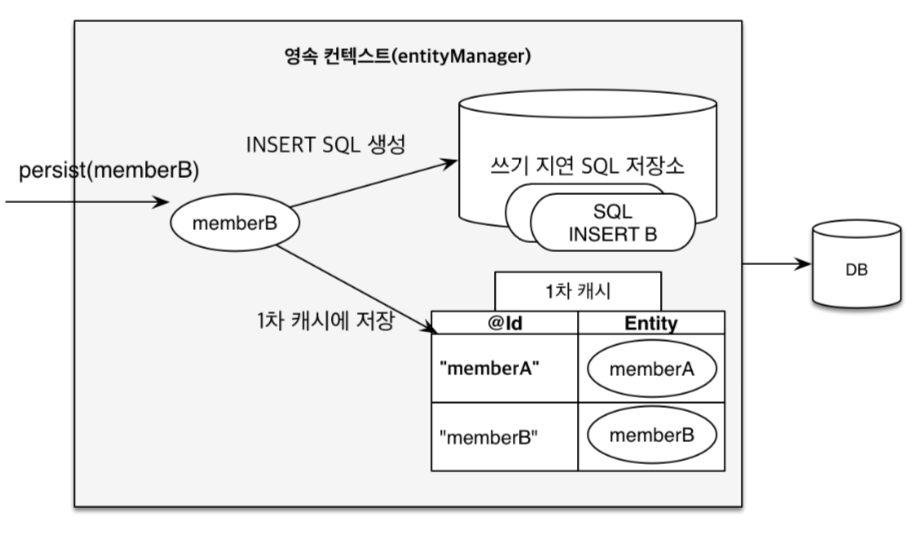
엔티티엔티티는 영속성을 가진 객체로 DB 테이블에 보관할 대상입니다. 영속성데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.영속성을 갖지 않으면 데이터는 메모리에서만 존재하게 되고 프로그램이 종료되면 해당 데이터는 모두 사라지게 된다.그래서
5.builder로 생성하면 list초기화가 안된다
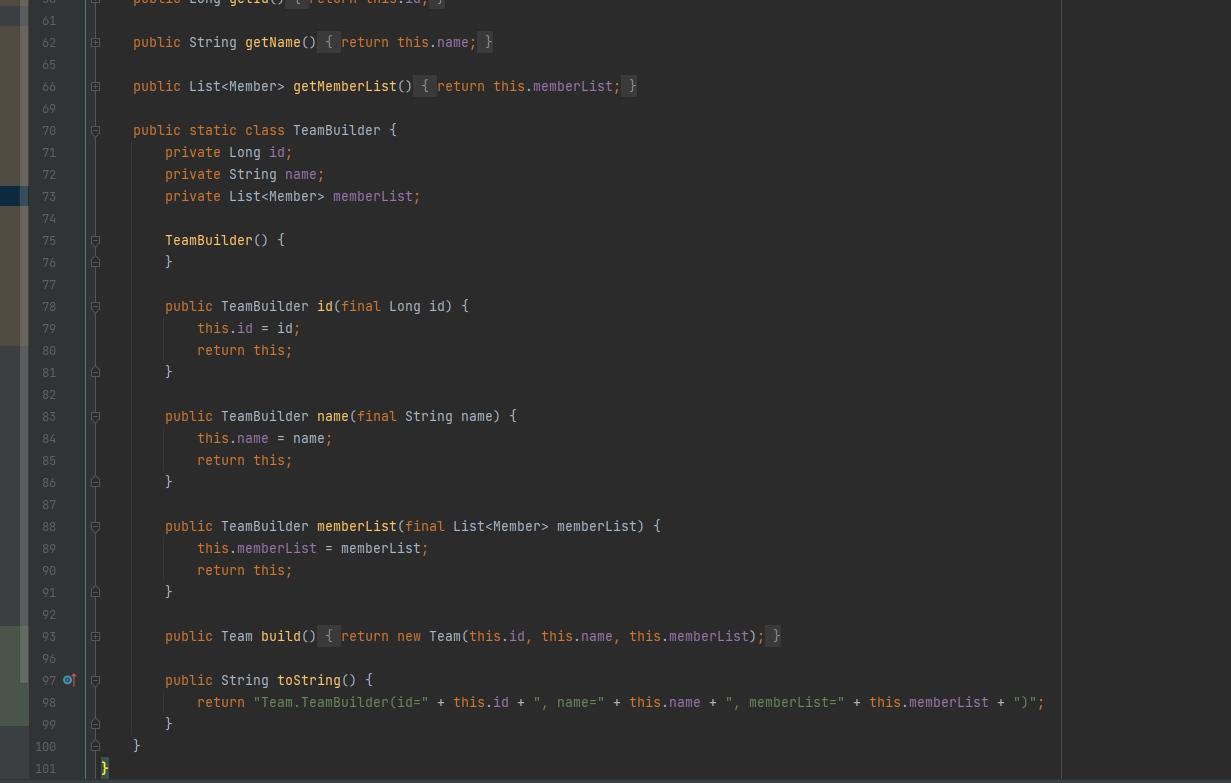
그럼 private List<Member> memberList = new ArrayList<>(); 할당은 왜 해주는 것일까?
