이 글은 Lil'Log의 Self-Supervised Representation Learning 글을 읽고 정리한 글입니다.
Introduction
unlabeled data(라벨링 되어있지 않은 데이터)가 labeled data(라벨링 되어있는 데이터)보다 훨씬 많다. 최근에는 데이터를 대량으로 쉽게 수집할 수 있는데, 이 데이터는 모두 unlabeled data이다. 데이터에 라벨을 다는 것은 사람의 수작업이 필요하기 때문에 비용이 높고 시간도 오래걸린다. 그래서 unlabeled data를 그대로 이용해서 지도학습처럼 모델을 학습하는 방법이 연구되었다. 이 연구를 self-supervised learning라고 한다.
self-supervised learning의 목적은 모델이 원래의 task에 좋은 성능을 내기 위해 모델의 representation 능력을 높이는 것에 있다. self-supervised learning에서 unlabeled data의 의무는 데이터에 대한 모델의 representation 능력을 높이는 데 있다. 이 모델의 representation 능력을 높이기 위해 unlabeled data를 사용하더라도 학습을 위해서는 loss, 즉 문제(task)가 필요하다. 이 문제(task)를 pretext(뜻: 구실, 핑계) task 혹은 self-supervised task라고한다. 그리고 이 representation 능력을 이용하여 해결하려는 원래의 큰 task를 downstream(뜻: 후속의) task라고 한다.
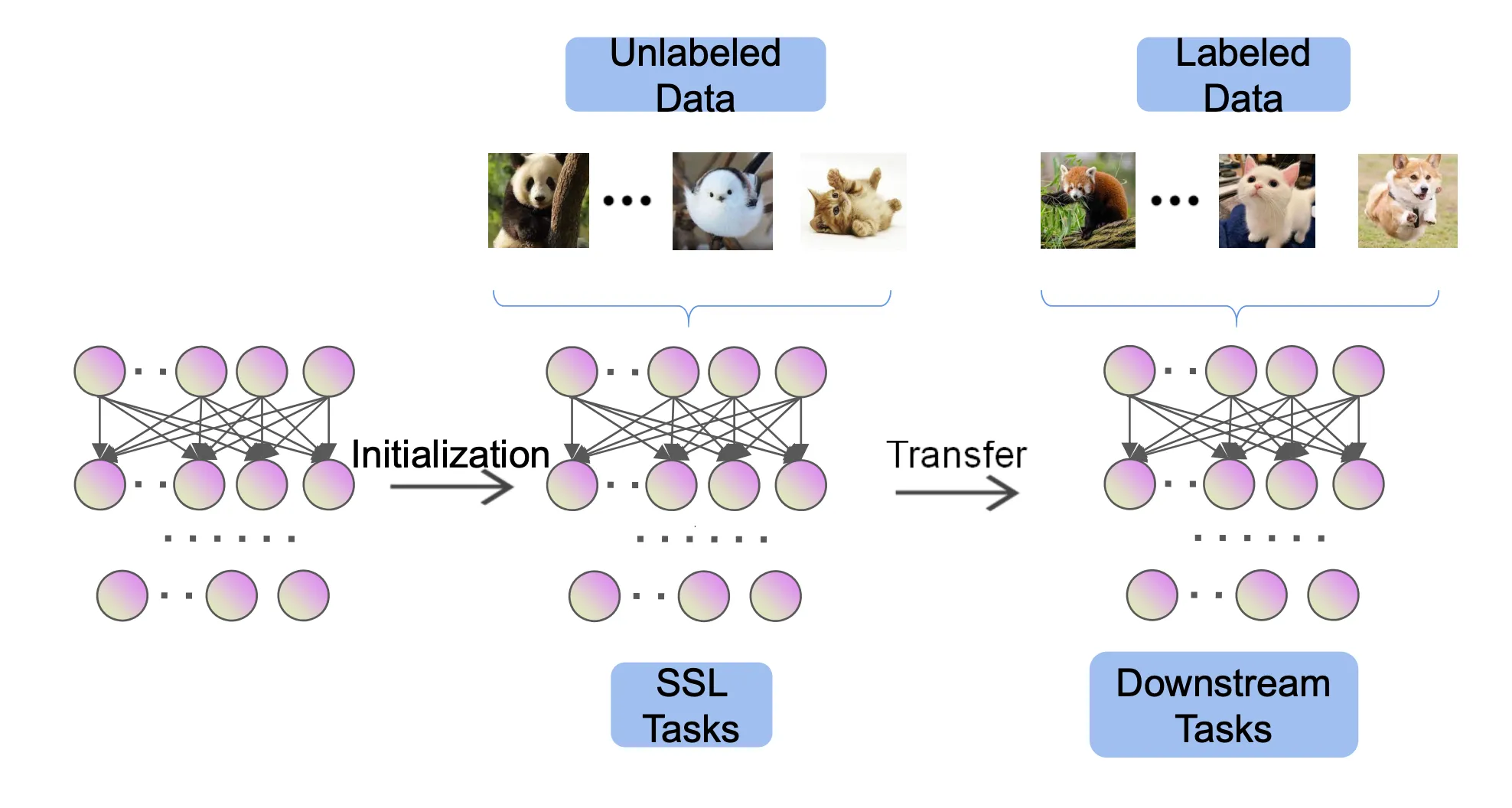
pretext task에 대해 모델을 학습할 때 지도 학습 방법으로 모델을 학습한다. 이때 사용하는 데이터셋이 unlabeled data인데 어떻게 지도 학습을 할까? unlabeled data에 의도적인 변형을 하고 이 변형 여부 및 정도를 정답으로 사용하여 맞추는 형식으로 pretext task에 대해 학습한다. 다양한 pretext task가 있을 수 있는데, 아무 task가 pretext task로 사용될 수 있는 것은 아니다.
어떤 representation이 labeled data에 대한 task에 도움이 될 수 있을까? 비전 관점에서 보자면, 이미지 내의 object를 잘 인식하는 representation일 것이다. 이미지가 변형되더라도 이미지 내의 object를 잘 인식할 수 있는 feature map을 뽑을 수 있는 가중치일 것이다. 그렇기 때문에 이런 representation을 학습시킬 수 있는 task가 pretext task로 사용될 수 있다. 물론 모든 task가 pretext task로 사용될수는 있겠지만, downstream task의 모델의 가중치로 사용하여 미세조정을 한 결과가 좋지 못하다면 pretext task로 사용할 필요가 없는 식일 것이다. 이는 어떤 작업을 위한 학습이든, 실제 작업을 위해 고품질의 latent variable을 학습할 것의 예상을 근거로 한다.
언어 모델에서 self-supervised learning을 자주 사용한다. 대표적으로 BERT의 경우를 볼 수 있다.
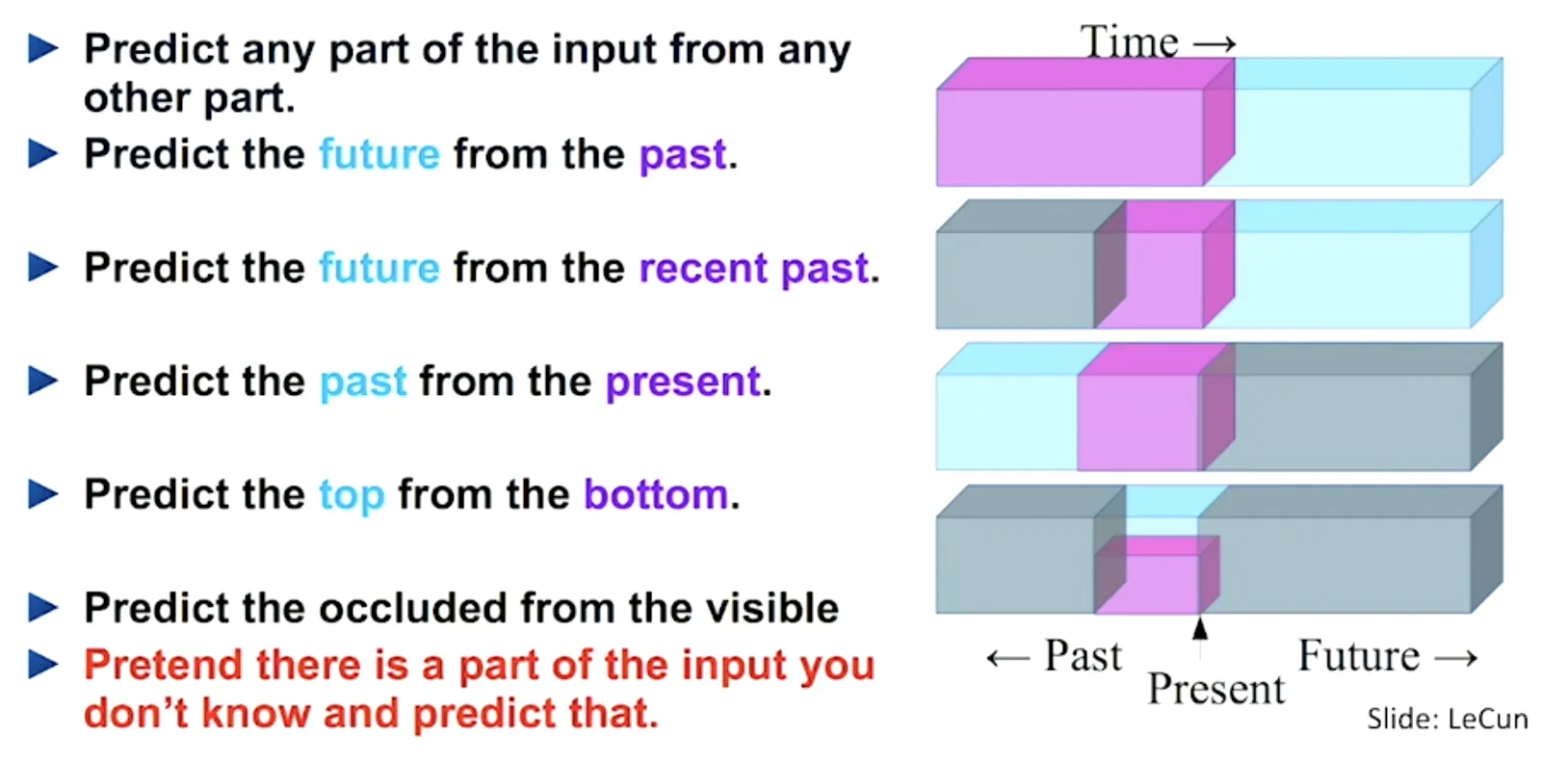
언어 모델의 디폴트 task는 과거 sequence가 주어지면 그 다음 단어를 예측하는 것이다. BERT에서는 두개의 보조 task를 추가한다: 자가 생성된 라벨을 이용하여 과거의 최근 것으로부터 그 다음을 예측하고 현재의 것으로부터 과거를 예측한다.
