이 글은 Lil'Log의 Are Deep Neural Networks Dramatically Overfitted? 글을 읽고 정리한 글입니다.
주제 | 모델의 일반화와 과적합
오컴의 면도날
오컴의 면도날 → 가장 간단한 모델이 가장 일반화에 유리한 모델이다.
오컴의 면도날의 적용: 가장 “간단한” 모델은 어떻게 표현되는가?
MDL(Minimum Description Length) 원칙
→ 모델 설명의 길이와 데이터 설명의 길이가 최소
MDL의 기본 아이디어는 학습을 데이터 압축으로 보는 것이다: 데이터를 압축하여 unseen 데이터에도 잘 적용될 수 있는 데이터의 패턴과 규칙성을 파악하는 것이 학습이라고 본다.

- H는, 데이터셋 D를 설명할수 있는 모델을 말한다.
MDL 원칙에서는 모델 설명의 길이와 데이터 설명의 길이가 최소가 되는 모델이 best 모델이라고 본다. 즉, 인코딩된 데이터와 모델 그 자체를 포함하는 가장 작은 모델이 가장 좋은 모델이라고 본다.
Kolmogorov 복잡성
→ 바이너리 컴퓨터 프로그램의 길이가 최소
Kolmogorov 복잡도는 object의 알고리즘 복잡도를 정의하기 위한 현대 컴퓨터 개념에 기반하여 → object의 복잡도를 object를 설명하는 가장 짧은 바이너리 컴퓨터 프로그램의 길이로 정의한다.

- : 범용 컴퓨터(모든 현대 컴퓨터)
- : 어떤 프로그램
- : 프로그램 를 컴퓨터가 처리한 출력
- : 프로그램의 설명적 길이
- : Kolmogorov 복잡도
확률 변수의 예상 Kolmogorov 복잡도는 섀넌 엔트로피와 거의 같다.
Solomonoff의 추론 이론
→ 학습 데이터를 생성하는 프로그램 길이가 최소(Kolmogorov 복잡성 기반)
Kolmogorov 복잡성과의 차이점은 Kolmogorov 복잡성은 모든 프로그램에 해당되는 개념인 반면, Solomonoff 추론 이론은 이 프로그램이 데이터 기반의 프로그램에 적용된 개념이라는 것인듯 하다. 특히, 베이지안 모델에 적용되는 개념인듯하다.
1️⃣ 딥러닝은 높은 표현력을 얻으려면 많은 매개변수가 불가피하게 필요하다. 2️⃣ 그러나 많은 수의 파라미터는 과적합을 일으킨다.
-
1️⃣ Universal Approximation Theorem → 특정 조건을 만족하는 딥러닝 네트워크는 모든 연속 함수를 근사할 수 있다.
-
Linear output layer+hidden layer(≥1)+activation func으로 구성된 feed-forward network는 모든 연속 함수를 근사할 수 있다. -
단일 레이어의 feed-forward network도 모든 함수를 표현하기에 충분하기만 폭이 지수적으로 커야 한다.
-
레이어 수를 늘이면 사용하는 가중치 개수를 줄여도 충분한 성능이 보장된다.
그러나 이 이론은 모델을 적절하게 학습하거나 일반화 가능 여부를 보장하지 않는다. (그냥 모델의 표현력만 언급되어있다.)
이 이론을 통해 모든 함수를 표현하는 모델을 찾을 수 있지만, 네트워크의 크기(파라미터 수)가 극적으로 커질 수 있다.
언어 모델에서 파라미터 수가 증가할수록 성능이 좋아진다는 이론은 → scaling law
-
사람의 경우에도 가중치(뉴런, 시냅스)가 많은 사람일수록 똑똑할까?
-
그런데 vision의 경우 반드시 똑똑해야 인지를 잘하는 것은 아니라고 본다. 언어영역이면 몰라도. 그렇다면 vision의 경우 반드시 파라미터 수가 많아야 하는 것은 아닐지도 모른다.
-
-
2️⃣ 딥러닝 모델은 무작위 노이즈까지 완벽하게 학습(학습 손실=0)할 수 있다.
