1. 서브 쿼리
서브쿼리는 하나의 SQL문 안에 포함, 종속된 또 다른 SQL문을 뜻한다. 서브쿼리는 항상 메인쿼리 레벨로 결과집합이 생성된다. 서브쿼리는 괄호로 감싸서 기술하며, where절이나, select절에 사용하는 서브쿼리는 order by를 사용하지 못한다.
서브쿼리는 다음과 같이 분류할 수 있다.
동작 방식에 따른 분류
| 서브쿼리 종류 | 설명 |
|---|---|
| 연관 서브쿼리 | 서브쿼리가 메인쿼리의 컬럼을 가진 형태, 대부분 메인쿼리가 먼저 수행되어 읽혀진 데이터를 서브쿼리에서 조건이 맞는지 확인할 때 사용한다. |
| 비연관 서브쿼리 | 메인쿼리에 값을 제공하기 위한 서브쿼리, 서브쿼리가 메인쿼리의 컬럼을 가지지 않는다. |
반환되는 데이터의 형태에 따른 분류
| 서브쿼리 종류 | 설명 |
|---|---|
| 단일행 서브쿼리 | 서브쿼리 실행결과가 1건이하인 서브쿼리, 단일행 비교 연산자와 함께 사용되며, =,<,<=,>,>=,<>등이 있다. |
| 다중행 서브쿼리 | 서브쿼리 실행결과가 여러개인 서브쿼리, IN, ALL, ANY, SOME, EXISTS 등이 있다. |
| 다중칼럼 서브쿼리 | 서브쿼리 실행결과가 여러개의 칼럼으로 이루어진 서브쿼리 ex) where (a,b) = (select c,d) |
단일행 서브쿼리
서브쿼리의 결과가 두개이상 나오면 반드시 오류가 나오기 때문에 주의해야한다.
select PLAYER_NAME AS 선수명, POSITION AS 포지션, BACK_NO AS 백넘버
from PLAYER
where TEAM_ID = (select TEAM_ID
from PLAYER
where PLAYER_NAME = "김정은")
위 쿼리에서 김정은이라는 이름이 두명이상 있으면 오류가난다.
단일행 비교 연산자인 =은 두개이상의 결과를 받아들일 수 없기 때문이다.
참고* 평균키 이하인 선수 구하기
select PLAYER_NAME AS 선수명, POSITION AS 포지션, BACK_NO AS 백넘버
from PLAYER
where HEIGHT <= (select AVG(HEIGHT)
from PLAYER)
다중행 서브쿼리
서브쿼리의 결과가 두개이상 나올 수 있는 서브쿼리
| 다중 행 연산자 | 설명 |
|---|---|
| IN(서브쿼리) | 서브쿼리 결과에 존재하는 임의의 값과 동일한 결과를 가진다. |
| 비교연산자 ALL(서브쿼리) | 서브쿼리 전체를 기준으로 비교연산하여, 만족하는 결과를 가진다. |
| 비교연산자 ANY(서브쿼리) | 서브쿼리중 일부를 기준으로 비교연산하여, 만족하는 결과를 가진다. |
| EXISTS(서브쿼리) | 서브쿼리의 결과를 만족하는 만족하는 값이 존재하는지 여부만 확인하며, 1건을 찾으면 더 이상 검색하지 않는다. |
- IN 연산자
select *
from PLAYER
where TEAM_ID IN (select TEAM_ID
from PLAYER
where PLAYER_NAME = "김정은")
1. 서브쿼리의 값을 모두 출력하여, 메인쿼리의 결과값과 비교한다.
2. 그 중 메인쿼리의 값과 일치하는 모든 행을 출력한다.
-------------------------------------------------------------------- ALL 연산자
select *
from PLAYER
where SAL >= ALL (select SAL from 축구선수 where 선발코드 = 30)
선발코드 = 30을 가진 축구선수 전체를 기준으로 (ex)최고연봉 50억)
그것보다 높은 연봉을 가진 운동선수들을 모두 출력한다.
-------------------------------------------------------------------- ANY 연산자
select *
from PLAYER
where SAL >= ANY (select SAL from 축구선수 where 선발코드 = 30)
선발코드 = 30을 가진 축구선수 아무나를 기준으로 (ex)최소연봉 1억)
그것보다 높은 연봉을 가진 운동선수들을 모두 출력한다. 다중 칼럼 서브쿼리(SQL SURVER 지원 X)
여러개의 행이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미한다.
select *
from PLAYER
where (TEAM_ID, HEIGHT) IN (SELECT TEAM_ID, MIN(HEIGHT)
FROM PLAYER
GROUP BY TEAM ID)
1. 서브쿼리의 결과값으로 두개의 칼럼(팀 ID와 팀별가장작은키)이 나타난다.
2. 메인쿼리에서 서브쿼리값과 일치하는 모든행을 출력한다.
이 때, 키가 가장작으면서 같은사람을 모두 출력된다.연관 서브쿼리
서브쿼리 내에 메인쿼리의 컬럼이 사용된 서브쿼리다.
select B.팀명, A.선수명, A.포지션, A.백넘버, A.키
from PLAYER A, TEAM B
where A.HEIGHT < (SELECT AVG(X.키)
FROM PLAYER X
WHERE X.TEAM_ID = A.TEAM_ID -->조인으로 사용됨
GROUP BY X.TEAM_ID
AND B.TEAM_ID = A.TEAM_ID
ORDER BY 선수명
1. 메인쿼리를 실행해 모든 선수들을 정렬한다.
2. 선수를 하나씩 서브쿼리와 비교해 자식이 속한 팀의 평균키보다 작은 선수들만 최종 출력한다. Exists 서브쿼리
하나의 결과만 있어도 출력한다.
select 경기장_ID
from 경기장 a
where EXISTS (select 1
from 스케쥴 x
where x.경기장_ID = a.경기장_ID ---->조인으로 사용됨
and x.경기일자 BETWEEN '20220101' AND '20221231')
2022년에 경기가 하나라도 있는 경기장을 모두 출력한다.기타 서브쿼리
스칼라 서브쿼리(select 절)
인라인뷰(from절)
HAVING절 서브쿼리
HAVING 절은 집계함수를 사용할 때 그룹핑된 결과에 대해 부가적인 조건을 주기위해 사용한다.
select A.TEAM_ID, B.TEAM_NAME, round(avg(a.height), 3) AS 평균키
from PLAYER A, TEAM B
where B.TEAM_ID = A.TEAM_ID
GROUP bY A.TEAM_ID, B.TEAM_NAME
HAVING AVG(A.HEIGHT) < (SELECT AVG(X.HEIGHT)
from PLAYER X
where X.TEAM_ID IN (SELECT TEAM_ID
FROM TEAM
WHERE TEAM_NAME = "한화"))
1, 한화의 모든 선수를 뽑는다.
2. 한화의 모든 선수의 평균키를 뽑는다.
3. 한화의 모든 선수의 평균키보다 낮은 평균키를 가진 팀_ID와 팀_NAME을 그룹핑하여 결과를 출력한다.
뷰
테이블은 실제로 데이터를 가지지만, 뷰는 실제데이터를 갖지 않는다. 단지 뷰 정의만을 갖고 있다. DB에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS내부적으로 질의를 재작성해 질의을 수행한다.
뷰의 장점
| 뷰의 장점 | 설명 |
|---|---|
| 독립성 | 테이블 구조가 변경되어도 뷰를 사용하는 응용프로그램은 변경하지 않아도 된다. |
| 편리성 | 복잡한 질의를 단순한 형태로 바꿀 수 있다. 특히 자주 사용하는 SQL에 효과적이다. |
| 보안성 | 뷰 생성시 가리고 싶은 컬럼이 있다면 빼고 생성함으로써 정보를 감출 수 있다. |
뷰의 사용법
뷰는 다음과 같이 create view문을 사용하여 생성할 수 있다.
CREATE VIEW v_player_team AS
select A.player_name, A.posittion, A.back_no, B.team_id, B.team_name
from player A, team B
where B.team_id = A.team_id
뷰는 테이블 뿐 아니라 뷰를 참조해서도 사용할 수 있다. 이 때, from절에 테이블명 대신 view이름을 넣으면 된다.
select player_name, position, back_no, team_in, team_name
from v_palyer_team
where player_name LIKE "황%"
위의 뷰는 옵티마이저가 SQL을 아래처럼 재작성한 것이다.
select player_name, position, back_no, team_in, team_name
from (select A.player_name, A.posittion, A.back_no, B.team_id, B.team_name
from player A, team B
where B.team_id = A.team_id
where player_name LIKE "황%"
뷰 제거는 DROP VIEW를 사용하여 제거한다.
DROP VIEW v_player_team
2. 집합연산자
조인을 사용하지 않고 두개 이상의 테이블을 조회하는 방법이있다. 바로 집합연산자를 사용하는 방법이다. 집합연산자는 행과행을 연결하는 조인과 달리 각 테이블 마다 개별적으로 추출한 "검색결과"를 하나로 합쳐서 출력하는 방법으로 조회화면을 출력한다.
