목표
TCP 및 UDP 구조를 배운다.
지난 시간
- 어떻게
신뢰도 있는 네트워크를 보장 하는가?
- 패킷 유실 때,
- 패킷 순서 바뀔 때,
복구하는 방법에 대해 알아봄
- 어떻게
Port와 Socket을 TCP에서 지원을 하는가? - 어떻게 내용이
변조됐을 때 탐지하는가?
- 잡음이나 기타 interference 등
- 이 내용은 어떻게 버리는가?
- 보안 공격 때 x
- receiver가 더이상 패킷을 받아들일 공간이 없을 때, transmitter가 이를 인지하고 패킷 전송을 중단하는 방법은?
=>흐름 제어에 관한 것.
이번 시간
이제 혼잡 제어에 대해 알아보자.
혼잡제어란?
: 네트워크가 혼잡한 상황에서 tcp가 이를 인지하고 제어하는 것. (전체 사회를 돕는 느낌)
tcp를 언제 사용하는가?
- 파일 교환
- 커다란 동영상 파일을 주고 받을 때, 최대한 많은 대역폭, 즉, 네트워크에서 제공하는 자원을 많이 사용할수록 데이터를 더 빨리 받는다.
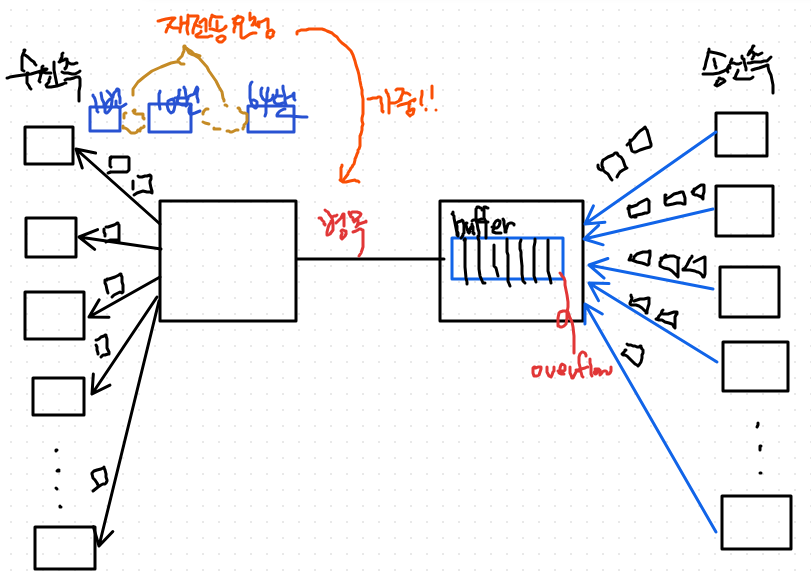
- 병목 현상 더 가중됨
- 네트워크에 많은 부하가 걸렸을 때, 송신측에서 송신량을 조절해서 부하를 제어 해야 함.
=> 컴퓨터에서는 혼잡을 제어할 수 있는 프로토콜을 설계해야함.
이 혼잡상황을 tcp에서 제어하는 것에 대해 말해보자 !!
혼잡 제어
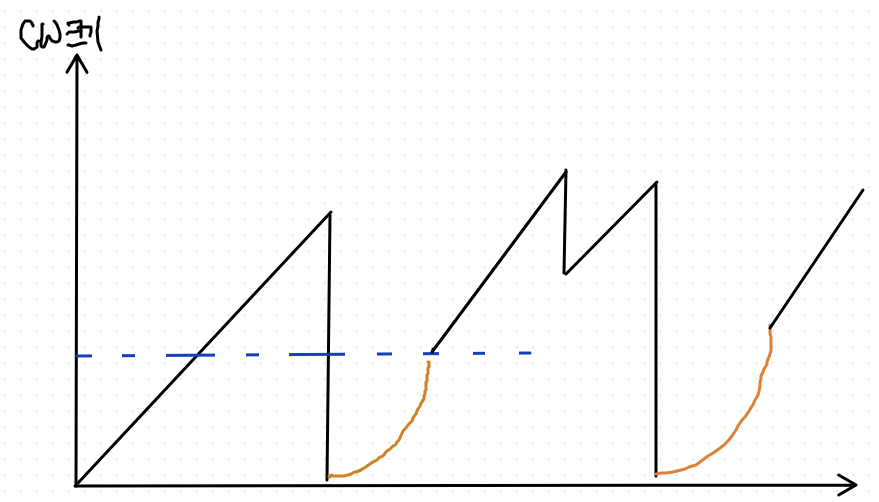
1.혼잡 인지
전체 맥락
패킷 유실이 발생하면
=> 혼잡 상황이라고 인지.
