wiki 페이지를 크롤링하는 방법에 대해 정리한다.
1차적으로 단일 페이지를 크롤링하는 방법을 숙지하고,
추후 wiki의 모든 문서를 동적으로 크롤링하는 것이 목표이다
먼저 로그인부터 뚫어야 한다
셀레니움으로 로그인페이지에서 직접 input값에 id pw를 집어넣고
로그인 버튼을 click()해서 마치 사용자가 로그인 한 것처럼 페이지를 로드해보자
개발자 도구(F12)를 통해 입력하는 id와 pw의 input태그의 id를 확인

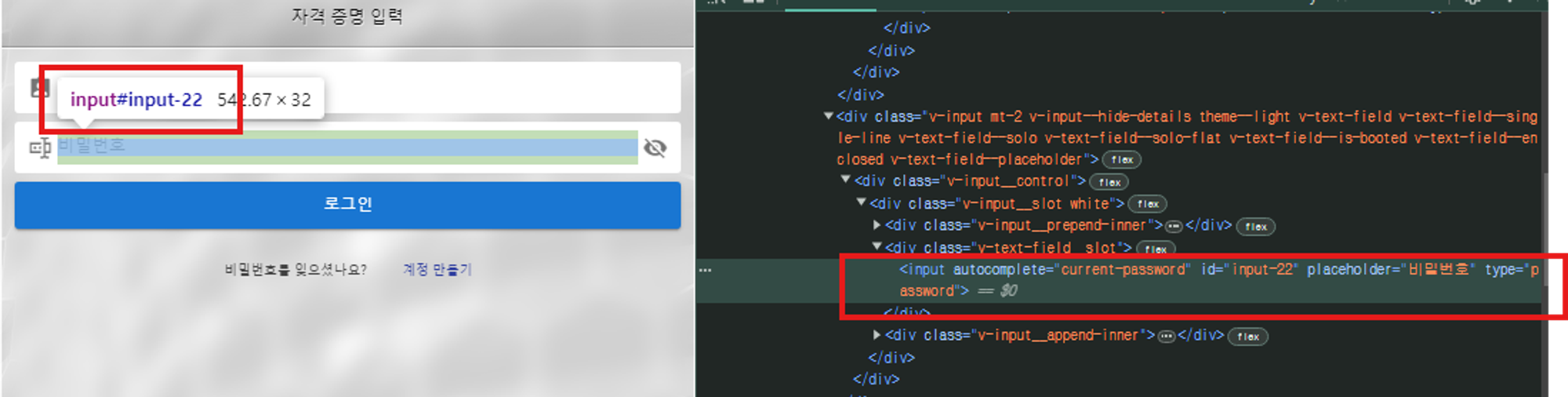
input 태그 안에 내 아이디와 비밀번호를 넣는다
driver.find_element(By.ID, 'input-20').send_keys(your_user_id)
driver.find_element(By.ID, 'input-22').send_keys(your_user_pw)로그인을 시도하는 방법으로는 form태그를 submit하는 방법도 있고
나의 경우 form태그가 보이지 않아서 버튼 onClick()이벤트로 로그인이 되는것이 아닌가 추정했다
selenium이 이럴떄 필요하기 때문에 셀레니움을 택한것.
