목표
TCP 및 UDP 구조를 배운다.
검증 방법2가지
- 신뢰성 보장하기 위해 한단계, 한단계 패킷을 보낼 때마다 검증
- 처음부터 끝까지 보낸 다음에 검증 (END TO END)
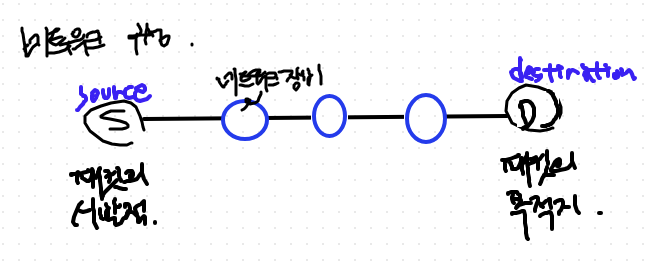
=> 전송계층은 end to end 프로토콜임.- 중간단계 네트워크 장비들에 간섭하지 않음
- 양 끝단 장비에만 설치 및 검증 함.
- tcp 계층은 양 끝단에서 검증함.
- 전송계층에서 이야기하는 모든 서비스는 양 끝단에 해당하는 서비스임.
신뢰성

1. TCP
- 내용 유실이 없다.
- 내용상의 이빠짐이 없다.
- 패킷을 보내는 도중에 네트워크 끊김(와이파이 없는 곳으로 이동)으로 인해 패킷이 끊긴다면 1,2,3,4번,...7번 패킷까지 가고, 5,6,번 패킷아 안가는 등의 경우는 없단 뜻.
- UDP
- 내용 유실이 있다.
속도

- TCP
- 고의적인 지연이 존재할 수 있다.
- 왜 ? : 경우에 따라서 필요함.
- 1,2,3,4 패킷까지 받고, 6번 패킷 받아도, 6번 패킷을 applictation 에 안알려줌. (순차적으로 패킷을 보내는게 중요하기 때문임)
- 왜 ? : 경우에 따라서 필요함.
- UDP
- 고의적인 지연이 없다.
- 보내달라하면 무조건 즉각적으로 보내고, 받는 단에서 받자마자 application 한테 보냄
- 네트워크 불안, 네트워크 패킷을 멀리 보내야 하는 지연은 있을 수 있음.
혼잡제어

- TCP
- 네트워크 혼잡이 심하면, 모든 사람이 서비스 못 받는 상황이 생길 수 있음.
=> 패킷을 보낼 수 있음에도 참음. - 네트워크는 혼잡이 많아지면, 각 장비에 패킷이 쌓이되면, 버려지는 패킷이 생김 => 신뢰성 하락 => 네트워크 더 복잡해짐. => 방지하기 위해
혼잡제어
- UDP
- 네트워크 혼잡해도 보냄.
전송단위

1. TCP
- 내용 유실 자체가 아예 없음.
=> 내가 보낸 패킷의 단위를 그대로 기억할 필요가 없음. - byte를 전송단위로함.
- 굳이 내가 몇번 send를 호출해서 이 데이터를 어느 단위로 끊어서 보냈는지 기억하지 않는다.
- UDP
- 내용이 너무 잘게 쪼개진 단위로 패킷이 유실되면 골치아파짐. 내용이 유실 될 수 있지만, 의미적 단위로만 유실 할 수 있게 한다.
- 패킷을 보낸다고 할 때, send라는 함수를 통해 하나의 데이터 덩어리를 보내게 됨.
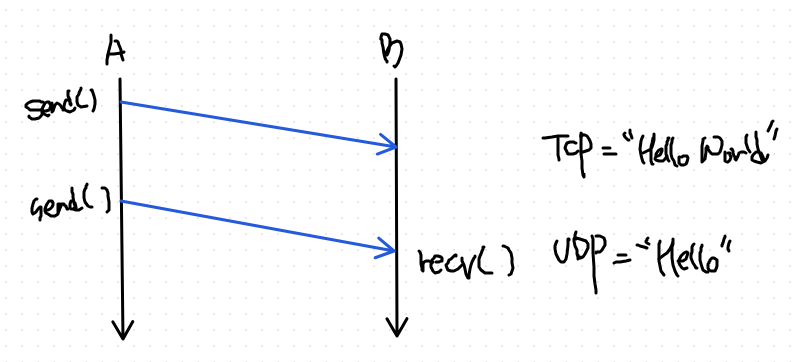

- tcp는 byte 단위로 전송하기 때문에, send(), recv() 단위상의 일치 관계가 성립하지 않는다.
- udp에서는 send 함수에서 보낸 데이터 내용 자체가 recv()에 받는 데이터가 대응관계다.
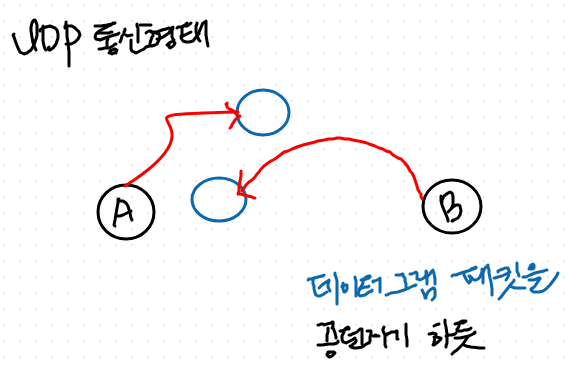
- 실제로 A가 데이터를 던졌는데 B가 못받을 수 있음 (패킷 유실)
- 순서 보장 X
- 빨리 보내줌
- 단위는 공으로 뭉쳐서 보내기 때문에, 그 통신의 단위는 데이터 그램이다.