6.양방향 매핑의 필요성

위의 코드는 양방향 매핑을 잘 해주지 않았기 때문에(team.setMember를 해주지 않아서) 1차캐시에 애초에 findTeam.getMembers가 없다. 그래서 size=0이 나온것하지만 저렇게 단방향으로만 매핑을 해주어도 서로 참조가 가능하긴하다. 그래서 아래와
7.null, null값을 넣으면 안되는 이유
ㅇㅁㄴㅇㅁㄴㅇㅁㄴㅇㅁㅇ디티오탈 ㅇ
8.프록시
JPA에서 프록시는 연관된 객체들을 데이터베이스에서 조회하기 위해서 사용합니다.프록시를 사용하면 연관된 객체들을 처음부터 데이터베이스에서 조회하는 것이 아니라 실제 사용하는 시점에 데이터베이스에서 조회할 수 있습니다.하지만 자주 함께 사용되는 객체들은 조인을 사용해서
9.JPA 입문(1)
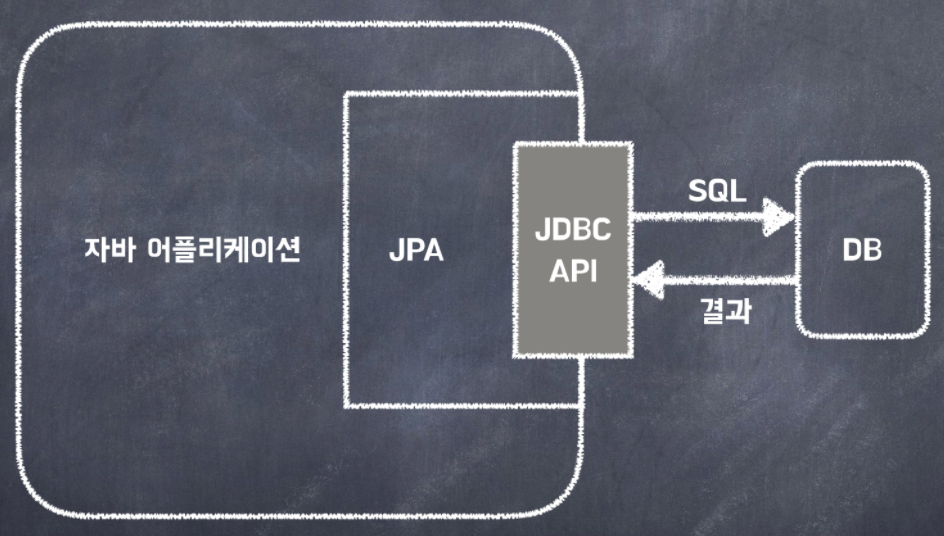
JDBC(Java Database Connectivity)는 즉 자바에서 DB에 연결하기 위해 제공되는 API로서 SQL(Structured Query Language)에 접근한다.JDBC 한 파일에서는 SQL작성, DB연결, Java언어가 모두 존재하기때문에 재사용성
10.JPA 질문 모음
제가 처음에 flush()와 commit()의 차이점을 잘 모르겠어서다른 글들을 읽어봤는데도 제가 궁금한 것이 풀리지 않아 질문드립니다.플러시를 하는 순간 쓰기 지연 SQL 저장소에서 DB에 반영이 된다고 하셨는데, 그런데 또 다른 글들을 보니 플러시를 한다고 해서 실
11.연관관계
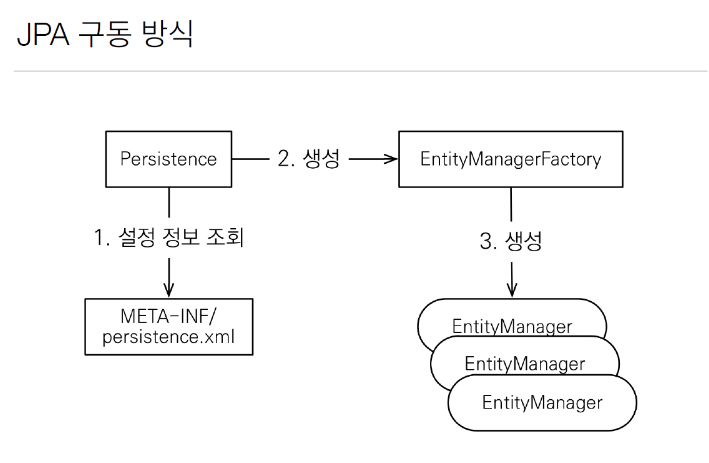
DB는 SQL만 알아들을 수 있다 -> SQL중심적인 개발하지만 SQL 중심적인 개발은 여러 문제가 생긴다기능하나 추가해서 테이블을 하나 만들더라도 CRUD쿼리를 다 짜야한다이런 반복적인 코드는 실수를 유발할 수 있다.관계형DB가 나온 사상 : 데이터를 잘 정규화해서
