디렉토리를 탐색할 방법까지 찾아서 드디어 크롤러를 완성했다
해답은 바로 알고리즘에 있었다.
def dfs_crawl(driver, visited, crawledPages, json_data):
while True:
soup = crawl_and_parse(driver)
seperator_div = soup.find('div', class_='v-subheader')
if not seperator_div:
print("No 'v-subheader' class found.")
break
siblings = seperator_div.find_next_siblings('div')
try:
current_dir = seperator_div.find_previous_sibling('div').getText()
prev_div = seperator_div.find_previous_sibling('div').find_previous_sibling()
if prev_div.getText() == "sidebar.root" or prev_div.getText() == "루트":
print("This is root directory")
break
except AttributeError:
break
unvisited_sibling = None
if current_dir not in crawledPages:
crawledPages.append(current_dir)
# 크롤링 수행
links = extract_links(driver)
for link in links:
print(link)
driver.get(link)
# time.sleep(1)
contents_html = crawl_html_by_class(driver, "v-main__wrap")
jsonData = extract_doc(contents_html)
print(json.dumps(jsonData, ensure_ascii=False, sort_keys=True, indent=4))
json_data.append(jsonData)
for sibling in siblings:
sibling_text = sibling.get_text().strip()
if sibling_text not in visited:
unvisited_sibling = sibling_text
break
if unvisited_sibling:
visited.add(unvisited_sibling)
path_pointer(driver, unvisited_sibling)
dfs_crawl(driver, visited, crawledPages, json_data)
else:
path_pointer(driver, prev_div.get_text().strip())
time.sleep(1)
break
return json_data코드가 좀 많이 길지만 밑으로 내려가 하나씩 뜯어본다
soup = crawl_and_parse_menu(driver) # (1)
seperator_div = soup.find('div', class_='v-subheader') # (2)
if not seperator_div:
print("No 'v-subheader' class found.")
break
siblings = seperator_div.find_next_siblings('div') # (3)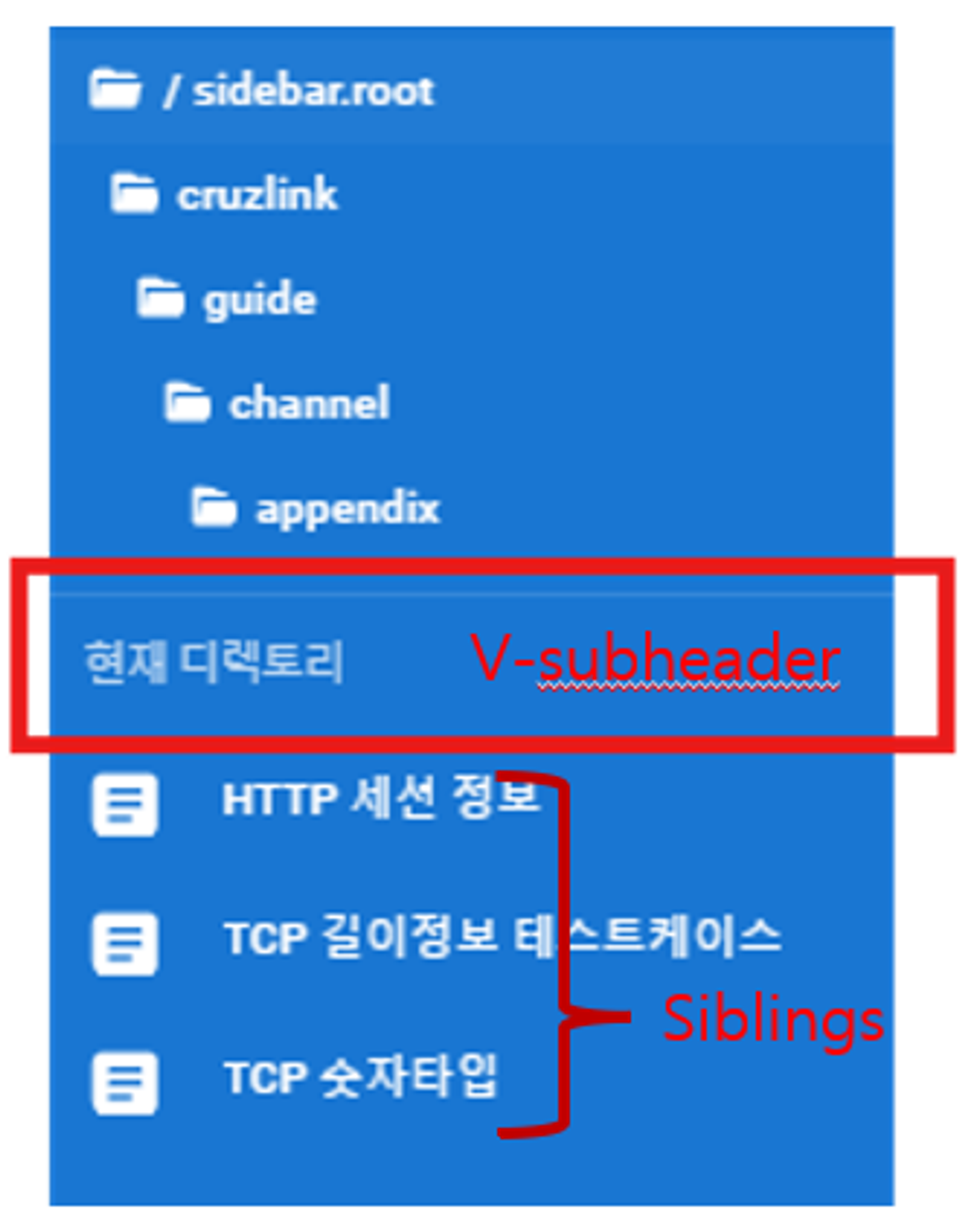
def crawl_and_parse_menu(driver):
contents_html = crawl_html_by_class(driver, "__view")
return BeautifulSoup(contents_html, 'html.parser')(1) __view class의 div 즉 메뉴바에서 HTML데이터를 긁어서 bs4로 파싱
(2) v-subheader는 메뉴바에서 디렉토리 이동과 현재 디렉토리 파일들의 path를 구분하고 있는 div