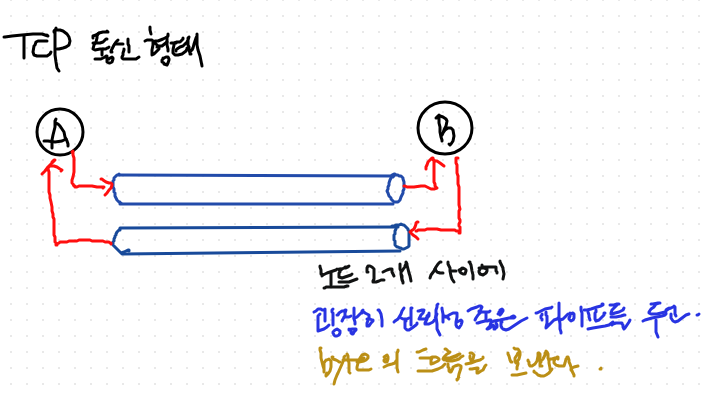
TCP의 구현
- Reliable Network
- 패킷 유실 x , 순서 보장
- 내용 변조 탐지 기능
- 패킷이 중간에 잡음등 때문에 (보안 공격을 탐지하는 건 아님)
- 혼잡제어
- 네트워크 혼잡이 심한 것 같으면, 보내지 않고 기다렸다가 보냄
- 흐름제어
- 패킷을 수신하는 쪽에도 buffer가 있는데, 꽉차서 넘치는 상황이 생길 수 있는데, 수신하는 쪽에 있는 응용이 지금까지 받은 내용 줘봐봐. recv 함수를 통해서 요청을 운영체제한테 할 수 있는데 요청을 아예 안하게 되면 위에있는 운영체제에서 지금까지 받은 패킷을 계속 잡고 있을 수밖에 없어. 창고에 쌓아두는데 위에 응용계층에서 달라고 안하면, 창고가 꽉차면 송신측에서 보내는 내용을 쌓을 수 없는 경지에 이르게 된다. 그렇게 되면 수신측에서 더이상 보내지 말라고 이야기한다.
UDP의 구현
- 패킷 보내라 하면, 보내고, 달라하면 위로 주고
- 하는게 거의 없음. 속도가 빠른 프로토콜임
TCP 패킷 구성
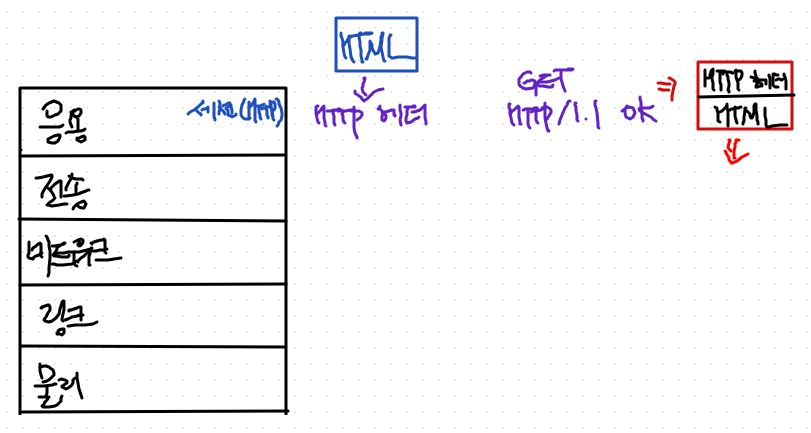
1. 응용계층에서 HTML 문서를 보내면,
2. 세션계층 즉, HTTP가 받는다.
- HTML에다가 세션계층 header를 붙인다. (문자열 형태 header)
- http req, get (http 1.1 ok)
=> 결과적으로, body로는 HTML 문서, header로서 http 헤더를 붙인다.
- http req, get (http 1.1 ok)
- 전송계층에 전송
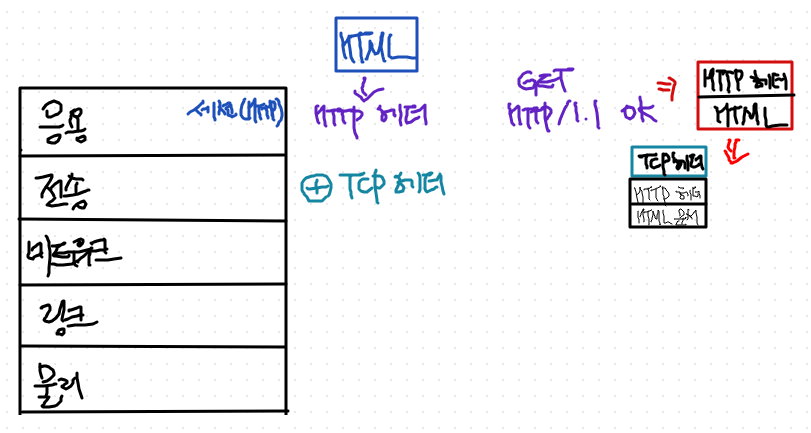
1. 전송계층에서는 응용계층에서 받은 문서가 payload가 된다.
- 최종적인 내용은 html이지만, http header까지 붙인게 내용으로 취급
- 받은 내용에다가 tcp header를 추가한다.
