
Categorial + Gradient Boosting
Boosting
 부스팅은 약한 학습 모델을 여러 개 붙여서 하나의 강한 학습 모델을 만드는 앙상블 기법이다.
부스팅은 약한 학습 모델을 여러 개 붙여서 하나의 강한 학습 모델을 만드는 앙상블 기법이다.
순차적으로 학습을 시켜 이전 모델의 오답을 다음 모델에서 고치려고 하기 때문에, 이전 모델에 의존하게 된다.
boosting으로 모델을 순차적으로 생성한다. 모델1을 만든 후 그 정보를 바탕으로 모델2를 만들고 다시 그 정보를 바탕으로 모델3을 만든다. 그리고 최종적으로 만들어진 이러한 weaker 모델을(약한 예측기-모델1,2,3)을 모두 결합하여 최종 모델을 만드는 것이 boosting의 원리이다.
부스팅은 오답에 집중해서 학습하기 때문에 성능이 좋지만, 그만큼 outlier에 취약하며 오버피팅의 우려가 있다.
outlier란 이상치이다.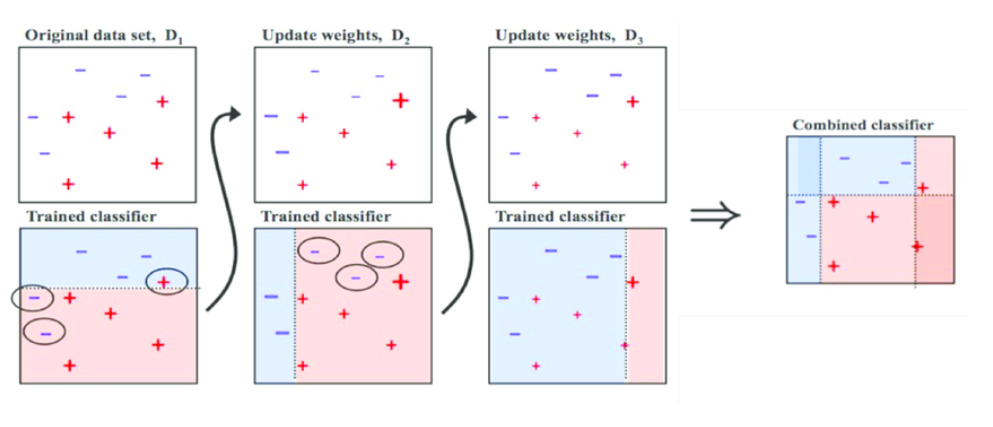
Gradient boosting
catboost 는 gradient boosting 을 기반으로 하는 모델이다.각 데이터 포인트에 동일한 가중치를 부여한다.제대로 예측되지 않은 데이터포인트가 존재할 것이다. (=오차)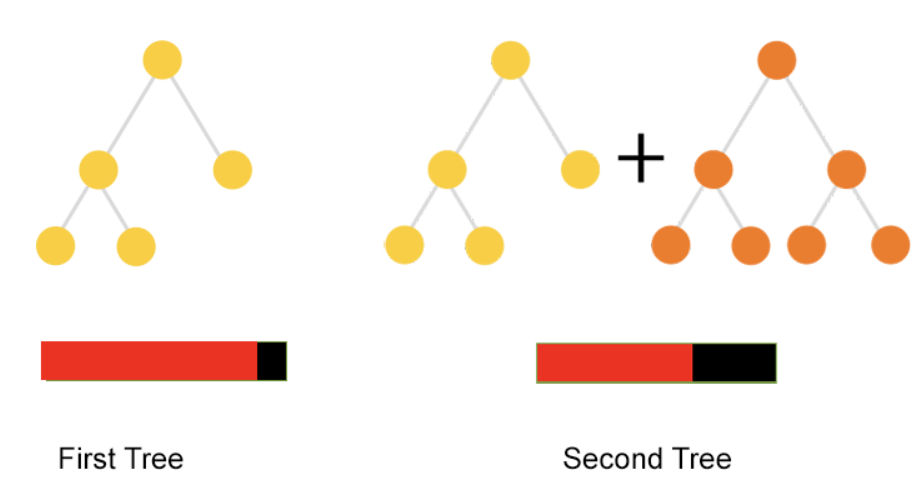 사진의 빨간색은 오차로, 빨간색 영역이 줄어들수록 예측 결과가 정확하다는 뜻이다.
