1. InnoDB 스토리지 엔진 아키텍처
- 스토리지 엔진 중 가장 많이 사용
- 레코드 기반의 잠금을 제공
- 높은 동시성 처리가 가능
- 안정적이며 성능이 뛰어남
프라이머리 키에 의한 클러스터링
- 모든 테이블이 프라이머리 키를 기준으로 클러스터링 되어 저장
- PK순으로 저장됨
- 빠른 레인지 스캔이 가능
- MyISAM은 지원하지 않음, 모두 물리적인 레코드 주소 값(ROWID)를 가짐
- 세컨더리 인덱스는 프라이머리 키의 값을 논리적인 주소로 저장
- PK가 쿼리의 실행 계획에 선택될 확률이 높음
외래 키 지원
- 부모 테이블과 자식 테이블 모두 해당 Column의 인덱스 생성이 필요
- 변경 시 부모 테이블이나 자식 테이블에 데이터가 있는지 확인 작업이 필요
- 잠금이 여러 테이블로 전파되고, 이로 인해 데드락이 발생할 가능성이 큼
- 수동 작업 시
foreign_key_checks를 OFF로 설정해 확인과정을 멈출수 있음
MVCC(Multi Version Concurrency Control)
- 일반적으로 레코드 레벨의 트랜잭션을 지원하느 DBMS가 제공하는 기능
- 잠금을 사용하지 않는 일관된 읽기를 제공
- InnoDB는 Undo log를 이용해 구현
- MV는 하나의 레코드에 여러 개의 버전이 동시에 관리되는 것을 의미
- INSERT 시 버퍼 풀 저장 - 디스크 저장
- UPDATE 시 변경 전 데이터 언두 로그 저장 - 버퍼풀 수정 - 디스크 수정
- 이후 SELECT 시 격리 수준에 따라 버퍼 풀 or 언두 로그의 데이터를 불러오게 됨
잠금 없는 일관된 읽기
- MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행
- 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고, 읽기 수행
- 언두 로그를 계속 유지해야하기 때문에 오랜 기간 활성 상태인 트랜잭션에서 서버가 느려질 수 있음
- 가능한 한 빨리 롤백이나 커밋이 필요
자동 데드락 감지
- 내부적으로 잠금이 교착 상태에 빠지지 않았는지 체크하기 위해 잠금 대기 목록을 그래프(Wait-for List)형태로 관리
- 데드락 감지 스레드가 주기적으로 그래프를 검사해 교착상태의 트랜잭션을 종료
- 언두 로그의 양을 기준으로 종료 순서 정함
- 적은 것 우선 롤백 (적을 수록 부하가 적음)
- 테이블 잠금으로 데드락 감지가 불확실해질 수 있음
-innodb_table_locks시스템 변수를 활성화하면 감지 가능 - 동시 처리 스레드가 많거나, 트랜잭션들의 잠금이 많아지면 데드락 감지 스레드가 느려짐
- 데드락 감지 스레드가 잠금 목록이 저장된 리스트에 새로운 잠금을 걸어 상태 변경을 막는데, 이 때문에 데드락 감지 스레드가 느려지면 서비스 쿼리를 처리 중인 스레드가 작업을 불가함.