다시 정리하자면 self-supervised learning은 좋은 표현을 얻는게 목적이기 때문에 pretext task에 대한 최종 수행 능력에는 관심이 없다. 그보단 학습된 중간의 표현에 관심이 있다.
대체로 모든 생성 모델은 self-supervised 모델로 간주할 수 있지만 목표가 다르다. 생성 모델의 경우 다양하고 사실적인 이미지를 생성하는 것이 목표인 반면, self-supervised learning 모델은 일반적으로 많은 작업에 도움이 되는 함수를 생성하는 것이 목표가 된다.
Image-based
unlabeled image로 하나 혹은 여러 pretext에 모델을 학습하고 이 모델이 중간 feature layer를 사용하여 ImageNet 분류에 대한 다항 로지스틱 회귀 분류기를 제공한다. 최종 분류 정확도는 학습된 표현이 얼마나 좋은지를 정량화한다.
Distortion
이미지를 조금 왜곡해도(변형시켜도) 원래의 semantic한 의미나 기하학적인 형식이 크게 변하지 않을것이라는 가정에서 고안되었다. 따라서 학습된 feature는 왜곡되어도 동일할 것으로 볼 것이다. 다양한 왜곡으로 pretext task를 구성할 수 있다.
Exemplar-CNN
동일한 이미지에서 패치를 잘라서 랜덤으로 변형(transformation)을 주고 변형을 준 패치들로부터 동일한 이미지를 찾게 한다. 즉, 어떤 이미지에 속하는지 분류하도록한다—동일한 이미지가 클래스가 되어 클래스 분류를 한다고 볼 수 있다.

회전
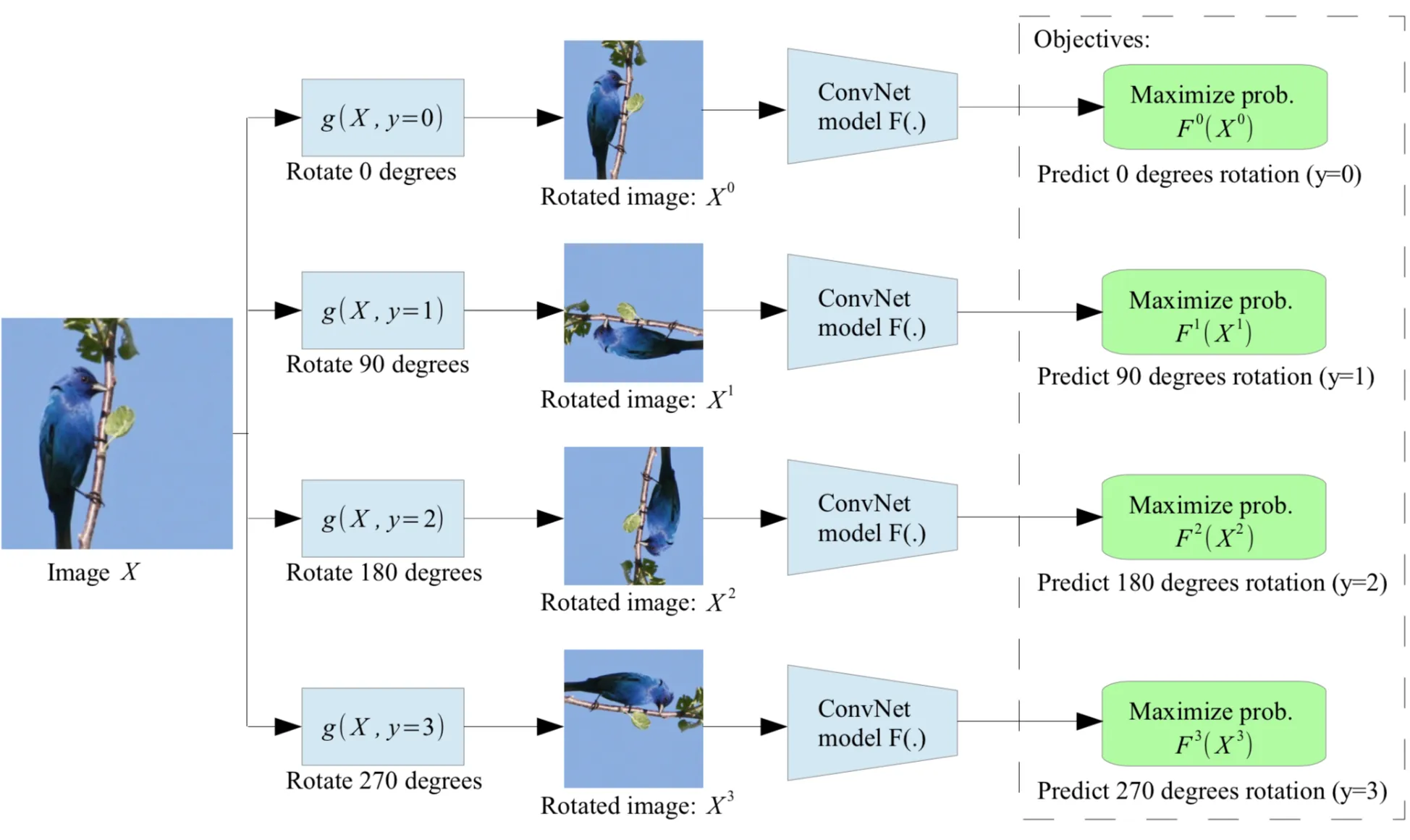
[] 회전을 시켜주고 회전을 얼마나 시킨 이미지인지 맞춰보게 한다. (4-class classification)
➡️ 얼마나 회전된 그림인지 파악하기 위해서는 (동물 이미지를 예로 들면) 눈, 코, 입, 몸통의 상대적인 위치가 중요하므로 이 task를 위한 표현은 유용할 것이다! 즉, 이 task를 통해 학습된 모델이 객체의 semantic한 개념을 학습할 수 있을 것으로 본다.
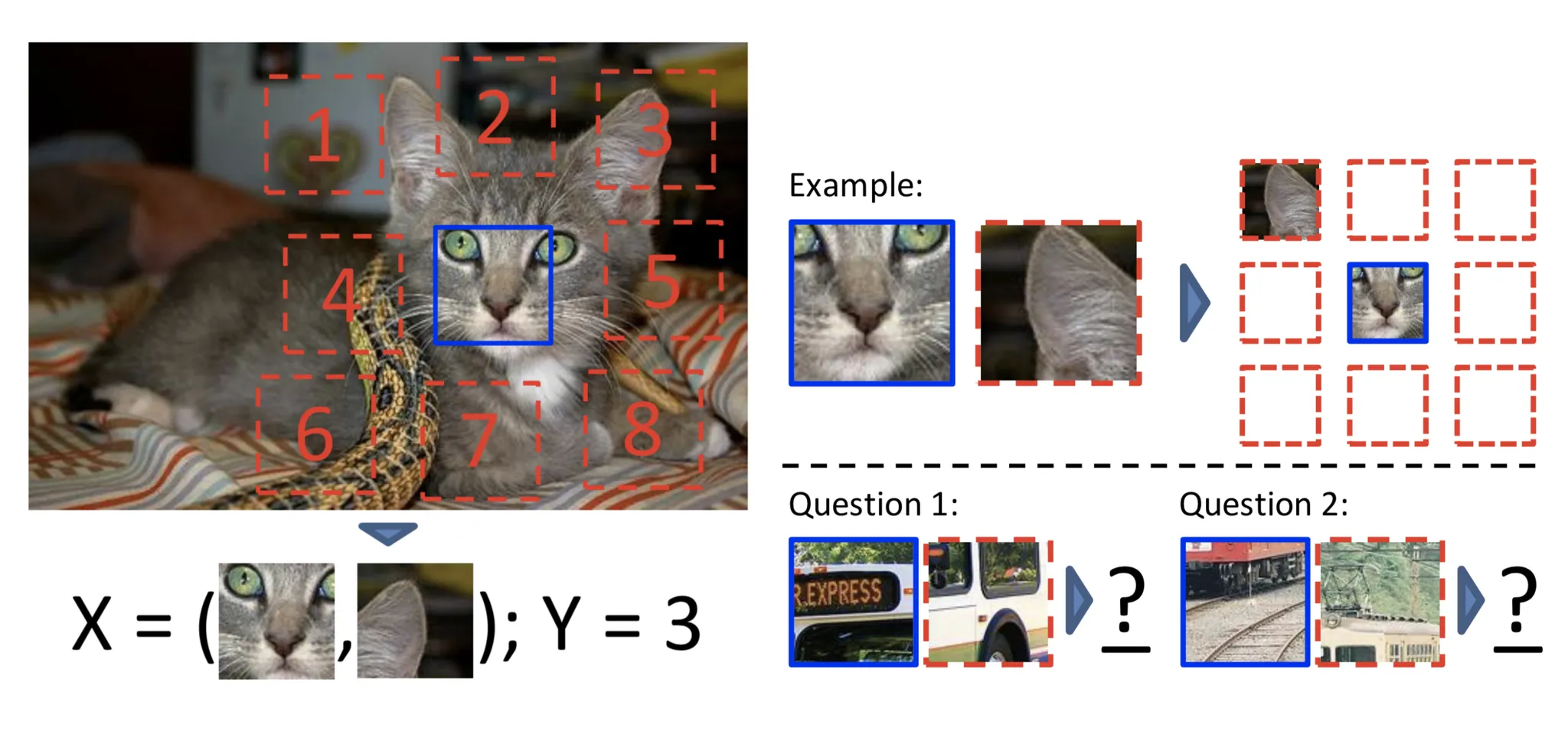
Patches
하나의 이미지로부터 여러 패치를 추출하여 패치들의 관계를 예측한다.