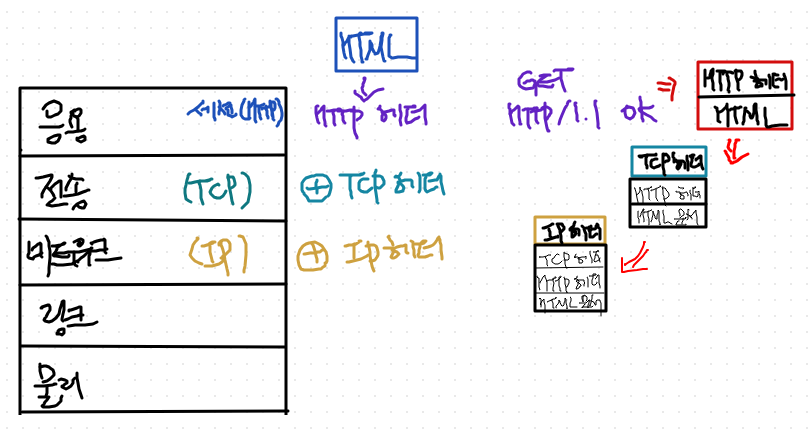
1. 네트워크 계층에서는 ip 헤더를 붙인다.
- 목적지까지 보내려면 주소를 써야겠지.
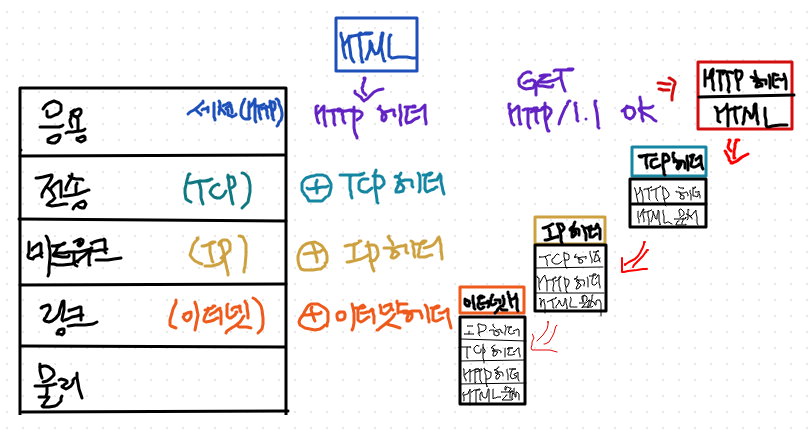
1. 링크 layer는 와이파이, LTE, 이더넷 등이 된다.
2. 이더넷 헤더를 붙인다.
3. 물리계층으로 보낸다.
물리계층은 헤더를 붙이는 것이 아니라, 내용을 전기적 신호로 바꾼다.
수신측에서 다시, 데이터 형태로 바꾼다.
마지막으로 수신측에서 각 계층에서 각각에 해당하는 header를 해체시키고, 위 계층으로 올려보낸다.
- 헤더에는 그 계층에서 필요로 하는 데이터들이 들어가있다.
그 헤더에 어떤 내용이 들어가는지 공부해보자.
TCP 헤더 구성

-
tcp 헤더는 convention이 있다. http 헤더와는 다르게 문자열이 아닌
binary 형태- 커널 계층에서 빨리 처리해야 되기 때문임.
-
각각의 몇번째 바이트는 어떤 의미다 라는것이 고정
-
32bit로 구성
-
각각 16bit 씩
-
tcp의 주요 기능으로
포트(사서함) 기능을 지원한다.- port 번호는 응용 프로그램을 구분한다.
- ip 번호는 각 기계를 구분한다.
-
socket : 응용 안에서 port를 구분하는 개념으로 사용하는 것
Socket vs Port
- socket 여러개가 하나의 port에 연결될 수 있다.
- socket과 port는 네트워크 통신에서 중요한 역할을 한다. 개념은 서로 다르지만, 함께 작동하여 client와 server간의 데이터 교환을 가능하게 한다.
socket
- 소켓은 네트워크 통신의 종착점을 나타내는 추상화된 개념이다.
- 소켓은 ip 주소와 port 번호로 구성된다.
- 소켓은 네트워크 상에서 데이터를 송수신하는데 사용되며, 프로그램 통신을 가능하게 한다.
- 예를 들어, client sw(브라우저 등)가 특정 서버에 연결할 때 소켓을 사용한다.
port
- 포트는 ip 주소에서 특정 프로세스를 식별하는 역할을 한다.
- 네트워크 통신에서 한 컴퓨터에서 실행되는 여러 프로그램 간의 데이터를 구분하는데 사용된다.
- 포트번호는 0번부터 65535 까지의 범위를 가지며, 특정 서비스와 연관되어 있다.
- http는 포트 80, https 443
관계
- 소켓은 ip주소와 포트 번호의 조합이다.
- ex) 192.168.11:80 이라는 소켓은 ip주소와 포트번호로 구성된다.
- 여러 소켓이 동일한 포트 번호를 사용할 수 있다. => 여러 클라이언트가 동일한 서버의 동일한 서비스에 연결할 수 있음을 의미한다.
예시 : 클라이언트와 웹 서버
- 클라이언트: 클라이언트는 소켓을 사용하여 서버에 연결한다. 예를 들어, 웹 브라우저가 웹 서버에 연결할 때 클라이언트 소켓을 사용한다.
- 웹 서버:웹 서버는 특정 포트에서 수신 대기한다. 일반적으로 http는 포트 80을, https는 포트 443을 사용한다.