(3) seperator div 기준 아래는 현 디렉토리의 모든 파일 여기에는 파일 뿐만 아니라 이동 경로 또한 포함하고 있음
try:
current_dir = seperator_div.find_previous_sibling('div').getText() # (1)
prev_div = seperator_div.find_previous_sibling('div').find_previous_sibling() # (2)
if prev_div.getText() == "sidebar.root" or prev_div.getText() == "루트":
print("This is root directory")
break
except AttributeError:
break(1) 현재 크롤링을 수행하고자 하는 dir
(2) 현재 디렉토리를 기준으로 이전 디렉토리
def extract_links(driver): # (1)
html_content = crawl_html_by_class(driver, 'v-navigation-drawer__content')
soup = BeautifulSoup(html_content, 'html.parser')
links = []
for a_tag in soup.find_all('a', class_='v-list-item'):
href = a_tag.get('href')
full_url = urljoin("https://wiki.direa.synology.me", href)
if full_url not in links:
links.append(full_url)
return linksunvisited_sibling = None # (2)
if current_dir not in crawledPages:
links = extract_links(driver)
for link in links: # (3)
driver.get(link)
contents_html = crawl_html_by_class(driver, "v-main__wrap")
jsonData = extract_doc(contents_html)
json_data.append(jsonData)
crawledPages.append(current_dir) # (4)(1) 메뉴바에서 모든 파일의 링크 src를 추출하는 함수
여기서 파일을 담고 있는 div의 class는 v-list-item이다
(2) 깊이 탐색을 위한 미방문 노드 리스트
(3) 문서를 순회하며 데이터 크롤링
(4) 크롤링 이후 방문 노드로 append
”크롤링 목적의 깊이탐색”
def path_pointer(driver, text):
driver.find_element(By.XPATH, f"//div[@class='v-list-item__title'][contains(text(), '{text}')]").click()
time.sleep(1)for sibling in siblings:
sibling_text = sibling.get_text().strip()
if sibling_text not in visited: # (1)
unvisited_sibling = sibling_text
break
if unvisited_sibling:
visited.add(unvisited_sibling)
path_pointer(driver, unvisited_sibling) # (2)
dfs_crawl(driver, visited, crawledPages, json_data) # (3)
else:
path_pointer(driver, prev_div.get_text().strip()) # (4)
break(1) 방문하지 않은 노드면 unvisited_sibling에 선언
(2) 현재 pointer가 바라보는 디렉토리가 방문하지 않은 노드면 해당 디렉토리로 이동
(3) 재귀적 호출
(4) 주석 (2)번 조건이 아니라면 이전 디렉토리로 이동
”디렉토리 이동 목적의 깊이탐색”

기록 == 성장