집합연산자는 동일 테이블에서 서로다른 질의를 수행해 결과를 합칠때 사용한다.
주의할 점으로는 반드시 select절의 칼럼의 수가 동일해야하며, select절의 동일 위치에 존재하는 칼럼의 데이터 타입이 동일해야만 오류를 피할 수 있다.
집합연산자의 종류 (oracle, sqlsurver)
| 집합연산자 종류 | 설명 |
|---|---|
| UNION | 개별 SQL문의 결과에 대해 합집합 연산을 수행한다. 단, 결과에서 중복된 행은 하나의 행으로 만든다. |
| UNION ALL | 개별 SQL문의 결과에 대해 합집합 연산을 수행하며 중복된 행도 그대로 표시된다. 두 집합이 상호 배타적일 때 사용 |
| INTERSECT | 개별 SQL문의 결과에 대해 교집합 연산을 수행한다. 단, 결과에서 중복된 행은 하나의 행으로 만든다. |
| MINUS, EXCEPT | 개별 SQL문의 결과에 대해 차집합 연산을 수행한다. 단, 결과에서 중복된 행은 하나의 행으로 만든다. |
집합연산자의 사용법
select
from
where
group by
having
집합연산자
select
from
where
group by
having
order by
*이 때 order by는 테이블이 집합된 최종결과를 대상으로 정렬한다.두 집합간의 중복된 행을 확인하는 방법
아래는 ID가 K2면서 포지션이 GK인 중복된 행을 확인하고 싶다.
select의 모든 칼럼을 group by해줌으로써 개개의 속성값을 기준으로 그루핑 해주었다.
즉, count가 1이면 unique하다는 뜻이며, 2이상은 중복된 행이라는 뜻이다.
select 팀코드, 선수명, 포지션, 백넘버, 키, count(*) as 중복수
from (select 팀코드, 선수명, 포지션, 백넘버, 키
from PLAYER
where ID = "K2"
union all
select 팀코드, 선수명, 포지션, 백넘버, 키
from PLAYER
where POSITION = "GK")
GROUP BY 팀코드, 선수명, 포지션, 백넘버, 키
HAVING COUNT(*) > 1;1. union 추가 설명
union은 아래와 같이 사용한다.
select ... from ...
where ID = "K7"
union
select ... from ...
where ID = "K2"
------------------------------------------
위 쿼리는 동일 테이블끼리 집합할 때 아래와 같이 바꿀 수도 있다.
select DISTINICT ... from ...
where ID = "K7"
OR ID = "K2"2. minus(except) 추가 설명
아래는 minus 연산자를 사용한 예 이다.
select ... from ...
where ID = "K7"
minus
select ... from ...
where position = "GK"
order by 1, 2, 3, 4, 5 - minus는 select절 전체를 order by 해주어야 한다.
--------------------------------------------------
위 쿼리는 아래와 같이 바꿀 수도 있다.
select DISTINICT ... -이거 왜 distinict 해주냐?
from PLAYER A
where ID = "K7"
and not exists (select 1
from PLAYER X
where X.ID = A.ID
AND X.POSITION = "GK") - GK가 아닌 것을 만족해야 함을 의미
ORDER BY 1, 2, 3, 4, 5
-------------------------------------------------
위 쿼리는 아래와 같이 바꿀 수도 있다.
select DISTINICT ...
from PLAYER A
where ID = "K7"
and not IN (select A.ID
from PLAYER A
where X.POSITION = "GK") - GK가 아닌 것을 만족해야 함을 의미
ORDER BY 1, 2, 3, 4, 5
------------------------------------------
위 쿼리는 동일 테이블끼리 집합할 때 아래와 같이 바꿀 수도 있다.
select DISTINICT ... from PLAYER
where ID = "K7"
and POSITION <> "GK"
ORDER BY 1, 2, 3, 4, 5intersect 추가 설명
intersect는 교집합이다. 사용 방법은 minus 설명부분에서 NOT을 빼준 것과 똑같다.
3. 그룹 함수(ANSI/ISO)
그룹함수는 데이터 분석을 위한 함수이다.
- 집계함수
- 그룹함수
- 윈도우 함수
집계함수
집계함수는 그룹집계함수라고도 부르며, COUNT, MIN, AVG, MAX, MIN 외 각종 집계 함수들이 포함되어 있다.
그룹함수
그룹함수는 소계, 합계, 총합계 등의 여러 레벨(LEVEL)을 가지는 데이터 처리에 사용한다.
- ROLLUP 함수 : GROUP BY의 확장형, 소그룹 간의 소계를 계산하는 함수.
- CUBE 함수 : GROUP BY 항목간 다차원적인 소계가 가능한 함수.
- GROUPING SET : 원하는 부분의 소계만 쉽게 추출할 수 있는 함수.
현재는 정렬기능을 수동으로 order by 해주어야 일정한 결과가 출력된다.
ROLLUP 함수
GROUP BY의 확장형 함수로, GROUP BY ROLLUP(칼럼)의 형태로 사용한다.
GROUP BY ROLLUP(A) : 전체합계 + A칼럼의 소계
GROUP BY ROLLUP(A,B) : 전체합계 + A칼럼의 소계 + 칼럼 A+B의 조합 소계
GROUP BY ROLLUP(A,B,C) : 전체합계 + A칼럼의 소계 + 칼럼 A+B의 조합 소계 + 칼럼A+B+C의 조합 소계
GROUP BY ROLLUP(A,(B,C)) : 전체합계 + A칼럼의 소계 + 칼럼 A+(B+C)의 조합 소계
CUBE 함수
GROUP BY CUBE(A) : 전체합계 + 칼럼 A의 소계
GROUP BY CUBE(A, B) : 전체합계 + 칼럼 A의 소계 + 칼럼 B의 소계 + 칼럼 A+B의 조합 소계
모든 칼럼에 대해 소계를 내기 때문에 성능이 매우 나쁘나, union all과 달리 테이블을 한번만 엑세스하기 때문에 union all 방식보다 빠를 수 도 있기에 성능을 고려하여 사용하여야 한다.
GROUPING SET
전체합계를 빼고 칼럼의 소계만 볼 때 사용한다.
GROUP BY GROUPING SET (A) : A칼럼의 소계
GROUP BY GROUPING SET (A, B) : A칼럼의 소계 + B칼럼의 소계
HOW TO USE?
ROLLUP 함수
select 직무, sum(연봉) AS 연봉합
from 사원
group by ROLLUP (직무)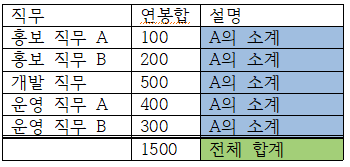
select 부서명, 직무, sum(연봉) AS 연봉합
from 사원
group by ROLLUP (부서명, 직무)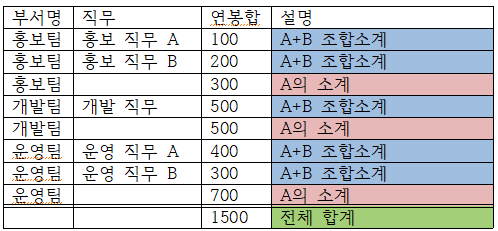
아래는 부서명을 GROUP BY 하고 직무만으로 ROLLUP 했을 경우이다.
select 부서명, 직무, sum(연봉) AS 연봉합
from 사원
group by 부서명 ROLLUP (직무)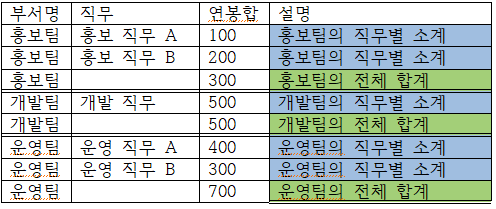
부서명 별로 테이블을 서로 쪼개놓은 상태에서 1.A의 소계와 2.전체합계를 구해준다고 생각하면 된다. 즉, 첫번쨰 테이블이랑 논리가 똑같다.
GROUPING 함수
grouping 함수는 rollup함수에 의해 집계가 일어나는 경우 1을 반환, 일어나지 않는 경우 0을 반환해주는 함수이다.
select 부서명, 직무, sum(SAL) AS 연봉합, GROUPING(DNAME), GROUPING(JOB)
from 사원
group by GROUPING (부서명, 직무) 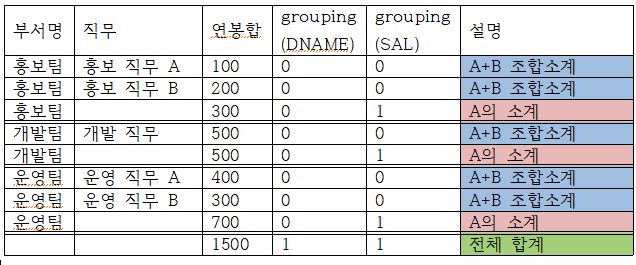
GROUPING(SAL)은 SAL을 기준으로 집계가 이루어 졌느냐를 따진다. A의 소계 부분이 부서명 구분 안에서 직무를 기준으로. 즉, 직무별로 소계가 이루어 졌기에 1을 반환한 것이다.