사진의 빨간색은 오차로, 빨간색 영역이 줄어들수록 예측 결과가 정확하다는 뜻이다.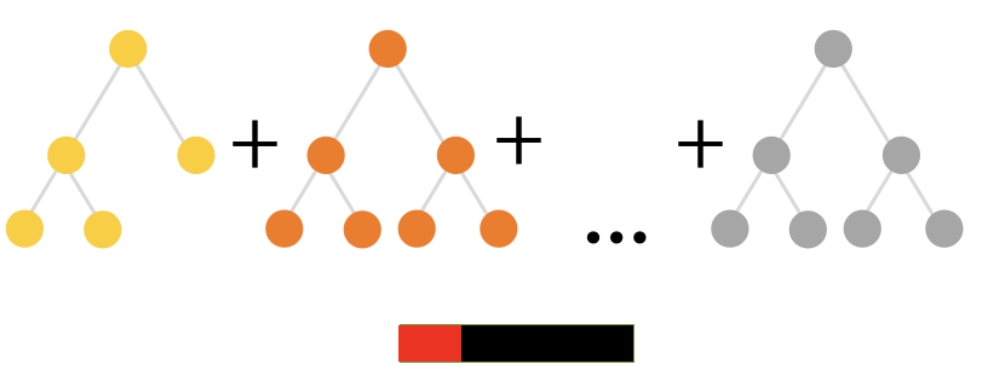 예측이 틀린 데이터포인트만을 가지고 다시 학습을 시킨다. 성능이 준수할 때까지 이 과정을 계속 반복하는 것!
예측이 틀린 데이터포인트만을 가지고 다시 학습을 시킨다. 성능이 준수할 때까지 이 과정을 계속 반복하는 것!
약한 예측기를 결합하여 강한 예측기를 만드는 boosting계열의 앙상블(Ensemble) 알고리즘.
사이킷런의 GradientBoostingClassifier는 기본적으로 깊이가 3인 결정 트리 100개를 사용한다. 깊이가 얕은 결정트리를 사용하기 때문에 과대적합에 강하고 일반적으로 높은 일반화 성능을 기대할 수 있다.
Level-wise
catboost는 level-wise 모델이다. XGBoost 와 더불어 Catboost 는 Level-wise 로 트리를 만들어나간다. (반면 Light GBM 은 Leaf-wise 다)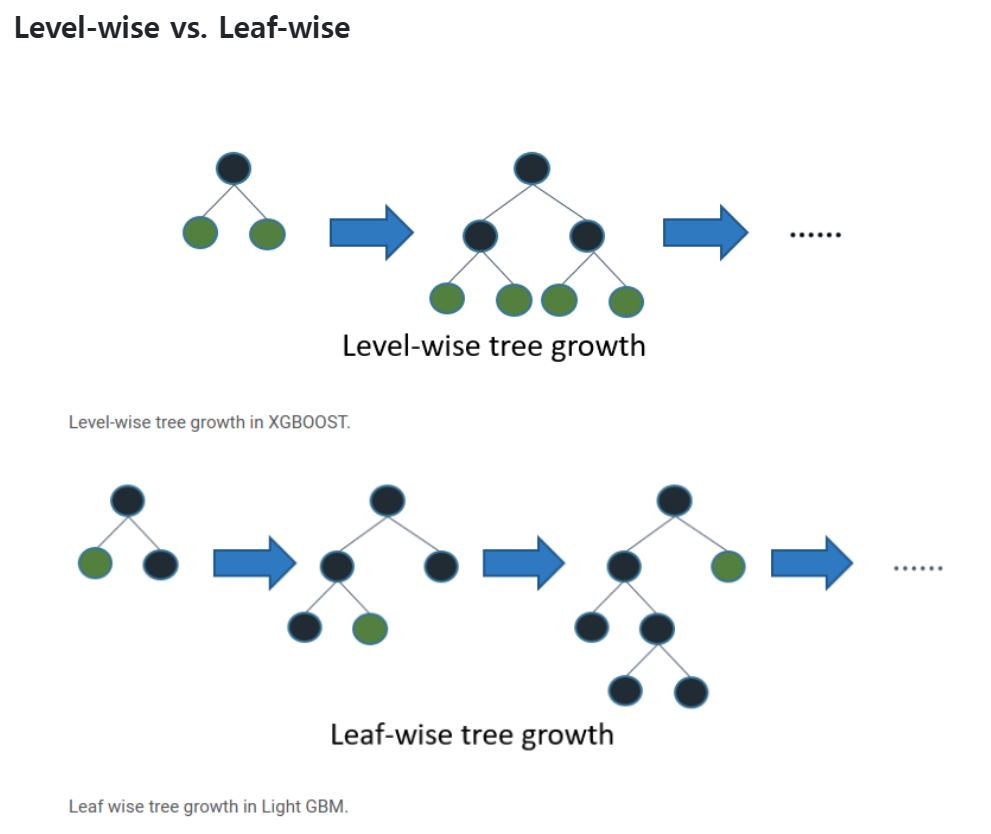
XGBoost: 층이 늘어남 (수평 성장) = Level-wise = Depth-first
LGBM: 리프가 늘어남 (수직 성장) = Leaf-wise = Best-first
기존 알고리즘의 경우 categorical data는 one-hot encoding으로 추가적인 전처리 프로세스를 거쳐야 했지만, CatBoost는 그런거 없이 모델이 자동으로 처리를 해준다 이게 무슨 말일까?
학습 시간은 느리지만 예측 시간은 빠르다고 한다. 음.. 그럼 학습에 어느 정도 걸리는 거지?
파라미터
CatBoost의 기본 파라미터는 알고리즘의 성능과 학습 속도에 영향을 미칩니다. 기본적으로 CatBoost는 여러 가지 독특한 특징을 가지고 있으며, 우리는 일반적으로 다른 Gradient Boosting 알고리즘보다 더 적은 수의 반복 학습으로 높은 정확도를 달성할 수 있습니다.
일반적으로 CatBoost의 주요 기본 파라미터는 다음과 같습니다:
- iterations: 학습 횟수를 지정합니다. 높은 값은 모델의 정확도를 높일 수 있지만, 학습 시간이 길어질 수 있습니다.
- depth: 트리의 최대 깊이를 지정합니다. 더 깊은 트리는 더 복잡한 학습 모델을 만듭니다.
- learning_rate: 각 반복에서 모델 가중치를 조정하는 정도를 제어합니다. 작은 값은 더욱 조금씩 가중치를 조정하며, 큰 값은 가중치를 더 크게 변화시킵니다.
- loss_function: 손실 함수를 지정합니다. 분류 문제의 경우 일반적으로 Logloss를 사용하며, 회귀 문제의 경우 RMSE를 사용합니다.
CatBoost 모델 훈련
model = cb.CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, loss_function='Logloss')
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=100, verbose=100)위의 예제 코드에서는 CatBoostClassifier를 사용하여 분류 문제를 해결합니다. 모델을 훈련하기 위해 특성 데이터와 타겟 데이터를 준비한 후, train_test_split 함수를 사용하여 훈련 데이터와 테스트 데이터로 분리합니다.
CatBoost 모델을 초기화한 후, fit 메소드를 호출하여 훈련을 수행합니다. eval_set 매개 변수를 사용하여 각 에포크마다 테스트 데이터에서 모델을 평가할 수 있습니다. early_stopping_rounds를 사용하여 과적합을 방지하고, verbose를 사용하여 학습 과정을 확인할 수 있습니다.
마지막으로, 훈련된 모델을 사용하여 훈련 데이터와 테스트 데이터에서 예측을 수행하고, accuracy_score 함수를 사용하여 평가 지표를 계산합니다.
CatBoost의 기본 파라미터를 적절하게 튜닝하면 높은 정확도를 달성할 수 있습니다. 그러나 데이터에 따라 최적의 파라미터가 달라질 수 있으므로, 여러 가지 파라미터 조합을 시도해보고 최상의 결과를 찾아야 합니다.
Reference:
