📌 Knowledge Distillation
-
지식 증류(Knowledge Distillation)는 크고 복잡한 모델의 성능을 작고 콤팩트한 모델에 옮기는 딥러닝 기법이다.
-
지식 증류를 통해 더 연산적으로 효율적인 모델에서 큰 모델의 성능을 구현할 수 있다.
- 큰 모델은 “선생님 모델(Teacher Model)”, 작은 모델은 “학생 모델(Student Model)”이라고 지칭한다.
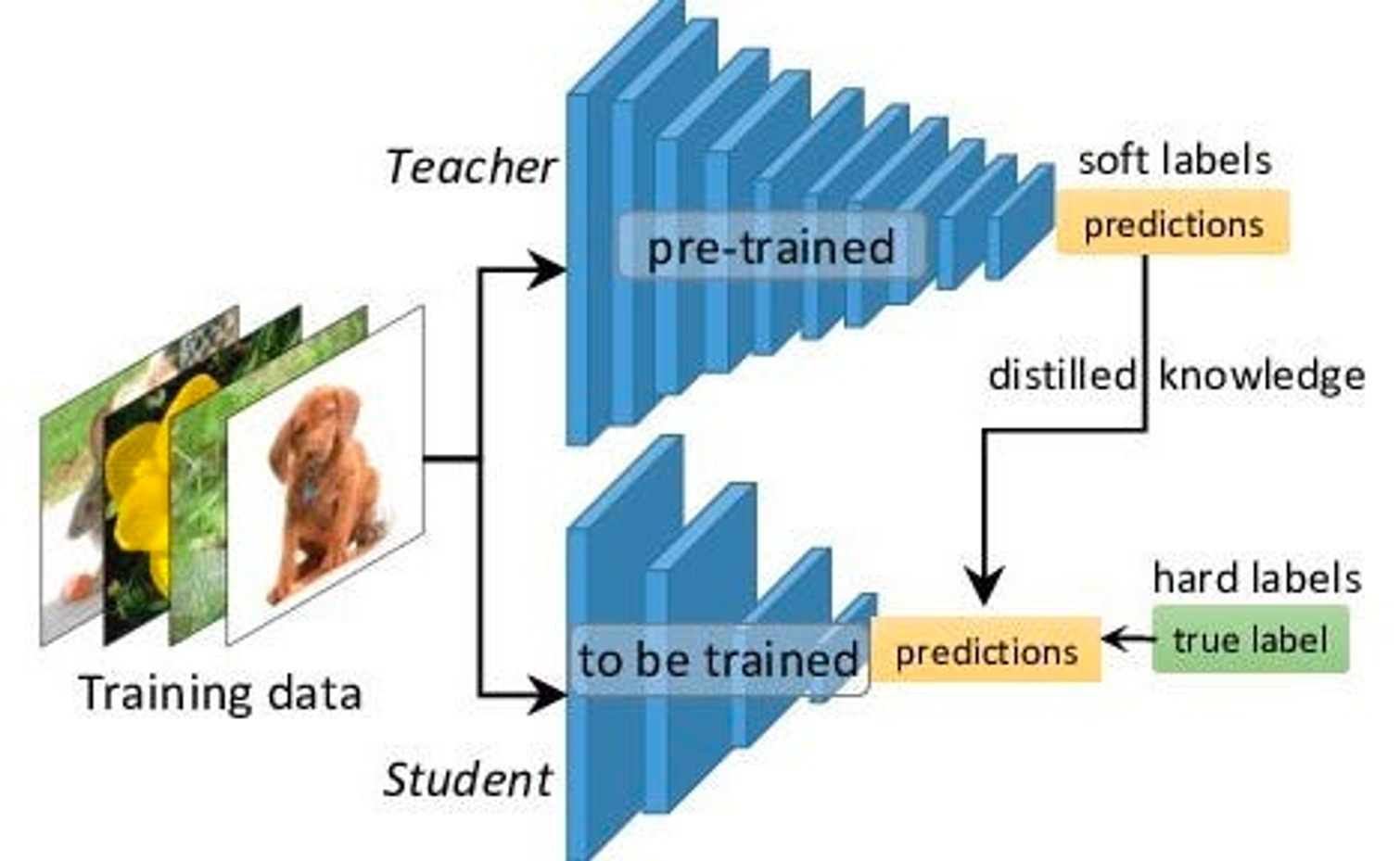
출처 : A Gentle Introduction to Hint Learning & Knowledge Distillation | by LA Tran | Towards AI
📎 선생님 모델
- 선생님 모델은 사전 학습된 모델이며 일반적으로 높은 수준의 정확도와 일반화 정도를 가진 더 큰 모델이다.
- 일반적으로 이미지 분류 또는 자연어 처리와 같은 특정 작업을 수행하기 위해 대규모 Dataset에 대해 학습된 깊은 모델들이 있다.
- 지식 증류는 교사 모델이 가지는 뛰어난 성능과 데이터에 대한 지식을 학생 모델에 잘 전달하는 것을 목표로 한다.