innodb_deadlock_detect변수를 통해 적절히 비활성화해야함innodb_lock_wait_timeout변수로 데드락 상황에 일정 시간(초)이 지나면 요청 실패 후 에러 메시지를 반환하게 할 수 있음
자동화된 장애 복구
- InnoDB 데이터 파일은 기본적으로 MySQL서버가 시작될 때 항상 자동 복구 수행
- 이 때 복구될 수 없는 손상이 있으면 서버 종료
innodb_force_recovery변수로 설정
- 서버 기동 후 InnoDB 테이블이 인실되면
mysqldump를 이용해 데이터를 가능한 만큼 백업하고 DB와 테이블을 다시 생성하는 것이 좋음
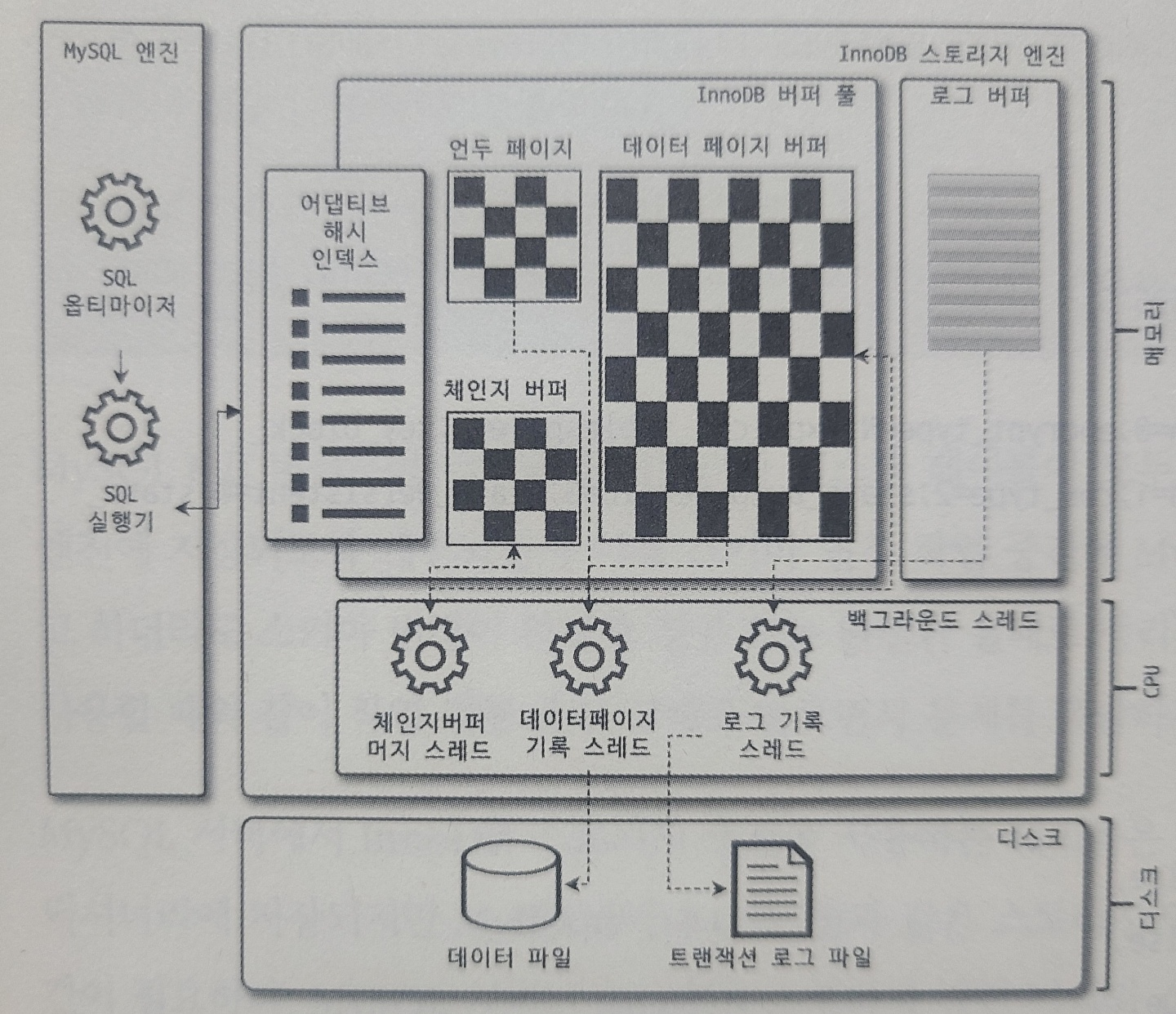
2. InnoDB 버퍼 풀
- InnoDB 스토리지 엔진에서 가장 핵심적인 부분
- 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간
- 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할
- 데이터 변경 시 데이터 파일의 이곳 저곳에 있는 레코드를 수정하기 때문에 이 작업을 줄여줌.
버퍼 풀의 크기 설정
- 대부분 메모리를 크게 필요로 하는 부분은 없음
- 클라이언트 세션이 테이블의 레코드를 읽고 쓸 때 사용하는 레코드 버퍼는 공간을 많이 쓸 수 있음
- 커넥션이 많을 때, 테이블이 많을 때
- 별도 설정 불가했지만, 이제 가능.
innodb_buffer_pool_size- 동적으로 조절, 128MB 단위
innodb_buffer_pool_instance로 버퍼 풓을 분리하여 할당 가능
버퍼 풀의 구조
- 버퍼 풀이라는 거대한 메모리 공간을
innodb_page_size변수 크기의 페이지 조각으로 쪼개어 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장 - 페이지 조각 관리를 위해 LRU 리스트, 플러시(Flush) 리스트, 프리(Free) 리스트라는 자료 구조를 관리한다.