통신과정
1. 클라이언트 소켓 생성: 클라이언트가 서버에 연결하기 위해 소켓을 생성한다.
2. 서버 포트에 연결: 클라이언트 소켓은 서버의 ip 주소와 지정된 포트 번호에 연결 요청을 보낸다.
3. 연결 수락: 서버는 포트 번호를 통해 연결 요청을 수락하고, 클라이언트와의 통신을 시작한다.
포트- 소켓 관계 예제
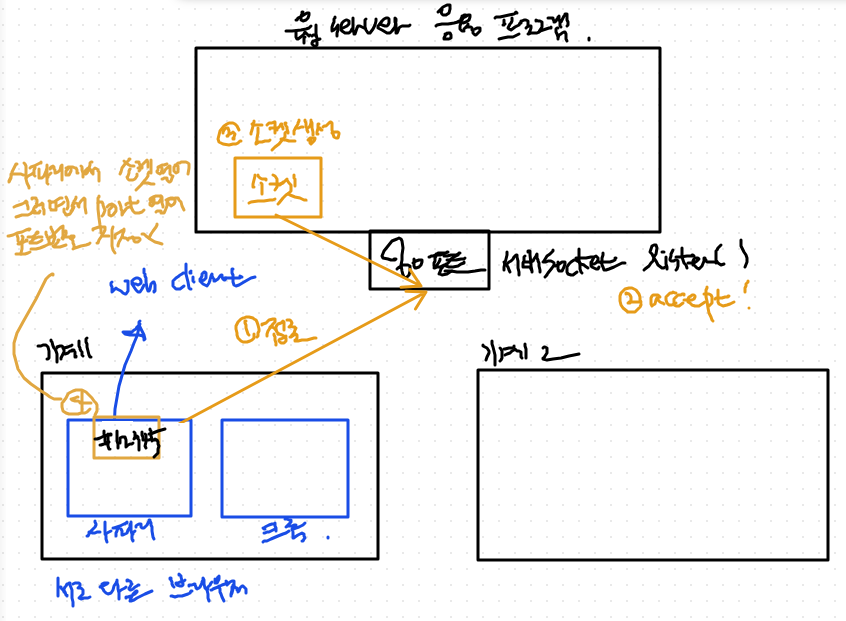
-
네이버 web server 응용 프로그램이다.
- 가장 먼저 하는 것은 80 번 포트로 server socket을 연다.
- server socket으로 제일 먼저 하는 것은
listen()(누가 접근하는지)
- server socket으로 제일 먼저 하는 것은
- 가장 먼저 하는 것은 80 번 포트로 server socket을 연다.
-
기계가 두개가 있다.
- 그 기계 안에는 web client 프로그램이 떠있다. (사파리, 크롬)
-
사파리에서 web server로 먼저 접근을 한다.
=> web server 소켓에서accept -
사파리와 web server를 연결해주는 소켓이 web server 안에 생성
=> 사파리에서도 역시 소켓 하나 연다. port 하나를 열게 되는데, client 포트번호는 지정을 안한다. 12345 포트 번호로 운영체제가 임의로 할당 => 이것이 80번 port와 연결되게 된다.- 예를 들어)
- 기계1 ip가 3.4.5.6이고, 네이버의 ip가 1.2.3.4 일 때의 경우를 살펴보면, 3.4.5.6 에 있는 12345 포트에서 1.2.3.4 기계의 80번 포트랑 연결된다. 그것이 하나의 소켓을 열게 되는 것이다.
- 예를 들어)
정리)


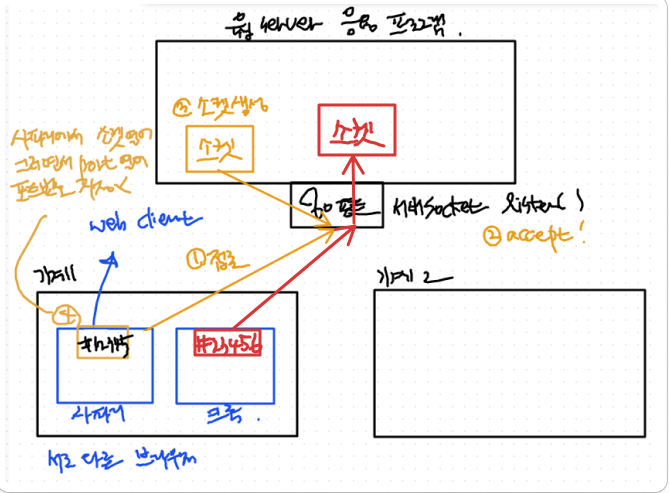
상황)
똑같은 기기의 크롬을 통해서 네이버 웹서버에 접속한다고 하자.
- 크롬을 위한 포트 설정
- 23456번 포트
client 프로그램의 경우는 일반적으로 하나의 포트가 하나의 소켓에 mapping이 된다.
- 23456 포트가 => 80번 포트에 접근 하면
- 80번 포트가 listen을 한다.
- chrome을 담당하는 소켓이 네이버 웹 server에 추가적으로 하나 생김
- 이 소켓 객체가 이 크롬을 담당한다.
정리)
사파리와 크롬 두개의 client는 동일한 서버의 동일한 80번 포트에 접근한다.
하지만 실제로 응용 프로그램 안에 있는 소켓 객체는 서로 다르다.