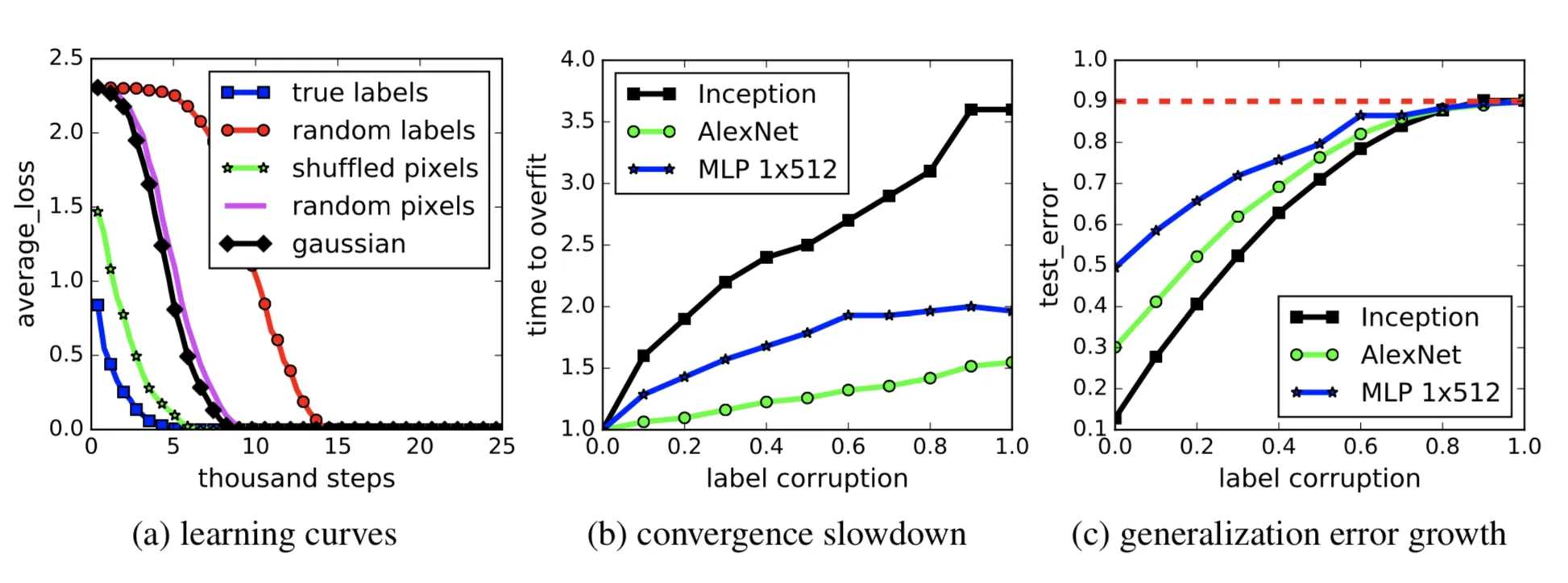
a) random label, random pixel도 학습 결과 loss가 0이 되었다.
무작위 노이즈 → 완전 랜덤한 값
즉, 딥러닝 모델은 어떤 값이든 상관없이 완벽하게 학습해낼 수 있다. 그러나 완전 랜덤한 값은 패턴이 없는 값이고, 우리가 실제로 학습해야하는 값은 패턴이 있는 값이다. 그리고 모델을 학습하는 것의 목적이 데이터의 패턴을 찾아내는 것인데 패턴이 없는 값을 완벽하게 학습해낸 다는 것은, 데이터의 중요한 패턴이 아닌, 필요없는 부분들까지도 학습해버린다는 것이다.예를 들면 자전거 이미지를 학습한다고 하면 두개의 바퀴가 크게 달려있고 그 위에 안장이 있고 바퀴와 안장을 연결하는 프레임이 있는 규칙성을 학습해야할 것이다. 그런데 자전거 바구니에 올려져있는 가방까지 자전거로 학습을 해버리면 가방이 바구니에 올려져있지 않은 unseen 데이터는 자전거로 인식을 하지 못하게 된다.
이렇게 noise까지 완벽하게 학습을 해버리는 것이 과적합으로 이어지게 된다.
