서브쿼리의 종류와 특징
| 서브쿼리 | 내용 | 종류 |
|---|---|---|
| 단일행 서브쿼리 | 서브쿼리의 결과가 1개 행이다. | =, >=, <= 등 |
| 다중행 서브쿼리 | 서브쿼리의 결과가 2개 이상 행이다. | IN, EXISTS, ALL, ANY 등 |
| 다중쿼리 서브쿼리 -ORACLE ONLY- | 서브쿼리의 결과가 여러 칼럼이다. | (a,b) IN (select a, b)등의 다중컬럼 형태 |
| 연관 서브쿼리 | 서브쿼리가 메인쿼리 참조 O 주용도: 메인쿼리가 먼저 실행되어 서브쿼리에서 조건이 맞는지 필터링 | (select * from dual where 조건 = A.메인조건) |
| 비연관 서브쿼리 | 서브쿼리 메인쿼리 참조 X 주용도: 서브쿼리가 먼저 실행되어 메인쿼리 실행을 위한 값을 제공 | (select * from dual) |
서브쿼리는 보통 메인쿼리가 먼저 실행되며, 메인쿼리(1)쪽 집합만큼 결과를 낸다.
문제유형 1. 행 서브쿼리 종류를 외워 오류가 나는지 않나는지 확인한다.
예를 들어 같은 SQL에 단일행서브쿼리를 사용시 결과가 1건이면 오류나지 않는다.
문제유형 2. 연관서브쿼리,비연관 서브쿼리의 주 역할
집합 연산자
| 집합연산자 | 연산 |
|---|---|
| UNION | DISTINICT + 합집합 |
| UNION ALL | NOT DISTINICT + 합집합 |
| INTERSECT | DISTINICT + 교집합 |
| EXCEPT | 차집합 |
문제유형1
3개이상의 테이블을 조인하면서, A UNION ALL B UNION C 순서대로 놓고 DISTINICT 여부를 묻는다.
문제유형2
UNION 연산시 서로다른 테이블에 GROUP BY 절과 ORDER BY절의 처리가 어떻게 되는지 묻는다.
답:
1. GROUP BY는 각각의 테이블에 따로 적용뒤 결과집합만 더한다.
이 때 결과값이 똑같다면 그것도 DISTINICT 된 채로 출력한다.
2. ORDER BY는 가장 마지막 테이블에 사용한 것을 기준으로 적용된다.
윈도우 함수
SUM함수
SUM() = 누적합계를 구하는 함수이다.
문제유형 1. 각 문법별 출력 결과의 차이를 묻는다.
유형1: SUM(score) OVER (PARTITION BY student_name)
col 2 파티션별로 나눈 col1컬럼의 SUM을 구한다.
유형1
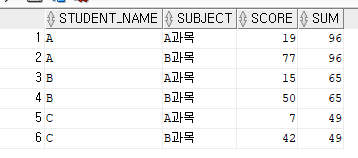
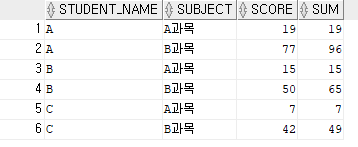
유형2: SUM(score) OVER (PARTITION BY STUDENT_NAME ORDER BY SUBJECT range unbounded preceding)
STUDENT_NAME 파티션별로 SUBJENT로 정렬된 SCORE의 점진적 누적합을 구한다.유형2
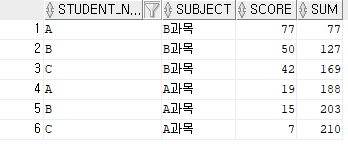
유형3: SUM(score) OVER (ORDER BY score desc) -- col1로 order by절만 사용한 경우
where subject = B과목
ORDER BY UNBOUNDED 없이 최종 누적합을 구한다.
문제 유형 2: SUM() 윈도우 함수 없이 누적합 구하기 : >= 등의 NON-EQUEL 비교연산자를 사용하면 된다.
핵심: SELECT에 A.일자, B.일자를 쓰는가에 따라 결과가 달라진다.
+ 부등호의 방향에 따라서도 결과는 달라진다.
ex)
1년 매출 A(=B)테이블에는 1월 ~12월 데이터존재 각각 1000씩 매출액 저장
유형 1.
select A.일자, SUM(매출액) as 누적매출액
from 1년매출 A, 1년매출 AS B
where A.일자 >= B.일자
group by A.일자;
위 쿼리는 정상작동한다.