📎 학생 모델
- 학생 모델은 교사 모델의 동작을 모방하도록 학습된 더 작고 가벼운 모델이다.
- 교사 모델과 유사한 구조를 갖도록 설계되었지만 파라미터가 더 적고 모델 복잡도가 낮다.
- 학생 모델은 교사 모델에 인코딩된 지식을 포착하고, 주어진 과제에서 유사한 성과를 달성하면서 메모리와 추론 시간 측면에서 더 효율적인 것을 목표로 한다.
증류 과정에는 일반적인 학습 과정에서 쓰이는
하드 레이블(Hard Label)뿐 아니라 선생님 모델이 내뱉는 대답을 이용해소프트 레이블(Soft Label)을 설정한다. 그리고 두 가지 손실 함수를 활용한다.
📎 소프트 레이블(Soft Target)
- 교사 모델은 일련의 소프트 타겟(Soft Target) 또는 소프트 레이블(Soft Label)을 생성한다.
- 소프트 타겟은 한 번에 인코딩된 레이블이 아닌 출력 클래스에 대한 확률 분포이다.
- 이러한 소프트 타겟은 예측에 대한 선생님 모델의 신뢰도와 불확실성을 반영하며 하드 레이블보다 더 복잡한 정보를 제공한다.
- 학생 모델은 이 소프트 레이블을 손실 함수에 활용하여 학습한다.
📎 손실 함수
-
학생 모델은 교차 엔트로피 손실과 같은 표준 손실 함수를 이용하여 하드 레이블과의 차이를 최소화하는 것을 학습하면서, 동시에 교사 모델이 생성한 소프트 타겟과의 차이를 좁히도록 학습한다.
-
이러한 지식 손실은 학생 모델이 하드 레이블뿐만 아니라 소프트 레이블에 포함된 풍부한 정보를 학습하도록 하여 선생님 모델이 가진 지식을 잘 포착할 수 있도록 한다.
-
이로써 학생 모델은 선생님 모델의 전문성, 일반화 능력 및 견고함(Robustness)을 활용하면서 더 작은 크기와 빠른 추론 속도를 유지할 수 있다.
지식 증류는 리소스가 제한된 환경에서도 대규모 모델에 필적하는 높은 성능과 정확도를 유지하면서 효율적인 모델을 사용할 수 있도록 하였다. 따라서 모델 압축, 전이 학습, 앙상블 학습과 같은 다양한 시나리오에 널리 적용되었다.
📌 LLM
LLM(Large Language Model)이란 인간의 언어를 이해하고 생성하도록 설계된 일종의 인공지능 모델을 말한다. 이러한 모델은 일반적으로 방대한 양의 텍스트 데이터로 학습되어 언어의 패턴, 구문, 문법 및 의미를 학습할 수 있다. 대규모 언어 모델은 학습에 필요한 매개변수와 계산 리소스 측면에서 그 크기가 매우 크다는 특징이 있다.
어느 정도 크기의 모델부터 LLM이라고 부르는지 정의된 바는 없지만, 일반적으로 모델 파라미터 수가 10B 이상, 거대한 데이터셋으로 학습, 복잡한 태스크(일반적인)에 전체적으로 우수한 성능을 보이면 LLM이라고 부른다.
GPT-1, BERT도 처음에는 Super large로 취급받았지만 지금 모델들에 비하면 크기가 작은 편이다. 아래는 현재까지 공개된 LLM들을 시간순으로 정리한 이미지이다.