GROUPING(DNAME)은 부서명을 기준으로 집계가 이루어 졌기에 전체합계 부분에서 1을 반환하였다.
CUBE 함수
CUBE는 모든 칼럼을 기준으로 한 소계를 출력하는 함수다.
GROUP BY CUBE(A, B) : 전체합계 + 칼럼 A의 소계 + 칼럼 B의 소계 + 칼럼 A+B의 조합 소계
select 부서명, 직무, sum(SAL) AS 연봉합
from 사원
group by CUBE (부서명, 직무) 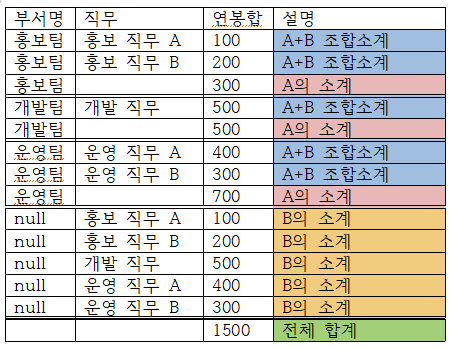
GROUPING SET
GROUPING SET는 필요한 부분의 소계만 출력하는 함수다. 전체합계는 출력하지 않는다.
select 부서명, 직무, sum(SAL) AS 연봉합
from 사원
group by GROUPING SET (부서명, 직무) 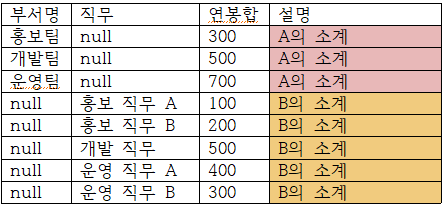
GROUPING SET로 조합소계를 내고 싶다면 아래와 같이 하면된다.
select 부서명, 직무, sum(SAL) AS 연봉합
from 사원
group by GROUPING SET (부서명, 직무, (부서명, 직무)) 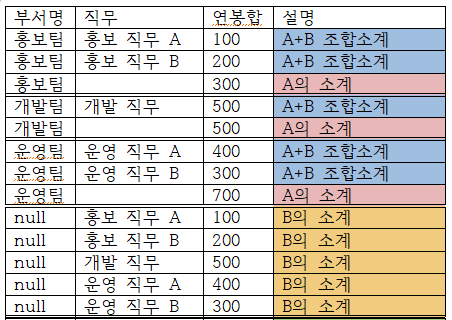
4. 윈도우 함수
윈도우 함수는 전체 테이블 안에서 새로운 테이블(창문)을 정의하여 분석하는 방법이다. 컬럼(열)과 컬럼간의 연산, 비교 연결은 select from where 절을 통해 집계할 수 있었다. 하지만 행과 행간의 관계를 정의하거나 행과 행간 비교연산하는것은 매우 어렵다. 이를 쉽게 정의 하기 위해 윈도우 함수를 사용한다.

윈도우 함수의 종류
- 그룹 내 순위함수 (RANK, DENSE_RANK, ROW_NUMBER)
- 그룹 내 집계함수(SUM, MAX, MIN, AVG, COUNT)
단, SQL SURVER에서는 OVER절 내의 ORDER BY를 지원하지 않는다. - 그룹 내 행 순서 관련 함수(FIRST_VALUE, LAST_VALUE, LAG, LEAD) ONLY ORACLE
- 그룹 내 비율 관련 함수(CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT)
1,2번째= (ANSI/ISO, ORACLE), 3번째 = (ORACLE, SQL SURVER), 4번째 = (ORACLE)
HOW TO USE?
(행을 분할, 행을 정렬, 행을 지정)
SELECT WINDOW FUNCTION(ARGUMENTS) OVER (PARTION BY 칼럼, ORDER BY절, WINDOWING절)
1. ARGUMENTS 자리에는 0~N개의 인수가 지정될 수 있다.
2. PARTION BY에는 행을 소그룹으로 나눌 수 있다.
3. ORDER BY절에는 정렬을 할 수 있다.
4. WINDING절에는 함수의 대상이 되는 행 기준의 범위를 강력하게 지정할 수 있다.(SQL SURVER 지원 X)
ROWS는 물리적인 결과"행의 수"를, RANGE는 논리적인 "값에 의한 범위"를 나타낸다.파티션 을 3개로 나눈 예 (출처:https://www.youtube.com/watch?v=2ec7S5tlGSI&t=55s)
사용 예
SELECT JOB, SUM(SAL) OVER (PARTITION BY JOB
ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) AS SUM_SAL
OVER 뒤에 사용된 문장들은 PARTITION -> ORDER BY -> WINDOWING 순으로 처리된다.
그리고,
ROW는 행
UNBOUNDED는 전체
PRECEDING는 윗부분을 뜻한다.
즉, JOB으로 파티션된 부분을 윈도우로 만들고, SUM_SAL에는 자기자신과 그 행 윗부분 전체의 합을 구한다는 뜻이다.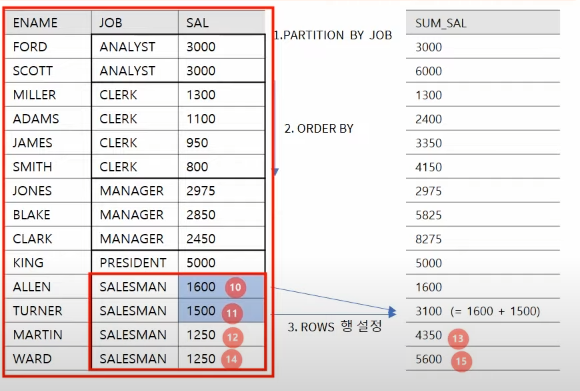
ROWS 사용법
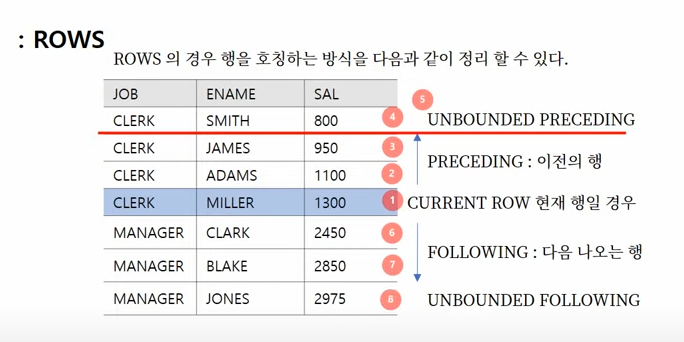
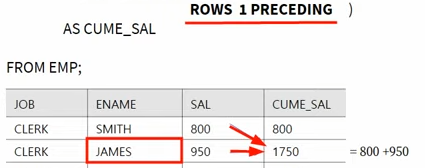
이 때, 전체라는 뜻의 UNBOUNDED PRECEDING 대신 1 PRECEDING 처럼 숫자가 나타난 경우, 전체 대신 윗 부분 한행만 집계하겠다는 뜻이다. FOLLOWING도 같은 논리로 사용할 수 있다.
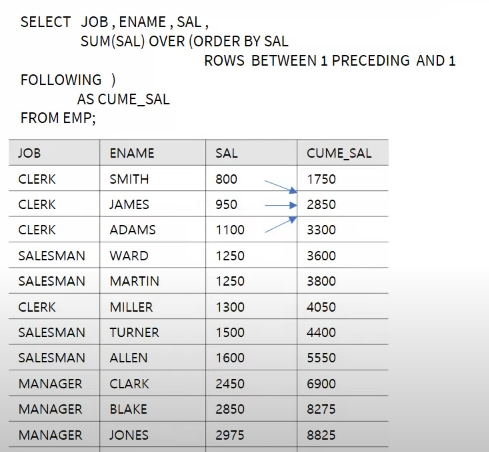
ROWS BETWEEN A AND B
양쪽 행을 기준으로 집계하고 싶을 때 아래와 같이 사용할 수 있다.
RANGE 사용법
RANGE는 값을 기준으로 집계하고 싶을 떄 사용할 수 있다.
예를 들어
select JOB, ENAME, SAL, SUM(SAL) OVER (ORDER BY SAL
RANGE 150 PRECEDING) AS CUME_SAL
FROM EMP
파티션을 해주지 않았기에 전체를 대상으로하며, 자기자신의 값과 그 보다 150이하의 범위만큼 작은 모든 행을 더한다.
아래는 950보다 작은 150 이하범위, 즉 950이하 800이상 인 모든 행을 더한 값을 출력한다.
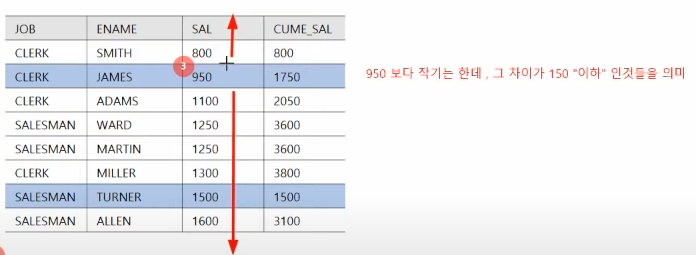
만약, 현재값보다 크면서 150이하인 범위를 구하고자 한다면 FOLLOWING을 대신 적어주면 된다.