class를 통해서 해당 button을 클릭하여 로그인을 시도한다
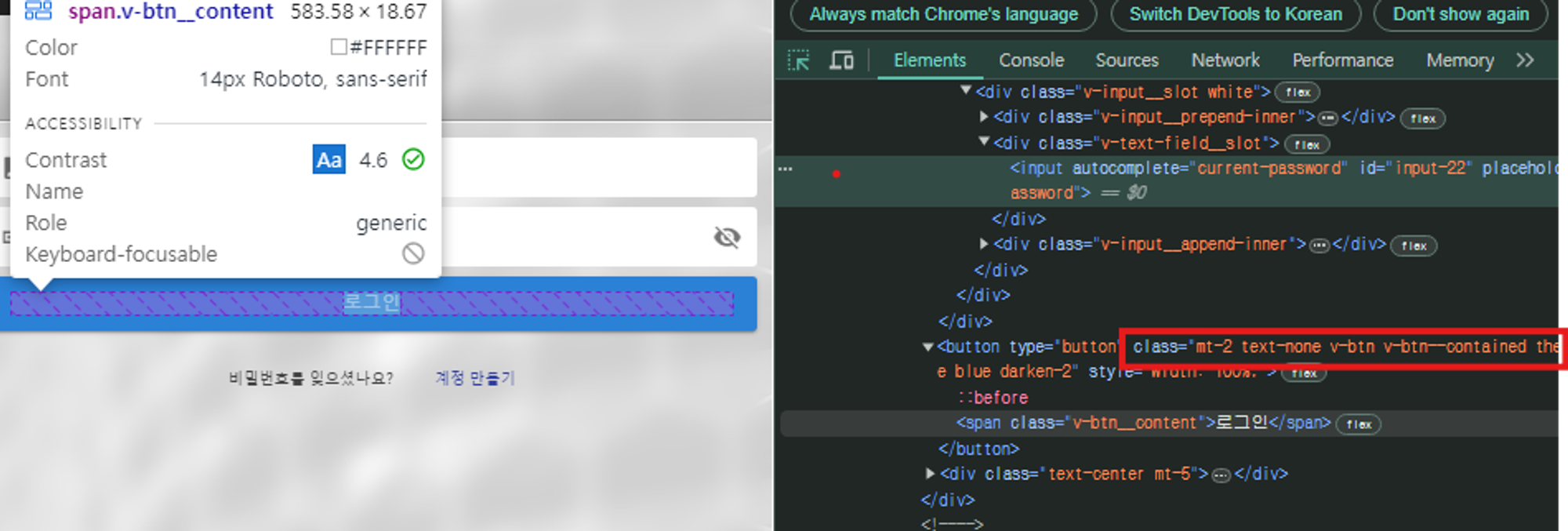
클래스명을 통해 button element를 찾고 click()
login_button = driver.find_element(By.XPATH, "//button[@class='mt-2 text-none v-btn v-btn--contained theme--dark v-size--large blue darken-2']")
login_button.click()
# or
# login_button = driver.find_element(By.CLASS_NAME, 'mt-2 text-none v-btn v-btn--contained theme--dark v-size--large blue darken-2')이제 로그인을 통해 권한이 필요한 문서도 모두 열람이 가능하니 본격적으로 페이지 구조를 확인하고 크롤링을 진행해본다.
페이지의 구조
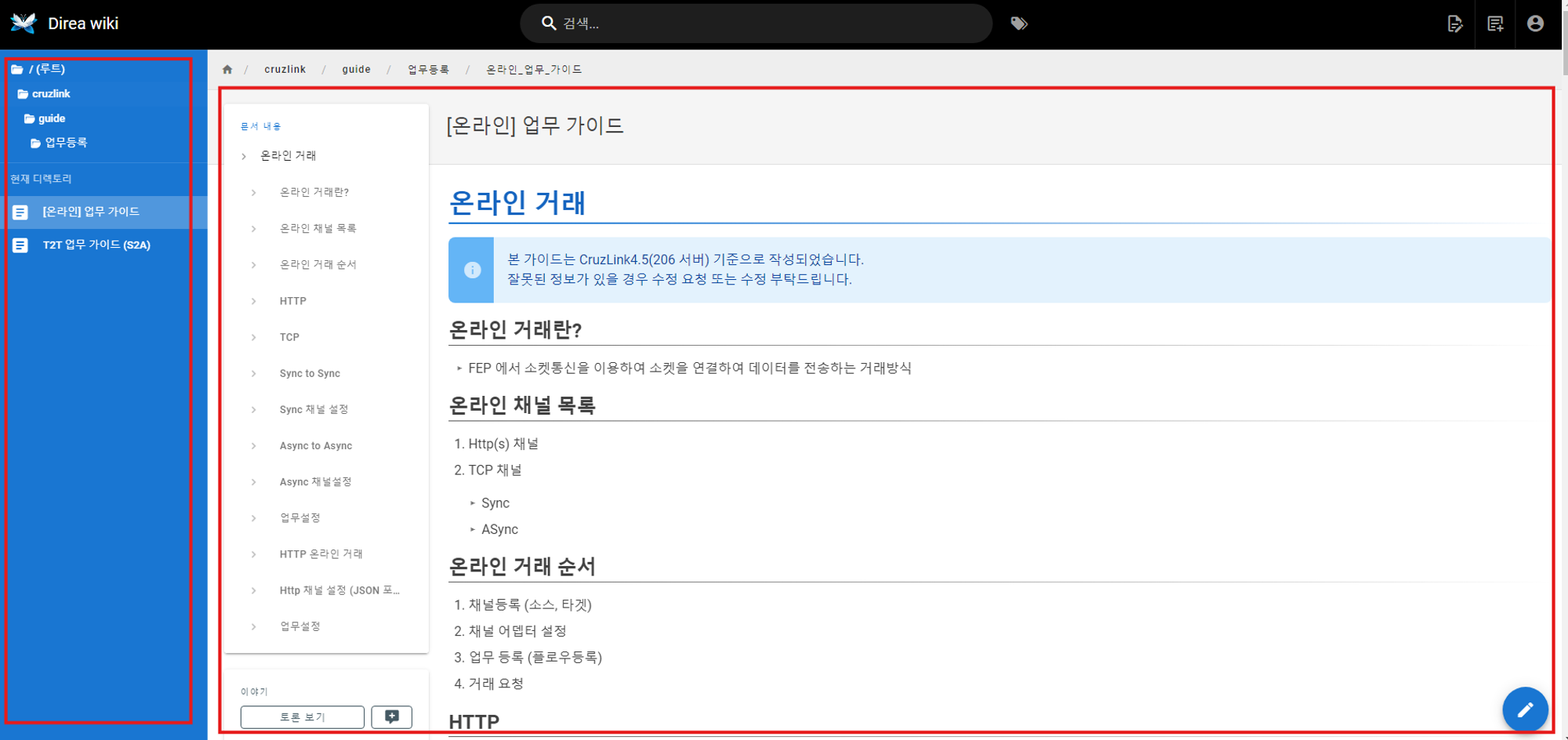
현재 wiki는 v-main__wrap의 본문 content와 v-navigation-drawer에 메뉴바로 div 클래스가 구성되어 있다.
메뉴바는 추후 동적 크롤링을 위해 사용될것이며, 우리는 v-main__wrap 태그의 내용에 관심이 있다.
먼저 로드된 페이지의 전체 HTML데이터를 크롤링하여 BeautifulSoup라이브러리를 활용해 데이터를 감싼다.
크롤링으로 긁어온 데이터를 살펴보면 문서의 제목으로는 headline 그리고 부연 설명으로 caption이 있으며 그 하위 본문 내용으로는h1, h2, h3 소제목 태그와 li, ul 등의 목록으로 정리한 설명, 첨부 파일(src가 포함된 태그)로 작성하고 있다.
해당 태그별로 soup.find(’태그’, class_=’클래스명’)으로 element값을 꺼내서
json데이터에 하나하나 append해준다.
data_structure = {
"main_title": main_title,
"main_description": main_description,
"sections": []
}
current_section = None
current_subsection = None
for element in soup.find_all(['h1', 'h2', 'h3', 'p', 'ul', 'ol', 'img']):
