문제의 발단
request 방식으로 url요청하여 HTML 모든 데이터를 추출
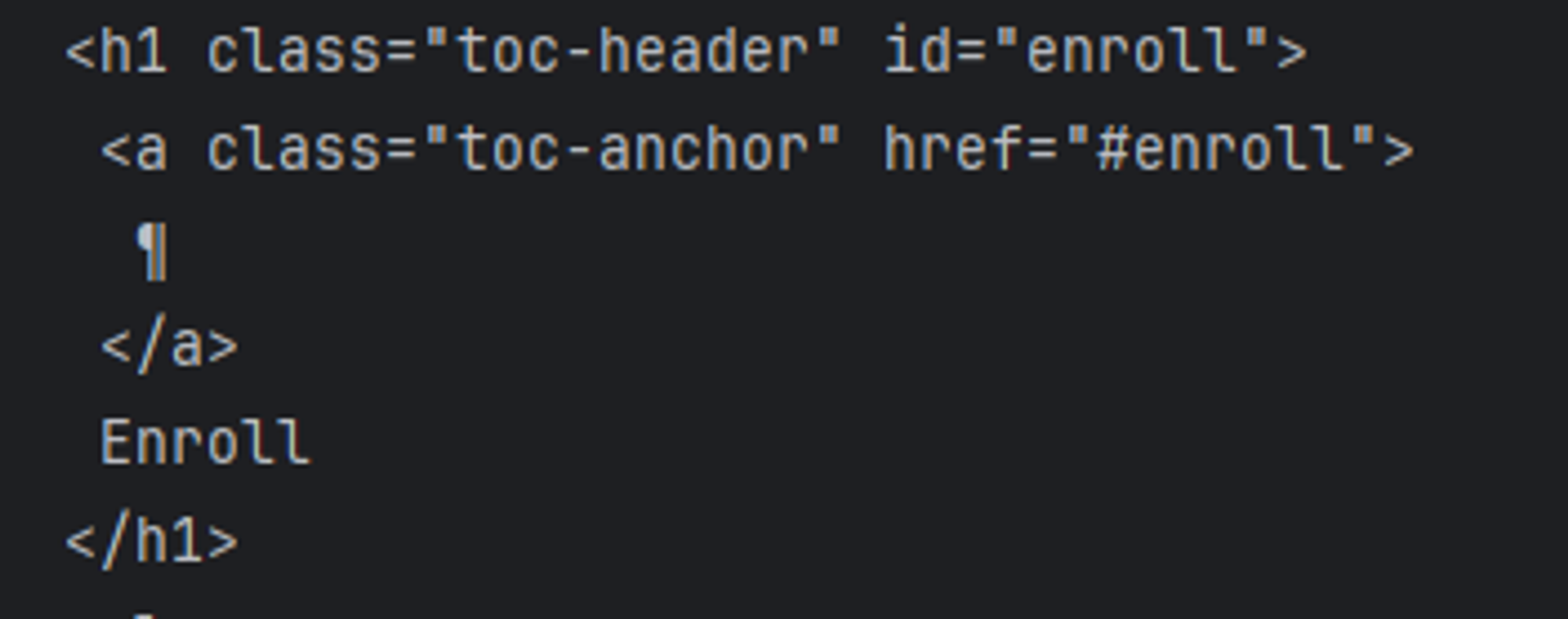
추출한 데이터를 로그로 찍어보면 enroll이 보인다 이 데이터를 추출해보려하면
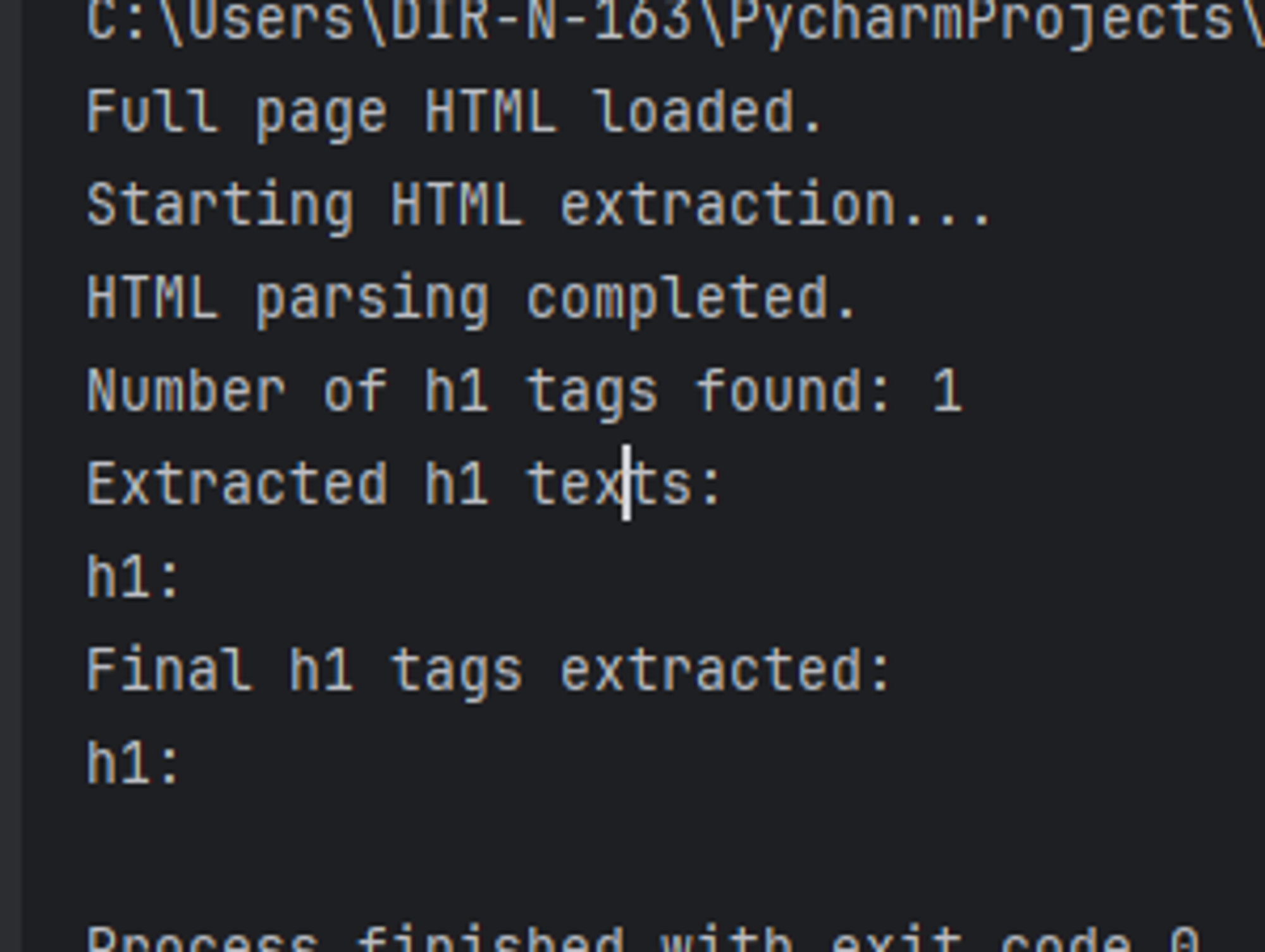
로그에서 분명 확인했는데 막상 추출하면 데이터가 비어 있다.
이유는 js 렌더링 이전의 데이터를 긁어 오고 있기 떄문
Selenium은 실제 브라우저를 자동화하여 웹 페이지를 렌더링하는 반면, request로 받아온 HTML을 파싱하는 BeautifulSoup는 단순히 HTML 텍스트를 파싱하는 라이브러리. 둘 사이의 주요 차이점과 BeautifulSoup이 실패한 이유는 다음과 같다
1. JavaScript 렌더링
- Selenium: Selenium은 실제 브라우저(예: Chrome, Firefox 등)를 사용하여 웹 페이지를 로드하고 렌더링합니다. 따라서 페이지 내의 JavaScript 코드가 실행되어 동적으로 생성된 콘텐츠도 가져올 수 있습니다.
- BeautifulSoup: BeautifulSoup은 정적 HTML을 파싱하는 도구입니다. 서버에서 초기 로드된 HTML만 처리할 수 있으며, JavaScript에 의해 동적으로 생성된 콘텐츠는 가져올 수 없습니다.
2. 동적 콘텐츠