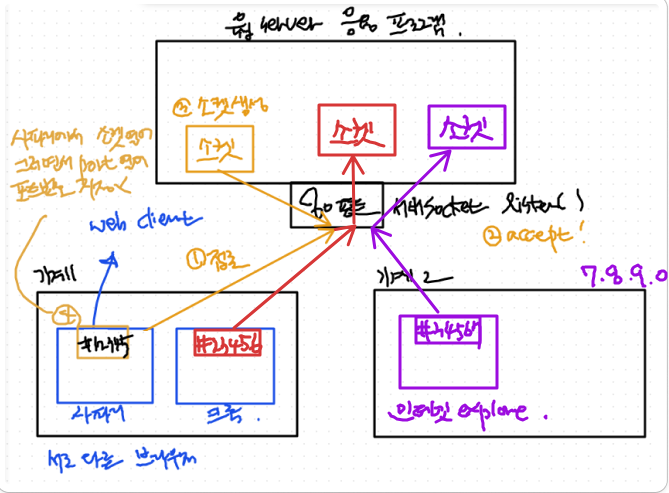
- 포트 하나를 가지고 3개의 소켓이 나눠서 쓰고 있다.
- 웹 서버 안에서는 각각의 client를 구분할 방법이 필요해짐.
=> TCP 헤더 안에 있는src port 번호,dest port 번호로 구분함
=> TCP 헤더를 감싸고 있는 IP 헤더 (src IP 번호,des IP 번호)로 구분함
=> 4가지를 페어로 해서 각각 어느 소켓에 해당하는 패킷인지 판단하는 기준 근거로 삼는다.
- 동일한 포트로 들어오는 연결이라 할지라도 각각의 소켓으로 넘겨줄 수 있다.
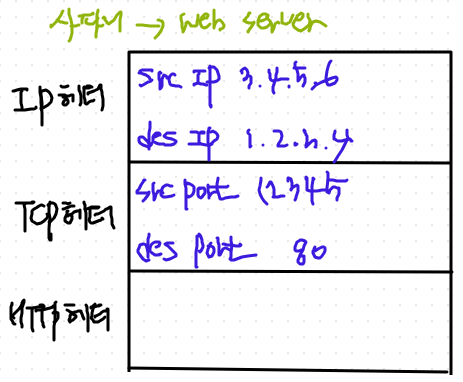
예시1) 사파리에서 web server로 접근하는 (data packet), http request packet이 있다고 치자.
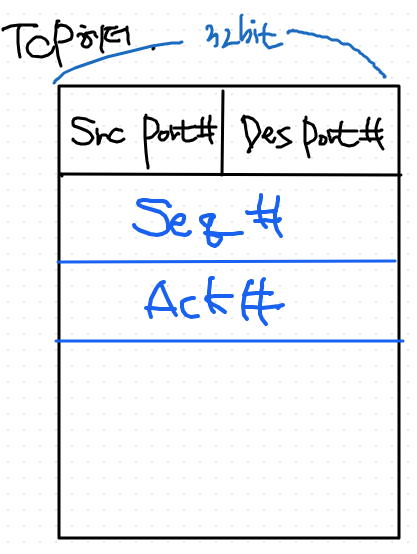
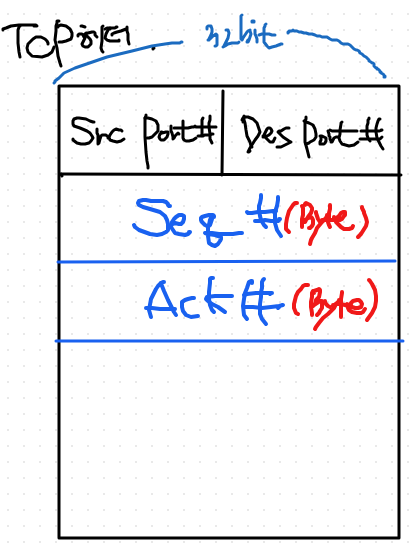
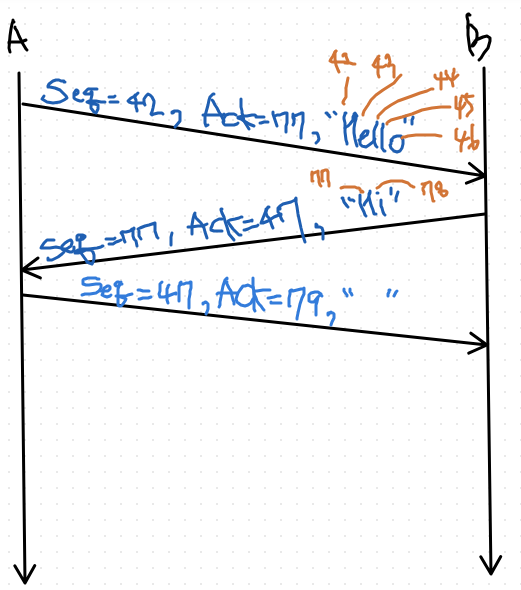
TCP 헤더의 2번째, 3번째 줄의 32 bit에 대해 알아보자
-
Seq 넘버
-
Ack 넘버
-
reliable 네트워크과 관련있음
- 어떻게 TCP로 신뢰성 있는 통신을 제공할 것인가?
우리가 지난 시간에 배운 것.
- 실제로 보내는 packet과 ack packet은 구별되는 packet이다.
그런데 tcp에서는, - seq number와 ack number가 같은 packet에 적히게 된다.
우리가 지금까지 배운것.
- seq number와 ack number는 packet의 번호였음.
하지만 tcp 헤더에서는, - 몇번째 byte 번호인가에 해당하는 번호다.