=> 패킷 전송률을 낮춘다.
(처음에는 패킷 전송률을 나누기 2로 낮춘다.)
패킷 전송 원활(유실 x)
=> 비혼잡 상황이라고 판단.
=> 패킷 전송률을 증가시킨다.
(현재 전송률 + C(상수))
Additive Increase
Multiplicative Decrease
=> AIMD
: 증가시킬 때는 선형적으로, 줄일 때는 기하급수적으로
패킷 유실
- 패킷유실이란 ACK 신호가 Timeout 내에 오지 않는 것.
Timeout은 너무 길거나 너무 짧아서는 안된다.- 너무 길 때: 재송신 지원 많아짐
- 너무 짧을 때: false alarm (정상적으로 패킷이 갔는데도 유실로 판단)
Timeout 어떻게 설정하나?
- 패킷 유실을 판단하는 Timeout은 즉, 재전송을 결정하는 것임.
=>Retransmission Timeout(RTO)
RTO를 판단하려면 기본적으로 네트워크 지연시간이 어떤 분포를 따르는지 알아야 한다.
EX) 미국과 통신할 땐, 장거리에 많은 장비를 거침- 기본적으로 지연시간 김
- 이럴 땐 timeout이 너무 짧으면 패킷 대부분이 걸림
EX) 가까운 곳과 통신할 땐 금방 됨. - 가까운 거리일 땐 Timeout이 너무 길면 패킷 유실 때도 한참 기다림
실제로 내가 패킷을 보내고, ACK 받을 때까지 시간이 얼마나 걸리는지 샘플링해서 통계적으로 접근한다.
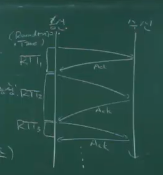
- RTT를 계속 측정하다보면 분포가 생긴다.
=> Retransmission Timeout 기준을 잡으면 ACK이 그 안에는 들어오겠다 ~
그런데 chatgpt는 RTO를 Recovery Time Objective라고 표현함.
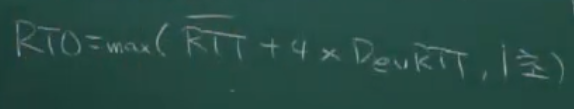
- RTO = RT 평균값 + 4 * DevRT(RT 표준편차)
- 대신 1초보다 짧음
RT이 여러가지 값을 가지게 되는 이유 분석
-
네트워크 장비의 전송지연이 많은 부분을 차지함.
-
각각의 장비에서 걸리는 큐잉 시간은 임의의 분포를 따른다
- ex) 포아송 분포, uniform한 분포, 아주 임의의 분포가 될 수 있다.
- 각 네트워크 장비는 이런 다양한 분포를 따를 수 있으며, 목적지까지 도달하는 데 여러 장비를 거쳐야 한다.
- 각각의 장비가 어떤 분포를 따르든, 여러 장비의 지연 시간을 합산한 값의 분포는 통계적으로 정규 분포(Normal Distribution), 즉 표준 분포를 따르는 경향이 있습니다.
