SQL 문장의 종류
DDL:데이터 정의어
DML:데이터 조작어
DCL:데이터 제어어(grant, revoke)
TCL:트랜젝션 제어어(commit, rollback)
0. SQL 작동원리
문제유형 1.
ORACLE은 DDL후 commit 된다.
SQLSERVER 는 DDL후 commit 되지 않는다.
문제유형 2.
DROP, truncate, delete 중 1, 2는 수행후 자동 commit된다.
1. CREATE TABLE 문과 제약조건 설정
create table 테이블명
(속성명 데이터타입 [DEFALT 기본값] [NOT NULL],[PRIMARY KEY(col1, col2)]
[UNIQUE (col1, B)] -- 후보기
[FOREIGN KEY(A, B)]
REFERENCES 참조T(참조속성)
[ON DELETE 옵션][ON UPDATE 옵션]
[CONSTRAINT PK명 PRIMATY KEY (PK속성)]
[CHECK(조건문)]
1. on update/delete
on update : 참조(1쪽원본) 테이블 값이 수정되었을 때 기본(M쪽)이 해야할 action지정
on delete : 참조(1쪽원본) 테이블 값이 삭제되었을 때 기본(M쪽)이 해야할 action지정
옵션: no action, cascade, set null, defalt
cascade :참조테이블속성이 변경되면 기본테이블 속성도 같이 변경
set null: 참조테이블 속성이 변경되면 기본테이블 속성도 null로 변경
defalt: 참조테이블 속성이 변경되면 기본테이블 속성도 defalt값으로 변경
2. 테이블 명 특수문자는 _ $ #만 사용가능
3. UNIQUE 키는 NULL이 허용된다.
4. PK는 1개만 존재하나 구성속성은 2개이상이 가능하다.
5. FK는 NULL이 허용된다.
2. ALTER TABLE 문
[ADD], [RENAME], [ALTER COLUMN], [DROP]
| 문장 | 기능 | 사용법 |
|---|---|---|
| ADD column | 새로운 컬럼을 추가할 때 사용한다. | alter table 테이블명 add 속성명 varchar2(10) |
| RENAME [column] | 새로운 테이블명, 속성명 설정 | alter table 테이블명 RENAME TO 새테이블명 alter table 테이블명 RENAME COLUMN 속성명 TO 새속성명 |
| ALTER column | 컬럼의 type을 수정할 때 사용한다. | alter table 테이블명 alter column 속성명 TYPE [데이터타입]/SET [제약조건]/ DROP[제약조건] 데이터타입(varchar. number 등), 제약(check, not null 등) |
| DROP column | 컬럼을 삭제할 때 사용한다. | alter table 테이블명 DROP COLUMN 속성명 |
집합연산자
1. 일반 집합연산자
| 기능 | 구현 | 집합명 |
|---|---|---|
| UNION | UNOIN | 합집합 |
| UNION ALL | UNION ALL | 단순 덧셈 (중복 제거 X) |
| INTERSECTION | INTERSECT | 교집합 |
| PRODUCT | CROSS JOIN | 카테시안 곱 |
2. 순수 관계 연산자
| 기능 | 구현 | 집합명 |
|---|---|---|
| select | where | 행 |
| project | select | 열 |
| join | join | 조인 |
| DVIDE | 현재 사용X | 현재사용X |
문제유형1: 기능과 구현을 바르게 짝지은 것은?
문제유형2: 순수관계 연산자로 옳은 것은?데이터의 유형
모든 영어 문자열은 1바이트이기 때문에 숫자만큼 입력이 가능하지만, 한국어는 1바이트가 넘기 때문에, 설정한 숫자가 길이가 아니다.
| 문자유형 | 의미 |
|---|---|
| CHAR(A) | A길이의 고정길이 문자열을 입력한다. 입력되지 않은 문자는 공백 입력 |
| VARCHAR2(A) | 최대 A길이의 변동길이 문자열을 입력한다. |
| NUMBER(A,B) | A길이의 소수점이 B길이인 변동길이 문자열을 입력한다. ex) NUMBER(8,2) = 6정수, 2소수점 자리 |
| date | 시간 데이터를 입력한다. |
문제유형1.
고정길이 문자열 "AA__" = "AA"
변동길이 문자열 "AA__" != "AA"
문제유형2.
where number = varchar 데이터 유형일 때 "모든" varchar데이터에 숫자가 입력되면 정상 비교 가능
문제유형3. DATE형에는 '20191231' 처럼 연도를 전부 사용할 경우, date로 자동 변환되어 입력이 가능하다.