그러나 종종 과적합 딥러닝 모델이 unseen 데이터에 대해 나쁘지 않은 성능을 가지는 경우가 있다.
double descent
파라미터 수가 증가할수록 test loss가 증가하다가 파라미터 수가 어느정도 이상으로 증가하게 되면 test loss가 다시 줄어든다.
기존의 bias-variance risk 곡선
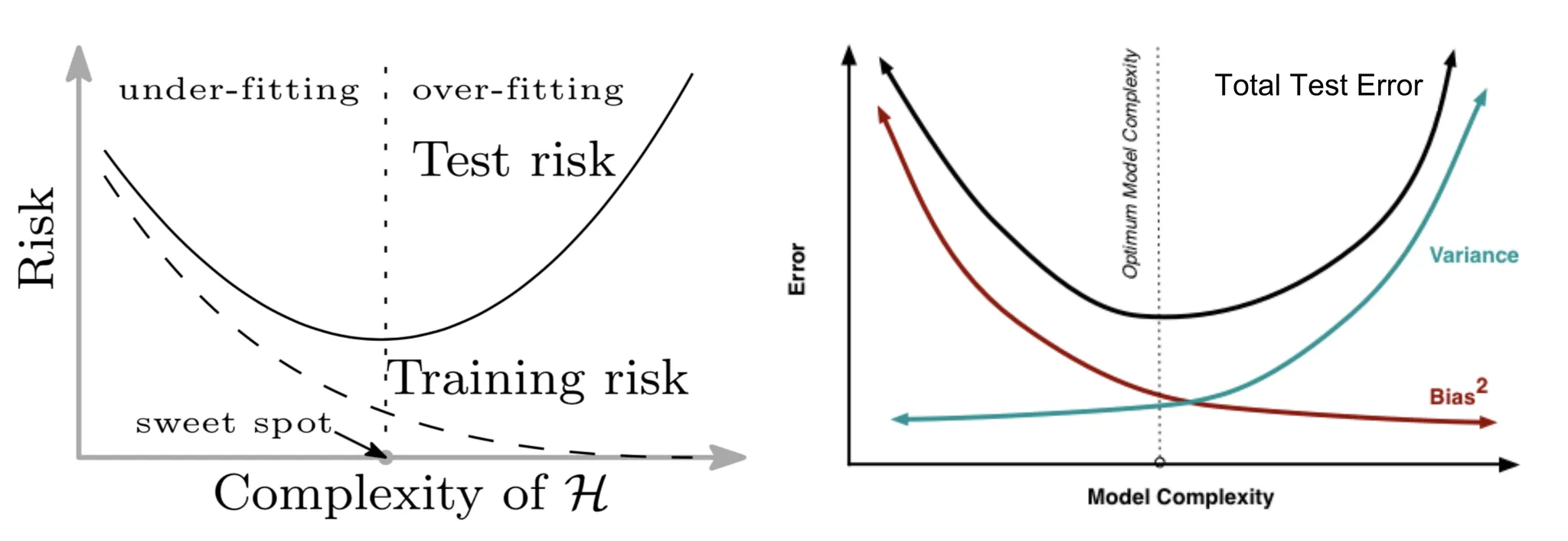
그러나 네트워크 매개변수의 수가 충분히 커지면 곡선이 다른 체제로 들어간다는 것을 발견하였다.