1. 하나의 이미지에서 두 개의 랜덤 패치의 상대적인 위치를 예측한다.
특정 패치와 그 주위 8개의 위치 중 하나의 패치를 입력으로 받고 두번째 패치의 위치를 예측한다.
- 모델은 상대적인 위치를 알기 위해 객체들의 공간적인 문맥을 이해/학습할 것이다. 일부의 이미지 위치들의 관계성을 알려면 그것들을 모은 전체적인 이미지의 형태를 인식해야, 즉 객체 하나를 인식해야 객체의 어떤 위치에 해당하는 패치인지를 알 수 있을 것이기 때문에.
- 저수준의 사소한 시그널(점, 선, 객체를 설명하지 못하는 local한 패턴의 feature)을 학습하는 것을 막기 위해 약간의 노이즈를 추가한다: 패치를 만들때 패치들 사이에 약간의 사이를 떨어뜨린다거나, 일부 패치를 downsampling후 upsampling하거나(픽셀에 대해 robust하도록), 패치를 흑백화(채널 2개를 삭제 혹은 Green, Red를 회색으로 바꿈)
- Chromatic aberration(색수차): 색상 채널 사이에 작은 offset이 발생하는 현상. 렌즈를 통과하는 다른 파장의 빛의 초점거리가 달라서 발생한다. 렌즈 내에서 위치에 따라 색수차가 발생하는 정도가 다르기 때문에 색상의 차이의 정도로 패치의 위치를 파악할 수 있다. → 패치를 흑백화하여 이러한 문제를 해결할 수 있다.
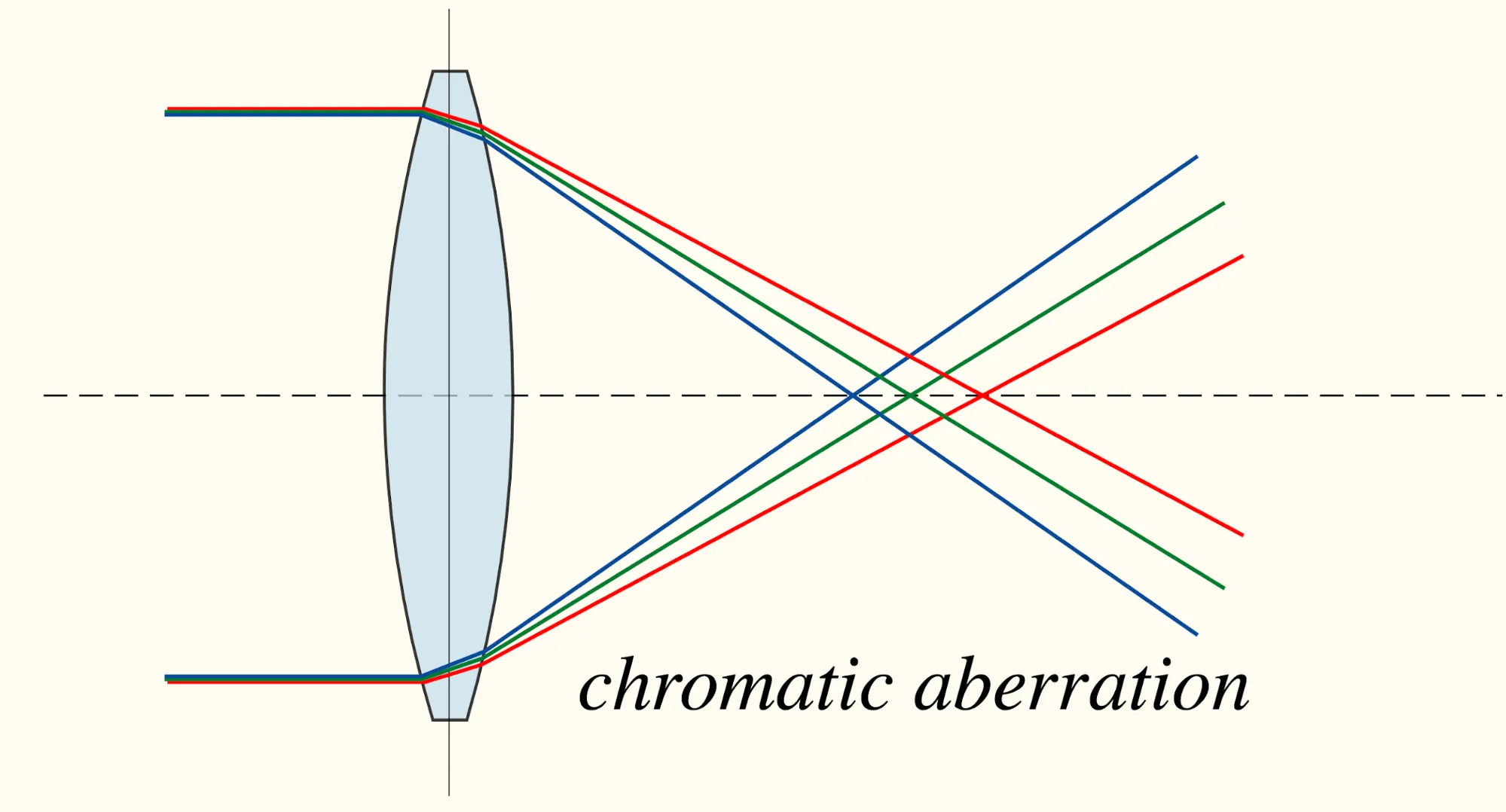
- Chromatic aberration(색수차): 색상 채널 사이에 작은 offset이 발생하는 현상. 렌즈를 통과하는 다른 파장의 빛의 초점거리가 달라서 발생한다. 렌즈 내에서 위치에 따라 색수차가 발생하는 정도가 다르기 때문에 색상의 차이의 정도로 패치의 위치를 파악할 수 있다. → 패치를 흑백화하여 이러한 문제를 해결할 수 있다.
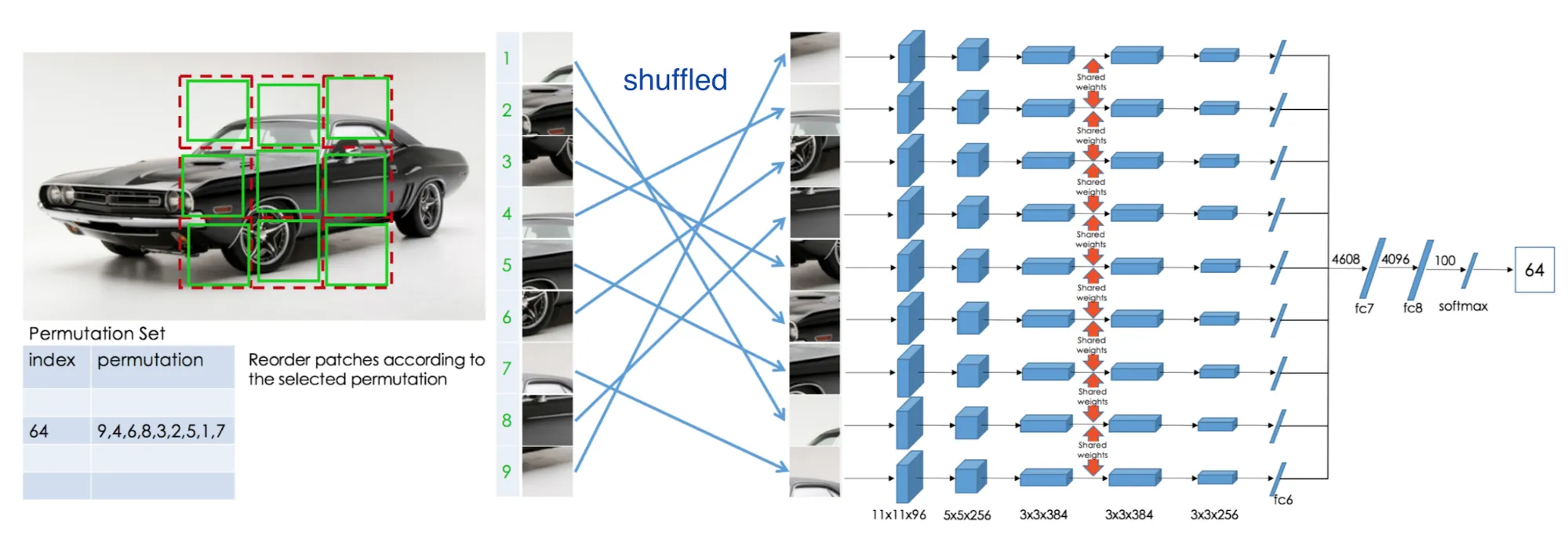
더 나은 pretext task
위치가 랜덤으로 변경된 9개의 패치를 모두 제자리로 위치시킨다. 마치 직쏘 퍼즐 조각을 맞추는 것과 같다. 9개의 패치 각각을 섞어서 다른 모델에 넣고 feature를 뽑아 각 인덱스에 대한 확률 벡터를 예측하도록 한다.
counting feature
또다른 pretext task로는 패치의 feature를 수치화하여 이미지를 비교하는 방법이 있다. 이미지를 구성하는 패치들을 특정 수식을 통해 합산하여 계산한 값이 원래 이미지를 계산한 값과 비슷하도록 학습한다. 즉, 이미지 축소 연산(scaling)과 패치를 나누는 연산(tiling)의 primitive 결과가 동일해지도록 학습한다.