- 프리 리스트 : 비어 있는 페이지 목록, 새롭게 데이터 페이지를 읽어와야 할 때 사용
- LRU 리스트 : LRU와 MRU를 결합한 형태로, 가장 오래 전/최근에 사용한 페이지의 리스트
- 플러시 리스트 : 디스크와 동기화되지 않은 데이터를 가진 데이터 페이지(더티 페이지)의ㅡ 변경 시점 기준의 페이지 목록 관리
- LRU 과정
- 필요한 레코드가 저장된 이터 페이지가 버퍼 풀에 있는지 검사
A. InnoDB 어댑티브 해시 인덱스를 이용해 페이지를 검색
B. 해당 테이블의 인덱스(B-Tree)를 이용해 버퍼 풀에서 페이지를 검색
C. 버퍼 풀에 이미 데이터 페이지가 있었다면 해당 페이지의 포인터를 MRU 방향으로 승급 - 디스크에서 필요한 데이터 페이지를 버퍼 풀에 적재하고, 적재된 페이지에 대한 포인터를 LRU 헤더 부분에 추가
- 버퍼 풀의 LRU 헤더 부분에 적재된 데이터 페이지가 실제로 읽히면 MRU 헤더 부분으로 이동(대량 읽기의 경우 버퍼 풀에 적재는 되지만, 실제 쿼리에 사용 안될 수 있고, MRU로 이동 안함)
- 버퍼 풀에 상주하는 데이터 페이지는 사용자 쿼리가 얼마나 최근에 접근했었는지에 따라 나이(Age)가 부여되며 사용이 안될 시 나이가 늘어나고, 사용 시 초기화됨. Age는 데이터 페이지가 가득 차거나, 너무 오래 상주 시 제거 기준.
- 필요한 데이터가 자주 접근됐다면 해당 페이지의 인덱스 키를 어댑티브 해시 인덱스에 추가
- 필요한 레코드가 저장된 이터 페이지가 버퍼 풀에 있는지 검사
- 플러시 리스트 to 리두 로그
- 한 번 데이터 변경이 가해진 데이터 페이지는 플러시 리스트에 관리
- 특정 시점에 디스크로 기록
- 데이터 변경 시 리두 로그 기록
- 버퍼 풀의 데이터 페이지에 반영
- 둘이 불일치 할 수 있어, 체크포인트를 발생시켜 디스크의 리두 로그와 데이터페이지의 상태를 동기화함.
- 체크포인트는 리두 로그의 어느 부분부터 복구를 실행할 지 판단 기준
버퍼 풀과 리두 로그
- 버퍼 풀의 기능인 캐시와 쓰기 버퍼링
- 메모리는 캐시의 성능을 높일 뿐 쓰기 버퍼링을 위해 리두 로그와의 관계를 파악해야함
- 리두 로그는 하나의 고정 크기의 파일을 순환 형태로 연결해서 사용
- 어느 순간 사용중인 공간을 덮어 쓸 수 있기 때문에 구분이 필요
- 재사용 불가능한 공간을 활성 리두 로그라고 부름
- 하나의 파일을 순환하지만 로그 포지션은 계속 증가
- LSN(LogSequence Number)
- 데이터를 디스크에 기록 시 가장 최근 체크포인터 시점의 LSN이 활성 리두 로그 공간의 시작점
- 마지막 로그 엔트리의 LSN 과의 차이가 체크포인트 에이지
- 활성 리두 공간의 크기
- 체크포인트의 LSN보다 작은 리두 로그 엔트리와 관련된 더티 페이지들을 디스크에 동기화
버퍼 풀 플러시
- 버퍼 풀에 더티 페이지가 쌓이다가 한꺼번에 플러시 되면 대량의 쓰기 작업에 처리가 느려지고, 부드럽지 않다.
- 8.0 버전에 와서 두가지 기능을 제공하며 이를 보완했다.
- 플러시 리스트 플러시
- LRU 리스트 플러시
- 플러시 리스트 플러시
- 리두 로그 공간의 재활용을 위해 공간을 비우려면 관련 더티 페이지를 먼저 동기화 시켜야 한다.