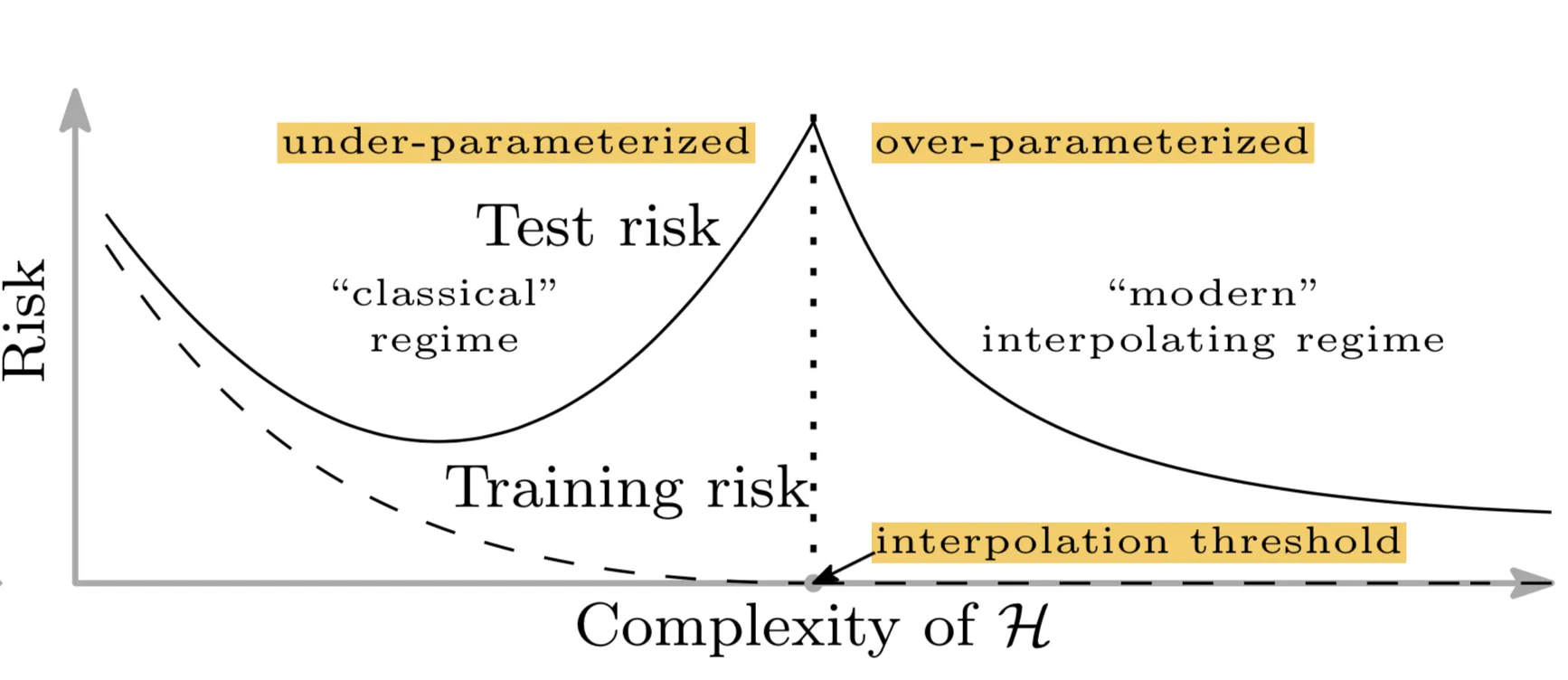
해당 논문은 그 이유를
- 매개변수의 수는 알려지지 않은 샘플을 예측하는데 사용되는 학습 알고리즘의 가정들로 정의된 inductive bias의 좋은 측정기준이 되지 못한다.
- 더 큰 모델을 사용하면 더 큰 function class를 발견할수도 있고 더 작은 norm을 가지는 보간함수를 찾을 수 있고 그러므로 더 간단(일반화)해질 수 있다.
이것 말고도 일반화에 대해 알려진 이론들을 깨는 연구 결과들이 있다.
- 명시적 정규화(데이터 증가, 가중치 감소 및 드롭아웃)가 일반화 오류를 줄이는데 큰 도움이 되지 않는다.
어쨌든 돌아와서, 많은 매개변수 수는 반드시 과적합을 불러오지는 않기 때문에 매개변수 계산이 DNN의 복잡성을 표현하는 좋은(적합한) 방법이 아님을 알게 되었다.
이에 따라, 모델의 복잡성을 정량화하는 많은 방법이 제안되었다: 모델 자유도 수, 사전 코드, 내재적 차원
그렇다면 왜 파라미터 수가 증가해도 과적합에 빠지지 않는 것일까?
실험 결과 많은 모델 혹은 문제가 매개변수 수보다 훨씬 작은 내재적 차원을 가지고 있더라.