- Selenium: 웹 페이지를 실제로 로드하고 렌더링하기 때문에 JavaScript로 생성되거나 변경된 모든 콘텐츠를 가져올 수 있습니다. 이는 웹 페이지가 로드된 후에 발생하는 모든 동적 변화를 포함합니다.
- BeautifulSoup: 서버에서 제공하는 초기 HTML만 파싱할 수 있습니다. 따라서 JavaScript에 의해 동적으로 추가된 콘텐츠는 포함되지 않습니다.
3. 페이지 로딩 및 대기
- Selenium: 웹 페이지를 로드하고 JavaScript가 완료될 때까지 대기할 수 있습니다. 예를 들어,
time.sleep(5)와 같은 명령을 사용하여 페이지가 완전히 로드될 때까지 기다릴 수 있습니다. - BeautifulSoup: HTML 텍스트를 바로 파싱하기 때문에 페이지 로딩 상태나 JavaScript 실행 상태를 고려하지 않습니다.
결론
Synology Wiki 페이지와 같은 사이트는 JavaScript를 사용하여 페이지 로드 시 동적 콘텐츠를 생성하거나 수정할 수 있습니다. BeautifulSoup은 이러한 JavaScript 처리를 수행하지 않기 때문에 동적으로 생성된 콘텐츠를 가져오지 못합니다. 반면, Selenium은 실제 브라우저를 사용하여 JavaScript를 실행하고, 모든 동적 콘텐츠를 포함한 완전한 페이지를 렌더링합니다.
이로 인해 BeautifulSoup은 정적 HTML 페이지에서는 잘 작동하지만, JavaScript로 동적 콘텐츠를 생성하는 페이지에서는 Selenium과 같은 도구가 필요함.

기록 == 성장