- 100 byte를 보내면, seq number가 100 증가됨
- packet마다 번호 x, byte마다 번호 o
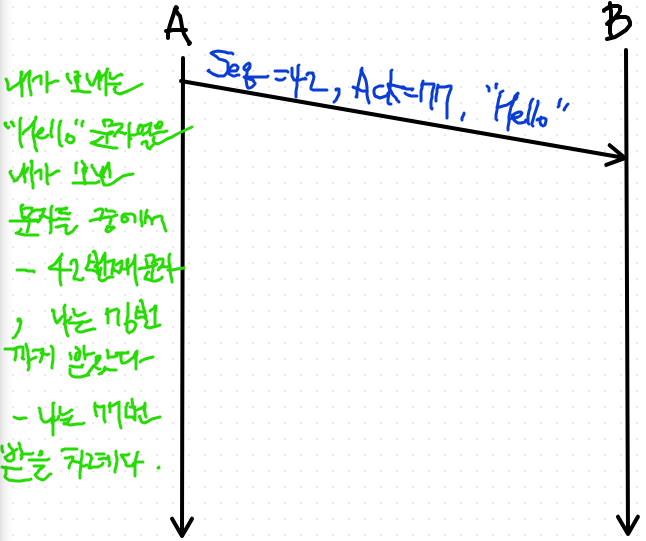
- 나는 42번 문자 부터 보내고 있다.
- 나는 77번 byte 받을 차례다
ex) H=> 42번 문자, e=> 43번 문자, l => 44번 문자, l=> 45번 문자, o=> 46번 문자
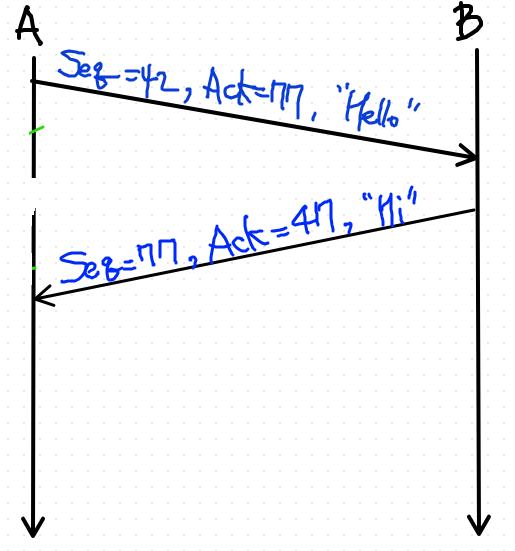
답변 ex) h => 77번 문자, i => 78번 문자
-
나는 77번 byte부터 보내고 있다.
-
나는 47번 byte 받을 차례다.
-
tcp에서의 내용 송수신 단위는 byte다.
-
tcp에서는 보내는 단위는
segment라고 한다. -
packet은 그 자체로서 의미있는 내용의 단위 vs segment는 조각임.
- 만약 여기에 대해서 A가 별 할말이 없었다?
=> 그냥 ACK만 보내면됨. - TCP 안에는 아무 내용이 없는 문자열 패킷도 보낼 수 있음.
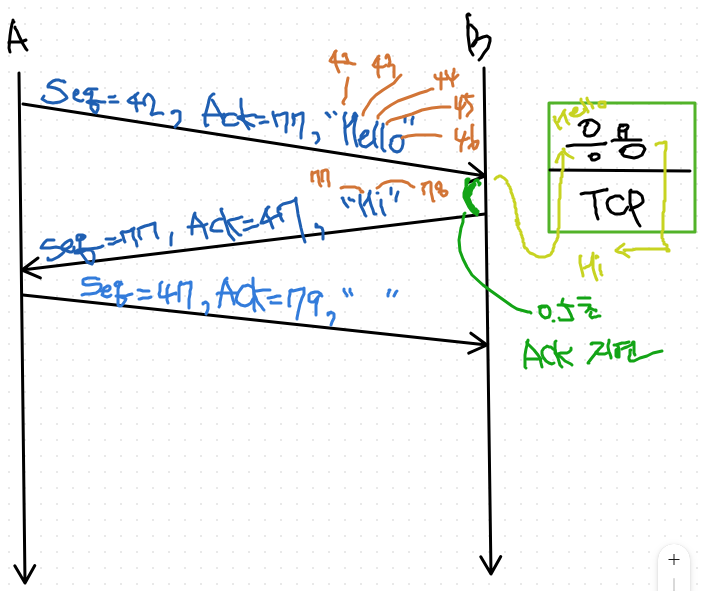
- 네트워크 통신양을 아끼기 위해서 0.5초 기다리게 된다.
- 혹시나 응용이 응답을 만들어내면, 첨부해서 답장을 하고,
- 0.5 초가 지나도 응용이 아무런 이야기도 하지 않으면, 아무 내용도 담지 않은 내용을 보내면 된다.
TCP가
- Go-back-N 기법을 사용하게 될지
- Selective-repeat을 사용하게 될지
고민할 필요가 있다.
답: Go-back-N기법에 기반한다.
이유) - Selective Repeat
- 수신자가 현재 몇 번째 패킷을 받았는지 알려야 한다.
- 수신자는 각 패킷의 상태를 개별적으로 관리하고, 손실된 패킷만 재전송 요청한다.
- 이는 수신자가 많은 상태 정보를 유지해야 하고, 더 복잡한 구현을 요구한다.
- 그러나 TCP는,
- TCP는 수신자가 현재 몇 번째 패킷을 받을 차례인지 ACK 번호만 알려준다.