매개변수 공간이 매우 높은 차원성을 가지고 있기 때문에 효율적으로 학습하기 위해 모든 차원을 활용할 필요가 없다. objective landscape의 한 slice만 여행하고도 좋은 해(solution)을 학습할 수 있다면 모델의 복잡성은 매개변수 계산을 통해 보이는 것보다 낮을 가능성이 높다.
objective landscape(manifold)가 매끄러울수록 예측 가능한 기울기를 얻을 수 있다. 이는 더 큰 학습률을 사용할 수 있어 학습 속도가 빨라질 수 있다(학습을 위한 연산량이 줄어들 수 있다). 이 논문은 배치 정규화는 landscape를 매끄럽게 만들기 때문에 배치 정규화가 학습을 안정화하는데 도움이 되었다고 분석한다.
- 모델의 복잡도은 모델의 크기가 아니라 학습하여 추론을 위한 모델을 얻어내기 위해 필요한 연산량을 의미하는 것 같다. 즉, 연산 복잡도를 말하는 듯하다. 원래 파라미터 수가 많아지면 식 자체가 길어지니까 연산량이 당연히 늘어나게 되는데, 모델 학습의 차원에서 보면 학습을 반복하는 횟수, 수렴 속도가 학습 과정의 연산량을 결정짓게 되기 때문에 내재적 차원에 이런 측면에 초점을 두고 있는 듯하다.
레이어 종류, 깊이 별로 다른 견고성을 가진다. 재초기화에 견고한 계층이 어떤 크기의 모델이든 존재하기 때문에 실제 모델이 가지는 파라미터 수보다 작은 복잡성을 가진다. → 이 관점에서 내재적 차원에서 내린 결론과 같은 결론에 도달한다.
모델의 각 레이어는 다른 견고성(robustness)을 가지고 있다. 더 변화에 민감한 레이어가 있다.(그 외의 레이어는 변화에 둔감)
특정 레이어를 재초기화하거나 재무작위화를 하여 성능을 확인해봄을써 레이어의 견고성을 확인한다.
- re-initialization: 특정 레이어의 매개변수를 초깃값으로 재설정
- re-randomization: 특정 레이어의 매개변수를 무작위로 다시 샘플링
- 해당 레이어 매개변수를 재초기화/재무작위화했을때 성능이 크게 저하되면 변화에 민감하다(
critical layer)고 볼 수 있고 성능에 큰 차이가 없으면 견고하다(robust layer)고 볼 수 있다.- 근데 재초기화와 재무작위화에 견고한게 왜 중요한 레이어가 되는가?
실험 결과
[VGGNet을 대상으로 실험]
- Re-randomization
어떤 계층이든 re-randomization을 적용하면 prediction이 바로 무작위 추측으로 떨어지기 때문에 모델 성능이 완전히 파괴된다. - Re-initialization
첫번째 혹은 초기 계층만 성능이 크게 변한다.
그 뒤 계층에 re-initializtion을 적용했을때 성능에 큰 변화가 없었다.