12.Idclass vs EmbeddedId
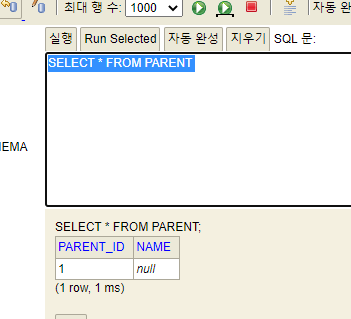
비식별child - 복합키parent을 idclass를 이용하여 구현식별복합키child - 단일키parent을 idclass를 이용하여 구현
13.조인테이블
각각에 onetoone을 적어주고 연관관계의 주인이 아닌쪽에 maddedby="연관관계의주인이아닌쪽"을써준다한쪽에 jointable(name, joincolumns, inversejoincolumns) 를 적어준다name : 조인테이블명 // -> 자동으로 jointa
14.JPA 입문(2)
매번 연관된 객체들을 불러오는것보다 일단 가짜객체를 불러와두고 실제로 연관된 객체를 사용할시점에 쿼리를 날려서 불러오는게 성능상의 이점이 있다. 이때 사용하는 가짜 객체가 프록시다.사용할시점에 쿼리를 날려서 불러오는 것을 지연로딩이라고한다.매번 연관된 객체들이 항상 사
15.JPA입문(3) - JPQL
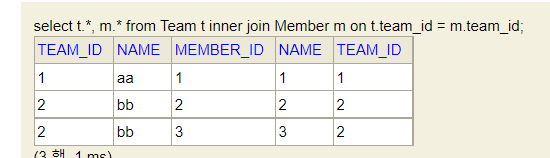
엔티티 객체를 대상으로 쿼리하는 객체지향 쿼리SQL을 추상화하기 때문에 DBMS에 의존적이지 않다JPQL은 결국 SQL로 변환된다TypeQuery : 반환타입지정가능 시Query : 반환타입지정 불가능 시(명확x시)JPQL을 생성하는 빌더클래스(?가뭐지)문자 대신 프로
16.쿼리DSL
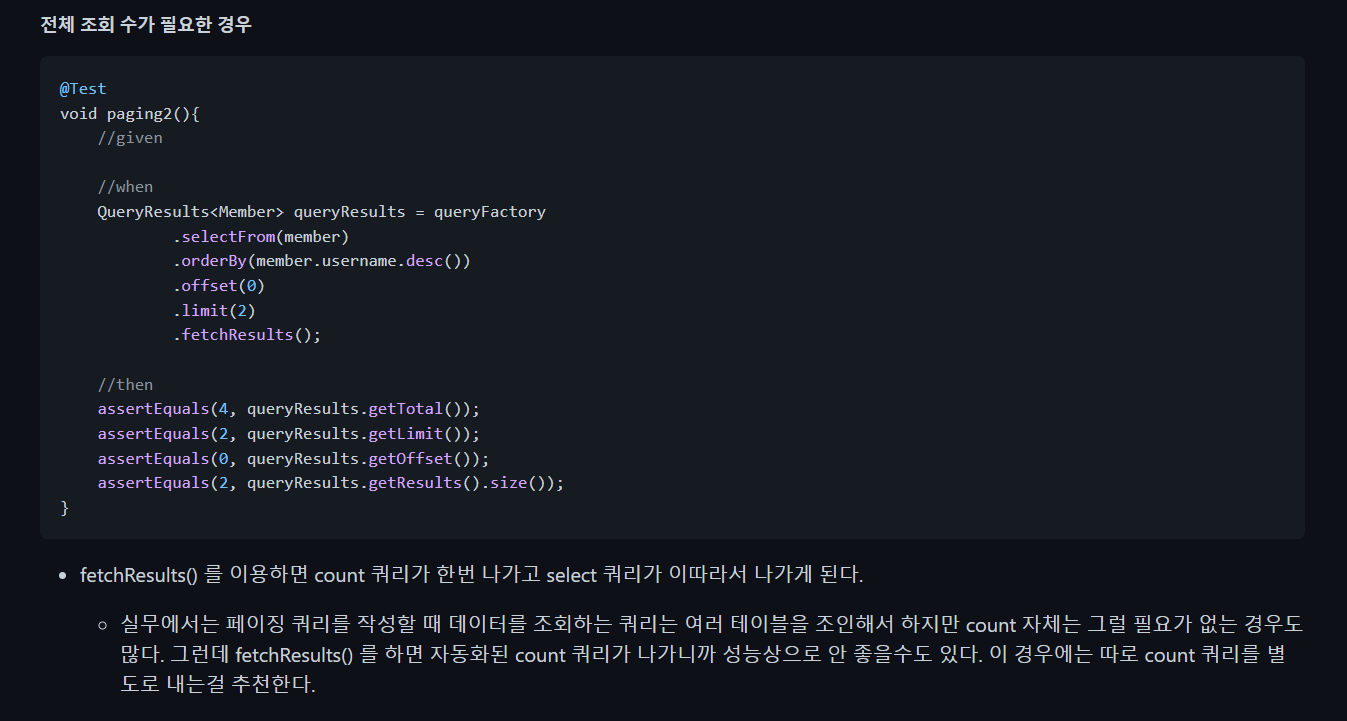
어떻게 하라는거지? 별도로 어떻게 내?.join(member.team, team1)에 넣어주는 team1은 QTeam을 선언해서 넣어줘야한다from 에 member, team이렇게 넣는다ON 절과 WHERE 절의 차이는 ON 절 같은 경우는 JOIN 할 데이터를 필터하
17.detached
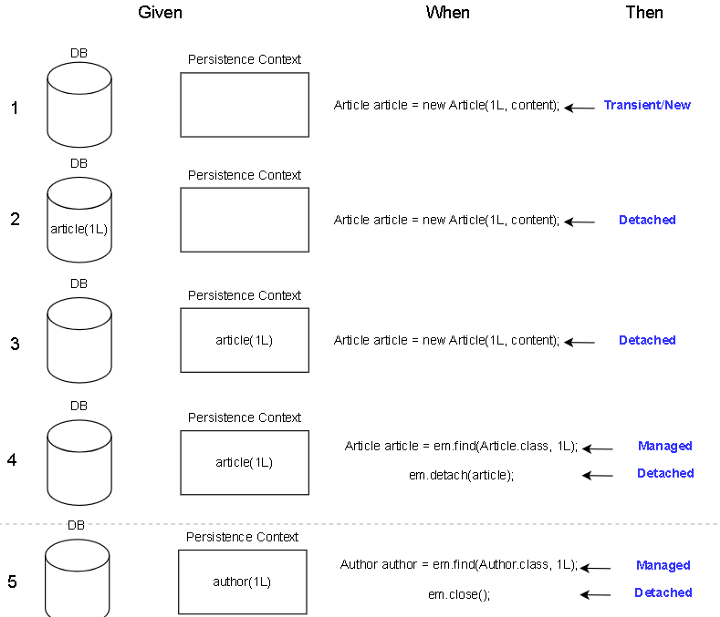