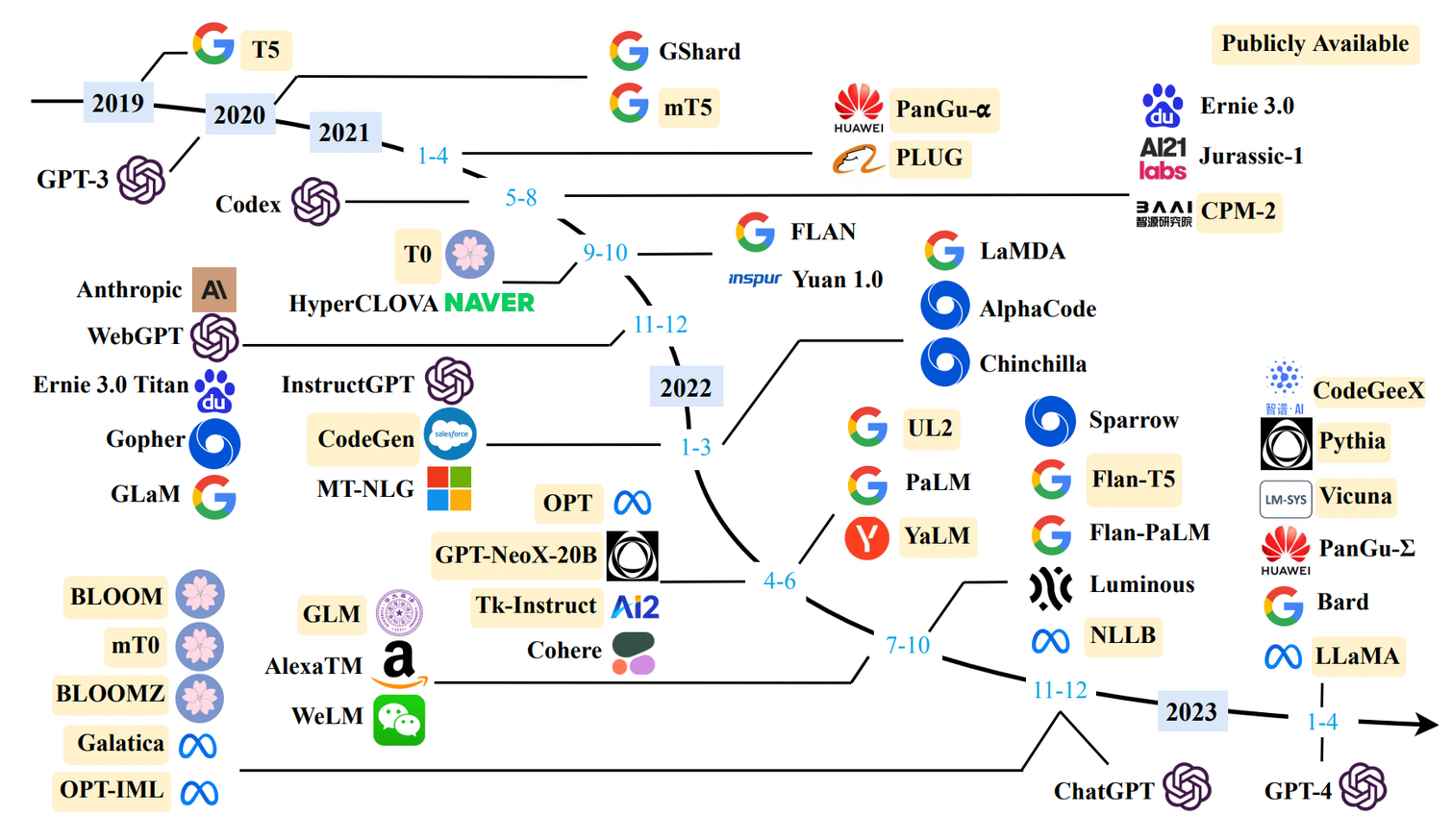
(LLM의 기준과 이미지 출처 : A Survey of Large Language Models, Zhou et al, 2023)
OpenAI의 GPT(Generative Pre-trained Transformer)시리즈와 같은 대규모 언어 모델은 트랜스포머 아키텍처를 기반으로 구축된다. 트랜스포머는 텍스트와 같은 순차적 데이터를 처리하는 데 탁월한 심층 신경망 모델이다. 셀프 어텐션 메커니즘을 사용하여 문장이나 문서 내에서 단어 또는 토큰 간의 장거리 종속성과 관계를 포착한다.
LLM을 학습하려면 책, 기사, 웹사이트 등 다양한 소스의 방대한 양의 텍스트로 모델을 학습시켜야 한다. GPT나 BERT 같은 모델은 라벨 없이 텍스트의 빈칸이나 다음 단어를 유추하게 하는 방식으로 학습하는데, 이를 비지도 학습이라고 한다.
학습이 완료된 LLM은 특정한 태스크에 맞게 추가 학습되지 않더라도 다양한 자연어처리 과제를 수행할 수 있다. 일관되고 문맥에 맞는 텍스트를 생성하고, 문장이나 단락을 완성하고, 질문에 답하고, 요약을 제공하고, 언어 간 번역을 하고, 심지어 대화에 참여할 수도 있다.
대규모 언어 모델의 출현은 고객 서비스, 콘텐츠 생성, 언어 번역, 가상 비서 등 다양한 분야에 큰 영향을 미쳤다. 대규모 언어 모델은 일상적인 언어 기반 작업을 자동화하고, 정보 검색을 개선하며, 여러 애플리케이션에서 사용자 경험을 향상시킬 수 있는 잠재력을 가지고 있다.
일반 연구실, 회사도 돌리기 힘들 정도의 크기에 모델의 가중치들도 공개가 되지 않아서 연구를 진행하기 힘들다는 의견이 많았지만 최근에 Llama, Vicuna 등 경량화된 모델과 학습에 필요한 데이터셋들이 공개가 되고 있다.
대규모 언어 모델은 학습과 추론에 상당한 컴퓨팅 리소스와 에너지 소비가 필요하므로 환경 영향과 에너지 효율성에 대한 우려가 제기된다. 편견, 개인정보 보호, 책임감 있는 사용과 관련된 윤리적 고려 사항도 중요해지고 있다.
[출처 | 딥다이브 Code.zip 매거진]