RANGE BETWEEN A AND B
양쪽 값을 기준으로 집계하고 싶을 때 아래와 같이 사용할 수 있다.
select JOB, ENAME, SAL, SUM(SAL) OVER (ORDER BY SAL
RANGE BETWEEN 150 PRECEDING AND 150 FOLLOWING) AS CUME_SAL
FROM EMP
위 예제는 현재값을 기준으로 150이하 범위의 작은 값과 150이하 범위의 큰 값을 출력하는 쿼리이다.
1. 순위 윈도우 함수
그룹 내 순위함수 종류(RANK, DENSE_RANK, ROW_NUMBER)
RANK()함수는 순위를 구하는 함수이다. RANK함수에는 ()는 빈공간으로 놔둔다.
select ENAME, SAL, RANK() OVER (ORDER BY SAL) AS RANK
from emp
위 예제는 SAL을 기준으로 순위를 매기는 함수이다. 이 때, 같은 순위의 경우 아래처럼 표현한다. (1 2 3 4 4 6)
파티션 을 할경우 아래처럼 한다.
select ENAME, SAL, RANK() OVER (PARTITION BY JOB
ORDER BY SAL) AS RANK
from emp
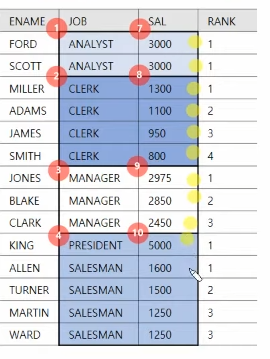
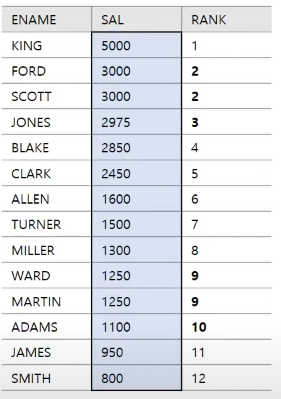
DENSE_RANK()함수는 같은 랭크가 있을 때 그 수만큼 띄어쓰지 않고 그대로 표현한다.
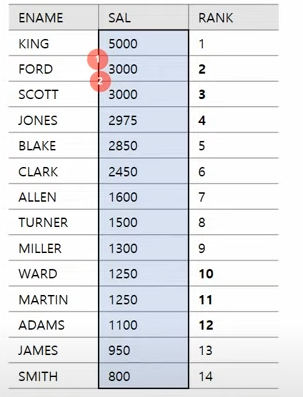
ROW_NUMBER()함수는 같은 수치라도 출력된 순서에 따라 랭크를 다르게 표현한다.
2. 행 순서 윈도우 함수(ORACLE)
그룹 내 행 순서 관련 함수 종류(FIRST_VALUE, LAST_VALUE, LAG, LEAD)
FIRST_VALUE함수는 파티션별 윈도우에서 가장 먼저 나온 값을 구하는 함수다.
SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) AS ENAME_FV
DEPTNO별로 파티션된 테이블에서 가장 먼저 나온 ENAME값을 구한다.
UNBOUNDED PRECEDING은 현재행을 기준으로 첫번쨰 행까지 범위를 지정한다. 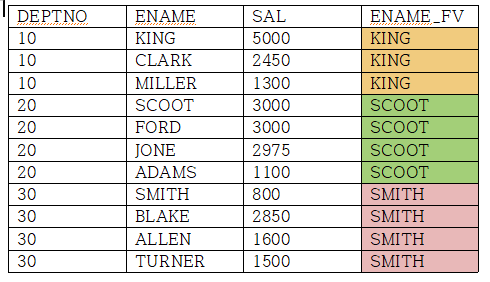
이 때 값이 같을 경우 먼저 나온 행의 값을 채택한다.
LAST_VALUE함수는 파티션별 윈도우에서 가장 마지막에 나온 값을 구하는 함수다.
SELECT DEPTNO, ENAME, SAL, LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS BETWEEN CURRENT UNBOUNDED FOLLOWING) AS ENAME_FV
DEPTNO별로 파티션된 테이블에서 가장 먼저 나온 ENAME값을 구한다.
UROWS BETWEEN CURRENT UNBOUNDED FOLLOWING은 현재행을 포함해 파티션내의 마지막 행까지 범위를 지정한다.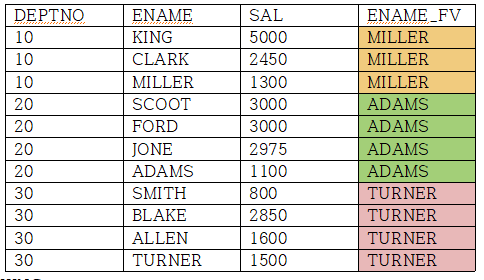
LAG 함수는 파티션별 윈도우에서 이전 몇번째 행의 값을 가져올 수 있다.
SELECT ENAME, HIREDATE, SAL, LAG(SAL,1,0) OVER (ORDER BY HIREDATE) AS LAG_SALLAG(1,2,3)에서
첫번째 인자는 가져올 값을 지정하며,
두번째 인자는 이전 몇번째 행을 가져올 건지 정하는 인자이고,
세번째 인자는 가져올 인자가 없을 때, 대신 넣어줄 값을 지정한다. DEFALT = NULL
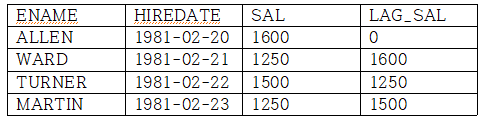
LEAD함수는 파티션별 윈도우에서 이후 몇번째 행의 값을 가져올 수 있다.
SELECT ENAME, HIREDATE, SAL, LEAD(SAL,1,0) OVER (ORDER BY HIREDATE) AS LEAD_SAL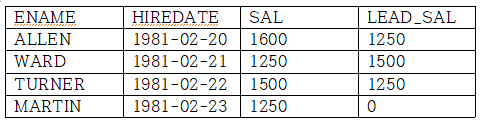
3. 비율 관련 윈도우 함수
그룹 내 비율 관련 함수 종류(CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT)
CUME_DIST()함수는 현재 행보다 같거나 작은 함수에 대한 누적 백분률을 구하는 함수이다.
select DEPTNO, ENAME, SAL, ROUND(CUME_DIST (PARTITION BY DEPTNO
ORDER BY SAL DESC),2) AS CD
FROM EMP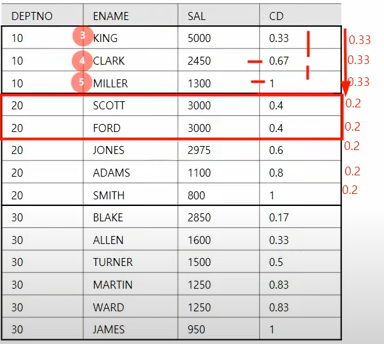
NTILE() 함수는 전체테이블을 N등분으로 나누어 줄 때 사용한다.

위 테이블은 4등분 되었으며, 나누고 난 나머지는 1번부터 순서대로 채워 넣는다.
RATIO_TO_REPORT()함수는 전체에서 원래값의 비율을 나타낼 때 사용하는 함수이다.
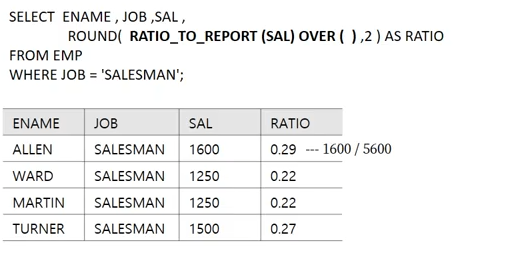
전체의
PERSENT_RANK()함수는 값을 기준으로 한게 아닌 행을 기준으로 한 백분율을 구하는 함수다.
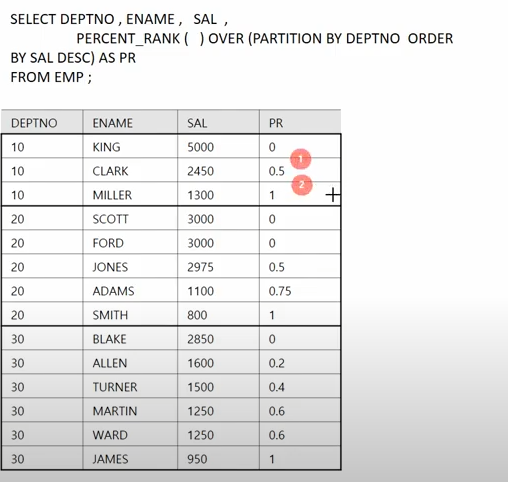
5. TOP N 쿼리
1. ROWNUM 슈도 컬럼(ORACLE)
슈도컬럼은 SQL처리 결과집합의 각 행에대해 임시로 부여되는 일련번호로, ORACLE은 ROWNUM을 사용하며, where절에서 행의 개수를 제한하는 목적으로 사용된다.