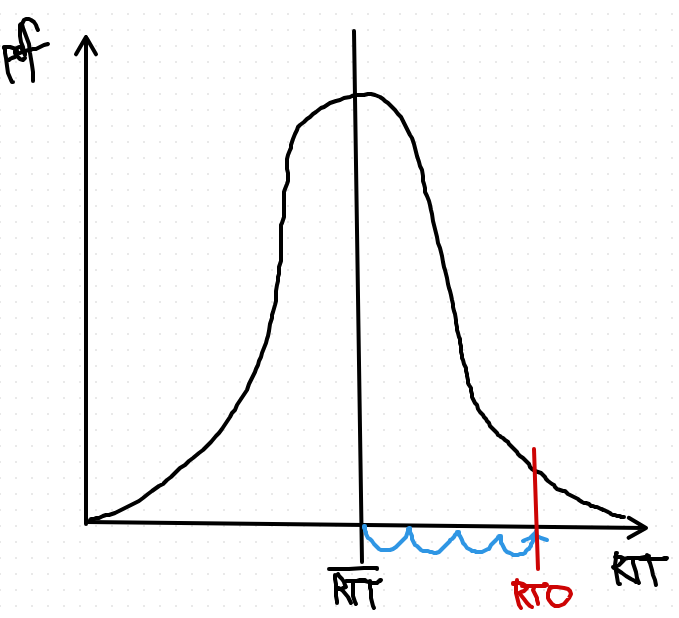
-
RTT(라운드 트립 타임)의 평균에 표준편차의 4배를 더한 값 (빨간선) 보다 큰 RTT가 나올 확률이 0.9999보다 작다.
: RTT 값이 평균 + 표준편차의 4배를 넘지 않을 확률이 매우 높다는 것을 의미합니다. 즉, RTT가 평균보다 훨씬 더 큰 값이 나올 가능성은 극히 적다는 것
=> 99.99 퍼센트 패킷들이 RTO 안에 통과를 한다는 뜻.
RTO = max(RTT 평균 + RTT 표준편차 * 4, 1초)이것보다 더 크게 만들면 너무 긴 재전송 지연 문제가 생김.
그러면 문제는 아래 두개 값을 어떻게 구할 것인가?
- 평균과
- 표준편차를!
RTT 을 구하는 평균값을 구하는 공식은 일반적인 평균값을 구하는 공식과는 다르다.
- 네트워크 상황 변화에 더 빠르게 반응하도록 최근 측저값을 가중치를 더 둔다. (가중 이동 평균)
- 가중 이동 평균은 방식 (Weighted Moving Average,WMA)
RTT 평균값 구하기
- 가중 이동 평균은 방식 (Weighted Moving Average,WMA) 을 사용함.
: 굉장히 중요한 기법임. 프로그래밍 코딩할 때 평균을 구할 때 효과적이고, 값의 의미도 좋음 !
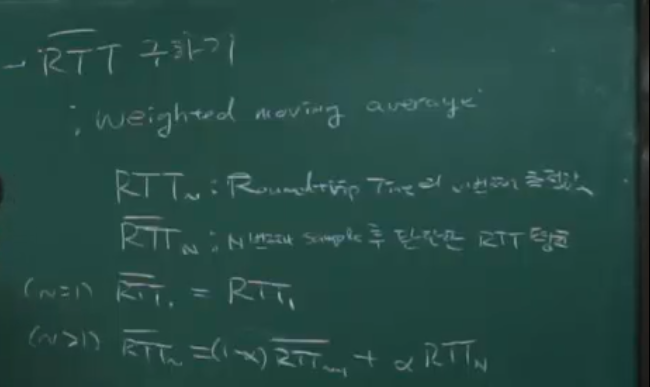
RTTn : Round trip Time의 n번째 측정값
RTT_n : n번째 sample 후 판단한 RTT 평균
(N=1) RTT_1 = RTT_1 (RTT1까지의 평균은 RTT1 그차제가 됨.)
(N>1) RTT_n = (1-α) * RTT_(N-1) + α * RTT_N
- TCP에서의 알파값은 0.125다. (1/8 정도임)

정리
혼잡인지를 하기 위한 것은
=> 패킷 유실이 되었는지 판단해야 하고,
=> Retransmission Timeout (RTO) 을 결정할 때,
=> Round Trip Time (RTT)을 이용한다.
=> RTT의 평균값을 이용할 때 Weighted Moving Average 기법을 사용한다.
혼잡제어
본격적으로 어떻게 혼잡제어를 하는지 이야기해보자 ~
AIMD: Additive Increase Multiplicative Decrease
Additive Increase
잘 전송이 됐을 때 어떻게 패킷을 한개씩 전송하는지 ?