- 더티 페이지를 디스크와 동기화하는 클리너 스레드를 이용
innodb_page_cleaners로 개수 조절innodb_buffer_pool_instances와 동일한 값으로 해 하나의 클리너 스레드가 하나의 버퍼 풀 인스턴스를 처리하도록 설정하면 좋음
- 더티 페이지와 클린 페이지의 비율을 정함
innodb_max_dirty_pages_pct- 기본값이 좋음
- 많은 더티 페이지를 가지면 버퍼링이 효율은 좋아지나 한번에 디스크 쓰기를 하면 디스크 쓰기 폭발이 발생할 수 있음
- 디스크가 읽고 쓸 수 있는 정도 설정
innodb_io_capacity_max
- 어댑티브 플러시
innodb_adaptive_flushing- 데이터베이스가 적절한 알고리즘으로 처리
- LRU 리스트 플러시
- LRU 확인으로 사용 빈도가 낮은 페이지들 flush
innodb_lru_scan_depth만큼 스캔- 더티 페이지는 동기화, 클린 페이지를 프리 페이지로 변환
- LRU 확인으로 사용 빈도가 낮은 페이지들 flush
버퍼 풀 상태 백업 및 복구
- 버퍼 풀에 캐시를 통해 쿼리들의 속도를 향상시킴
- 서버 재시작 시 버퍼 풀이 날라가 속도가 느려짐
- 기존에는 워밍업이란 작업으로 서비스 전 임의로 버퍼 풀에 캐시해줌
- 버퍼풀 백업 및 복구를 통해 해결
- 명령어
SET GLOBAL innodb_buffer_pool_[dumb|load]_now=ON
Double Write Buffer
- 리두 로그에는 변경 사항에 대해 전체 레코드가 아닌 변경된 부분만 저장하여 더티 페이지 플러시 시 일부만 기록되는 경우가 있다.
- 이를 해결하기 위해 시스템 테이블스페이스에 Double Write Buffer를 두어 기록 전 변경 사항을 따로 저장하고, 시스템 오류 발생 시 복구용도로만 사용한다.
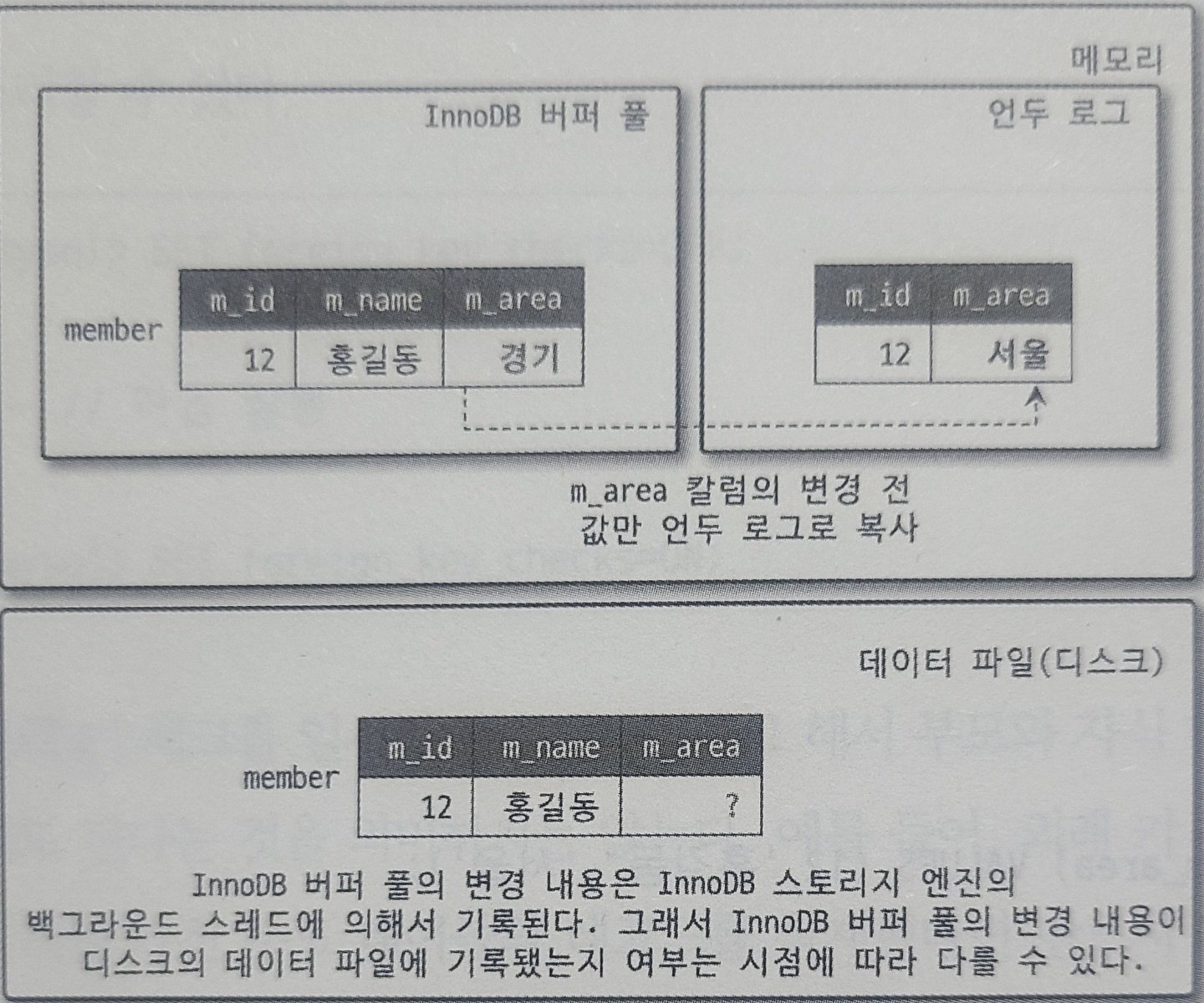
3. 언두 로그
- 트랜잭션과 격리 수준을 보장하기 위해 DML 작업 시 이전 버전을 백업하는 용도