A.일자 1 -> B.일자 1
A.일자 2 -> B.일자 1, 2
A.일자 3 -> B.일자 1, 2, 3
유형2. SELECT 절이 B.일자 일 때
select B.일자, SUM(매출액) as 누적매출액
from 1년매출 A, 1년매출 AS B
where A.일자 >= B.일자
group by B.일자;
위 쿼리는 정상작동하지 않는다.
B.일자 1 -> A.일자 1,2,3,4,5,6,7,8,9,10
B.일자 2 -> A.일자 2,3,4,5,6,7,8,9,10
B.일자 3 -> A.일자 3,4,5,6,7,8,9,10`순위함수
| 순위함수 | 예시 |
|---|---|
| RANK | 1, 2, 2, 4 |
| DENSE_RANK | 1, 2, 2, 3 |
| ROW_NUMBER | 같은 값이어도 행순서에 따라 값을 매긴다. 1, 2, 3, 4 |
행순서 함수
| 행순서 함수 | 예시 |
|---|---|
| FIRST_VALUE | 첫번째 값을 읽어온다. |
| LAST_VALUE | 마지막 값을 읽어온다. |
| LAG(col, N ,defalt) | N번째 이전행의 값을 읽어온다. |
| LEAD(col, N ,defalt) | N번째 이후행의 값을 읽어온다. |
비율 함수
| 비율 함수 | 예시 |
|---|---|
| CUME_DIST | 누적 백분율을 구한다. |
| NTILE(N) | 전체행을 N등분 한 비율을 구한다. 나머지값은 순서대로 채운다. |
| RATIO_TO_REPORT | (속성 값/전체 값) 비율을 구한다. |
| PERSENT_RANK | 0부터 시작한다. 행 순서 기준 백분율을 구한다. 같은값은 같은 비율로 출력한다. |
유형3
where 조건절한경우

where 조건절을 하지 않은 경우
계층형 질의
문제 유형 1: 순방향과 역방향에 대한 질문을 한다.
순방향: 루트 -> 리프 (아래로)
역방향: 피르 -> 루트 (위로)
PRIOR을 사용 가능한 곳 = SELECT, WHERE, CONECT BY 등으로 conect by에만 사용가능한것은 아니다.
PRIOR 을 하위에 두면 아래로 향해 정방향/ 상위에 두면 위로향해 역방향이다.
1. 정방향
connect by prior 지부명 = 상위지부명;
or
connect by 상위지부명 = prior 지부명;
2. 역방향
connect by 지부명 = prior 상위지부명;
or
connect by prior 상위지부명 = 지부명;
문제 유형 2
START WITH절은 where절로 필터링 하는게 아닌이상,
connect by절에서 필터링을 시도하더라도 반드시 들어간다.
ex) connect by prior 하위 = 상위 AND 입사일자 between 2012 and 2013;
위 문장에서 start with에서 필터링하려 했지만 start인 2010년 데이터가 들어간다.
문제유형 3
LEVEL절은 START부터 레벨 1로 지정되며 순/역방향 상관없이 시작된 곳이 레벨 1이다.
문제유형 4
ORDER BY SIBILING절에 대해 묻는다.
답: 레벨별로 정렬하는 쿼리이다. 이게 없으면 각 레벨 사이에서 정렬되지 않느다.
GRANT 와 REVOKE
문제유형1. 권한 부여하기
GRANT 권한명1 , 권한명2, [role] ON 테이블명 TO 유저명
[public], [role] [WITH GRANT OPTION]
-권한명 [DBA, RESOURCE:DB나 테이블 생성가능 권한, CONNECT: 단순 사용자 권한, ALL =전부]
-public = 자신이가진 모든 권한 모든 사람에게 부여
-role =부여할 ROLE/부여받을 ROLE
-WITH GRANT OPTION = 부여받은 권한을 다른 사용자에게 다시 부여할 수 있는 권한
문제유형2. 권한 삭제하기
REVOKE [GRANT OPTION FOR] 권한명1 , 권한명2 ON 테이블명 FROM 유저명 [CASCADE]
- [GRANT OPTION FOR] : (권한명1,2)를 대상으로 권한부여 권한을 취소
- CASCADE : 권한 취소시 권한을 부여받은 사용자가 다른사용자에게 부여한 권한도 취소

DB가 좋아요