- 단위 (Increase의 단위)
:MSS(Maximum Segment Size)- 실제로 두개의 노드가 TCP 커넥션을 맺은 다음에 협의에 의해서 결정하는 단위임
- 결정하는 기준은 중간 네트워크 장비들이 packet size를 어느것으로 쓰느냐에 따라서 결정한다.
- 중간에 인터넷 장비 등이 경로를 하나 만든다음에 경로에 segment size를 proving 하는 프로토콜이 있음 . 그러면 중간에 packet size 설정을 알 수 있음. segment size가 중간에 네트워크 장비들이 쓰는 packet size보다 큰걸 사용하면 프로토콜이 복잡해짐. segment size는 사실 얼마가 되든 상관없어. tcp 통신 단위가 기본적으로 byte이기 때문에 사실 상관은 없으나, 효율의 문제가 있는 것임. 크게 정할 수록 좋지만 중간의 장비가 segment size 를 처리하지 못하면 segment size를 다시 쪼개야 함. 한번 정해진 segment size로 통신하면 중간의 장비가 쪼개지 않는 것이 제일 효율적임.
- 보통 1KB ~ 4KB : 이 Maximum Segment Size를 정하게 되면은 tcp 패킷을 보낼 때 이 MSS보다 크게 보내지 않는다.
만약 더 큰 내용을 application이 보내달라 하더라도 이 MMS 사이즈로 잘라서 통신한다. - 네트워크 장비들
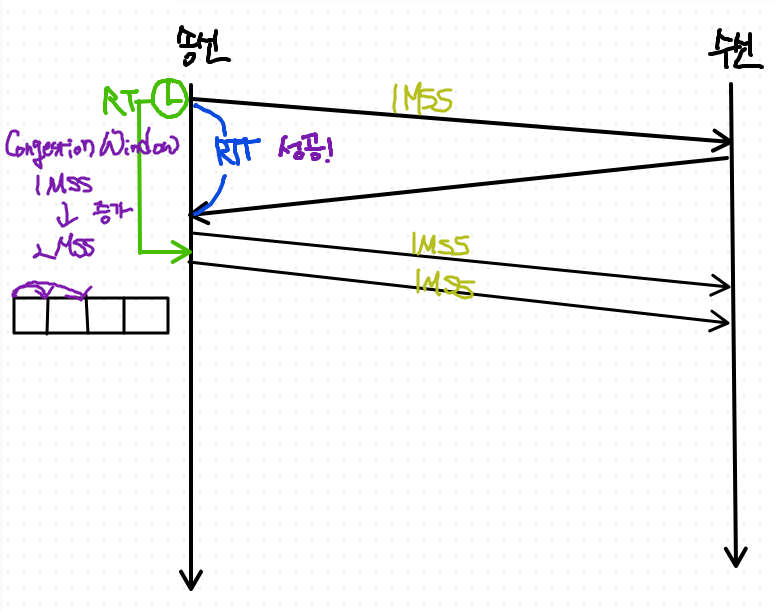
- 성공하면, window size를 1MSS 만큼 증가시킨다.
- congestion window size가 1 증가됨
- 1mss 보내고 ack이 안와도 또 1mss를 보낸다.