detached 상태는 제대로 표현한다면, "지속성이 보장되고 있지만 세션과 현재 분리된 상태"를 의미합니다.Detached 상태가 될 수 있는 상황들을 그림을 통해서 다시 설명드리겠습니다.첫번째 상황에서는 id가 1L에 해당하는 엔티티가 Persistence Cont
18.사용자 정의 리파지토리
https://dazbee.tistory.com/84다음은 두개의 인터페이스와 하나의 클래스의 정의예요쿼리dsl강의에서 이런식으로 정의를 하더라구요 그런데 이건 한개의 엔티티가 두개의 리파지토리를 만드는꼴아닌가요?그럼 헷갈릴텐데.,. 한개로 못합치나요? 왜 하
19.Querydsl

QuerydslPredicateExecutor을 상속받으면중간에 predicate(조건)를 통해서 결과를 필터링하는게 가능하다but 조인이 안됨repository에 predicate 파라미터를 넘겨줘야한다 -> 강한결합(강한 의존성)이 일어남Querydsl Web 지원
20.n+1 문제
팀과 user의 일대다 관계가 있다.5개의 팀과 5명의 유저가 있다team repo에서 findAll()을 하면 하나의 쿼리만 나갈것으로 예상된다.\-> select from team;하지만 추가적으로 team의 개수만큼의 쿼리가 더 발생한다.왜그러는것일까?1\. f
21.스프링 JPA의 사실과 오해
일대다 관계를 쓰면 안되는 이유 다대일관계의 Team과 Member가 있다. 그리고 이들을 cascade설정해두고 Team1, Member1,Member2가 있고 이들을 모두 묶은다음에 저장한다 그러면 3개의 insert쿼리가 나간다 (예상대로다) 하지만 일대다관계에서
22.domain, dto, setter, 사용자정의쿼리
사용자정의쿼리하는 방법쿼리메서드(메서드의 이름이 쿼리의 구문으로 처리되는)@Query@NamedQuery\-> 아래의 두가지방법은 거의 같다. 애플리케이션 로딩시점에 문법 체크한다.entity와 dto를 구분해야하는이유1\. 관심사의 분리entity라는것은 테이블과