- 트랜잭션 보장
- 트랜잭션이 롤백되면 트랜잭션 도중 변경된 데이터를 변경 전 데이터로 복구해야 하는데, 이때 언두 로그의 백업해둔 데이터로 복구
- 격리수준 보장
- 특정 커넥션에서 데이터를 변경하는 도중에 다른 커넥션에서 데이터를 조회하면 트랜잭션 격리 수준에 맞게 변경중인 레코드를 읽지 않고, 언두 로그에 백업해둔 데이터를 읽어와 반환하기도 함
언두 로그 문제점(이전 버전)
- 대용량 처리
- 100억건의 삭제 작업이 있으면 모두 언두 로그에 저장해둬야 하므로 용량이 매우 커짐.
- 트랜잭션 지연 시
- A, B, C 트랜잭션이 연속 실행될 때, B, C는 끝났지만 A가 활성상태로 유지중이라면 B, C의 언두 로그도 저장해놔야함.
- 이 문제들과 함께 SELECT 발생 시 관련 언두 로그를 스캔하면서 문제가 커짐
- 8.0 버전에서는 주기적으로 언두 로그 공간을 삭제함
언두 테이블스페이스
- 이전 버전들에서는 언두 로그를 시스템 테이블스페이스에 저장했지만, 8.0버전부터는 외부의 독립적인 파일로 저장.
- 하나의 테이블스페이스에 1~128개의 롤백 세그먼트를 가지고, 각 롤백 세그먼트는 여러개의 언두 슬롯을 가진다.
- 언두 슬롯의 최대 개수: 페이지의 크기 / 16Byte
- 최대 동시 트랜잭션 수 = InnoDB 페이지 크기 / 16 * 콜백 세그맨트 수 * 테이블 스페이스 수
- 테이블스페이스 공간이 과도하다면 Truncate작업을 통해 공간을 반환해준다.
- 자동 모드 : 퍼지 스레드가 디스크에 동기화 된 언두 로그를 삭제하고 공간을 반환해준다.
- 수동 모드 : 테이블 스페이스를
INACTIVE상태로 바꿔준다.
체인지 버퍼
- 버퍼 풀에 없는 데이터 수정 발생 시, 디스크에 바로 수정이 되는게 아니라 체인지 버퍼라는 임시 공간을 할당해 저장하고 작업 수행.
- 인덱스에 대한 수정은 중복 체크를 위해 체인지 버퍼를 사용 못함.
- 나머지는 체인지 버퍼 머지 스레드에 의해 레코드를 병합하고 관리.