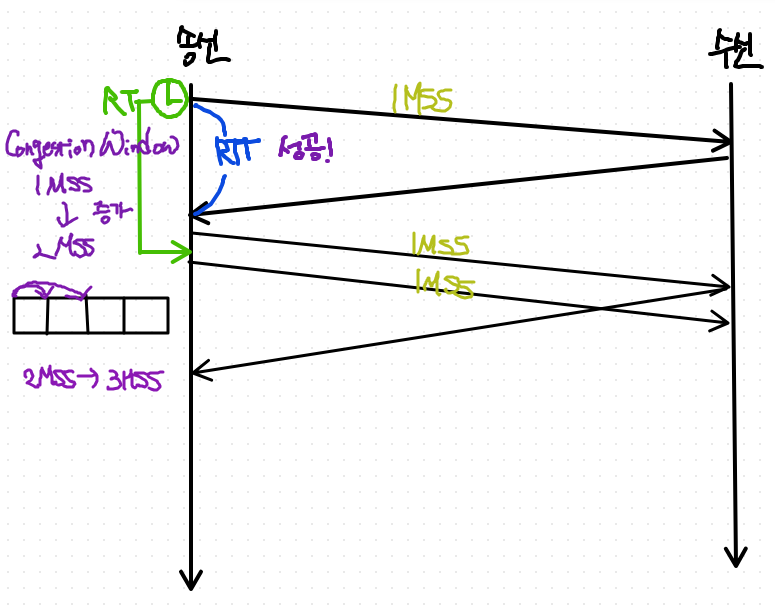
- 2MSS => 3MSS 로 증가
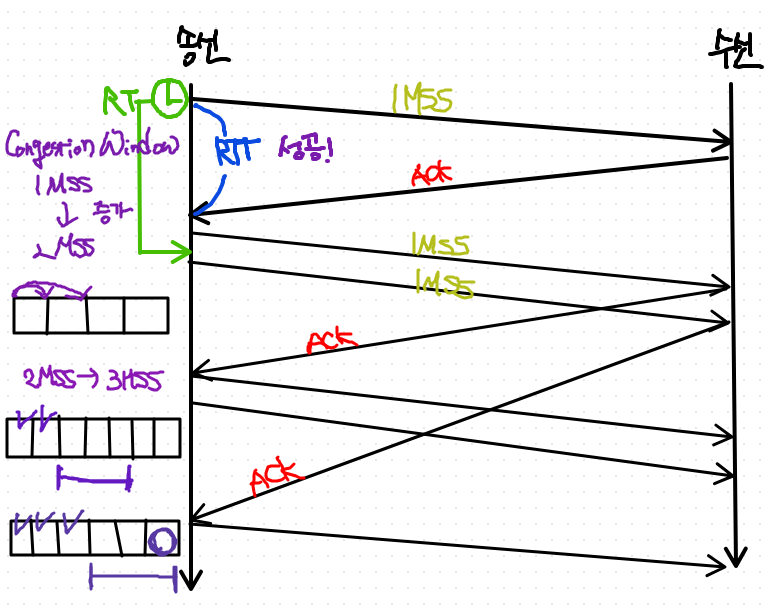
- 3MSS로 증가함
- 아직 ACK 하나 안온게 있으니까 2개 Packet 보낼 여력이 있는 것임
- 하나 ACK 받자마자 1개 Packet을 보낸다.
결론) RTT가 하나씩 성공할 때마다 동시에 보낼 수 있는 Segment size가 1MSS씩 증가한다.
Congestion window를 증가시키는 판단을 하는 것은,
congestion window를 증가시키자마자 바로 다음에 보내는 패킷이 돌아올 때 다음 congestion window를 판단한다. 한번의 RTT이 지나갈 때마다 판단을 하는 것이기 때문에, 그 사이사이 보내는 추가적으로 보내는 패킷의 ACK은 Additive Increase에 영향을 주진 않는다.
Multiplicative Decrease
- 패킷유실시 congestion window 크기를 절반으로 줄인다.
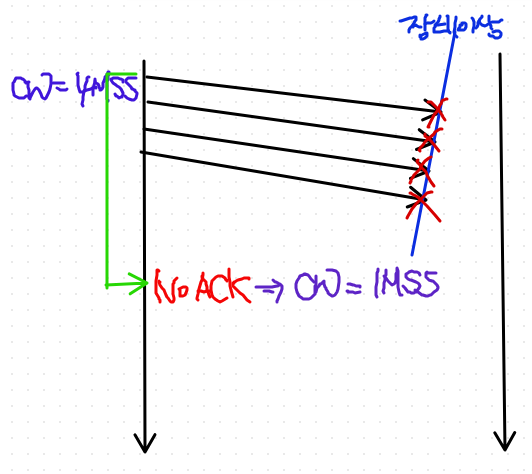
- 패킷 유실이 네트워크 이상을 반영할 때는 CW(congestion window)를 1MSS로 대폭 줄인다.