SELECT ENAME, SAL
FROM (SELECT ENAME, SAL
FROM EMP
ORDER BY SAL DESC)
where ROUNUM <= 3 ---------TOP3개를 출력
위 예제에서는 인라인뷰로 메인쿼리를 감싸주었다. 왜냐하면, SQL 처리순서는 다음과 같기 때문이다.
SQL 연산 순서
- FROM
- JOIN
- WHERE
- GROUB BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
위의 연산순서를 참고 했을 때, 인라인뷰를 사용하지 않고 메인쿼리에 아래처럼 전부 쓴다면 다음과 같이 SAL로 정렬된 TOP3개가 아닌 EMP전체 테이블의 TOP3개를 가져오게 된다.
SELECT ENAME, SAL
FROM EMP 1. EMP에서 모든 테이블 가져온다.
where ROUNUM <= 3 2. 그 중 TOP 3개를 가져온다.
ORDER BY SAL DESC 3. SAL로 내림차순 정렬한다. 2. TOP절(SQL SURVER)
오라클의 ROWNUM과 같은 기능을 하는 쿼리이다. 다만, 인라인뷰를 사용하지 않고 더 간단하게 사용한다.
select TOP(N) (percent) (with ties)
모두 사용한 예
select TOP(50) persent with ties
일반적 사용예
select TOP(2) ENAME, SAL
from EMP
ORDER BY SAL DESC
TOP(2)가 가장 마지막에 연산되어
SAL이 가장 높은 2개의 결과를 출력N = 몇개를 추출할 지 상수로 정할 수 있다.
percent = TOP(50) 등으로 사용할 수 있으며, 쿼리결과 집합에서 50%의 행만 행만 반환됨을 나타낸다.
with ties = ORDER BY절이 있을 때만 사용할 수 있으며, TOP N의 마지막 행과 같은 값이 있는 경우 추가로 행이 출력되도록 지정할 수 있다.
3. ROW LIMITING절(ANSI, ORACLE, SQL SURVER)
row limiting절을 이용한 TOP N 쿼리를 작성할 수도 있지만 잘 사용하지는 않는다. p349쪽 참조
6. 계층형 질의와 셀프 조인
테이블에 계층형 데이터가 존재할 때 데이터를 조회하기위해 계층형 질의를 사용한다.
예를 들면, 말단 사원과 그 차상위의 관리자가 있다라고 할 때, 그 차상위 관리자 또한 그의 차상위 관리자를 가질 것이다. 사원 -> 과장 -> 부장 -> 사장 이런 형태이다. 이를 보고 계층형 데이터라고 지칭한다.
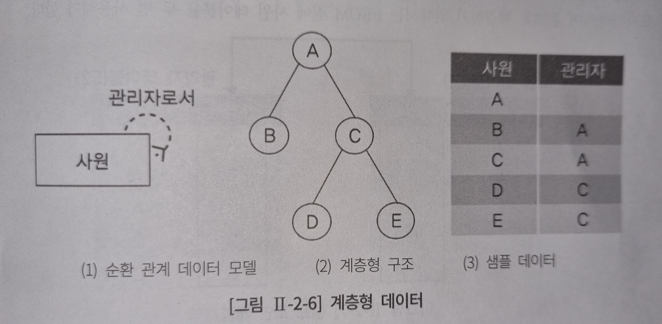
위와 같은 계층형 데이터 모델은 "셀프조인" 이나 "계층형 질의"로 조회할 수 있다.
1. 셀프조인
셀프조인은 "동일한 테이블 사이의 조인"을 뜻한다. 이 때 같은 테이블을 조인하는 것이기 때문에 반드시 AS를 붙여 (E1)과 (E2)로 테이블을 구분해야한다.
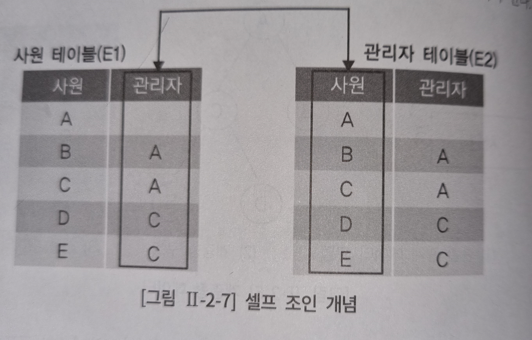
자식 노드를 조회하는 예제
select B.EMPNO, B.ENAME, B.MGR
from EMP A, EMP B
where A.ENAME = "철수"
and B.MGR = A.EMPNO
MGR = 매니저, EMPNO = 사원
-> 이름이 철수이며, 매니저(차상위 관리자)의 이름이 사원 "철수"와 같은 것을 출력한다.
자식노드의 자식노드를 조회하는 예제 (순방향 전개)
select C.EMPNO, C.ENAME, C.MGR
from EMP A, EMP B, EMP C
where A.ENAME = "철수"
and B.MGR = A.EMPNO
and C.MGR = B.EMPNO
부모노드의 부모노드를 조회하는 예제 (역방향 전개)
select C.EMPNO, C.ENAME, C.MGR
from EMP A, EMP B, EMP C
where A.ENAME = "철수"
and B.EMPNO = A.MGR
and C.EMPNO = B.MGR
2. 계층형 질의 (ORACLE)
SELECT...
FROM...
WHERE...
START WITH ...
AND ...
CONNECT BY [NO SYCLE] ...
AND ...
[ORDER SIBLINGS BY 컬럼1, 컬럼2, 컬럼3 ...]| 계층형 질의 구문 | 설명 |
|---|---|
| START WITH | 계층 구조 전개의 시작위치를 지정한다. |
| PRIOR | CONNECT BY절에 사용되며 현재 읽은 칼럼을 지정한다. ex) FK = PRIOR(PK) 형태는 순방향 전개, PK = PRIOR(FK) 형태는 역방향 전개이다. |
| NO CYCLE | 데이터를 전개하면서 이미나타난 데이터가 전개중에 다시나타나면 CYCLE발생이라고 한다. NO CYCLE을 사용하면, 사이클이 발생한 이후의 데이터를 전개하지 않는다. |
| ORDER SIBILINGS BY | 동일 레벨의 노드 사이에서 정렬을 수행한다. |
| where | 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다.(필터링) |
오라클은 계층형 질의를 할 때 다음과 같은 가상칼럼을 지원한다.
| 가상 칼럼 | 설명 |
|---|---|
| LEVEL | 루트 데이터면 1, 그 하위 데이터면 2다. 리프 데이터까지 1씩 증가한다. |
| CONNECT_BY_ISLEAF | 전개 과정에서 해당 데이터가 리프 데이터면 1, 아니면 0이다. |
| CONNECT_BY_ISCYCLE | 전개 과정에서 자식을 갖는데 해당 데이터가 조상으로써 존재하면1, 그렇지 않으면 0이다. SYCLE 옵션을 사용했을 때만 사용 가능하다. |
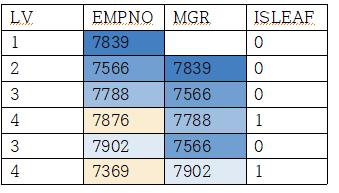
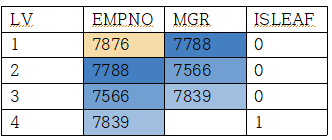
순방향 전개 (root -> leaf) 계층형 질의
select LEVEL AS LV, LPAD(' ',(LEVEL -1)*2)||EMPNO AS EMPNO, --LPAD는 들어쓰기 때문에 사용
MGR, CONNECT_BY_ISLEAF AS ISLEAF -------leaf데이터면 1 아니면 0
from EMP
START WITH MGR IS NULL ----------- MGR이 NULL, 즉 상위가 NULL인 부분부터 시작해라.
CONNECT BY MGR = PRIOR EMPNO ------ CONNECT BY FK = PRIOR PK 형식
*이 때 PK는 기준이 되는 쪽, 사원(empno)이 PK가 된다. 사장이면 자신의 상사(MGR)가 없을 수도 있기에 FK가 된다.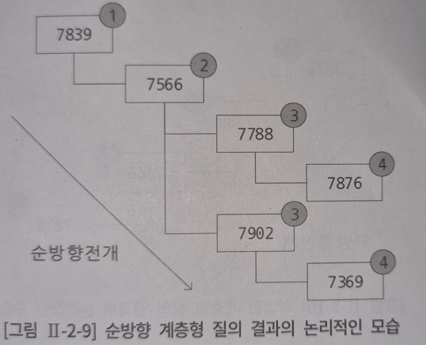
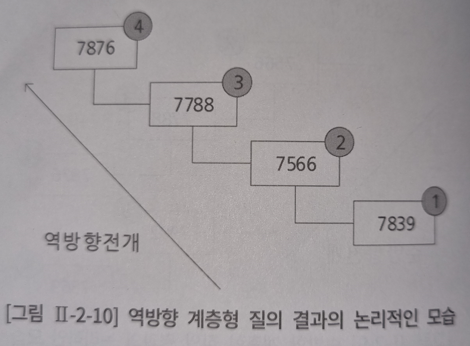
역방향 전개 (leaf -> root) 계층형 질의
select LEVEL AS LV, LPAD(' ',(LEVEL -1)*2)||EMPNO AS EMPNO, --LPAD는 들어쓰기 때문에 사용
MGR, CONNECT_BY_ISLEAF AS ISLEAF -------leaf데이터면 1 아니면 0
from EMP
START WITH EMPNO = 7876 ----------- MGR이 7876, 즉 뿌리 부분부터 시작해라.