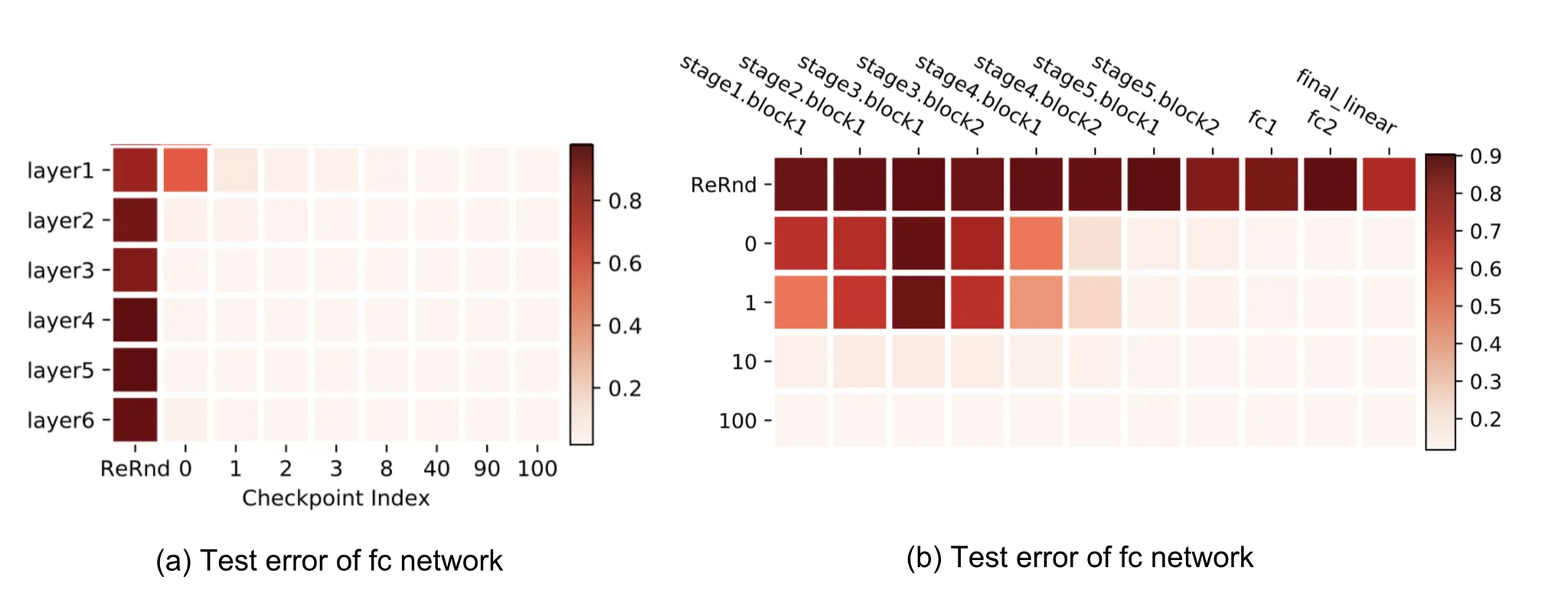
[ResNet을 대상으로 실험]
-
shorcut을 통해 민감한 layer를 네트워크 전체에 분산하는 효과를 얻었다.
-
residual block에 의해 re-randomization에 강건해질 수 있다.
-
residual block의 각 첫번째 layer만이 re-initialization/re-randomization에 민감하였다.
➡️ VGGNet과 비교하면 re-initialization에 민감한 layer의 수는 약간 늘고(초기 layer → 각 residual block의 첫번째 layer), re-randomization에 민감한 layer 수는 줄었다(모든 layer → 각 residual block의 첫번째 layer)고 볼 수 있다.
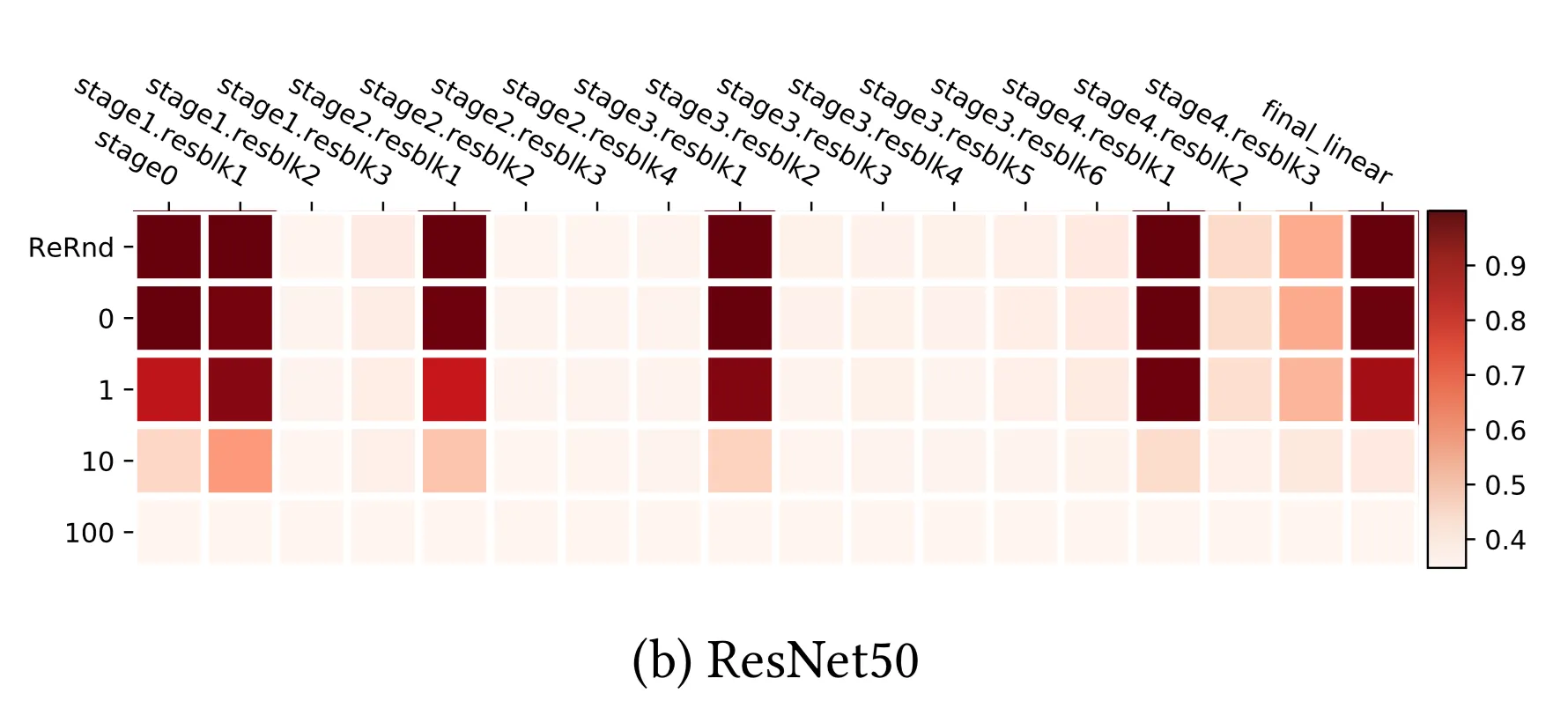
따라서 논문에서는 재초기화 후 DNN의 상위(top, last) 계층 중 다수가 모델 성능에 중요치 않다(non-critical)는 사실을 바탕으로 다음과 같은 결론을 내린다: stochastic gradient로 학습된 대용량의 DNN은 critical layer의 수를 자체적으로 제한하기 때문에 복잡도가 낮다.