23.jpa-2-활용(1)
controller는 api와 controller 디렉터리를 분리한다에러가 났을때 화면처리같은것을 보통 디렉터리단위로하는데 api에서 에러가났을경우에는 json으로 에러메세지를 줘야하는 반면 html을 뿌려주는 controller에서 에러가났을 경우에는 에러html페이
24.saveDto와 updateDto을 분리해야하는 이유
membersaveDto만있으면 memberupdatedto를 만들지 않아도돼요 둘다 만들게 되면 코드의 중복이 발생하는것아닌가요? save와 update는 아예다른것이기때문에 중복이 발생해도 상관이 없는걸까요? 아예다른것이라기엔 update에도 있고 save에도 있는
25.jpa2활용(2)
order을 select하는데 몇번의 쿼리가 나갈까?order는 member, delivery에서는 일에 대응되고order은 orderitemlist를 가지고 orderitem은 itemList를 가진다(order조회개수만큼)select memberselect deli
26.jpa활용1 복습
ObjectMapper사용ㄴ기본생성자로 객체 생성 후 리플렉션 해서 값을 주입함. 그래서 @setter와 @getter가 없어도됨json http body -> java객체 변환리플렉션을 사용하지 않는듯?리플렉션을 사용한다면 private한 필드에 대해 get,set이
27.fetch join 에서 alias가 필요한 이유
fetch join 시 alias를 사용해서 필터링하는게 왜 안되는걸까요?보통 이에 대한 답변으로 디비상태와 객체상태의 일관성이 깨지게 됨을 보통 얘기합니다.alias를 사용해서 필터링해버리면 실제 디비에 있는 데이터보다 적은 개수가 나오게 되니까요.근데 어차피 그 필