CONNECT BY EMPNO = PRIOR MGR ------- CONNECT BY PK = PRIOR FK 형식
위 들 표는 루트를 색깔로 표시했지만, 아래의 함수를 사용하면 직접 알 수 있다.
| 함수 | 설명 |
|---|---|
| SYS_CONNECT_BY_PATH(칼럼,경로분리자) | 루트 데이터부터 현재 전개할 데이터 까지의 경로를 표시한다. |
| CONNECT_BY_ROOT 칼럼 | 현재 전개할 데이터의 루트 데이터를 표시한다. |
select connect_by_root(empno) AS root_empno,
sys_connect_by_path(empno,',') AS PATH, EMPNO, MGR
from emp
START WITH MGR = IS NULL ----------- MGR이 NULL
CONNECT BY MGR = PRIOR EMPNO -------- CONNECT BY FK = PRIOR PK 형식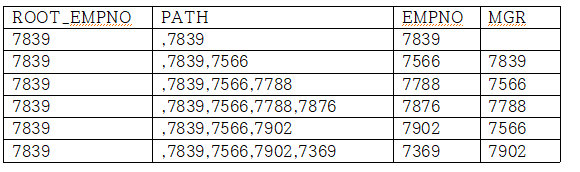
7. PIVOT절과 UNPIVOT절
pivot함수는 행을 열로 전환시킨다는 의미를 가지고 있다. 반대로 unpivot함수는 열을 행으로 전환시킨다.
PIVOT 함수
pivot 함수의 사용법
select *
from (피벗 할 대상의 쿼리)
PIVOT(집계함수(칼럼), 집계함수(칼럼2), ...
FOR 열로 지정할 컬럼명
IN (열의 속성 값1, 열의 속성 값2 ,....)
)
* PIVOT테이블은 항상 집계함수와 FOR절에 지정되지 않은 열을 기준으로 집계되기 때문에
항상 인라인뷰로 기준을 정해주어야 한다. pivot을 할경우, 내부적으로 group by가 작동하며,
group by의 기준은 열에넣을 컬럼명이다.
ex) 인라인뷰 = select A, B, C
PIVOT SUM(A) FOR B IN(10, 20, 30)
이면, C를 기준으로 열이 집계된다. 예를 들어 다음과 같은 데이터가 있다. SAL은 AVG()된 SAL이다.
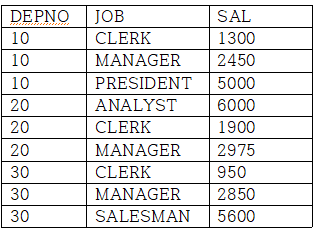
위 데이터를 아래와 같이 PIVOT하면 다음의 결과가 나온다.
SELECT *
FROM (select DEPTNO, JOB, SAL
from emp)
PIVOT (AVG(SAL) FOR DEPTNO IN (10,20,30))
- JOB을 기준열로 하여, DEPNO의 10, 20, 30을 PIVOT하여 출력한다.
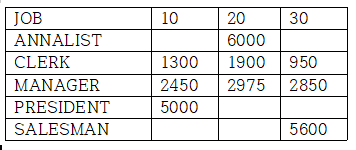
JOB을 기준 열(컬럼)으로 지정하고, DEPTNO의 값이 행에서 열이 되었다.
별칭 지정
PIVOT절에서 집계함수 부분과 IN의 컬럼에 별명을 지정할 수 있다.
SELECT *
FROM (select DEPTNO, JOB, SAL
from emp)
PIVOT (AVG(SAL) AS SAL FOR DEPTNO IN (10 AS D10,20 AS D20,30 AS D30))
출력형식
job | D10_SAL | D20_SAL | D30_SAL
먼저 컬럼별명인 IN부터 별명으로 바꾼뒤, _ 를 통해 구분한 집계함수 별명을 출력한다. 필요한 열만 조회하기
메인쿼리의 select와 where에 조건을 기재함으로 써 원하는 쿼리만 조회할 수 있다.
이 때 PIVOT절을 통한 최종 출력 별명을 조건절로 사용해야한다.
SELECT JOB, D20_SAL
FROM (select DEPTNO, JOB, SAL
from emp)
WHERE D20_SAL > 2500
PIVOT (AVG(SAL) AS SAL FOR DEPTNO IN (10 AS D10,20 AS D20,30 AS D30)) 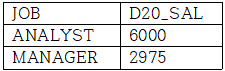
다수의 집계함수 지원
SELECT *
FROM (select DEPTNO, JOB, SAL
from emp)
PIVOT (AVG(SAL) AS SAL, COUNT(*) AS CNT FOR DEPTNO IN (10 AS D10,20 AS D20)) 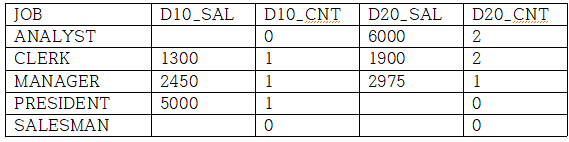
다수의 열 지원
FOR절에도 다수의 열을 기술할 수있다. 다음과 같이 IN절에 다중열을 사용하여야 한다.
SELECT *
FROM (select TO_CHAR(HIREDATE, "YYYY") AS YYYY, JOB, DEPTNO, SAL
from emp)
PIVOT (AVG(SAL) AS SAL, COUNT(*) AS CNT FOR (DEPTNO, JOB)
IN ((10, "ANALYST") AS D10A, (10, "CLERK") AS D10C
,(20, "ANALYST") AS D20A, (20, "CLERK") AS D20C))
-YYYY가 기준이되며,
-DEPTNO가 10이고 JOB이 ANALYST인 것을 열(컬럼)으로 지정하여, AVG(SAL)과 COUNT(*)를 구한다.
-위 과정을 IN의 개수만큼 (4번) 반복해 출력한다.ex) D10A_SAL, D10A_CNT로 1세트
UNPIVOT
UNPIVOT절은 집계함수를 사용하지 않으며, 열이 행으로 전환된다. 예를 들어 아래와 같은 데이터가 있다.
SELECT * FROM T1 ORDER BY JOB
job | D10_SAL | D20_SAL | D10_CNT | D20_CNT
ANALIST 6000 0 2
CLERK 1300 1900 1 2
위 데이터에 UNPIVOT을 하면 D10_SAL, D20_SAL열이 행으로 전환된다.
SELECT JOB, DEPTNO, SAL
FROM T1
UNPIVOT (SAL FOR DEPTNO IN (D10_SAL, D20_SAL))
ORDER BY 1, 2
-JOB을 기준으로 한 테이블에 DEPTNO의 D10_SAL, D20_SAL열을 행으로 전환한다. 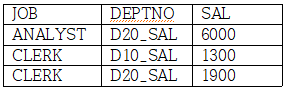
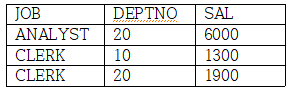
별칭 지정
SELECT JOB, DEPTNO, SAL
FROM T1
UNPIVOT (SAL FOR DEPTNO IN (D10_SAL AS 10, D20_SAL AS 20))
ORDER BY 1, 2
INCLUDE NULLS
UNPIVOT된 열의 값이 NULL인 행도 표시한다.
SELECT JOB, DEPTNO, SAL
FROM T1
UNPIVOT INCLUDE NULLS (SAL FOR DEPTNO IN (D10_SAL AS 10, D20_SAL AS 20))
ORDER BY 1, 2
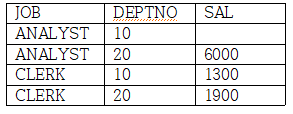
다수의 열과 별칭 지원
UNPIVOT 또한 다수의 열, IN절에 다수의 별칭을 지정할 수도 있다.
SELECT *
FROM T1
UNPIVOT ((SAL, CNT) FOR DEPTNO IN ((D10_SAL, D10_CNT) AS 10, (D20_SAL, D20_CNT) AS 20))
ORDER BY 1, 2
-JOB을 기준으로 DEPTNO를 행으로 변경하고, D10_SAL, D10_CNT 를 10으로, D20_SAL, D20_CNT를
20으로 지정하여 출력한다.