- scaling: 이미지가 2배로 축소되어도 primitive 수는 동일하다.
- tiling: 2x2 격자로 타일링되면 primitive 수는 합산되어 원래의 것에 4배로 늘어난다.
- loss:
- - feature encoder
- - downsampling operator
- - tiling operatior
- : 와는 다른 이미지
→ 원본 이미지를 패치 크기와 동일하게 맞추고(scaling) 하나의 원본으로부터 얻어낸 여러개의 패치 이미지(tiling)의 합을 feature로 게산해서 그 두 값이 비슷해지도록 loss 식을 구성하여 학습한다.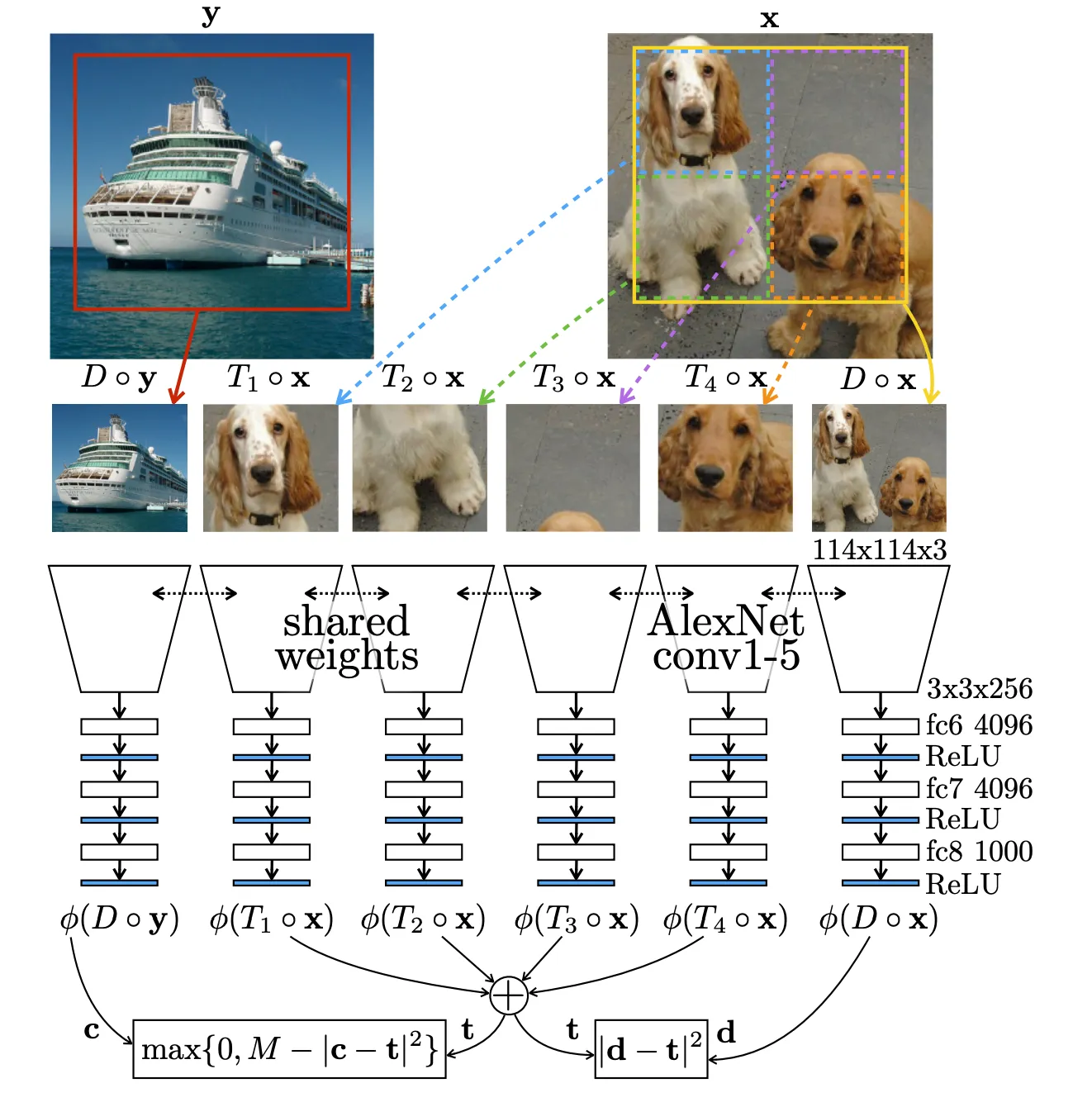
Colorization
grayscale의 이미지를 color image로 색칠한다.
output image는 CIELAB 색상 공간을 가진다.
- L*: 밝기 (0: black, 100: white)
- a*: green (negative) ↔ magenta (positive)
- b*: blue (negative) ↔ yellow (positive)
- green, blue → 배경 색에 가깝다.(일반적인 색상)
- magenta, yellow → 주요 객체의 색에 가깝다.(희귀한 색상)
해당 색상 공간을 사용하여 드물게 나타나는 색상 bucket의 손실을 증가시키도록 학습한다.
Generative Modeling
원본 입력 이미지를 복원하고 의미있는 잠재 표현을 학습한다.
denoising autoencoder
부분적으로 손상되었거나 무작위 노이즈가 있는 이미지에서 복구한다.
→ 사람은 노이즈가 없어도 사진에서 물체를 쉽게 인식할 수 있기 때문에 이런 pretext task를 구성한다.
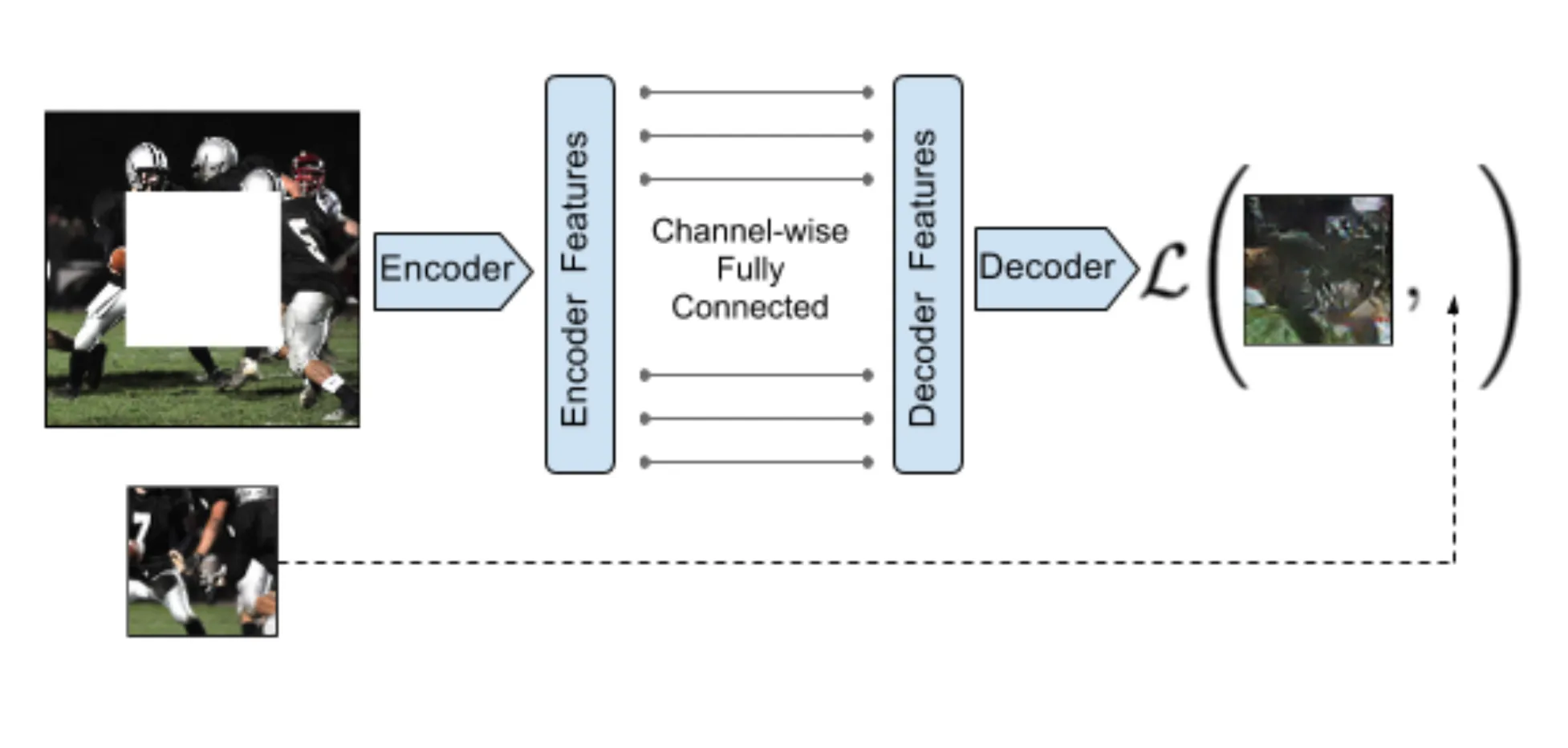
context encoder
이미지에서 누락된 부분을 채운다.

- loss = reconstruction loss + adversarial loss
- reconstruction loss (L2 loss)
- : 이진 마스크 (0: 삭제된 픽셀, 1: 나머지 픽셀)
- : encoder
- : decoder
- adversarial loss
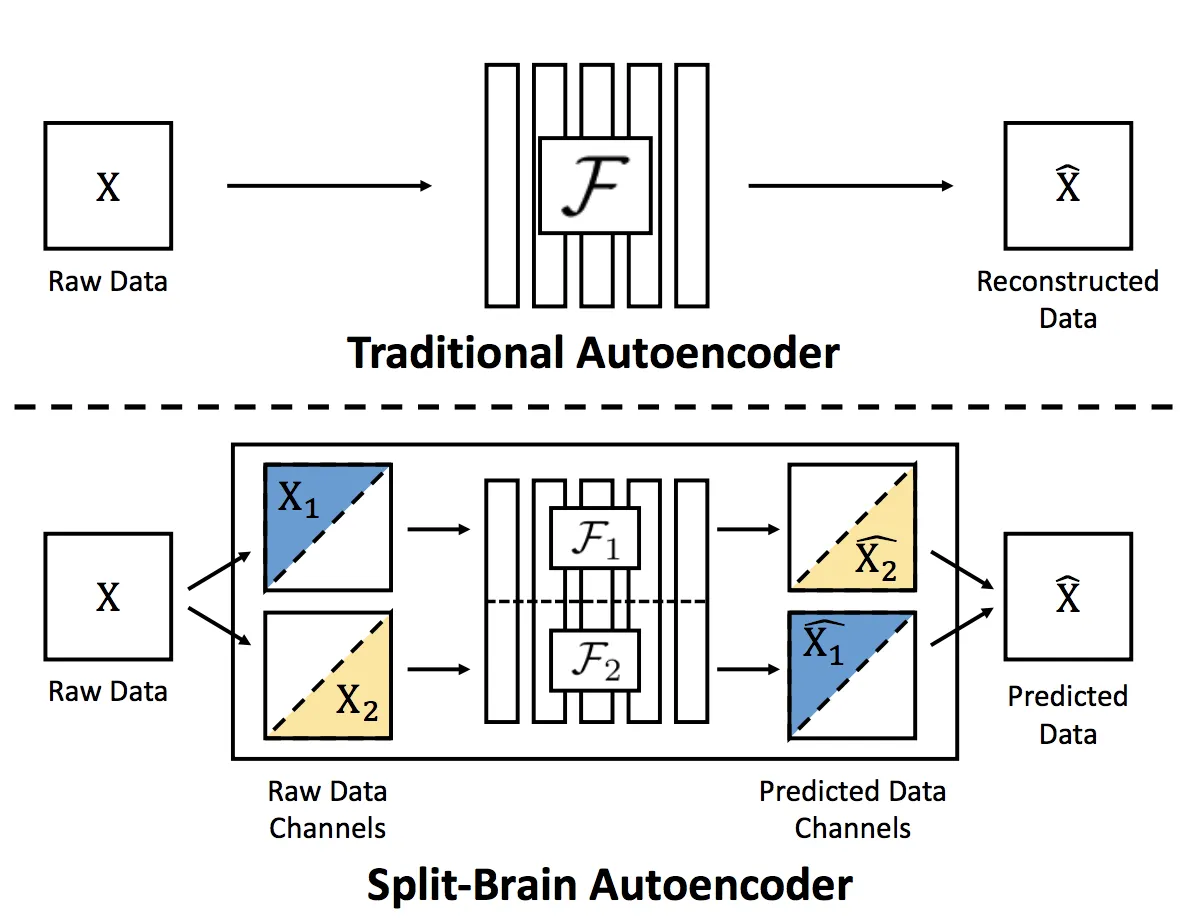
split-brain autoencoder
마스킹을 적용할 때 모든 색상정보를 제거하지 말고 하위 집합만 제거한다.
로 나누어 를 포함한 것, 를 포함한 것을 각각 학습하고 가중치를 공유한다.
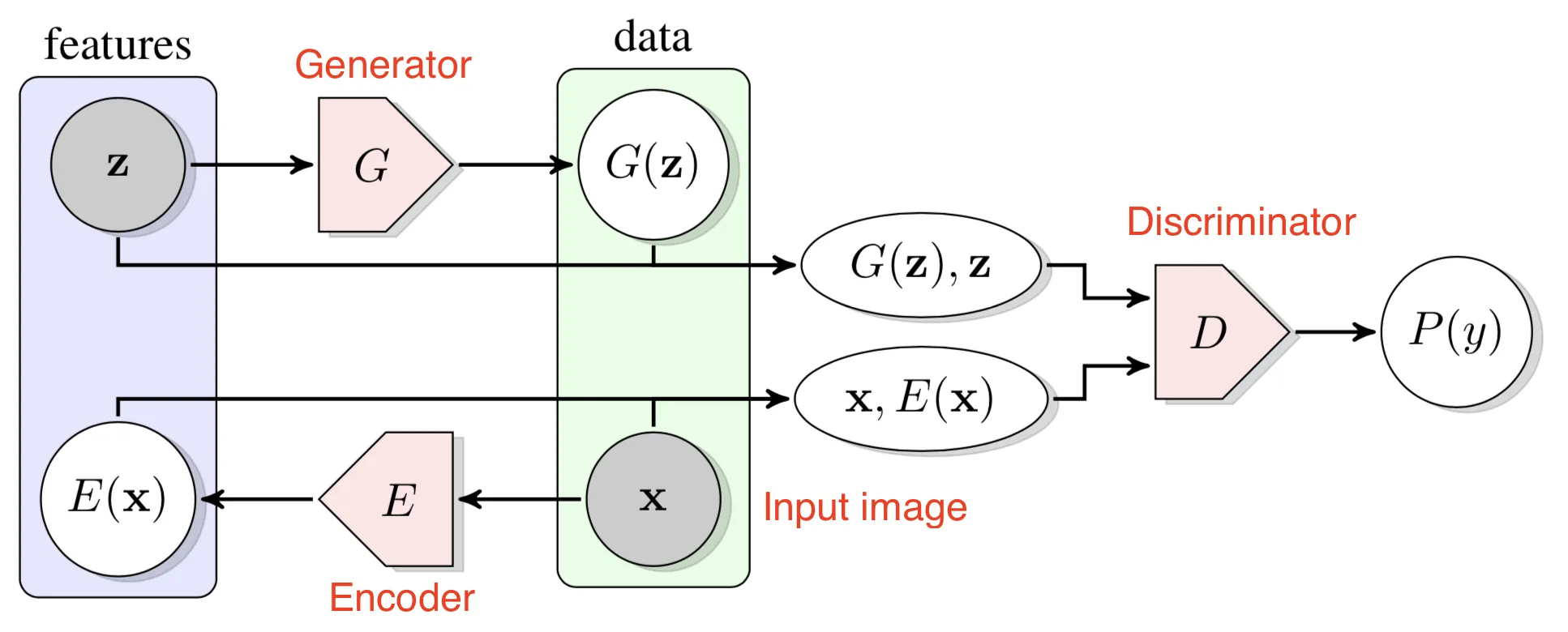
bidirectional GANs
GAN → 간단한 잠재 변수에서 임의로 복잡한 데이터 분포로 매피하는 법을 학습할 수 있다.
→ 생성 모델의 잠재 공간은 데이터의 semantic한 다양성을 포착한다.
bidirectional GAN → 기존 GAN에 인코더를 추가하여 실제 이미지와 비교하지 않고 이미지의 feature와 비교하여 실제 이미지가 아닌, 실제 이미지의 feature를 생성한다.