text = element.get_text(separator='\n', strip=True)
if element.name == 'h1':
if current_section:
data_structure['sections'].append(current_section)
current_section = {'title': text, 'content': [], 'subsections': []}
elif element.name == 'h2':
if current_section is None: # 상위제목이 없다면 생략
continue
if current_subsection: # 상위 제목이 있다면 그 하위 제목으로 append
current_section['subsections'].append(current_subsection)
current_subsection = {'title': text, 'content': []}
elif element.name == 'img':
src = "https://wiki.direa.synology.me/" + element['src'] # 이미지 파일의 경우 path추가
if current_subsection:
current_subsection['content'].append(src)
elif current_section:
current_section['content'].append(src)
else: # p, ul, ol 등의 내용
if current_subsection:
current_subsection['content'].append(text)
elif current_section:
current_section['content'].append(text)
if current_section:
if current_subsection: # 최근 상위 제목의 하위 contents로 append
current_section['subsections'].append(current_subsection)
data_structure['sections'].append(current_section) # 상위 제목이 없으면 section으로 바로 append
return data_structure해당 JSON parser로 아래와 같은 구조로 데이터를 정제 할 수 있다.
(문서제목에 대한 caption이 없기에 null값이다)

해당 데이터 파일을 JSON파일로 저장한다
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)