패킷이 단순히 유실된 case vs 네트워크가 이상해서 유실된 case
- 네트워크 이상시: 모든 전송 세그먼트가 동시 유실
- 모든 ACK이 도착하지 않는다. => RTO가 Trigger된다는 뜻.
- 단순 패킷 유실시: 유실된 네트워크 이후에 보낸 다른 세크먼트의 ACK이 도착
네트워크 이상시
위급 상황이니 1MSS로 단번에 줄인다.
단순 패킷 유실시
-
빠른 재전송이라고 함. 원래는 timeout 이 발생해야 재전송 했는데, 동일한 ACK이 여러개 오면 해당 SQ 세그먼트가 사라졌다는 것을 알 수 있기 때문에 빨리 재전송 해버림
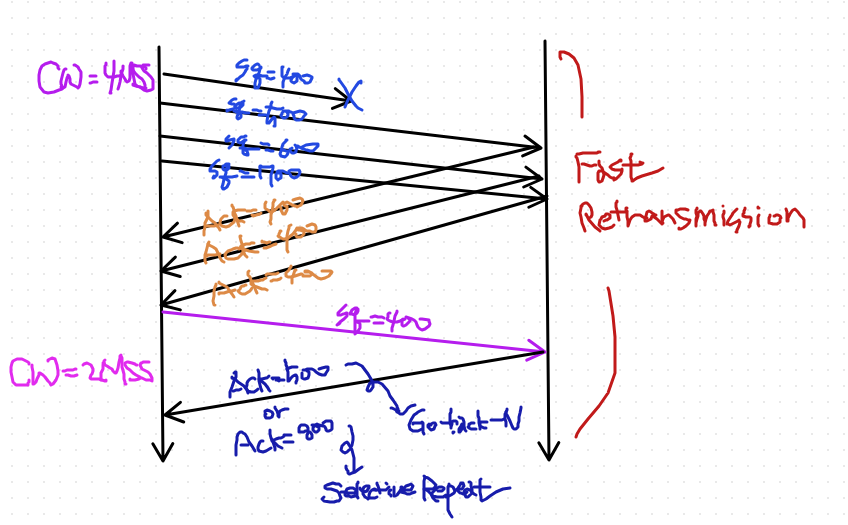
-
Fast Recovery: 반으로만 줄이기 때문에 훨씬 복구가 빨리된다.
Slow Start
네트워크 이상시 CW => 1이 된다.
문제: CW의 증가가 너무 느리다.
- 실제로 문제가 생겼던 장비가 다시 좋아질 수도, 더 좋은 경로를 찾을 수 있는데, CW =1로 두고, Additive Increase를 하면 너무 속도가 느리다.
만약 기존 CW = 100인 경우였다면?
=> Round Trip을 100번해야 cw가 100이 됨 ;;
=> CW 가 50이 될 때까지는 Muliplicative Increase를 하자.
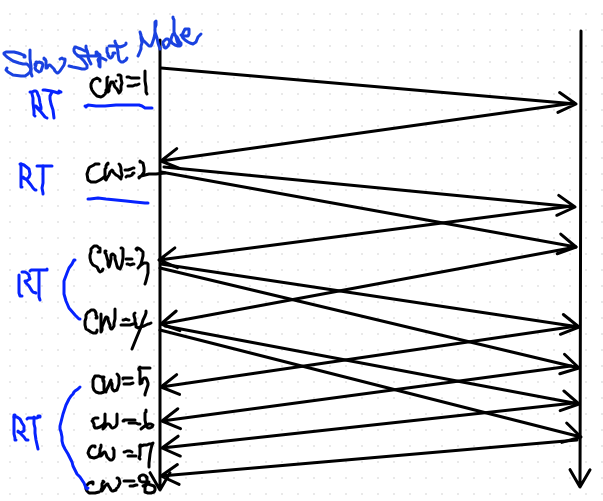
- 전송할 때마다 하나씩 cw를 증가시킨다. (원래는 한번의 round trip 때 cw를 증가시킨 것과는 대조됨)
=> 이 결과는 결국 한번의 round trip 때마다 cw가 2배로 증가되게 한다.
사실상 Multiplicative Increase 하는 것임.