- 구체적으로 몇 번째 패킷을 받았고, 못받았는지를 상세히 이야기하지 않는다.
- 수신자는 연속된 패킷만 ACK를 통해 확인하고, 중간에 손실된 패킷이 있으면 그 이후의 모든 패킷을 다시 요청한다
결론: TCP는 연속적인 패킷의 ACK만을 전달하는 Go-back-N기법에 기반한다. 따라서 TCP는 수신자가 현재 받을 차례인 패킷의 번호만을 알려주는 방식으로 동작한다.
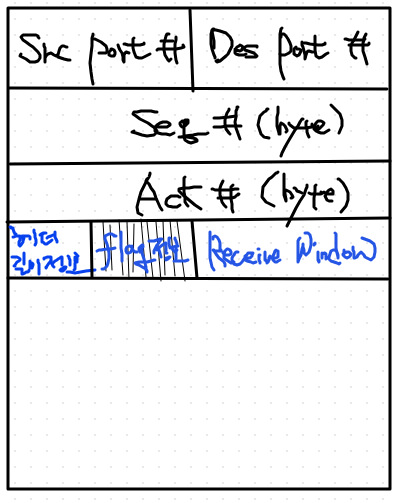
TCP 의 네번째 32bit는 어떤 내용일까?
- tcp 헤더 길이 정보
- tcp 헤더의 길이는 고정되어 있지 않다.
- 뒤에 optional한 정보를 채울 수도 있고, 안채울 수도 있는 가변적 특성
- flag 정보
- 이것이 혹시 전체 tcp connection을 맺고 끊는 제어 패킷이냐 아니냐 의 정보
- hand shaking 이런 제어 패킷이 주고 받아지면, tcp 연결이 맺고, 끊겨짐.
- 이것이 맺으려고 하는지, 끊으려고 하는지 정보가 필요하니 그 bit들을 세팅하냐 안하냐 할 수 있음.
- Receive Window
- 수신 가능한 Buffer 크기
- buffer 크기가 크면, 나한테 마음껏 보내라는 뜻.
- buffer가 0이면, 송신 쪽에다가 받을 수 없다고 이야기 하는 것.
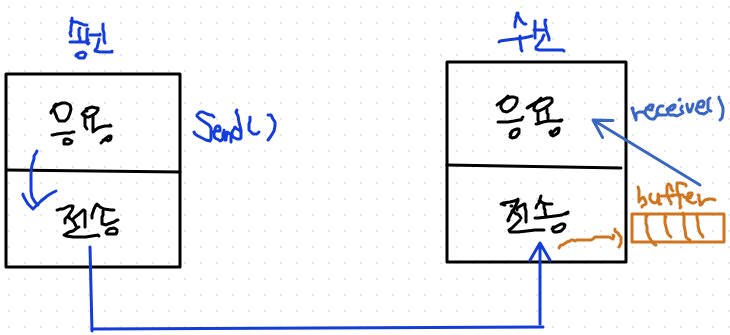
-
송신측 응용계층에서 send()실행하면,
-
송신측 전송계층에서 데이터를 수신측에 보낸다.
-
수신측 전송계층에서 해당 데이터를 buffer에 저장했다가.
-
수신측 응용계층에서 receive()를 실행하면,
-
그때 데이터를 응용계층으로 올려보낸다.
-
수신측 응용계층에서 receive 함수를 실행하지 않았는데, 전송계층에서 올려보내지 않는다.
- 대부분 운영체제에서 지원하지 않아.
-
그런 과정에서, 송신측은 계속 데이터를 보내고, 수신측은 buffer에 데이터를 계속 쌓는다.
-
그러다가, buffer가 꽉 차면 이제 패킷을 버리게 된다.
=>네트워크 낭비 -
이를 막기 위한 필드가
Receive Window임. [흐름제어 관련 내용임]- Receive Window가 자꾸 줄어들면 송신측에서는 이 window가 넘치지 않을 정도만 수신측에 패킷을 보낸다.
- => 더이상 보내지 않을 때 송신측에 buffer를 두고 거기다가 패킷을 저장하고 있는다
- => 그 buffer도 꽉찼는데, 응용계층이 전송계층한테 또 보내!! 라고 하면?
- => 전송계층이 응용계층에게
error로 응답
checksum
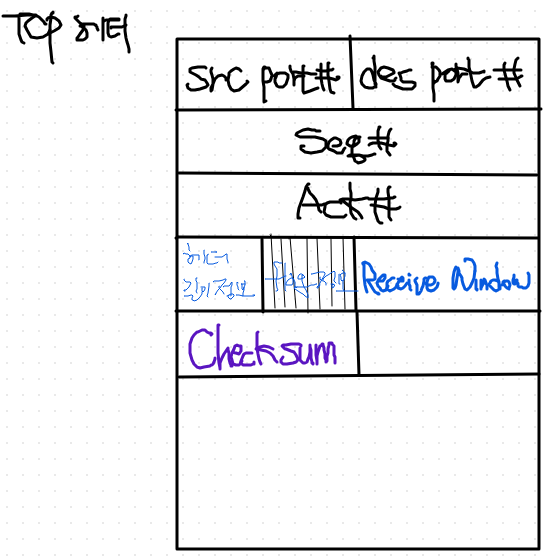
- 내용 변조 탐지를 위해 존재하는 tcp 전송계층에 있는 기법임.
- tcp에도 있고, udp에도 있음
- udp가 내용이 유실될 수도 있고, 순서도 바뀔 수 있지만, 내용 변조되는건 막아줌.