➡️ 변화에 민감한 critical layer들이 많은 연산량을 필요로 할 것이다. 그러므로 critical layer가 적을수록 복잡도가 낮다고 볼 수 있을 것이다. 그런데 DNN의 경우 layer의 수가 몇개 던 간에, 초기 layer가 critical하고, 나머지 뒷쪽 layer는 robust하기 때문에 복잡도는 더 낮을 수밖에 없다(모든 layer가 ciritical한 것이 아니기 때문에).
-
근데 왜 stochastic gradient로 학습한 모델로 범위를 제한했나?
따라서 재초기화를 매개변수의 실질적인 수(effective number of parameters)를 줄이는 방법으로 간주할 수 있으며 실험 결과는 내재적 차원에서 입증된 것과 동일하다. -
여기서 실질적인 수를 줄일 수 있다는 것이 학습 과정을 단축시킬 수 있다는 뜻이 맞으려나? non critical한 layer에 대해서는 추가적으로 학습을 거의 하지 않는다는 뜻으로?
복권 티켓 가설
네트워크 매개변수의 하위 집합 만이 모델 성능에 영향을 미치기 때문에 많은 수의 매개변수를 가져도 과적합이 되지 않는다.
→ 이 하위 집합을 “winning ticket(당첨 티켓)”이라고 한다.
초기화를 운좋게 잘하면 추가 학습을 많이 하지 않아도 되는(금방 높은 성능에 도달하게 되는), 복권에 당첨된 것으로 비유하여 지금 가지고 있는 복권이 당첨 복권인지 아닌지를 식별하는 방법을 제안하는 것 같다.

해당 방법론은 논문을 읽고 더 정리할 예정.