- 8.0 버전 이상에서는 버퍼링을 개선하여 가능해짐
리두 로그
리두 로그는 트랜잭션의 4가지 요소인 ACID 중에서 Durable에 해당하는 영속성에 가장 밀접하게 연관되어 있다. MySQL 서버가 비정상 종료 시 데이터 파일에 기록되지 못한 데이터를 잃지 않게 해주는 안전장치다.
ACID
Atomicity(원자성): 작업이 모두 Commit되거나 모두 Rollback되는 특성이다.Consistency(일관성): 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것이다. 숫자컬럼에 문자열값을 저장이 안되도록 보장해줍니다.
Isolation(고립성): 트랜잭션을 수행 시 다른 트랜잭션이 연산 작업에 끼어들지 못하는 것이다. 트랜잭션 중의 중간 데이터 상태를 어떤 트랜잭션도 볼 수 없다.
Durability(지속성): 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다.
데이터베이스 서버는 데이터 변경 내용을 로그로 먼저 기록한다. 데이터 파일 쓰기는 디스크의 랜덤 액세스가 필요하며 읽기에 비해 큰 비용이 발생한다. 이에 비용이 낮은 리두 로그를 이용해 저장하고, 문제 발생 시 리두 로그를 이용해 복구한다.
리두 로그를 버퍼링할 수 있는 로그 버퍼 자료 구조도 가지고 있다.
Durability가 지키져지 않는 경우
- 커밋됐지만, 데이터 파일에 기록되지 않는 경우
- 리두 로그를 데이터 파일에 복사
- 롤백됐지만, 데이터 파일에 이미 기록된 경우
- 리두 로그로 상태 파악 후, 언두 로그를 데이터 파일에 복사
리두 로그 디스크 동기화
innodb_flush_log_at_trx_commit변수 설정0: 1초에 한 번씩 리두 로그를 디스크로 기록(write)하고 동기화(sync)를 실행, 비정상 종료 시 최대 1초 동안의 트랜잭션은 커밋됐다고 해도 해당 트랜잭션에서 변경한 데이터는 사라질 수 있음1: 매번 트랜잭션이 커밋될 때마다 디스크로 기록 및 동기화 수행. 커밋되면 해당 트랜잭션에서 변경한 데이터는 사라짐2: 매번 트랜잭션이 커밋될 때마다 디스크로 기록은 되지만, 실질적 동기화는 1초에 한 번씩 실행. 커밋되면 운영체제의 메모리 버퍼로 기록되는 것이 보장. 서버의 비정상 종료에도 트랜잭션의 데이터는 사라지지 않음. 서버와 운영체제가 모두 비정상 종료 시 1초 동안의 트랜잭션 데이터는 사라질 수 있음.
어댑티브 해시 인덱스
일반적인 인덱스는 사용자가 생성해둔 B-Tree 인덱스를 의미한다. 어댑티브 해시 인덱스는 사용자가 수동으로 생성하는 인덱스가 아니라 InnoDB 스토리지 엔진에서 사용자가 자주 요청하는 데이터에 대해 자동으로 생성하는 인덱스이다.
B-Tree는 일반적으로 검색이 매우 빠르다 하지만, 스레드가 매우 많다면 이 역시 오래 걸린다. 이를 위해 자주 읽히는 데이터 페이지의 키 값을 이용해 해시 인덱스를 만들고 필요할 때 빠르게 레코드가 저장된 페이지를 찾을 수 있다.
- 인덱스는
인덱스 키 값, 데이터 페이지 주소쌍으로 되어있음 - 인덱스 키 값은
B-Tree 인덱스의 고유 번호(Id), B-Tree 인덱스의 실제 키 값의 조합 - 페이지 주소는 버퍼 풀에 로딩된 페이지 주소이다.
어댑티브 해시 인덱스가 성능 향상에 도움이 크게 되는 경우
- 디스크의 데이터가 InnoDB 버퍼 풀 크기와 비슷한 경우(읽기가 적은 경우)
- 동등 조건 검색(동등 비교와 IN 연산자)이 많은 경우
- 쿼리가 데이터 중에서 일부 데이터에만 집중되는 경우
어댑티브 해시 인덱스가 성능 향상에 도움이 크게 안되는 경우
- 디스크 읽기가 많은 경우
- 특정 패턴의 쿼리가 많은 경우(JOIN이나 LIKE 패턴 검색)
- 매우 큰 데이터를가진 테이블의 레코드를 폭넓게 읽는 경우