Contrastive Learning
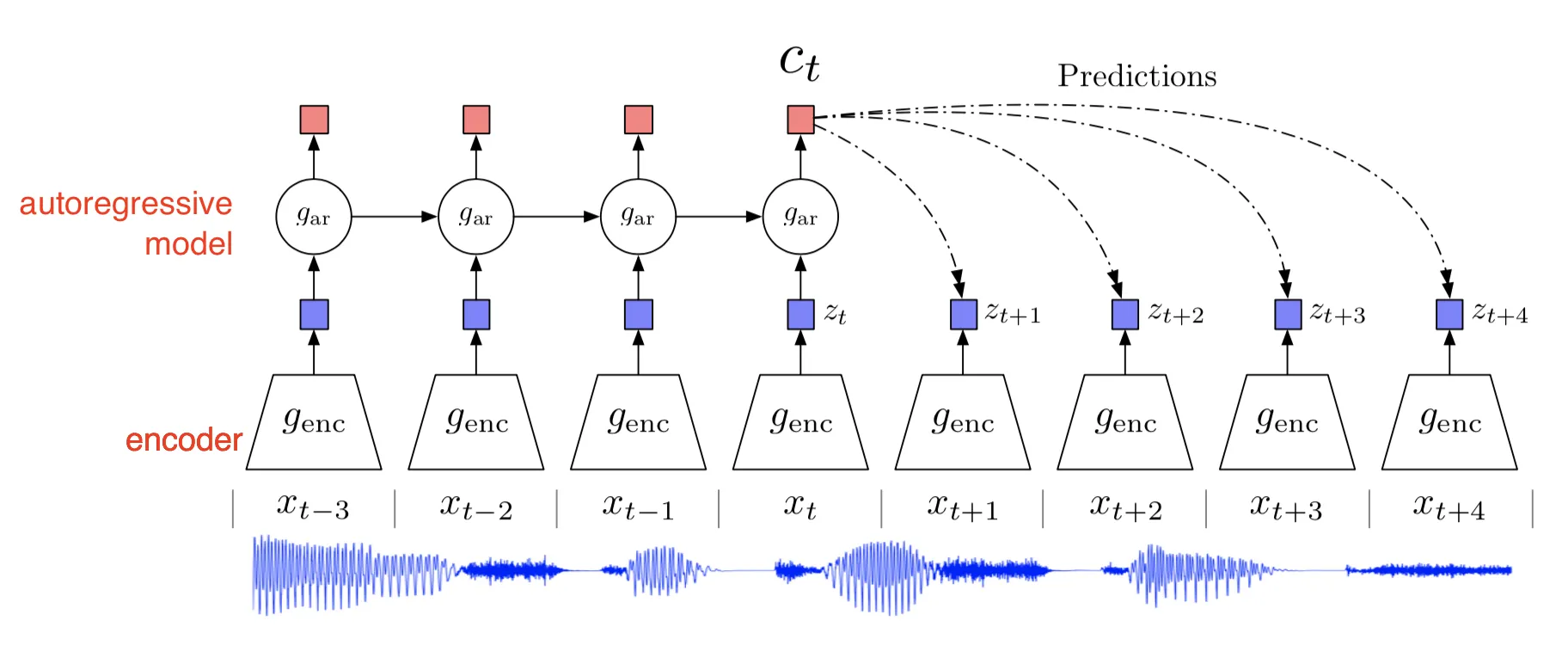
Contrastive Predictive Coding(CPC)
생성 모델링 문제를 분류 문제로 변환하여 고차원 데이터에서 비지도학습을 가능케한다.
CPC의 contrastive loss 혹은 InfoNCE loss
- cross-entropy loss를 사용하여 모델이 관련없는 negative sample 집합 중에서 미래 표현을 얼마나 잘 분류할 수 있을지를 측정한다.
- MSE와 같은 unimodal loss에는 충분한 용량이 없으면서도 전체 생성 모델을 학습하는데 너무 비쌀 수 있기 때문에 이와 같은 loss가 고안되었다.
- : input
- : 인코더, 디코더를 통해 생성된 context vector
- : 인코더를 통해 x를 압축한 것
미래 관찰을 모델링 (pk(x{t+k}|c_t))하는 것보다 직접적으로 상호정보를 보존하기 위해 밀도 함수를 모델링한다.
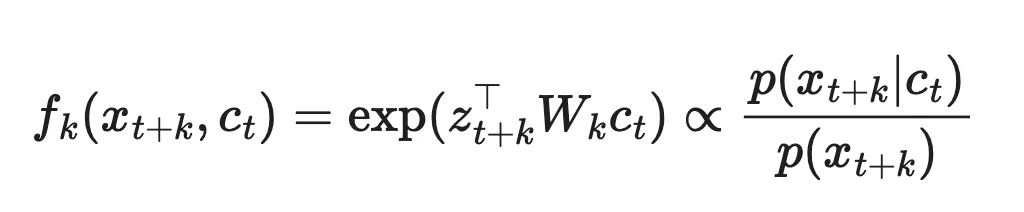
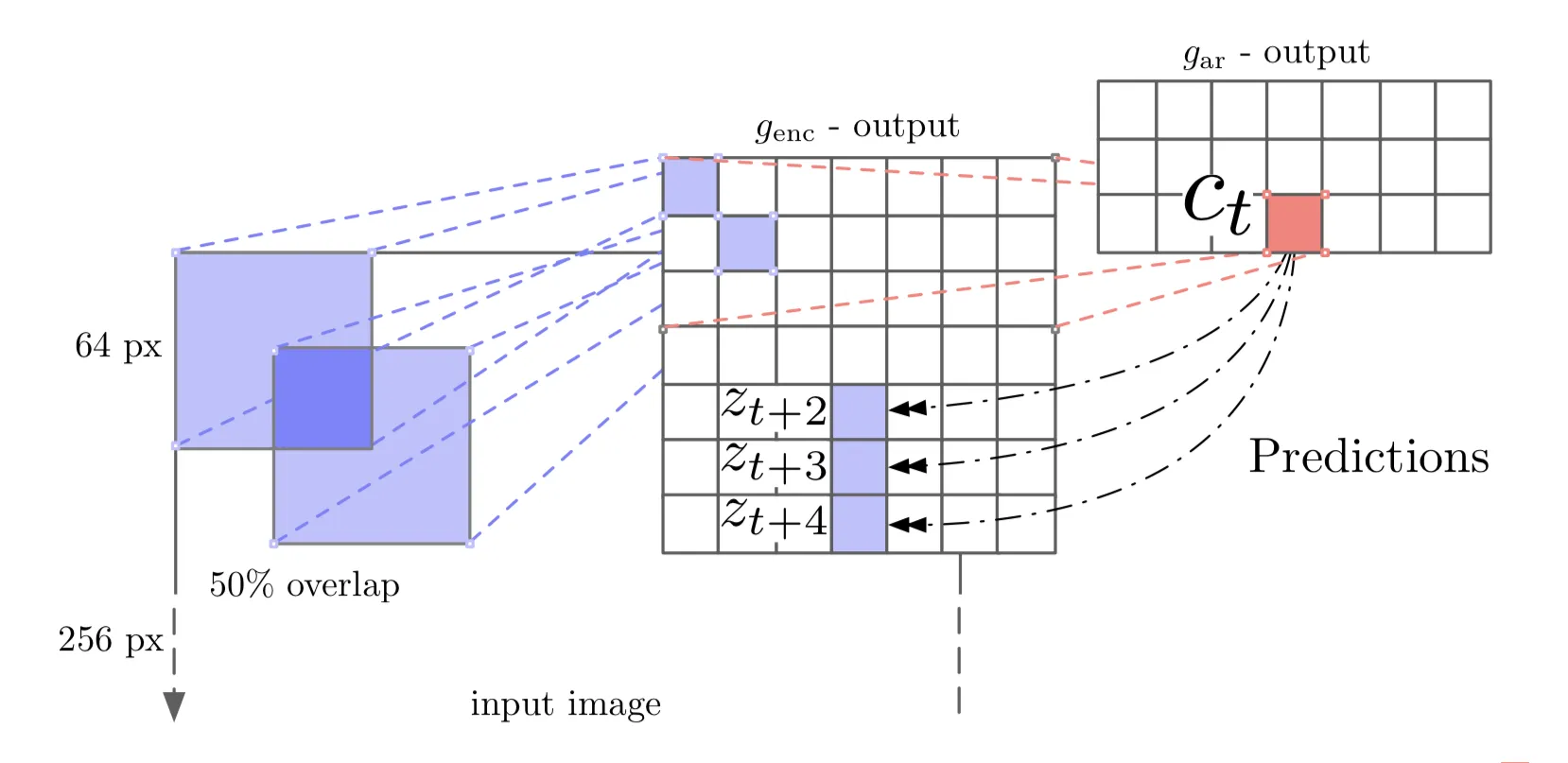
이미지에 이를 사용하는 경우 특정 입력을 위한 영역(receptive field)이 x로 주어지면 그에 해당하는 output feature map 노드 하나(z_t)로 인코딩되고 이 인코딩된 z_t의 여러 값들(특정 영역)을 다시 디코더에 반영하여 output c_t를 생성한다(predict).
Video-based
비디오 → semantic하게 관련된 sequential frame.
- 가까운 프레임은 시간적으로 가깝고 멀리 있는 프레임보다 더 높은 상관관계를 가진다.
- 프레임 순서는 물체의 움직임(움직임이 매끄러워야 함), 중력(아래 방향으로 작용)과 같은 특정 추론 규칙과 물리적 논리를 설명한다.
image-based의 방법과 마찬가지로 unlabeled video를 이용하여 하나 이상의 pretext task를 학습하고 중간 feature layer를 제공하여 action classification / segmentation / object tracking과 같은 downstream task의 간단한 모델을 파인튜닝한다.
Tracking
객체의 움직임은 비디오의 프레임에 의해 추적된다.
비슷한 때의(가까운) 프레임에서 동일한 객체가 화면에 캡처되는 움직임정도의 차이는 그리 크지 않다. 일반적으로 객체나 카메라의 작은 움직임으로부터 이러한 차이가 발생한다. 그러므로 특정 구간의 프레임에서의 동일한 객체에 대한 학습된 시각적 표현은 latent feature space에서 가까워야 한다.
이를 이용하여 비디오 내의 tracking moving objects를 통해 시각적 표현을 비지도 학습하는 방법을 제안한 연구가 있다.
anchor 패치 가 있을때 비슷한 프레임의 패치(프레임의 동일한 객체 중 하나의 패치)를 (positive sample)이라 두고, 다른 객체의 패치를 (negative sample)이라 두고, 와 사이의 거리(차이)가 와 사이의 거리보다 훨씬 가깝도록(차이가 적도록) 학습한다. 이때 거리를 둘의 cosine distance로 계산한다.
- 이러한 형식의 loss는 얼굴 인식 분야에서 triplet loss라고 알려져 있다. 얼굴인식에서는 다음 값들의 triplet loss를 계산한다.
- anchor x → 특정 사람의 이미지
- positive image → 다른 각도의 동일한 사람의 이미지
- negative image → 다른 사람의 이미지
두 단계의 비지도의 optical flow를 통해 관련 있는 패치들을 추적하고 추출한다.
- SURF interest points(시각적 representation 추출 방법 중 하나)를 얻어서 IDT(카메라 움직임을 제외한 이미지 내의 움직임의 optical flow를 계산)를 사용하여 각 SURF 포인트들의 움직임을 감지한다.
- SURF interest points의 궤적이 주어진 후에 flow 규모가 0.5 픽셀보다 크면 이 포인트들이 움직인다고 분류한다.
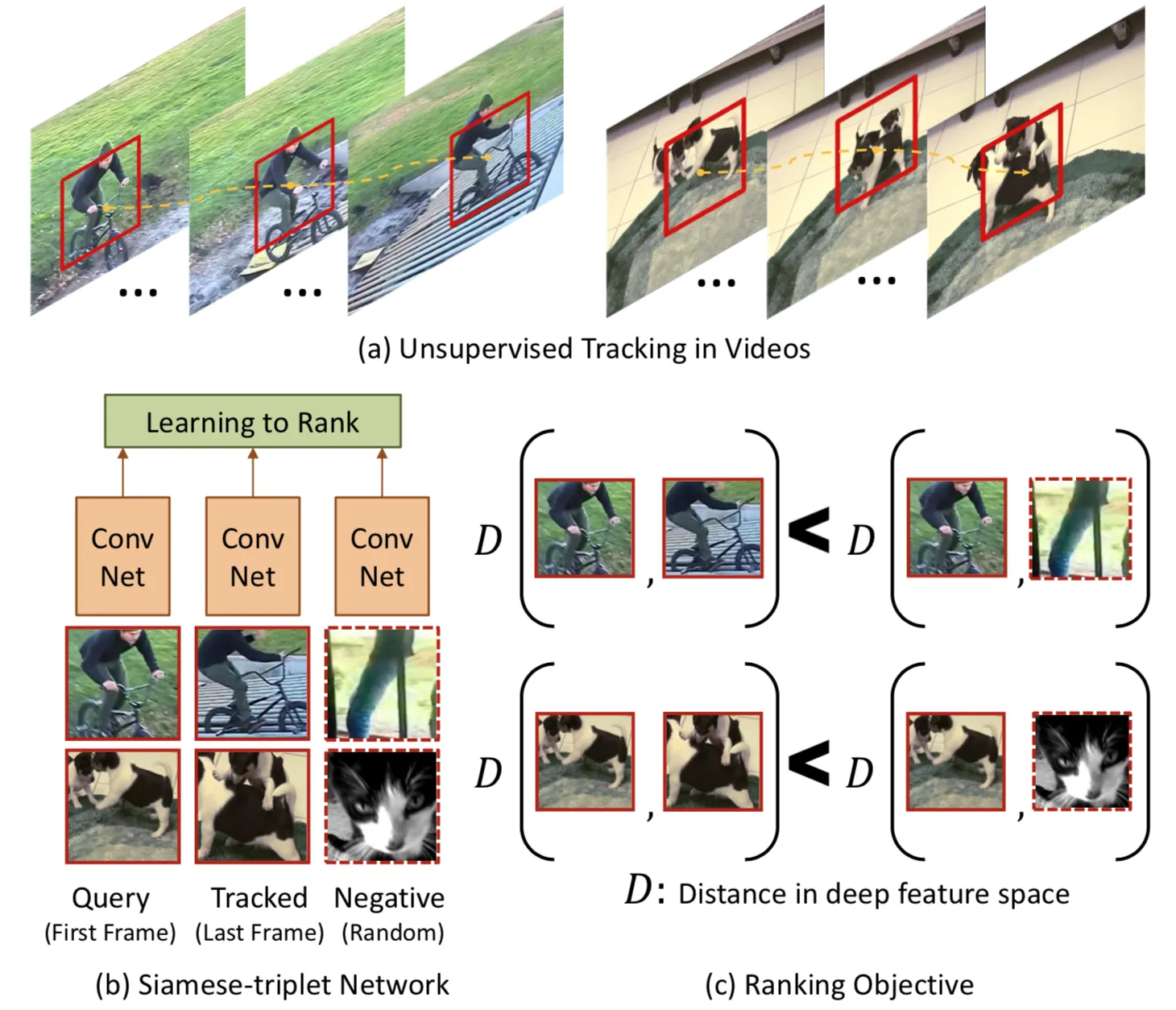
학습하는 동안 와 는 쌍으로 주어지고, 동일한 batch 중에서 랜덤으로 하나 뽑아 로 사용한다. 몇 에폭 학습 후에 hard negative mining을 적용하여 학습을 더 hard하고 효율적으로 만든다. 즉, loss를 최대화하는 랜덤 패치를 찾아서 gradient update를 한다.
Frame Sequence
좋은 표현은 프레임의 올바른 순서를 학습해야 한다는 기대(예상)에서 제안되었다.
validate frame over
맞는 순서의 프레임 순열인지 결정하는 pretext task
→ 모델은 이러한 작업을 완료하기 위해 프레임 전체에서 객체의 작은 움직임을 추적하고 추론해야한다.
training frames는 high-motion windows에서 샘플링된다.
가 있다고 할 때, 다음과 같은 positive, negative tuple을 지정했다고 하자.
-
1 positive tuple
-
2 negative tuples
-
이때 두 파라미터를 계산한다.
- : positive training instance의 난이도를 조절
- : negative training instances의 난이도를 조절
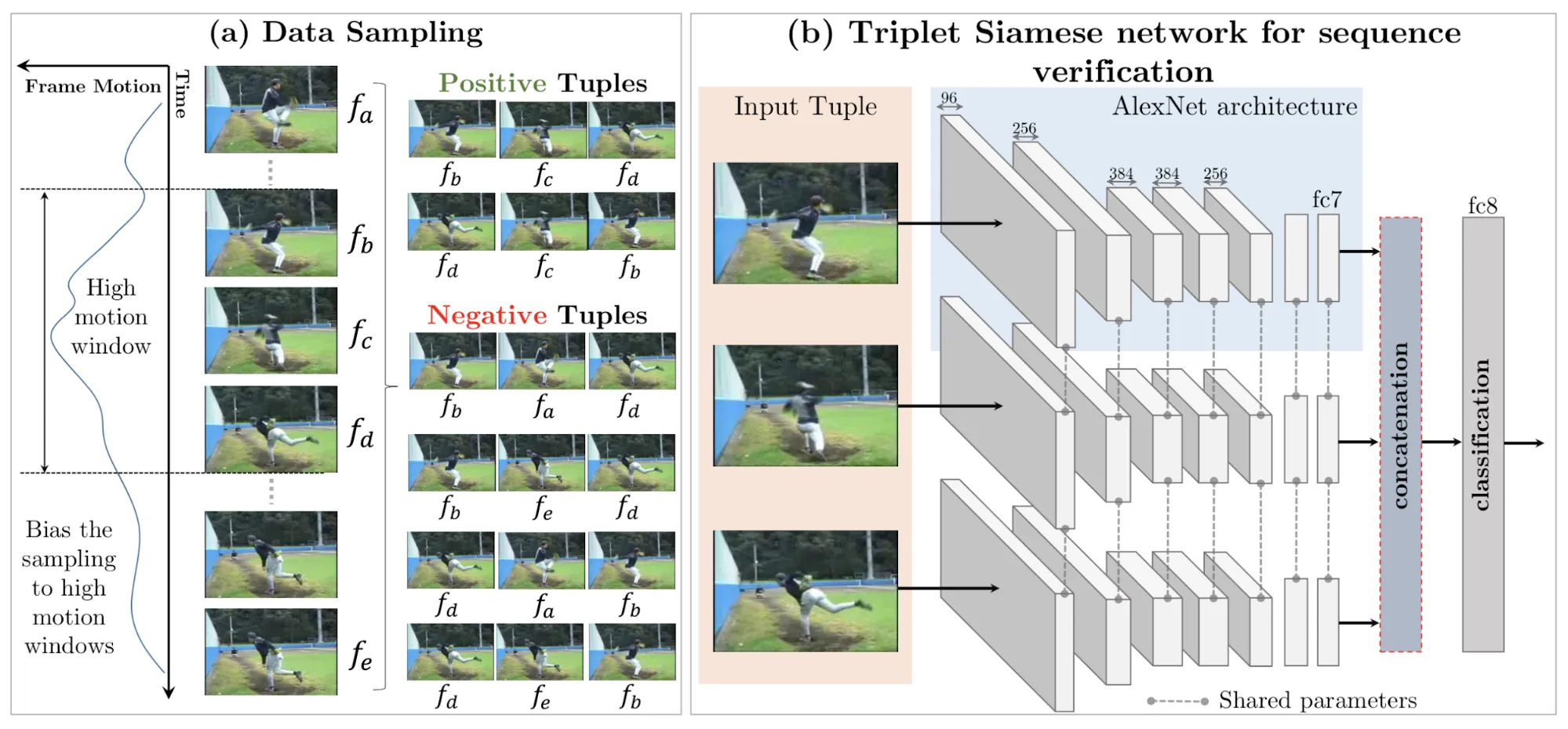
이러한 비디오 프레임 순서 검증의 pretext task는 사전 학습 단계로 사용될 경우 동작 인식의 downstream task 성능을 향상시켰다.