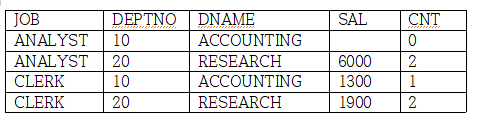
이때 각각 D10 SAL, D20 SAL, D10 SAL, D20 SAL이다.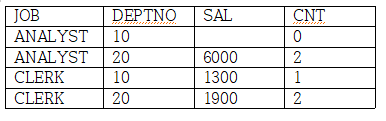
SELECT *
FROM T1
UNPIVOT ((SAL, CNT) FOR (DEPTNO, DNAME) IN ((D10_SAL, D10_CNT) AS (10, "ACCOUNTING") ,
(D20_SAL, D20_CNT) AS (20, "RESEARCH")))
ORDER BY 1, 2
-JOB을 기준으로 DEPTNO, DNAME을 행으로 변경하고,별칭을 부여한다.
8. 정규표현식(REGULAR EXPRESSION)
정규표현식은 문자열의 규칙을 표현하는 검색 패턴으로, 주로 문자열 검색과 치환에 사용된다.
유튜브 강의 참조
정규표현식
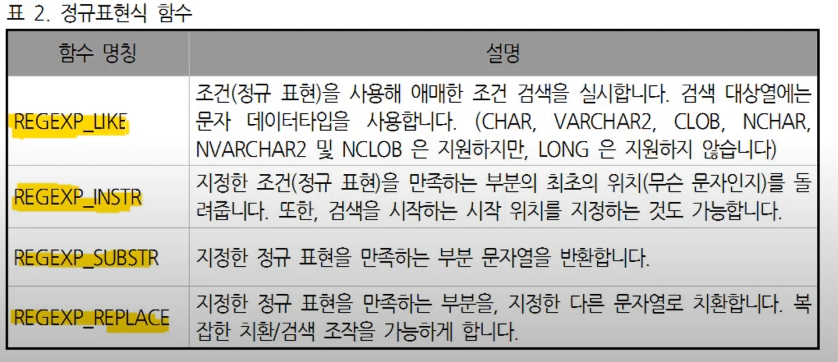
REG_SUBSTR("문자열", "정규표현식", "추출시작할 위치", "찾을 순번")
1. 기본문법
A. POSIX연산자 (POSIX operator)
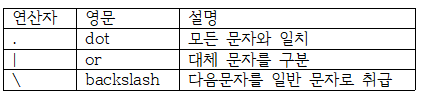
1. DOT 사용
SELECT REGEXP_SUBSTR ("aab", "a.b") AS C1 ---- aab출력
REGEXP_SUBSTR ("abb", "a.b") AS C2 ---- abb출력
REGEXP_SUBSTR ("acb", "a.b") AS C3 ---- acb출력
REGEXP_SUBSTR ("adc", "a.b") AS C4 ---- 공백출력
FROM DUAL
위는 1번째 A 2번째 아무문자(.) 세번째 글자가 가 B면 출력하라는 뜻이다. 2. OR사용
SELECT REGEXP_SUBSTR ("ab", "ab|b") AS C1 --- ab출력
REGEXP_SUBSTR ("ab", "ab|bc") AS C2 -- ab출력
REGEXP_SUBSTR ("a", "a|ab") AS C3 ---- a출력
REGEXP_SUBSTR ("adc", "ab|bc") AS C4 - 공백출력
FROM DUAL
양쪽중 하나라도 일치하면 출력한다.3. BACK SLASH사용
SELECT REGEXP_SUBSTR ("a|b", "a|b") AS C1 --- a를 출력 ---- |를 OR로 인식
REGEXP_SUBSTR ("a|b", "ab\|b") AS C2 - 'a|b'출력 --- |를 문자로 인식
FROM DUAL
a또는 b를 만나면 출력이지만, A를 만났기에 A만 바로 출력하였다.앵커태그
검색 패턴의 시작과 끝을 지정한다. ↓
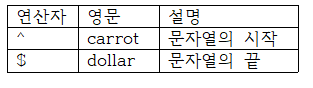
SELECT REGEXP_SUBSTR ('abcd', '^.', 1, 1) AS C1 --- a출력
REGEXP_SUBSTR ('abcd', '^.', 1, 2) AS C2 -- 공백출력
REGEXP_SUBSTR ('abcd', '.$', 1, 1) AS C3 ---- d출력
REGEXP_SUBSTR ('abcd', '.$', 1, 2) AS C4 - 공백출력
FROM DUAL
위에서 ^.는 아무 한글자로 시작하는 단어를 출력하라는 뜻이다.
이때 3번째 인자는 검색위치로 첫번쨰 글자인 a부터 시작하라는 의미이며,
4번째 인자는 반복탐색으로 첫번째 match성공시 출력하라는 뜻이다.
만약 C2처럼 2번째로 시작하는 문자는 존재할 수 없으니 당연히 null을 출력한다.
수량사
수량사는 일치 횟수를 탐욕적(greedy)로 출력하는 쿼리이다.
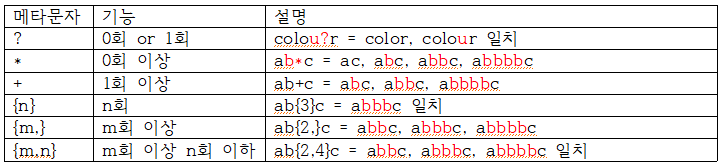
예를들어,
SELECT REGEXP_SUBSTR ('ac', 'ab?c') AS C1 --- b가 0,1이면 출력가능
REGEXP_SUBSTR ('abc', 'ab?c') AS C2 -- b가 0,1이면 출력가능
REGEXP_SUBSTR ('abbc', 'ab?c') AS C3 --- b가0,1이면 출력가능
REGEXP_SUBSTR ('ac', 'ab*c') AS C4 --- b가 0이상이면 출력가능
REGEXP_SUBSTR ('abc', 'ab*c') AS C5 -- b가 0이상이면 출력가능
REGEXP_SUBSTR ('abbc', 'ab*c') AS C6 --- b가0이상이면 출력가능
REGEXP_SUBSTR ('ac', 'ab+c') AS C7 --- b가 1이상이면 출력가능
REGEXP_SUBSTR ('abc', 'ab+c') AS C8 -- b가 1이상이면 출력가능
REGEXP_SUBSTR ('abbc', 'ab+c') AS C9 --- b가 1이상이면 출력가능
FROM DUAL
출력 결과
C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9
ac abc ac abc abbc abc abbc
{}사용법
SELECT REGEXP_SUBSTR ('ab', 'a{2}') AS C1 ---
REGEXP_SUBSTR ('aab', 'a{2}') AS C2 -- a를 정확히 2회 사용해 출력
REGEXP_SUBSTR ('aab', 'a{3,}') AS C3 ---
REGEXP_SUBSTR ('aaab', 'a{3,}') AS C4 --- a를 3회 이상 사용해 출력
REGEXP_SUBSTR ('aaab', 'a{4,5}') AS C5 --
REGEXP_SUBSTR ('aaaab', 'a{4,5}') AS C6 --- a를 4~5회 사용해 출력
FROM DUAL
출력 결과
C1 | C2 | C3 | C4 | C5 | C6
aa aaa aaaa
괄호
괄호안의 문자는 1글자로 취급할 수 있다.
SELECT REGEXP_SUBSTR ('ababc', '(ab)+c') AS C1 -- ab가 1회이상이면 출력
REGEXP_SUBSTR ('ababc', 'ab+c') AS C2 --
REGEXP_SUBSTR ('abd', 'a(b|c)d') AS C3 ----
REGEXP_SUBSTR ('abd', 'ab|cd') AS C4 -
FROM DUAL
출력 결과
C1 | C2 | C3 | C4
ababc abc abd ab
C1의 경우 abc가 답이 아닌가 싶지만 'Greed'방식은, 모든 '연속된'일치패턴을 전부 출력한다.
따라서 C2가 abbc였어도 출력했을 것이다. 역참조 쿼리
\n(n= 1~9) 을 사용하면 동일한 문자열이 반복되는 패턴을 검사가능하다.
SELECT REGEXP_SUBSTR ('ababab', '(.*)\1+') AS C1 --- 아무 글자가 1회 이상 반복
REGEXP_SUBSTR ('abcabc', '(.*)\1+') AS C2 ---
REGEXP_SUBSTR ('abcabd', '(.*)\1+') AS C3 ----
FROM DUAL
출력 결과
C1 | C2 | C3
ababab abcabc []대괄호
문자리스트중 1글자만 일치해도 출력하는 것으로 [ab]의 경우 a|b와 완전히 같은 뜻이다.
이때 [^ab]로 하면 a또는 b를 제외한 패턴을 출력한다.
[0-9] 모든 숫자
[a-z] 모든 소문자
[A-Z] 모든 대문자2. 문자 클래스
대괄호 안에는 한번더 []대괄호와 ::를 표기하는 것으로 POSIX문자 클래스를 사용할 수 있다.