=> '2014', 2014 등은 당연히 불가능
함수
1. 문자열 함수
| 문자열 | 의미 | 사용예시 |
|---|---|---|
| LOWER (A) | 영어 소문자를 출력한다. | LOWER('AQLP') = sqlp |
| UPPER (A) | 영어 대문자를 출력한다. | UPPER('sqlp') = SQLP |
| substr(A, m, n) | A문자열을 m위치에서 n글자 수만큼 출력한다. | substr("SQLP", 2, 2) = QL |
| LENGTH(A) | 문자열의 길이를 출력한다. | LENGTH('SQLP') = 3 |
| LTRIM(A, 지정문자) | 문자열의 왼쪽부터 지정문자가 있다면 제거한다. | LTRIM('SQLP', 'SP') = 'QLP' |
| RTRIM(A, 지정문자) | 문자열의 오른쪽부터 지정문자가 있다면 제거한다. | RTRIM('SQLP', 'SP') = 'SQL' RTRIM('SQLP', 'PS') = 'SQL' |
| TRIM(A) | 문자열의 양쪽에서 공백을 제거한다. | TRIM( 'SQLP' ) = 'SQLP' |
| REPLACE(A, 'B','C') | 문자열 A중 B문자를 C로 바꾼다. | REPLACE('SQLP', 'L','S') = SQSP REPLACE('SQLP', 'L')='SQP' |
2.숫자형 함수
| 문자열 | 의미 | 사용예시 |
|---|---|---|
| ABS (m) | 절대값 | ABS(-11) = 11 |
| SIGN (m) | 양수,음수 | SIGN(-11) = -1 |
| ROUND (m,n) | n자리수 만큼 반올림 | ROUND(11.23,1) = 11.2 ROUND(11.23,-1) = 10 |
| TRUNC (m,n) | n자리수 만큼 버림 | ROUND(11.27,1) = 11.2 |
| CEIL (m) | m을 올림 한 정수 | CEIL (-11.7) = -11 |
| FLOOR (m) | m을 내림한 정수 | FLOOR (-11.7) = -12 |
| MOD (m, n) | m을 n으로 나눈 나머지 | MOD (15, -4) =3 MOD (-15, -4) =-3 |
| POWER (m, n) | m의 n제곱 | POWER (2, 3) =8 |
| SORT (m) | m의 제곱근 | SORT (16) = 4 |
3.날자형 함수
| 문자열 | 의미 | 사용예시 |
|---|---|---|
| SYSDATE | 현재시간 | 2024-09-01 22:08:23 |
| EXTRACT (datetype FROM m) | 날짜의 데이터타입 출력 | EXTRACT (year FROM sysdate) |
| ADD_MONTH (to_date(sysdate, 'yyyymmdd') ,+1) | 1달 추가 계산 후 날가 없으면 맨끝의 날을 출력한다. | ADD_MONTH (to_date(20240131,1, 'yyyymmdd') ,+1) = 20240228 |
날자형 함수의 계산
문제유형 1.
TO_DATE('201501', 'yyyymm') = date
위 조건절은 1월 전체가 아닌 1월 1일의 데이터를 의미한다.4.NULL함수
| 문자열 | 의미 |
|---|---|
| NVL/ISNULL(m,n) | m이 null이면 n을 반환, 아니면 m출력 |
| NULLIF(m,n) | m이 n이면 null을 반환 |
| COALESCE(m,n,o...) | 가장 처음나오는 null아닌 것 출력 |
5.CASE WHEN 표현 2가지 + decode 표현
1. CASE A WHEN 1 THEN 성공 ELSE 실패;
2. CASE WHEN A=1 THEN 성공 ELSE 실패;| 문자열 | 의미 |
|---|---|
| DECODE(A,1,성공, 2, 실패, 오류) | A가 1이면 성공, 2면 실패 defalt=오류 |
문제 유형 1.
CASE문과 다른 결과를 내는 SQL 찾기
문제유형 2.
SELECT 절의 별명을 CASE 조건문으로 사용할 수 없다.where절 사용
1. 논리적 순서
문제유형1.
( ) -> NOT -> AND -> OR 순으로 처리한다.
문제유형2.
=컬럼의 좌우는 바뀌어도 같은 결과를 낸다.
문제유형3
where a = 1 or b=10 and c=20
의 결과는 [b=10 and c=20] or a=1 이다.
2. IN조건절 계산방법
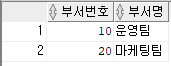
insert into 연습A values (10, '운영팀');
insert into 연습A values (20, '마케팅팀');
insert into 연습B values (10, '가철수');
insert into 연습B values (10, '다철수');
insert into 연습B values (20, '나철수');
select 연습A.부서번호, 연습A.부서명
from 연습A
where 연습A.부서번호 IN (select 연습B.부서번호
from 연습B);위 SELECT문에서 IN을 사용한 서브쿼리는 자동으로 DISTINICT 연산을 사용한다.
즉, 서브쿼리의 부서번호만 뽑았을 때 결과는 10, 20이 된다.
최종 쿼리결과는 아래와 같아진다.
3. LIKE 연산 방법
비교 연산자 사용이 문제로 많이 나온다.
LIKE 문자 사용 예시)
1. '_%' : 아무글자로 시작하는 문자
2. '_ _' : 1글자 + 띄어쓰기 + 1글자인 문자
3. ESCAPE 문자는 '_'나 '%'가 포함된 문자열을 검색할 때 사용한다.
ex1) where A like '%#%%' ESCAPE '#'
위 문장은 #뒤의 %문자를 문자로 인식한다. 즉, %컬럼을 포함하는 문자열을 출력한다.