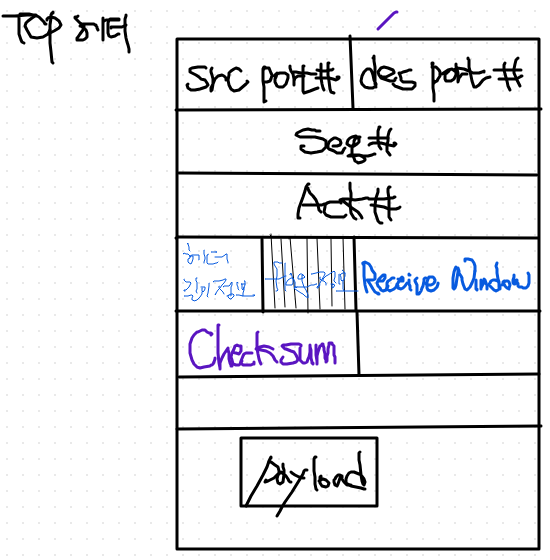
- 만약 밑에 payload 까지 있으면, 하나의 segment가 완성되는 것.
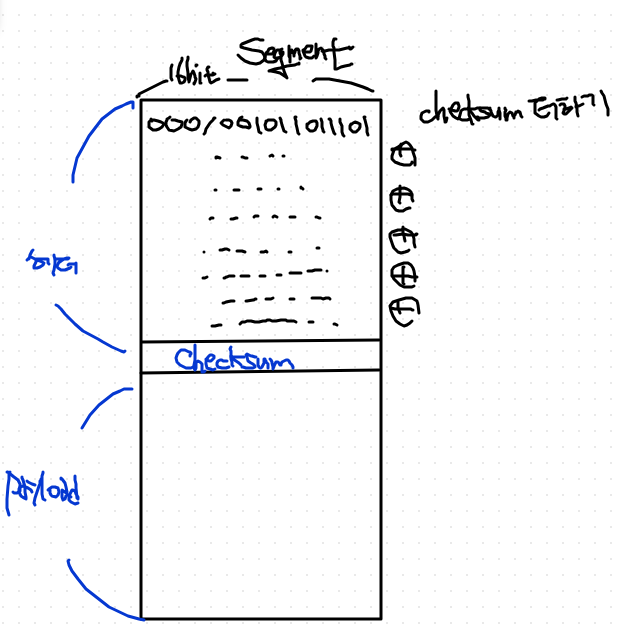
- tcp segment를 16 bit로 만들어보자
- 그리고, 이진수로 표현해보자.
- checksum 더하기를 하는 것.
- checksum 더하기란?
checksum 더하기란?
- 이진수 더하기
일반 이진수 더하기
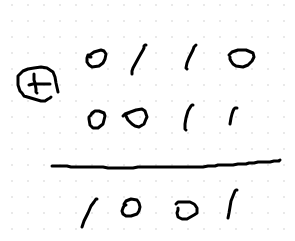
checksum 더하기
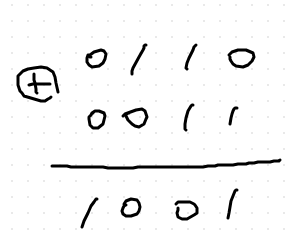
- 여기선 두개의 답이 동일하다.
- 올림이 없기 때문임. (캐리(carry)는 이진수 덧셈에서 자리 올림을 의미)
올림이 있는 경우를 보자.
일반 이진수 더하기
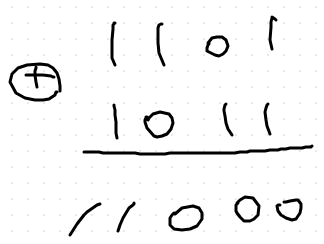
checksum 더하기
- 캐리가 생길 경우 캐리를 한번 더 더하는 것이다
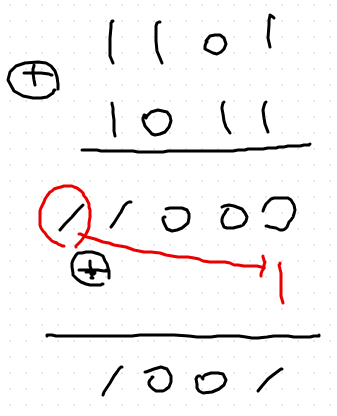
- checksum 더하기를 하면 무조건 4자리 수가 나올 수밖에 없음.
다시, checksum 으로 돌아가서 ,,,
checksum
- checksum이 하는 역할
- segment의 이진수 전체 모든 값을 더했을 때, 최종 값이 1111111111111111이 되도록 조작을 하는 것임.
- 예를 들어, checksum 을 제외한 모든 값을 checksum 더하기 했을 때 값이
1100101110000110이라면 그 값의 반전 시킨 것이 checksum이 된다. 그 둘을 더하면 1111111111111111이 되니까 !!!!
checksum은 0011010001111001 이 된다. - 만약, 중간에 데이터가 변조된다면 마지막 결과값이 1111111111111111 이게 깨진다.
=> 중간에 0이 섞이면, 이 데이터를 버린다. - 물론, 내용 변조가 고의적인 보안 공격이면, 실제로 checksum 까지 바꿔버리니까, checksum이 고의적인 내용 변조까지는 못 알아냄.
- 노이즈나 잡음에 의한 변조는 알아낼 수 있음.
=> 그럴 때는digital signature전자 서명 방법을 써야함.