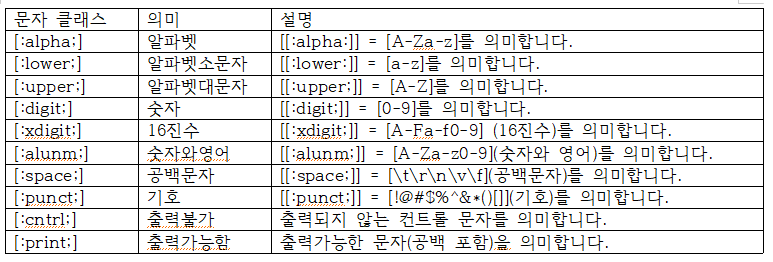
alunm은 오타이며, alnum이 올바른 표기이다.
alnum == alpha(lower + upper) + digit
3. PERL 정규 표현식 연산자
\d : 숫자 == [[:digit:]]
\D : 숫자를제외 == [^[:digit:]]
\w : 숫자와 영문자 + 언더바 _ == [[:alnum:]]
\W : 숫자와 영문자 + 언더바 _ 제외 == [^[:alnum:]]
\s : 공백문자 == [[:space:]]
\S : 공백문자제외 == [^[:space:]]3-1. PERL 정규표현식 함수의 사용
(1) 전화번호 찾기
SELECT REGEXP_SUBSTR ('(650) 555-0100', '^\(\d{3}\) \d{3}-\d{4}$') AS C1
REGEXP_SUBSTR ('650-555-0100', '^\(\d{3}\) \d{3}-\d{4}$') AS C2 --
REGEXP_SUBSTR ('b2b', '\w\d\D') AS C3 ----
REGEXP_SUBSTR ('b2_', '\w\d\D') AS C4 -
REGEXP_SUBSTR ('b22', '\w\d\D') AS C5 -
FROM DUAL
출력 결과
C1 | C2 | C3 | C4 | C5 |
(650) 555-0100 b2b b2_
C1을 순서대로 보면, (로시작하는 3글자 문자출력후 )를 검색한다.
\(와 \)는 (특수문자를 검색하기 위한 표기)(2) 이메일 찾기
SELECT REGEXP_SUBSTR ('asb@naver.co.kr', '\w+@\w+(\.\w+)+') AS C1
REGEXP_SUBSTR ('asb@naver', '\w+@\w+(\.\w+)+') AS C2 --
FROM DUAL
출력결과
C1 | C2
asb@naver.co.kr
c1을 해석하면,
1. 숫자와 영문자로 시작하는 1회 이상의글자를출력
2. @
3. 숫자와 영문자로 시작하는 1회 이상의글자를출력
4. (.으로시작하며, 숫자와 영문자로 시작하는 1회 이상의글자) 1회이상 반복출력 3-2. 비그리드 방식으로 정규표현식 사용
?를 기존 정규표현식의 수량사 뒤에 붙이는 것으로 사용한다.
?? : 0회~1회 일치
*? : 0회이상 일치
+? : 1회이상 일치
{m}? : m회일치
{m,}? : 최소 m회일치
{,m}? : 최대 m회일치
{m,n}? : 최소m회, 최대 m회 일치
SELECT REGEXP_SUBSTR ('aaaa', 'a??aa') AS C1 -- nogreed
REGEXP_SUBSTR ('aaaa', 'a?aa') AS C2 -- greed
REGEXP_SUBSTR ('xaxbxc', '\w*?x\w') AS C3 -- nogreed
REGEXP_SUBSTR ('xaxbxc', '\w*x\w') AS C4 - greed
REGEXP_SUBSTR ('abxcxd', '\w*?x\w') AS C5 - nogreed
REGEXP_SUBSTR ('abxcxd', '\w*x\w') AS C6 -greed
FROM DUAL
출력 결과
C1 | C2 | C3 | C4 | C5 | C6 |
aa aaa xa xaxbxc abxc abxcxd
c1: a가 1회 일치하지만, 0회가 최소 greed이기에 a를 제외한 aa만 출력하였다.
c2: a가 1회 일치하여 aaa를 출력하였다.
c3: 가능한 적은 문자를 매칭(0회)후 x로시작하는 word를 출력한다.
c5: 가능한 적은 문자를 매칭(ab)후 x로시작하는 word를 출력한다.
4. 정규 표현식 사용예제
CREATE TABLE 1 (coll VARCHAR(10))
INSERT INTO 1 VALUSE("ABCDE01234")
INSERT INTO 1 VALUSE("01234ABCDE")
INSERT INTO 1 VALUSE("abcde01234")
INSERT INTO 1 VALUSE("01234abcde")
INSERT INTO 1 VALUSE("1-234-5678")
INSERT INTO 1 VALUSE("234-567890")select * from 1
where regexp_like(coll, '[0-9][a-z]'); - 숫자 뒤에 영문자 소문자가 나온것을 찾아준다.
---------------------------------------------
coll
01234abcdeselect * from 1
where regexp_like(coll, '[0-9]{3}-[0-9]{4}'); - 숫자 3자리"-"숫자 4자리를 찾아준다.
---------------------------------------------
coll
1-234-5678
234-567890select * from 1
where regexp_like(coll, '[0-9]{3}-[0-9]{4}$'); - 맨 뒤가 숫자 3자리"-"숫자 4자리를 찾아준다.
---------------------------------------------
coll
1-234-5678select * from 1
where regexp_like(coll, '[[:digit:]{3}-[:digit:]{4}$]'); - 맨 뒤가 숫자 3자리"-"숫자 4자리를 찾아준다.
---------------------------------------------
coll
1-234-56785. 정규표현식 조건과 함수
(1) REGEXP_LIKE함수
정규 표현조건을 사용해 검색하는 함수, 제약조건에도 사용가능하다.
이를 조건절로 하여 검색할 경우, 정규표현식에 맞으면 True, 틀리면 False로 반환한다.
1. 조건절로 사용
where REGEXP_LIKE(제품코드, '^ste(b|ph)en$');
제품코드의 형식이 ste로 시작하고 중간글자가 b나ph 끝글자가 en인 것을 출력한다.
2. 제약 조건으로 만들기 예제
CREATE TABLE A (제품코드 VARCHAR2(10))
ALTER TABLE A ADD CONSTRAINT 제품코드오류A01 CHECK(REGEXP_LIKE(제품코드,
'^([[:alpha:]]{2}-[[:digit:]]{2}-[[:digit:]]{4}$'));
insert into 제품코드 VALUES('QA-01-0001') -성공
insert into 제품코드 VALUES('QA-013-007') -체크 제약조건 (제품코드오류A01)이 위배되었습니다.(2) REGEXP_INSTER 함수
지정한 정규표현을 만족하는 부분의 최초위치(무슨 문자인지)를 정수로 돌려줍니다.
CREATE TABLE 2 (coll VARCHAR(10))
INSERT INTO 2 VALUSE("ABCDE01234")
INSERT INTO 2 VALUSE("01234ABCDE")
INSERT INTO 2 VALUSE("abcde01234")
INSERT INTO 2 VALUSE("01234abcde")
INSERT INTO 2 VALUSE("1-234-5678")
INSERT INTO 2 VALUSE("234-567890")
INSERT INTO 2 VALUSE("@!=)(9&%$#")
INSERT INTO 2 VALUSE("자바3")select coll, REGEXP_INSTER(coll, '[0-9]') AS data1,
REGEXP_INSTER(coll, '%') AS data2
from 2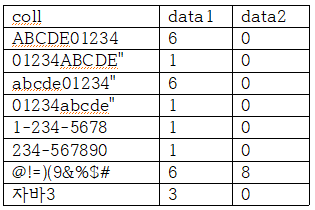
(3)REGEXP_SUBSTR 함수
지정한 정규표현을 만족하는 부분문자열을 반환합니다.
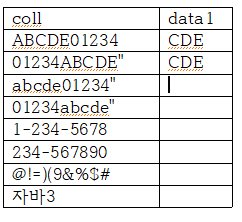
select coll, REGEXP_SUBSTR(coll, '[C-Z]+') AS data1
from 2
- 1회이상 [C-Z]가 나타난 부분부터 시작하는 문자열을 구해라
(4)REGEXP_REPLACE 함수
지정한 정규표현을 만족하는 부분을 지정한 다른 문자열로 치환합니다.
select coll, REGEXP_REPLACE(coll, '[0-2]+','*') AS data1 - 1회이상 [0-2]가 나타난 부분을 *로 바꾸어라.
from 2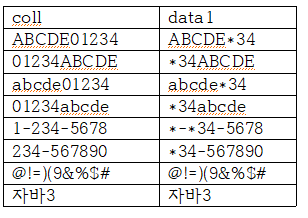
아래처럼 \1, \2, \3을 사용해 위치로 바꿀 수도 있다.
select 폰번호, REGEXP_REPLACE(coll, '[[:digit:]]{3}\.([[:digit:]]{3}\.([[:digit:]]{4}',
'(\1) \2-\3') as c1
폰번호 | c1
650.121.2004 (650) 121-2004재미있는 점은 대체 문자열에서는 \없이 괄호를 출력할 수 있다.
(5)REGEXP_COUNT 함수
패턴이 일치한 횟수를 출력하는 함수이다.
SELECT REGEXP_COUNT ('abababababab' , 'ab', 1) as c1
REGEXP_COUNT ('abababab' , 'ab', 3) as c2
c1 | c2
5 3
3번째 인자는 시작위치를 말한다.