메뉴바에서 URL 수집
이전장에서는 로드된 페이지 내에서 데이터를 수집했지만 모든 디렉토리를 개발자가 직접 입력해가며 크롤링을 진행하는것은 무리가 있다
페이지를 살펴보면 좌측 메뉴바에는 이동할 디렉토리 경로와 문서들을 확인할 수 있다.
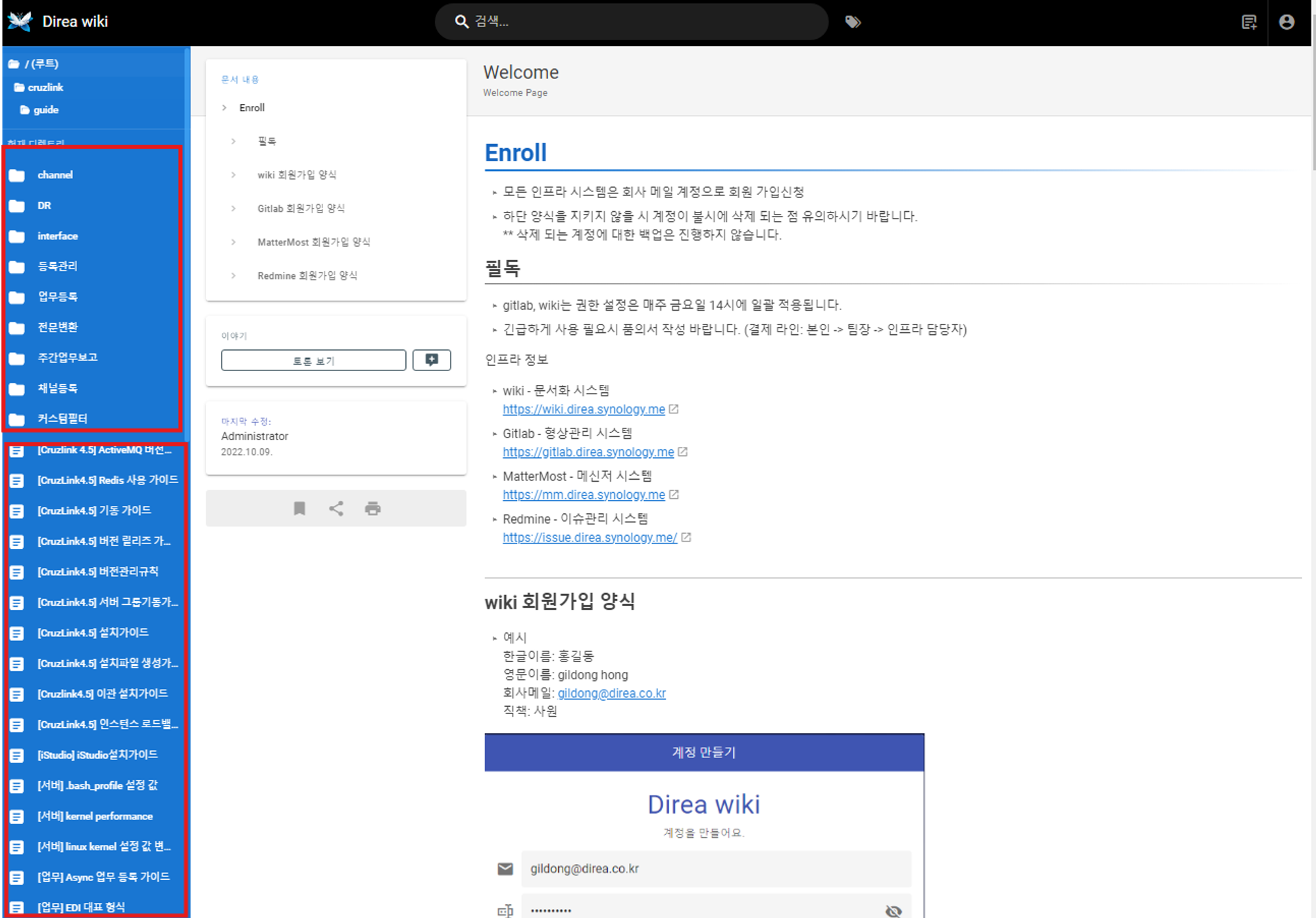
개발자 도구를 통해 살펴보면 메뉴바의 태그 안에 경로 이동을 수행하는 div와 문서 url로 이동하는 태그를 확인할 수 있다.