[%사랑, 김%수민] => 정상출력
ex2) where A like '%_%' ESCAPE '_'
_로 끝나는 문자열을 출력한다.
4. NOT 연산시 주의사항
NOT IN연산
where A NOT IN ('SQLD', 'SQLP')
where A NOT ('SQLD' OR 'SQLP')
where A != SQLD AND A != SQLP조건절 분배되면서 OR가 AND로 변하였다.
같은 결과를 내는 SQL을 찾는 문제로 출제된다.
NOT BETWEEN연산
where NOT A BETWEEN 1 AND 5
where NOT (A >= 1 AND A <= 5)
where A<1 OR A> 5조건절 분배되면서 AND가 OR로 변하였다.
같은 결과를 내는 SQL을 찾는 문제로 출제된다.
Group by와 집계함수 + Having절
1. SQL 처리 순서
FROM -> where -> group by -> having -> select -> order by
GROUP BY는 집계함수 사용시 가능하며, select, having order by절에 사용한다.
그러나 WHERE 절에 사용할 수 없다.
문제유형1.
처리순서에 따라 AS를 사용할 수 있는 곳에 사용했는지 묻는다.
예를 들어 select절에 있는 AS을 having절에 사용할 수 없다.
문제유형2.
NULL을 Group by 하면 NULL로 묶인다.
문제유형3.
group by를 사용한채 select에 집계함수를 2중으로 사용할 경우 ERROR
ex) select AVG(count (*))
group by ID
위 쿼리는 ID별로 출력해야하는데 집계함수가 1건만 출력함으로 ERROR
2. having절
문제유형1.
select 절에 안쓴 집계함수 having절에 사용해도 되는가?
= 당연히 된다.
문제유형2.
group by 없이 having절을 사용하는 경우는
테이블 전체를 대상으로 집계합수를 사용한 경우이다. ex) having count(*) = 1
따라서 결과가 having절을 만족하면 1건, 만족 못하면 공집합을 출력한다.
order by절
1. DBMS별 NULL 저장차이
오라클은 NULL을 가장 큰값에 둔다. SQL SERVER는 가장 작은값에 NULL을 두고 정렬한다.
2. 시간저장 차이
ASC 과거의 시간 -> 미래의 시간
DESC 미래의 시간 -> 과거의 시간
순으로 정렬된다.조인
EQUEL 조인
문제유형 1.
조인시 where 절을 사용하지 않으면, "카테시안 곱"이 발생한다.
문제유형 2.
조인 컬럼을 select절에서 출력시 어느 테이블 명을 붙이던 상관없이 같은 결과를 출력한다.
문제유형 3.
조인되는 두 테이블 사이에 같은 이름의 속성명이 없으면 select 절에서 테이블 명을 생략가능하다.
NON- EQUEL 조인
문제유형 1.
non-equel 조인에서 조인컬럼을 select 절에서 사용시 테이블 명에 따라 "다른 결과"를 출력한다.
문제유형 2.
대부분의 경우 non-equel 조인 사용이 가능하나, 설계상 불가능 한 경우가 종종 있다. OUTER 조인
문제 유형 1
테이블 조인과 그 결과를 맞추는 문제가 사용된다.
예를 들어
FROM A LEFT OUTER JOIN B ON(A.고객번호 = B.고객번호 AND A.고객번호 IN(100, 200))
LEFT OUTER JOIN C
A와 B를 LEFT OUTER JOIN하되, A.고객번호가 100, 200인것만 조인하고, 그 외에는
조인컬럼이 존재해도 NULL이 입력된다. 즉, 조인만 안되서 NULL이입력되지, 결과집합에서 안나오는 것은 아니다.
결과집합에서 제외하고 싶다면 where절을 이용해야 한다.
문제 유형 2
아래는 조인컬럼 이다. LEFT, RIGHT, FULL outer 조인 결과를 출력해라.
A = 1, 3, 5
B = 2, 3, 3
LEFT = 1, 3, 3, 5
RIGHT = 2, 3, 3
FULL = 1, 2, 3, 3, 5
NATURAL JOIN
두 테이블의 같은 이름을 가진 컬럼의 속성값이 모두 동일할 때 조인된다.
문제 유형 1
두 테이블의 공통된 이름의 컬럼은 select 절 위치에 테이블명을 사용해서는 안된다.
이는 USING에 지정된 컬럼도 마찬가지다.
NATURAL JOIN 대체 : INNER JOIN USING
Natural 조인을 using절로 일부만 대체하여 사용할 수 있다.
문제 유형 1
select cast, A.gender
...
USING(cast, gender)
select절에 테이블 명을 사용하여 오류
CROSS JOIN
별도의 조인 조건이 없는 경우
문제 유형 1
select *
from A, B
where B / 5= 0
위 쿼리는 조인조건이 없기 때문에 A, B의 곱만큼 결과가 나온다.UNION 절
유니온은 UNION ALL + DISTINICT 연산을 뜻한다.
문제 예제 1
select a컬럼, b컬럼
from A
union all
select null, b컬럼
from B
union all
select a컬럼, null
from C
A, B, C를 group by 후 count 하면 groupo by

DB가 좋아요