O3N(odd-one-out) network
여러 비디오 클립으로부터 위치를 예측하는 pretext task
N+1개의 입력 클립 중 하나의 프레임이 섞여 있어 순서가 잘못되고, 나머지는 순서가 맞는다. 그때 O3N은 이상한 비디오 클립의 위치를 예측하도록 학습한다.
T-CAM(Temporal Class-Activcation-Map)
arrow of time 개념
-
low-level physics와 high-level의 events에 대한 유익한 메시지를 포함
-
비디오를 앞으로 재생하든 뒤로 재생하든 시간의 화사표를 예측하여 잠재 표현을 학습한다. → 기본적인 물리적 원리를 학습한다.
T-CAM은 arrow of time를 예측한다. 이를 예측하기 위해 low-level physics와 high-level semantics를 모두 포착해야한다. -
optical flow를 추출하기 위해 많은 프레임을 포함하는 그룹을 T개 가지고 있다. 각 그룹으로부터 나온 출력을 concatenate하여 arrow of time을 예측한다.
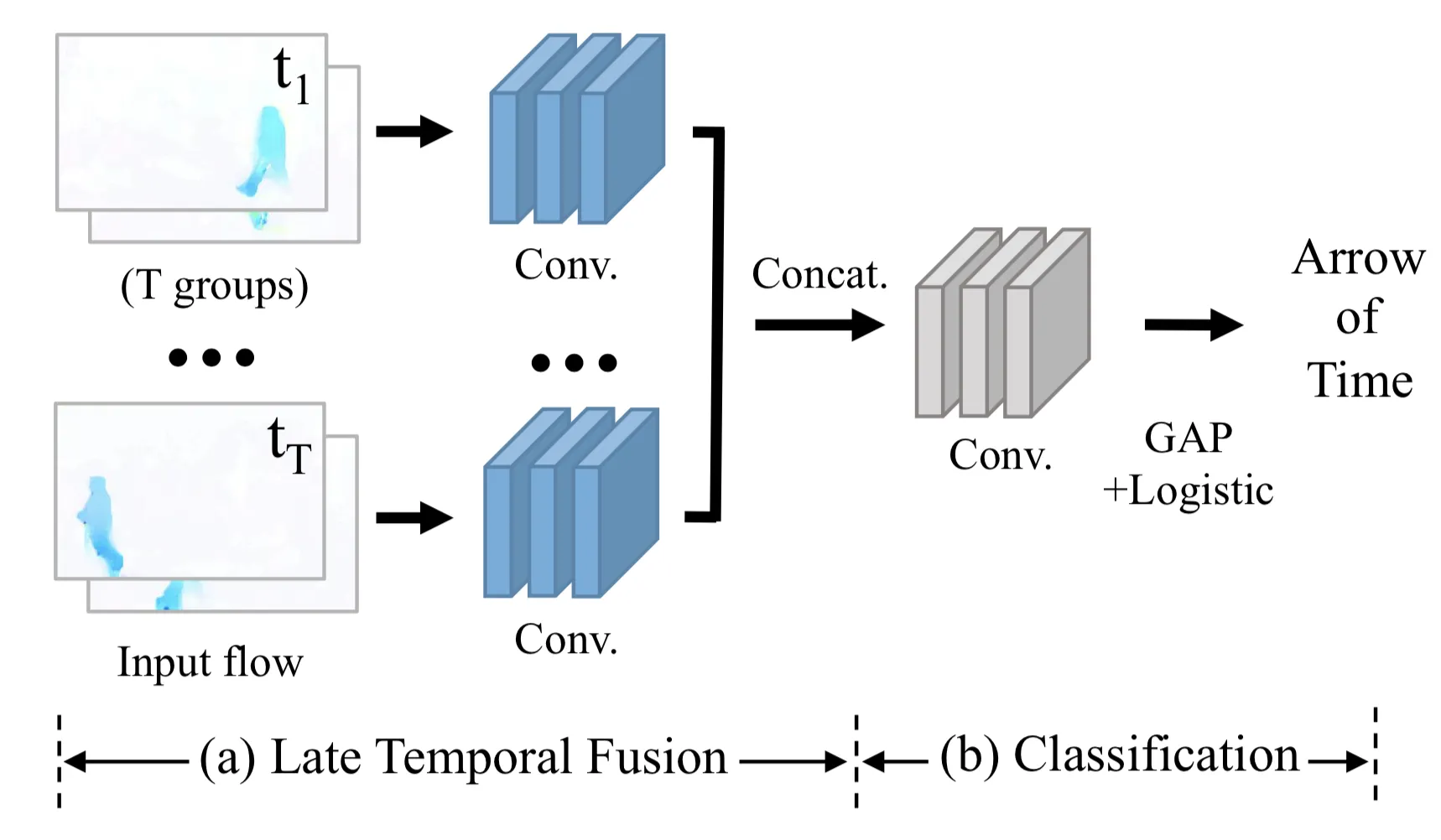
파란 conv layer들로부터 low-level physics를 예측하고 회색 cons layer로부터 high-level semantics를 추출한다.
arrow of time pretext task는 사전학습 단계로 사용할 때 action classification downstream task의 성능을 개선한다. 그러나 이때 파인튜닝이 추가로 필요하다.
Video Colorization
파인튜닝 없이도 video segmentation, unlabeled vision region tracking을 위한 풍부한 표현을 제공할 수 있다.
image-based colorization과 달리, video-based에서는 비디오 프레임 간의 자연스러운 시각적 일관성을 활용한다. 이를 통해 colored reference frame에서 다른 frame(reference와 시각적으로 가까운 프레임)으로 색상을 복사한다.
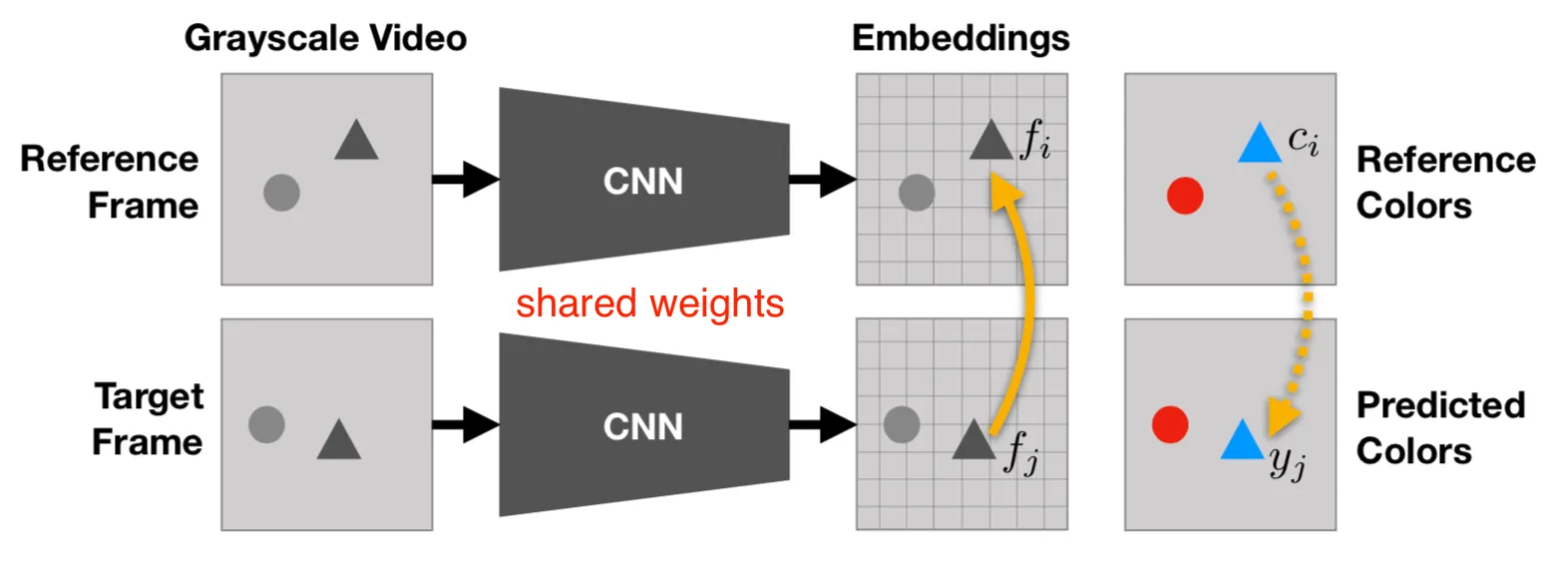
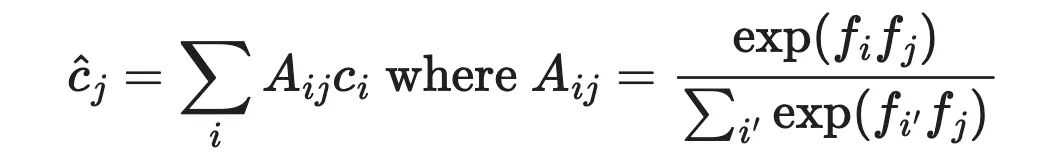
- : reference frame의 특정 픽셀
- : target frame에서의 와 연관된 픽셀
reference frame을 어떻게 표시하느냐에 따라 모델은 tracking segmentation in time / human pose in time과 같은 color-based downstream task에 적용할 수 있다. 이때 파인튜닝은 필요없다.

self-supervised learning 연구들에서 공통적으로 관찰된 것
- pretext task를 여러개 결합하면 성능이 향상된다.
- network를 깊게 쌓으면 표현의 퀄리티가 높아진다.
- 지도학습 baseline이 모든 self-supervised 방법보다 여전히 성능이 좋다.