최종적으로는 디렉토리를 모두 순회하면서 그과정에 문서들을 순회하며 데이터를 수집하는 것으로, 모든 디렉토리를 순회하는 것은 좀더 연구가 필요한 부분이다.
1차 적으로 지금은 페이지를 로드했을 때 메뉴nav 태그 내에 있는 모든 문서 URL을 메뉴바 SRC에서 수집한다
수집한 URL을 반복문으로 돌며 셀레니움이 페이지 이동을 수행하고 이동한 문서에서 데이터를 수집할 것이다.
def crawl_full_page(driver):
contents_div = driver.find_element(By.CLASS_NAME, 'v-navigation-drawer__content') #(1)
contents_html = contents_div.get_attribute('outerHTML')
return contents_html(1) 데이터는 메뉴바 태그
v-navigation-drawer__contentclass에 있으며 여기서 html데이터를 뽑아온다
def extract_links(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
links = []
for a_tag in soup.find_all('a', class_='v-list-item'): # (1)
print(a_tag)
href = a_tag.get('href') # (2)
full_url = urljoin("https://wiki.direa.synology.me", href) # (3)
if full_url not in links:
links.append(full_url)
return links(1) 전체 HTML을 순회하며 BeautifulSoup가 a태그의 클래스를 기준으로 find한다
(2) 찾은 a태그에서 url정보를 가지고 있는 href 정보를 추출한다
(3) href 정보에서 baseUrl은 포함하고 있지 않으니 추가해준다.
try:
# 로그인 수행
login(driver, url, user_id, user_pw)
print("Logged in successfully.")
# (1)
target_url = 'https://wiki.direa.synology.me/ko/cruzlink/guide/activemq_versionup_guide'
driver.get(target_url)
time.sleep(2)
# 페이지 전체 HTML 크롤링
contents_html = crawl_full_page(driver)
print("Full page HTML loaded and contents extracted.")
# 링크 추출 및 리스트에 추가
base_url = 'https://wiki.direa.synology.me'
collected_links = extract_links(contents_html)
print("Collected links:", collected_links)
finally:
driver.quit()(1) 글 초반부 언급했던 내용으로 페이지를 이동하는 부분을 동적으로 구현해야 한다.
동적 크롤링에 적용
이제 구현부를 이전에 구현했던 동적 크롤링에 적용해본다
def extract_links(driver):
html_content = crawl_html_by_class(driver, 'v-navigation-drawer__content')
soup = BeautifulSoup(html_content, 'html.parser')
links = []
for a_tag in soup.find_all('a', class_='v-list-item'): # (1)
print(a_tag)
href = a_tag.get('href')
full_url = urljoin("https://wiki.direa.synology.me", href)
if full_url not in links:
links.append(full_url)
return links(1) 셀렉터가 바라볼 클래스는 v-navigation으로 메뉴바의 링크를 담고 있는 v-vist-item의 text추출
links = extract_links(driver)
JSON_DATA = []
for link in links:
print(link)
driver.get(link) # (1)
time.sleep(2)
contents_html = crawl_html_by_class(driver, "v-main__wrap")
JSON_DATA.append(extract_doc(contents_html)) #(2)(1) 링크 리스트에서 하나씩 꺼내서 이동
(2) 문서 내용을 JSON 형식으로 변환 후 List에 append
